Node-Level Performance and Energy Characterization of Flagship Science Applications on SuperMUC-NG Phase 2
Pith reviewed 2026-06-26 07:05 UTC · model grok-4.3
The pith
GPU offload on SuperMUC-NG Phase 2 delivers 4-12 times higher throughput and up to 15 times better energy efficiency than CPU-only execution for flagship scientific workloads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
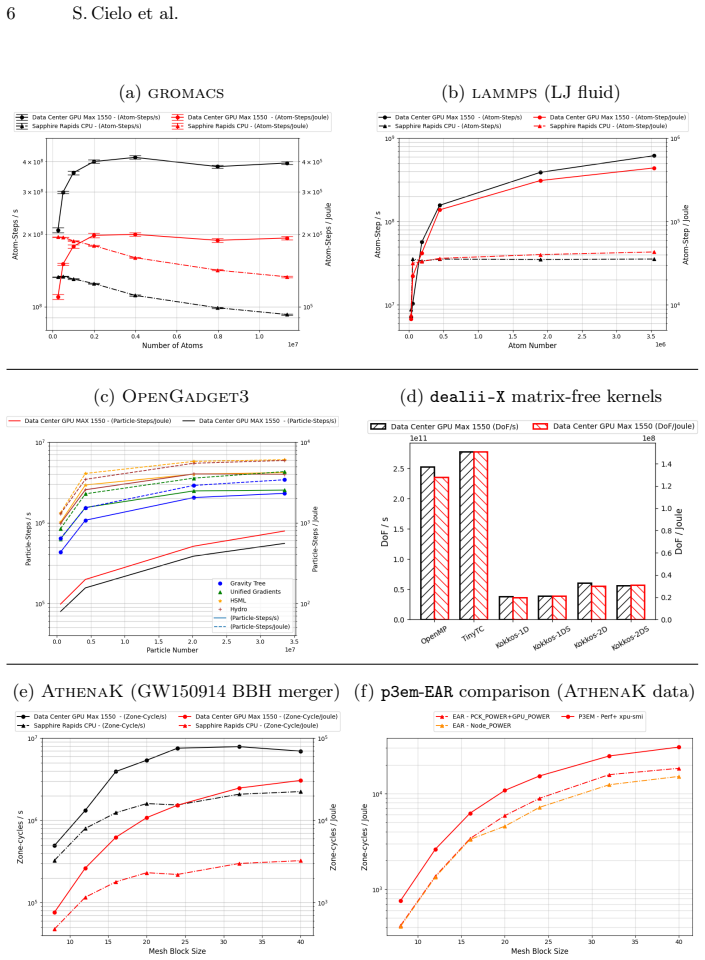
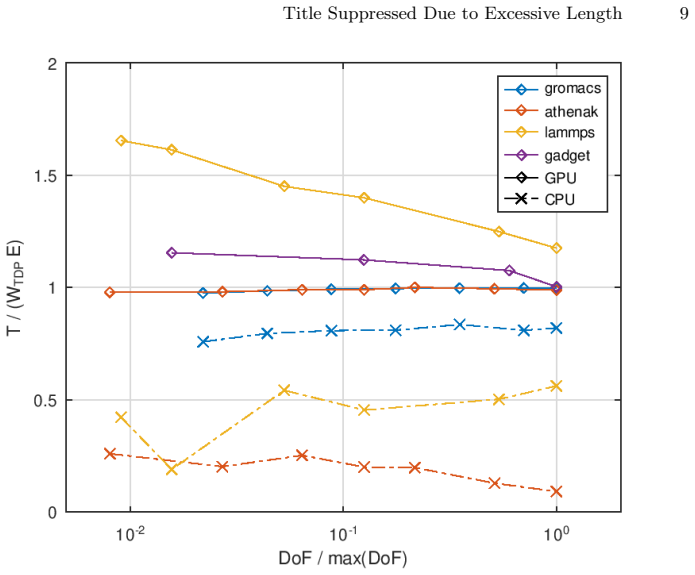
On the SuperMUC-NG Phase 2 node with Intel Xeon Platinum 8480+ CPUs and Intel Data Center GPU Max 1550 accelerators, offloading work to the GPUs yields 4-12× higher throughput measured in compute-elements per wall-clock second and up to 15× better energy efficiency measured in compute-elements per Joule than CPU-only execution. LAMMPS and AthenaK benefit most, while both metrics degrade when problem granularity is insufficient, for example small mesh-block sizes in AthenaK. Energy data come from p3em instrumentation or the system's Energy Aware Runtime, and power-budget utilization remains systematically lower for CPUs than for GPUs.
What carries the argument
Single-node CPU-only versus CPU-plus-GPU configuration comparisons using throughput (compute-elements per second) and energy efficiency (compute-elements per Joule) with energy data from p3em or EAR.
If this is right
- LAMMPS and AthenaK obtain the largest throughput and energy-efficiency gains from GPU offload.
- Insufficient work per GPU tile erodes the reported advantage, as shown by AthenaK at small mesh-block sizes.
- CPU runs leave a substantial fraction of the node's thermal envelope unused even at peak useful-work rate.
- Both throughput and energy gains vary with problem granularity across the tested codes.
Where Pith is reading between the lines
- Production runs could be tuned to larger per-node problem sizes to retain more of the GPU efficiency benefit.
- Schedulers on mixed CPU-GPU systems might incorporate granularity checks when assigning workloads.
- Node-level results imply potential aggregate energy savings if many jobs are configured to avoid the small-granularity regime.
Load-bearing premise
The energy measurements from p3em or EAR accurately capture true application-level consumption without significant overhead or systematic bias.
What would settle it
Repeating the energy measurements for one code using an independent external power meter on the node and checking whether the values match those reported by p3em or EAR.
Figures
read the original abstract
We present a systematic performance and energy-efficiency characterization of five flagship scientific workloads on SuperMUC-NG phase 2, the 28 PetaFLOPs system at the Leibniz Supercomputing Center (LRZ) equipped with Intel Xeon Platinum 8480+ and Intel Data Center GPU Max 1550 (Ponte Vecchio, PVC) accelerators. The selected codes span molecular dynamics (gromacs, lammps), astrophysics and cosmology (OpenGadget3, AthenaK), and finite-element PDE solvers from the dealii-X Center of Excellence. For each code we measure throughput and energy efficiency expressed as compute-elements per wall-clock second (or per Joule of consumed energy) on a single compute node, comparing CPU-only (SPR) against combined CPU+GPU (SPR+PVC) configurations where available. Energy measurements rely on lightweight code instrumentation with p3em, or the Energy Aware Runtime (EAR) present on the system. Our results show that GPU offload yields $4-12\times$ higher throughput and up to $15\times$ better energy efficiency compared to CPU-only execution, with lammps and AthenaK benefiting most. However, both throughput and energy gains are sensitive to problem granularity: insufficient work per GPU tile erodes the accelerator advantage, as clearly observed in AthenaK at small mesh-block sizes. The power-budget utilization is systematically lower for CPUs than it is for GPUs, indicating that even at peak useful-work rate, most applications running on CPUs leave a significant fraction of the node's thermal envelope unused.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a node-level performance and energy-efficiency characterization of five flagship scientific workloads (gromacs, lammps, OpenGadget3, AthenaK, and dealii-X finite-element codes) on SuperMUC-NG Phase 2 (Intel Xeon Platinum 8480+ CPUs and Intel Data Center GPU Max 1550 accelerators). For each code it measures throughput (compute-elements per wall-clock second) and energy efficiency (per Joule) on a single node, comparing CPU-only (SPR) against CPU+GPU (SPR+PVC) configurations. Energy data are obtained via lightweight p3em instrumentation or the system's Energy Aware Runtime (EAR). The central results are that GPU offload yields 4-12× higher throughput and up to 15× better energy efficiency, with lammps and AthenaK benefiting most, but that both gains are sensitive to problem granularity (e.g., mesh-block size in AthenaK). The work also notes systematically lower power-budget utilization on CPUs than on GPUs.
Significance. If the energy measurements prove reliable, the study supplies concrete, application-specific data on the practical benefits and granularity limits of GPU acceleration for production scientific codes on current-generation hardware. The multi-code coverage and explicit demonstration that insufficient work per GPU tile erodes the advantage provide actionable guidance for application tuning and system design. The direct empirical nature of the measurements (no fitted parameters or self-referential derivations) is a strength.
major comments (2)
- [Abstract] Abstract (and Methods section on energy instrumentation): the headline 4-12× throughput and 15× energy-efficiency claims rest on p3em/EAR data, yet the manuscript supplies no cross-validation against external node-level power meters, no quantification of instrumentation overhead, and no discussion of attribution accuracy between CPU and GPU power domains. This is load-bearing for the quantitative ratios.
- [Abstract] Abstract (granularity discussion): while sensitivity to problem size is noted for AthenaK, the chosen mesh-block sizes and other problem configurations are not shown to be representative of typical production workloads, weakening the claim that the reported gains generalize.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the energy instrumentation and the representativeness of problem configurations. We address each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract (and Methods section on energy instrumentation): the headline 4-12× throughput and 15× energy-efficiency claims rest on p3em/EAR data, yet the manuscript supplies no cross-validation against external node-level power meters, no quantification of instrumentation overhead, and no discussion of attribution accuracy between CPU and GPU power domains. This is load-bearing for the quantitative ratios.
Authors: We agree this is a valid concern for the reliability of the reported ratios. The p3em and EAR tools are the standard, system-provided instrumentation on SuperMUC-NG Phase 2; no external node-level meters were available during the campaign. We will revise the Methods section to (i) quantify the known low overhead of these tools from vendor documentation, (ii) describe the CPU/GPU power-domain attribution as reported by the hardware, and (iii) explicitly state the absence of external cross-validation as a study limitation. No new experimental data can be added at this stage. revision: partial
-
Referee: [Abstract] Abstract (granularity discussion): while sensitivity to problem size is noted for AthenaK, the chosen mesh-block sizes and other problem configurations are not shown to be representative of typical production workloads, weakening the claim that the reported gains generalize.
Authors: The AthenaK mesh-block sizes (8³–64³) were chosen to span the granularity range documented in the AthenaK user guide and in published cosmological production runs. We will add explicit references to those production configurations and a short comparison table in the revised manuscript to demonstrate representativeness and thereby support the generalization of the granularity-sensitivity result. revision: yes
Circularity Check
Empirical measurement study with no derivations or self-referential claims
full rationale
The paper consists entirely of direct node-level benchmarks and energy readings for five codes on specific hardware (SPR vs SPR+PVC). No equations, fitted parameters, predictions, or model derivations are present. Throughput and efficiency ratios are computed directly from wall-clock time and energy counters; they are not obtained by fitting or by reducing to prior self-citations. Self-citation load-bearing, ansatz smuggling, and uniqueness theorems are absent. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Observation of Gravitational Waves from a Binary Black Hole Merger
Abbott, B., others, LIGO Scientific Collaboration and Virgo Collaboration: Observa- tion of gravitational waves from a binary black hole merger. Physical Review Letters 116(6), 061102 (2016).https://doi.org/10.1103/PhysRevLett.116.061102
-
[2]
Abraham, M.J., Murtola, T., Schulz, R., Páll, S., Smith, J.C., Hess, B., Lindahl, E.: gromacs: High performance molecular simulations through multi-level parallelism from laptops to supercomputers. SoftwareX1–2, 19–25 (2015).https://doi.org/ 10.1016/j.softx.2015.06.001
-
[3]
In: Software for exascale computing-SPPEXA 2016-2019, pp
Arndt, D., Fehn, N., Kanschat, G., Kormann, K., Kronbichler, M., Munch, P., Wall, W.A., Witte, J.: Exadg: High-order discontinuous galerkin for the exa-scale. In: Software for exascale computing-SPPEXA 2016-2019, pp. 189–224. Springer (2020)
2016
-
[4]
SIAM Journal on Scientific Computing 47(1), B131–B159 (2025)
Böhm, F., Bauer, D., Kohl, N., Alappat, C.L., Thönnes, D., Mohr, M., Köstler, H., Rüde, U.: Code generation and performance engineering for matrix-free finite element methods on hybrid tetrahedral grids. SIAM Journal on Scientific Computing 47(1), B131–B159 (2025)
2025
-
[5]
Cielo, S., Pöppl, A., Pribec, I.: SYCL for energy-efficient numerical astrophysics: the case of dpecho (2025),https://arxiv.org/abs/2508.14117
arXiv 2025
-
[6]
Corbalan, J., et al.: Ear: Energy management framework for supercomput- ers. International Journal of High Performance Computing Applications37(5), 528–548 (2023).https://doi.org/10.1177/10943420231179036, https://github. com/eas4dc/EAR
-
[7]
Darden, T., York, D., Pedersen, L.: Particle mesh ewald: An n·log(n) method for ewald sums in large systems. J. Chem. Phys.98, 10089–10092 (1995)
1995
-
[8]
eu/, formal reference if available (deliverable / paper) 12 S.Cielo et al
deal.II-XCentreofExcellence:deal.ii-xcentreofexcellence, https://www.dealii-x. eu/, formal reference if available (deliverable / paper) 12 S.Cielo et al
-
[9]
In: Weiland, M., Neuwirth, S., Kruse, C., Weinzierl, T
Dobrev, P., Mathias, G.: Benchmarking of gpu performance saturation on accel- erated cluster nodes via molecular dynamics software packages. In: Weiland, M., Neuwirth, S., Kruse, C., Weinzierl, T. (eds.) High Performance Computing. ISC High Performance 2024 International Workshops. pp. 115–126. Springer Nature Switzerland, Cham (2025)
2024
-
[10]
Essmann, U., Perera, L., Berkowitz, M., Darden, T., Lee, H., Pedersen, L.: A smooth particle mesh ewald method. J. Chem. Phys.103, 8577–8592 (1995)
1995
-
[11]
Hammer, N., et al.: Extreme scale-out supermuc phase 2 - lessons learned (2016), https://arxiv.org/abs/1609.01507
Pith/arXiv arXiv 2016
-
[12]
Hess, B., Kutzner, C., van der Spoel, D., Lindahl, E.: GROMACS 4: Algorithms for highly efficient, load-balanced, and scalable molecular simulation. J. Chem. Theory Comput. (2008).https://doi.org/10.1021/ct700301q
-
[13]
Karademir, Geray S. ; Dolag, K.: Space-timers – a stack-based hierarchical timing system for c++ (2026),https://arxiv.org/abs/2603.01618
Pith/arXiv arXiv 2026
-
[14]
Bioinformatics29, 845–854, DOI: 10.1093/bioinformatics/btt055 (2013)
Pronk, S., Páll, S., Schulz, R., Larsson, P., Bjelkmar, P., Apostolov, R., Shirts, M.R., Smith, J.C., Kasson, P.M., van der Spoel, D., B. Hess, E.L.: Gromacs 4.5: a high-throughput and highly parallel open source molecular simulation toolkit. Bioinformatics (2013).https://doi.org/10.1093/bioinformatics/btt055
-
[15]
Páll, S., Abraham, M.J., Kutzner, C., Hess, B., Lindahl, E.: Tackling exascale software challenges in molecular dynamics simulations with gromacs. In S. Markidis and E. Laure (Eds.), Solving Software Challenges for Exascale (2015).https: //doi.org/10.1007/978-3-319-15976-8_1
-
[16]
Shukla, N., et al.: Eurohpc space coe: Redesigning scalable parallel astrophysical codes for exascale. CF ’25 Companion: Proceedings of the 22nd ACM International Conference on Computing Frontiers: Workshops and Special Sessions pp. 177–184 (2025).https://doi.org/10.1145/3706594.3728892
-
[17]
Stone, J.M., Mullen, P.D., Fielding, D., Grete, P., Guo, M., Kempski, P., Most, E.R., White, C.J., Wong, G.N.: Athenak: A performance-portable version of the athena++ adaptive mesh refinement framework. The Astrophysical Journal Supplement Series 283(1), 27 (2026).https://doi.org/10.3847/1538-4365/ae3717
-
[18]
The International Journal of High Performance Computing Applications33(4), 735–757 (2019)
Świrydowicz, K., Chalmers, N., Karakus, A., Warburton, T.: Acceleration of tensor- product operations for high-order finite element methods. The International Journal of High Performance Computing Applications33(4), 735–757 (2019)
2019
-
[19]
Thompson, A.P., Aktulga, H.M., Berger, R., Bolintineanu, D.S., Brown, W.M., Crozier, P.S., in ’t Veld, P.J., Kohlmeyer, A., Moore, S.G., Nguyen, T.D., Shan, R., Stevens, M.J., Tranchida, J., Trott, C., Plimpton, S.J.: Lammps – a flexible simula- tion tool for particle-based materials modeling. Computer Physics Communications 271, 108171 (2022).https://doi...
-
[20]
In: Proceedings of the international conference for high performance computing, networking, storage and analysis
Uphoff, C., Rettenberger, S., Bader, M., Madden, E.H., Ulrich, T., Wollherr, S., Gabriel, A.A.: Extreme scale multi-physics simulations of the tsunamigenic 2004 sumatra megathrust earthquake. In: Proceedings of the international conference for high performance computing, networking, storage and analysis. pp. 1–16 (2017)
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.