SOAP-Bubbles: Structured Weight Uncertainty for Neural Networks
Pith reviewed 2026-06-26 08:58 UTC · model grok-4.3
The pith
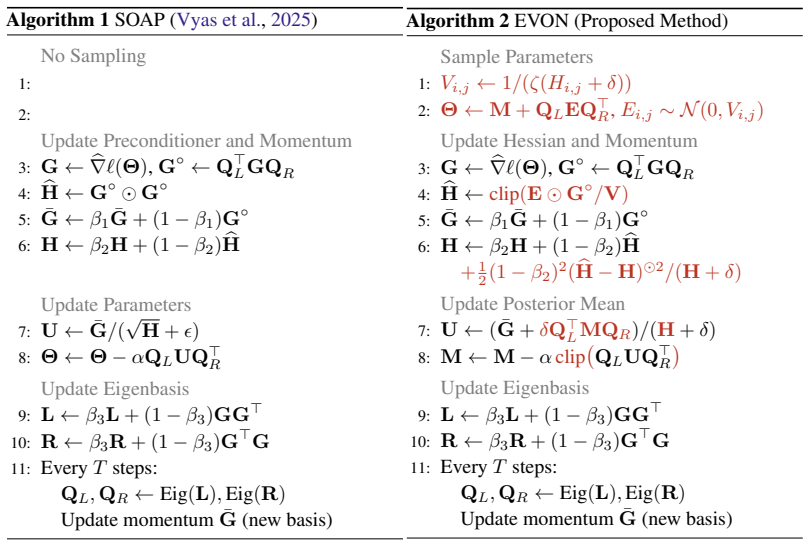
Structured non-diagonal weight uncertainty is obtained by running a diagonal variational method inside the eigenspace of SOAP's preconditioner and transforming the result back.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
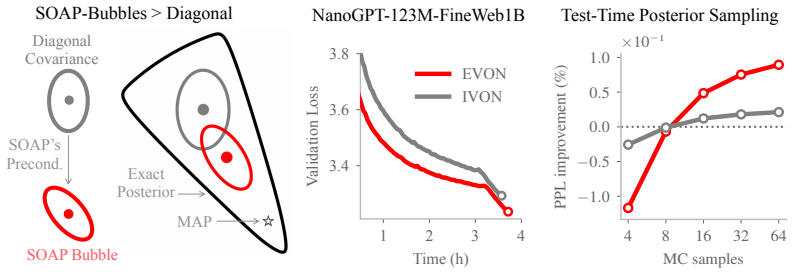
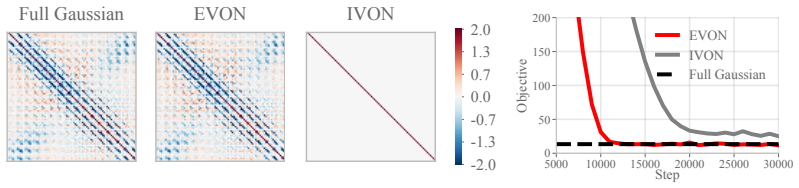
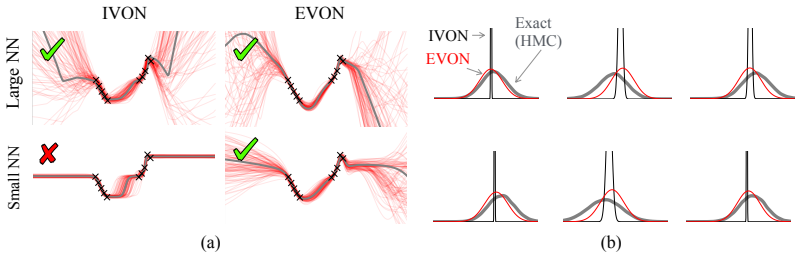
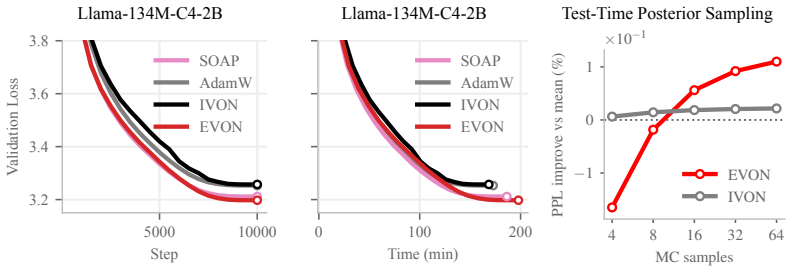
By running the diagonal-covariance variational inference method IVON inside the eigenspace defined by SOAP's preconditioner and then transforming the result back with the preconditioner, the procedure yields non-diagonal posterior covariances whose estimation cost matches that of SOAP itself. For logistic regression the recovered covariance equals the exact Gaussian posterior covariance; on language-model pretraining the same procedure produces measurably better results than existing diagonal-covariance methods.
What carries the argument
The change-of-basis that maps a diagonal covariance computed inside the eigenspace of SOAP's preconditioner back to a non-diagonal covariance in the original parameter space via multiplication by the preconditioner.
If this is right
- For logistic regression EVON recovers the exact Gaussian covariance.
- On language-model pretraining EVON outperforms existing diagonal-covariance variational methods.
- Computational cost remains comparable to that of the SOAP optimizer.
- No drastic changes to standard training pipelines are required.
Where Pith is reading between the lines
- The same eigenspace transformation could be paired with other diagonal variational methods besides IVON.
- The structured covariances may improve uncertainty-dependent downstream procedures such as pruning or active learning without raising training cost.
- Because the approach reuses an existing preconditioner, it can be inserted into current large-scale training codebases with little additional engineering.
Load-bearing premise
The eigenspace transformation must produce a covariance that remains accurate and unbiased when applied inside deep networks.
What would settle it
Exact posterior covariance computed on a small logistic-regression problem or a tiny neural net can be compared directly with the EVON estimate; a mismatch would falsify the exact-recovery claim, while the disappearance of the reported pretraining gains when the SOAP preconditioner is replaced by a purely diagonal one would test whether the non-diagonal structure is responsible for the improvement.
Figures
read the original abstract
Structured weight-uncertainty can improve many aspects of deep learning, but it remains costly to estimate and difficult to implement. Here, we show that these issues can be addressed by adapting the SOAP optimizer. Our key idea is to run IVON, an existing diagonal-covariance variational method, in the eigenspace of SOAP's preconditioner and then use the preconditioner to transform the diagonal estimate into a non-diagonal covariance. The resulting method has costs similar to those of SOAP and requires no drastic changes to training pipelines. We call the posteriors obtained in this way SOAP-Bubbles and our new optimizer Eigenspace-VON (EVON). We show that, for logistic regression, EVON recovers the exact Gaussian covariance and that, for language model pretraining, it yields significantly better results than existing diagonal-covariance methods. Our work makes it easier to estimate more expressive posterior distributions for deep learning at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SOAP-Bubbles (via the EVON optimizer) to obtain structured non-diagonal weight posteriors by running the diagonal IVON variational inference method inside the eigenspace of the SOAP preconditioner and then transforming the resulting covariance back with the preconditioner. It claims that this recovers the exact Gaussian covariance for logistic regression and yields significantly better results than existing diagonal-covariance methods on language-model pretraining, all at computational cost comparable to SOAP.
Significance. If the exact-recovery claim for logistic regression holds and the LM gains prove robust, the method would make non-diagonal posterior estimation practical at scale without major pipeline changes, addressing a key barrier in Bayesian deep learning.
major comments (2)
- [Logistic regression analysis (likely §3 or §4)] The central claim of exact Gaussian covariance recovery in logistic regression (stated in the abstract) requires an explicit derivation in the main text showing that the eigenspace transformation introduces no approximation error; without this, the reduction to the known posterior cannot be verified.
- [Language model experiments (likely §5)] The weakest assumption—that transforming the diagonal IVON estimate via the SOAP preconditioner produces an accurate non-diagonal covariance in deep networks without substantial bias—is load-bearing for the LM pretraining results but is not accompanied by error analysis or ablation on the transformation step.
minor comments (2)
- [Method overview] Notation for the preconditioner and eigenspace transformation should be introduced with explicit equations early in the method section to improve readability.
- [Introduction] The abstract and introduction should cite the original SOAP and IVON papers with precise equation references for the preconditioner and variational update.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the clarity and validation of our claims. We address each major point below and will revise the manuscript to incorporate the requested additions.
read point-by-point responses
-
Referee: The central claim of exact Gaussian covariance recovery in logistic regression (stated in the abstract) requires an explicit derivation in the main text showing that the eigenspace transformation introduces no approximation error; without this, the reduction to the known posterior cannot be verified.
Authors: We agree that an explicit derivation belongs in the main text. In the revision we will add a dedicated subsection (likely in §3) that derives the exact recovery: because the logistic regression posterior is Gaussian, IVON recovers the exact diagonal covariance in the SOAP eigenspace, and the linear transformation back by the preconditioner (which is the inverse square root of the empirical Fisher) maps this covariance exactly to the true posterior covariance without introducing approximation error. This step-by-step argument will make the reduction verifiable. revision: yes
-
Referee: The weakest assumption—that transforming the diagonal IVON estimate via the SOAP preconditioner produces an accurate non-diagonal covariance in deep networks without substantial bias—is load-bearing for the LM pretraining results but is not accompanied by error analysis or ablation on the transformation step.
Authors: We acknowledge that the transformation step is an approximation for non-linear networks and that additional validation would be beneficial. In the revised manuscript we will add (i) a short theoretical discussion of the bias induced by the diagonal assumption in the eigenspace and (ii) an ablation in §5 that reports the Frobenius distance between the transformed covariance and a reference covariance obtained by running full IVON on a smaller proxy model, together with the effect on downstream perplexity. These additions will quantify the practical accuracy of the non-diagonal covariance. revision: yes
Circularity Check
No significant circularity
full rationale
The paper constructs EVON by running the existing IVON method inside the eigenspace of the existing SOAP preconditioner and transforming the resulting diagonal covariance. For logistic regression it states that this recovers the exact Gaussian posterior; the claim is presented as following from the algebraic properties of the transformation rather than from any fitted quantity or self-citation that is itself unverified. Empirical results on language-model pretraining are reported as direct comparisons against diagonal baselines. No equation or derivation step reduces the reported recovery or performance gain to a tautology, a renamed fit, or a load-bearing self-citation whose validity depends on the present work. The central claims therefore remain independent of the inputs they are derived from.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Variational methods like IVON can be meaningfully run in a transformed eigenspace defined by a preconditioner
Reference graph
Works this paper leans on
-
[1]
Baan, J., Aziz, W., Plank, B., and Fernandez, R. (2022). Stop measuring calibration when humans disagree. In Goldberg, Y ., Kozareva, Z., and Zhang, Y ., editors,Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1892–1915, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. Bae, J., Zhang, G., and Grosse...
arXiv 2022
-
[2]
Huggins, J., Kasprzak, M., Campbell, T., and Broderick, T. (2020). Validated variational inference via practical posterior error bounds. InInternational Conference on Artificial Intelligence and Statistics (AISTATS). Immer, A., Bauer, M., Fortuin, V ., Rätsch, G., and Emtiyaz, K. M. (2021). Scalable marginal likelihood estimation for model selection in de...
arXiv 2020
-
[3]
Netzer, Y ., Wang, T., Coates, A., Bissacco, A., Wu, B., and Ng, A. Y . (2011). Reading digits in natural images with unsupervised feature learning. InNIPS workshop on deep learning and unsupervised feature learning, volume 2011, page
2011
-
[4]
Nguyen, C. V ., Li, Y ., Bui, T. D., and Turner, R. E. (2018). Variational continual learning. In International Conference on Learning Representations (ICLR). Nickl, P., Xu, L., Tailor, D., Möllenhoff, T., and Khan, M. E. (2023). The memory-perturbation equation: Understanding model’s sensitivity to data. InAdvances in Neural Information Processing System...
arXiv 2018
-
[5]
To derive EVON, we start from the variational online Newton (VON) method in Khan and Rue (2023, Eq
2023
-
[6]
Now, we apply the above VON updates to the reparametrized problem in w from Thm
For a generic Gaussian family N(θ|m,diag(s) −1) with diagonal covariance and isotropic Gaussian prior,m 0 = 0andΣ 0 =s −1 0 Ithe method reads: s←(1−ρ)s+ρ ζE q(θ)[diag(∇2ℓ(θ))] +s 0I ,(12) m←m−ρdiag(s) −1 ζE q(θ)[∇ℓ(θ)] +s 0m ,(13) whereρ >0is a learning rate. Now, we apply the above VON updates to the reparametrized problem in w from Thm. 1, which leads t...
2019
-
[7]
to write the Hessian in terms of gradients. Also using stochastic gradients, both for minibatches and the expectations, and writing h= (s ′ −s 0)/ζ, s0 =ζδ , and using short-hand notationg ◦ for the projected gradient, the above can be simplified: g← b∇ℓ(P(m′ +ϵ)),g ◦ ←P ⊤g,ϵ∼ N(ϵ|0,σ 2)(16) h←(1−ρ)h+ρg ◦ϵ/σ2,(17) m′ ←m ′ −ρdiag(h+δ) −1 (g◦ +δm ′).(18) Mu...
2025
-
[8]
Theorem 2.Assume a linear model f, loss function c, an isotropic prior and a dataset D={(x i, yi)}i=1,...,n
We restate it below for convenience. Theorem 2.Assume a linear model f, loss function c, an isotropic prior and a dataset D={(x i, yi)}i=1,...,n. If the matrices L and {xix⊤ i }i=1,...,n and the matrices R and {Eθ∼q[∇2 f c(yi, f(Θ,x i))]}i=1,...,n are simultaneously diagonalizable, then the optimal posterior q among all multivariate Gaussians is a SOAP-Bu...
2000
-
[9]
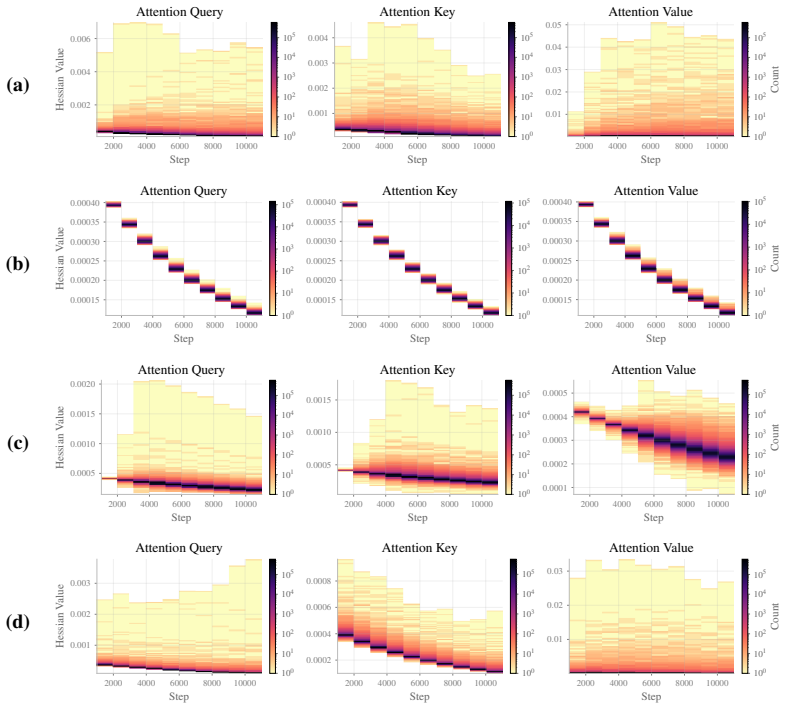
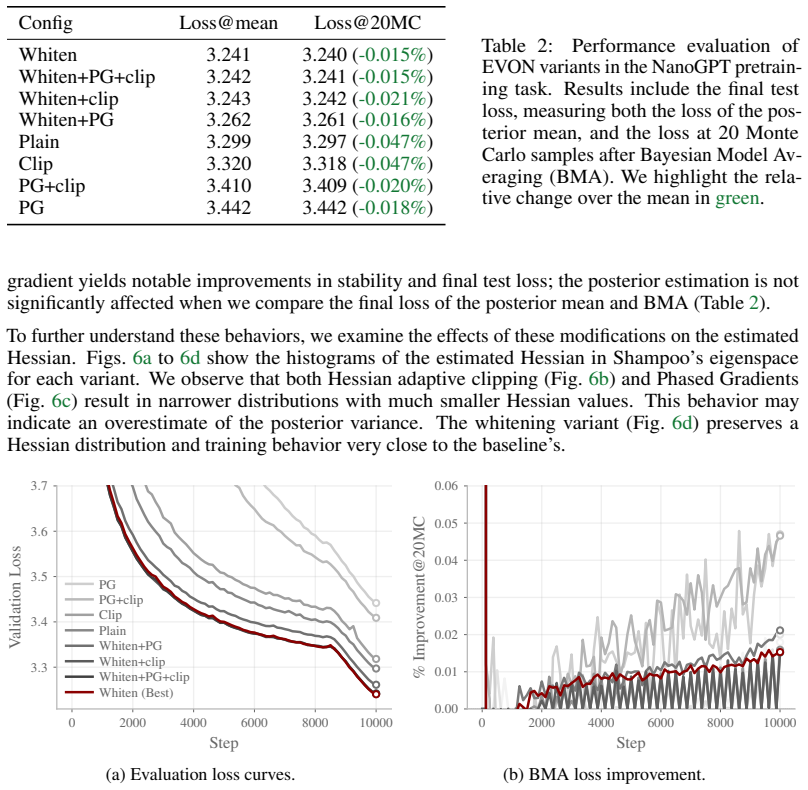
We fix the hyperparameters of the baseline optimizer and enable or disable the following components: Phased Gradients (PG), Hessian adaptive clipping (clip) with tight ratio (1.5) and preconditioned gradient Whitening (Whiten). The table presents the final test loss for each optimizer variant, and the effectiveness of the posterior is studied by performin...
2000
-
[10]
E.1 Illustrative Examples Illustrative experiment in Fig
We will release EVON as a PyTorch optimizer package and the code to reproduce all figures and tables. E.1 Illustrative Examples Illustrative experiment in Fig. 1.The experiment uses a linearly separable binary classification dataset with 2D features, from the Bayesian logistic regression chapter of Murphy (2012). Both EVON and IVON are run with small lear...
2012
-
[11]
3.We follow the setup of Mishkin et al
E.2 Bayesian Logistic Regression Experiment in Fig. 3.We follow the setup of Mishkin et al. (2018, Fig. 1), which is binary logistic regression on the USPS dataset, considering the 3vs5 classification case. We train for 30000 steps using full-batch gradients. Both IVON and EVON use elementwise clipping, EVON does not use any Hessian clipping. The hyperpar...
2018
-
[12]
23 E.3 Language Model Pretraining The experimental setup for NanoGPT (Jordan et al., 2024a) and Llama (Glentis et al.,
via the PyStan package to compute the exact posterior marginals via Hamiltonian Markov-Chain Monte Carlo (HMC) and the No-U-Turn Sampler (NUTS) (Hoffman and Gelman, 2014). 23 E.3 Language Model Pretraining The experimental setup for NanoGPT (Jordan et al., 2024a) and Llama (Glentis et al.,
2014
-
[13]
(2026, Fig
follows the experiments shown in Lin et al. (2026, Fig. 1), who provide tuned baselines and hyperparameters for AdamW and SOAP. All methods are run on a single H100 GPU with batch size
2026
-
[14]
Llama has linear warmup with cosine decay
For NanoGPT, a linear warmup, constant step size and linear cooldown is used. Llama has linear warmup with cosine decay. Both SOAP and EVON update the preconditioner every 10 steps using QR decomposition. For both experiments, EVON and IVON’s hyperparameters were tuned using equal budget of 500 runs in a random search over all hyperparameters. Both EVON a...
2026
-
[15]
E.4 CLIP Finetuning We train CLIP models on CARS (Krause et al., 2013), DTD (Describable Textures Dataset) (Cimpoi et al., 2014), EuroSAT (Helber et al., 2019), GTSRB (German Traffic Sign Recognition Benchmark) (Stallkamp et al., 2012), MNIST, RESISC45 (Cheng et al., 2017), SUN397 (Xiao et al., 2014), and SVHN (Netzer et al.,
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.