Superhuman AI for Generals.io Using Self-Play Reinforcement Learning
Pith reviewed 2026-06-26 09:01 UTC · model grok-4.3
The pith
An AI agent trained by self-play reinforcement learning reaches the top of the Generals.io human leaderboard and defeats the best players head-to-head.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
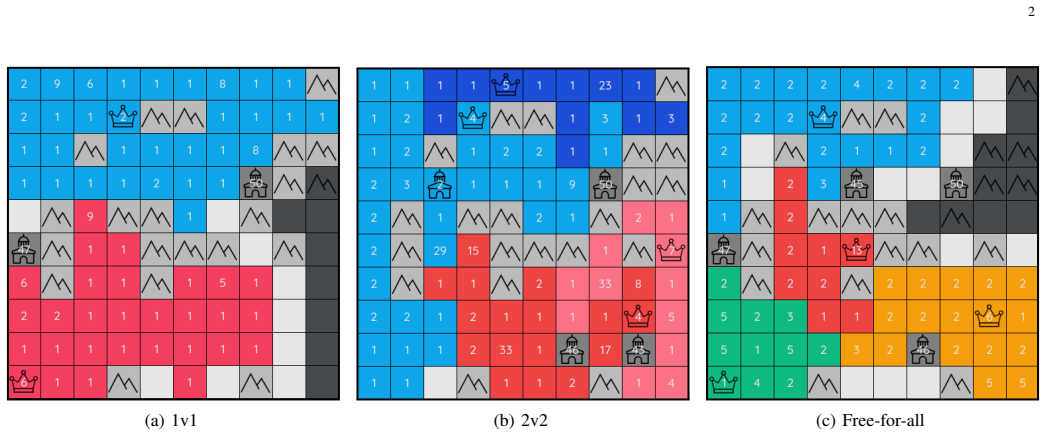
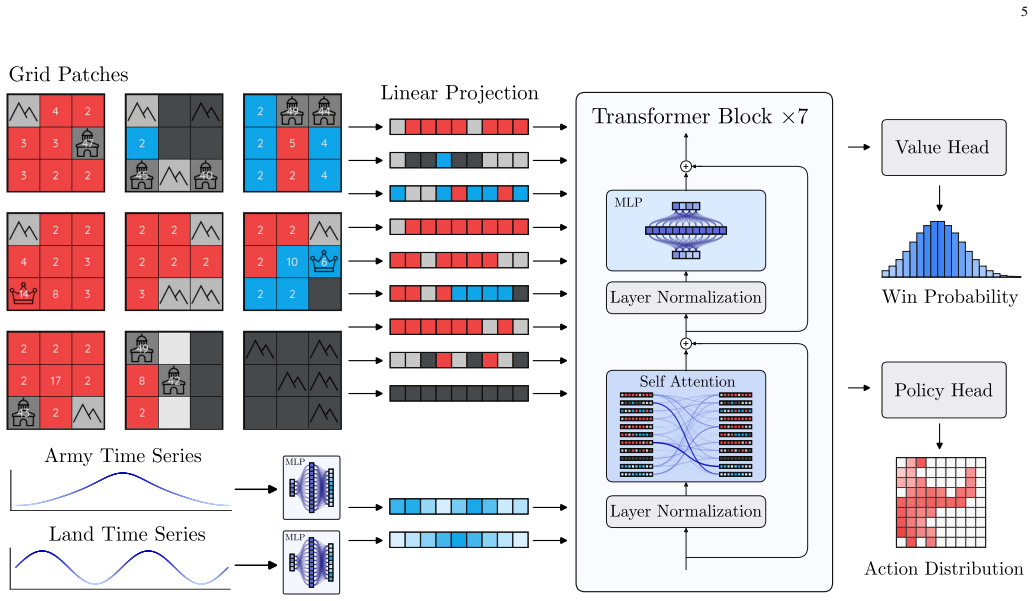
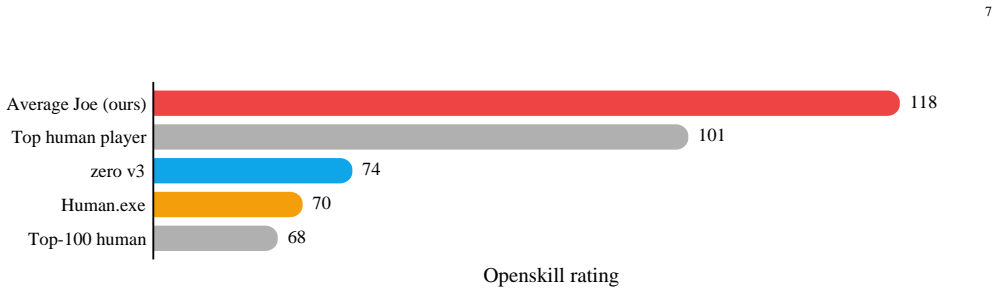
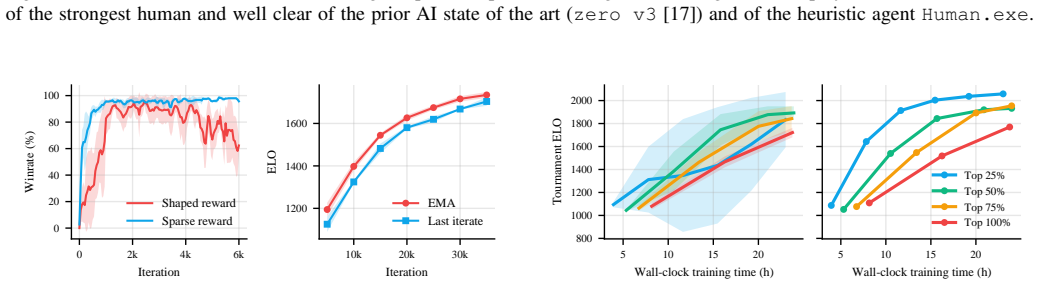
The agent reaches number one on the public 1v1 leaderboard of over five thousand human players, leading the second-ranked player by the same margin that separates second place from twenty-fifth, and records a combined 199-70 win rate against the two top-ranked humans in 269 ladder matches. Training uses a JAX-native simulator that runs roughly ten thousand times faster than the prior simulator, a vision-transformer policy, policy-gradient updates with top-advantage sample filtering, an exponential moving average of the policy, and only sparse win/loss reward.
What carries the argument
JAX-native simulator that reaches tens of millions of frames per second, paired with end-to-end self-play policy-gradient training of a vision transformer under sparse reward and top-advantage filtering.
If this is right
- Once simulation speed ceases to be the bottleneck, self-play with sparse rewards and simple filtering produces superhuman performance in a real-time strategy domain with imperfect information.
- Vision transformers can serve as effective policies for partially observable, long-horizon games when trained end-to-end.
- An exponential moving average of policy parameters combined with advantage filtering stabilizes training under sparse binary rewards.
- A 10,000-fold simulator speedup shifts research focus from data collection to which algorithmic choices actually affect final strength.
Where Pith is reading between the lines
- The same fast-simulator plus self-play recipe may transfer to other real-time strategy or imperfect-information games where human data is scarce.
- If the agent generalizes beyond the current human population, it could serve as a training partner that forces humans to discover new strategies rather than exploit known weaknesses.
- Future work could test whether the same architecture and training loop remains stable when the game rules or map pool are altered after training.
Load-bearing premise
The public leaderboard rankings and the 269 head-to-head matches against top humans provide an unbiased measure of general superhuman capability without confounds from opponent selection, rating inflation, or changes in human play over time.
What would settle it
A sustained drop below the top human ranks or a reversal to sub-.500 win rate in new matches against the same or newly adapted top human players after the agent is frozen.
Figures

read the original abstract
We present a superhuman AI agent for Generals.io, a real-time strategy game that requires both long-horizon planning and short-term tactics under strong imperfect information. Trained for four days on 4x NVIDIA H200 GPUs, our agent reaches #1 on the public 1v1 leaderboard of over 5,000 human players, leading the second-ranked player by the same margin that separates second place from 25th, and beats the two top-ranked humans head-to-head with a combined 199-70 record across 269 ladder matches. A key enabler is a JAX-native simulator that reaches tens of millions of frames per second on a single GPU, roughly a 10,000x speedup over the prior simulator. On top of this, we train a vision transformer policy end-to-end by self-play with a policy-gradient loop and sparse win/loss reward, using top-advantage sample filtering and an exponential moving average of the policy parameters. Taken together, our findings highlight what matters, and what does not, once a fast simulator removes the data bottleneck.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to train a superhuman AI agent for Generals.io via self-play reinforcement learning. It uses a JAX-native simulator providing a 10,000x speedup, a vision transformer policy trained end-to-end with policy gradients and sparse rewards, plus top-advantage filtering and EMA of parameters. After four days on 4x H200 GPUs, the agent reaches #1 on the public 1v1 leaderboard of >5,000 humans (with a large margin over #2) and records a 199-70 win record against the two top humans across 269 ladder matches.
Significance. If the human evaluation is unbiased, the result would demonstrate that self-play RL with a sufficiently fast simulator can produce superhuman performance in a real-time strategy game with long-horizon planning and imperfect information. The JAX simulator's reported speedup is a concrete engineering contribution that removes the data bottleneck and enables the training loop; this is worth highlighting as a reusable asset for similar domains.
major comments (1)
- [Abstract and Results] Abstract and Results section: The central superhuman claim rests on the public leaderboard position and the 199-70 record in 269 matches, yet the manuscript supplies no protocol describing how the agent was inserted into the live ladder, no per-opponent win-rate breakdown, and no time-series of ratings before/after insertion. These details are required to assess whether the evaluation is free of confounds from selective matchmaking, rating inflation, or human adaptation.
minor comments (1)
- [Method] The description of the top-advantage sample filtering and EMA update lacks an explicit equation or pseudocode; adding these would improve reproducibility without altering the central claim.
Simulated Author's Rebuttal
We thank the referee for the careful review and the emphasis on strengthening the evaluation details. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract and Results] Abstract and Results section: The central superhuman claim rests on the public leaderboard position and the 199-70 record in 269 matches, yet the manuscript supplies no protocol describing how the agent was inserted into the live ladder, no per-opponent win-rate breakdown, and no time-series of ratings before/after insertion. These details are required to assess whether the evaluation is free of confounds from selective matchmaking, rating inflation, or human adaptation.
Authors: We agree that these protocol details are necessary to fully substantiate the evaluation and rule out confounds. In the revised manuscript we will insert a new subsection 'Human Evaluation Protocol' under Results. It will describe (1) the exact insertion method (API-based account creation and ladder entry on the public Generals.io servers), (2) the per-opponent win-rate breakdown for the 269 matches against the two top humans, and (3) the agent's rating time-series immediately before and after insertion. These data were logged during the evaluation and will be reported to allow readers to assess stability and absence of selective matchmaking or inflation. revision: yes
Circularity Check
No significant circularity; performance claim rests on external human evaluations
full rationale
The paper's derivation chain consists of a JAX-native simulator, vision transformer policy trained end-to-end via self-play policy gradients with sparse rewards, top-advantage filtering, and EMA; none of these components are shown to reduce the reported leaderboard ranking or 199-70 head-to-head record to fitted internal quantities or self-citations by construction. The superhuman claim is validated against an external public leaderboard of over 5,000 human players and direct ladder matches, which constitute independent benchmarks outside the training loop. No self-definitional steps, fitted-input predictions, load-bearing self-citations, or uniqueness theorems imported from the authors' prior work appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mastering chess and shogi by self-play with a general reinforcement learning algorithm,
D. Silver, T. Hubert, J. Schrittwieser, I. Antonoglou, M. Lai, A. Guez, M. Lanctot, L. Sifre, D. Kumaran, T. Graepel, T. Lillicrap, K. Simonyan, and D. Hassabis, “Mastering chess and shogi by self-play with a general reinforcement learning algorithm,” 2017. [Online]. Available: https://arxiv.org/abs/1712.01815
Pith/arXiv arXiv 2017
-
[2]
DeepStack: Expert- level artificial intelligence in heads-up no-limit poker,
M. Morav ˇcík, M. Schmid, N. Burch, V . Lisý, D. Morrill, N. Bard, T. Davis, K. Waugh, M. Johanson, and M. Bowling, “DeepStack: Expert- level artificial intelligence in heads-up no-limit poker,”Science, vol. 356, pp. 508–513, 2017
2017
-
[3]
Superhuman ai for heads-up no-limit poker: Libratus beats top professionals,
N. Brown and T. Sandholm, “Superhuman ai for heads-up no-limit poker: Libratus beats top professionals,”Science, vol. 359, no. 6374, pp. 418–424, 2018
2018
-
[4]
Mastering the game of Stratego with model-free multiagent reinforcement learning,
J. Perolat, B. De Vylder, D. Hennes, E. Tarassov, F. Strub, V . de Boer, P. Muller, J. T. Connor, N. Burch, T. Anthony, S. McAleer, R. Elie, S. H. Cen, Z. Wang, A. Gruslys, A. Malysheva, M. Khan, S. Ozair, F. Timbers, T. Pohlen, T. Eccles, M. Rowland, M. Lanctot, J.-B. Lespiau, B. Piot, S. Omidshafiei, E. Lockhart, L. Sifre, N. Beauguerlange, R. Munos, D....
2022
-
[5]
Grandmaster level in StarCraft II using multi-agent reinforcement learning,
O. Vinyals, I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, R. Powell, T. Ewalds, P. Georgievet al., “Grandmaster level in StarCraft II using multi-agent reinforcement learning,”Nature, vol. 575, no. 7782, pp. 350–354, 2019
2019
-
[7]
Available: https://arxiv.org/abs/1912.06680
[Online]. Available: https://arxiv.org/abs/1912.06680
Pith/arXiv arXiv 1912
-
[9]
Available: https://arxiv.org/abs/1603.01121
[Online]. Available: https://arxiv.org/abs/1603.01121
-
[10]
Planning in the presence of cost functions controlled by an adversary,
H. B. McMahan, G. J. Gordon, and A. Blum, “Planning in the presence of cost functions controlled by an adversary,” inProceedings of the 20th International Conference on Machine Learning (ICML), 2003
2003
-
[11]
A unified game-theoretic approach to multiagent reinforcement learning,
M. Lanctot, V . Zambaldi, A. Gruslys, A. Lazaridou, K. Tuyls, J. Pérolat, D. Silver, and T. Graepel, “A unified game-theoretic approach to multiagent reinforcement learning,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[12]
Reevaluating policy gradient methods for imperfect-information games,
M. Rudolph, N. Lichtlé, S. Mohammadpour, A. Bayen, J. Z. Kolter, A. Zhang, G. Farina, E. Vinitsky, and S. Sokota, “Reevaluating policy gradient methods for imperfect-information games,”arXiv preprint arXiv:2502.08938, 2025. [Online]. Available: https://arxiv.org/abs/2502. 08938
Pith/arXiv arXiv 2025
-
[13]
Superhuman AI for Stratego using self-play reinforcement learning and test-time search,
S. Sokota, E. Vinitsky, H. Hu, J. Z. Kolter, and G. Farina, “Superhuman AI for Stratego using self-play reinforcement learning and test-time search,”arXiv preprint arXiv:2511.07312, 2025. [Online]. Available: https://arxiv.org/abs/2511.07312
arXiv 2025
-
[14]
A unified approach to rein- forcement learning, quantal response equilibria, and two-player zero- sum games,
S. Sokota, R. D’Orazio, J. Z. Kolter, N. Loizou, M. Lanctot, I. Mitliagkas, N. Brown, and C. Kroer, “A unified approach to rein- forcement learning, quantal response equilibria, and two-player zero- sum games,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[15]
Regret minimization in games with incomplete information,
M. Zinkevich, M. Johanson, M. Bowling, and C. Piccione, “Regret minimization in games with incomplete information,” inAdvances in Neural Information Processing Systems (NeurIPS), 2007
2007
-
[16]
Iterative solution of games by fictitious play,
G. W. Brown, “Iterative solution of games by fictitious play,” inActivity Analysis of Production and Allocation, T. C. Koopmans, Ed. Wiley, 1951
1951
-
[17]
Generally genius: A Generals.io agent development and data collection framework,
A. Bhatia, A. Davis, S. Ghosh, and G. Sukthankar, “Generally genius: A Generals.io agent development and data collection framework,” in Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, vol. 19, no. 1, 2023, pp. 400–406
2023
-
[18]
Hierarchical deep reinforcement learning agent with counter self-play on competitive games,
H. Xu, K. Paster, Q. Chen, H. Tang, P. Abbeel, T. Darrell, and S. Levine, “Hierarchical deep reinforcement learning agent with counter self-play on competitive games,” 2018, withdrawn ICLR 2019 submission
2018
-
[19]
Artificial generals intelligence: Mastering Generals.io with reinforcement learning,
M. Straka and M. Schmid, “Artificial generals intelligence: Mastering Generals.io with reinforcement learning,”arXiv preprint arXiv:2507.06825, 2025. [Online]. Available: https://arxiv.org/abs/2507. 06825
arXiv 2025
-
[20]
Dynamic program- ming for partially observable stochastic games,
E. A. Hansen, D. S. Bernstein, and S. Zilberstein, “Dynamic program- ming for partially observable stochastic games,” inProceedings of the AAAI Conference on Artificial Intelligence, 2004
2004
-
[21]
Proximal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017. [Online]. Available: https://arxiv.org/abs/1707.06347
Pith/arXiv arXiv 2017
-
[22]
R. S. Sutton, A. G. Bartoet al.,Reinforcement learning: An introduction. MIT press Cambridge, 1998, vol. 1, no. 1
1998
-
[23]
Stop regressing: Training value functions via classification for scalable deep rl,
J. Farebrother, J. Orbay, Q. Vuong, A. A. Taïga, Y . Chebotar, T. Xiao, A. Irpan, S. Levine, P. S. Castro, A. Faust, A. Kumar, and R. Agarwal, “Stop regressing: Training value functions via classification for scalable deep rl,” 2024. [Online]. Available: https://arxiv.org/abs/2403.03950
arXiv 2024
-
[24]
OpenSkill: A faster asymmetric multi-team, multiplayer rating system,
V . Joshy, “OpenSkill: A faster asymmetric multi-team, multiplayer rating system,”Journal of Open Source Software, vol. 9, no. 93, p. 5901, 2024. [Online]. Available: https://doi.org/10.21105/joss.05901
-
[25]
Policy invariance under reward transformations: Theory and application to reward shaping,
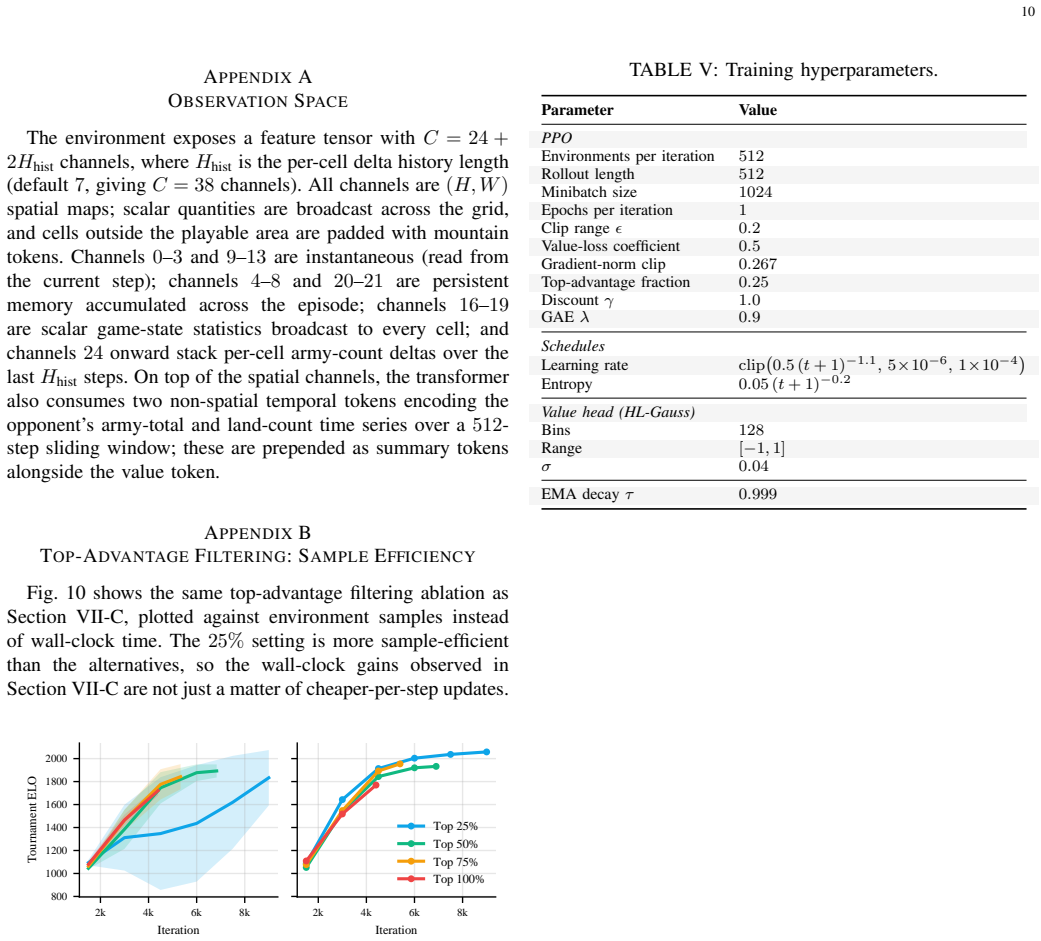
A. Y . Ng, D. Harada, and S. J. Russell, “Policy invariance under reward transformations: Theory and application to reward shaping,” in International Conference on Machine Learning, 1999. 10 APPENDIXA OBSERVATIONSPACE The environment exposes a feature tensor withC= 24 + 2Hhist channels, whereH hist is the per-cell delta history length (default7, givingC= ...
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.