Lift4D: Harmonizing Single-View 3D Estimation for 4D Reconstruction In-the-Wild
Pith reviewed 2026-06-26 08:56 UTC · model grok-4.3
The pith
Lift4D adapts single-view 3D models via causal latent conditioning to initialize deformable 3D Gaussian Splatting for monocular 4D reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
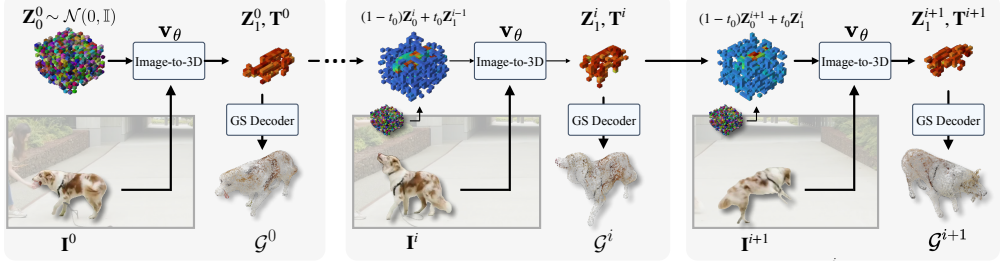
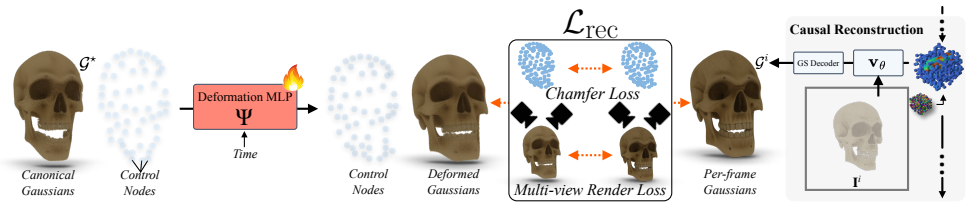
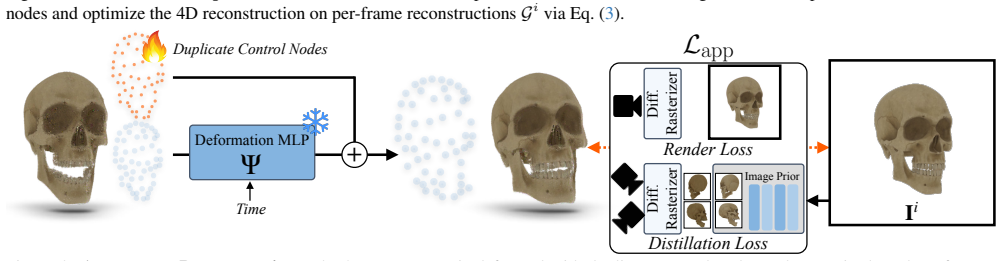
Lift4D is a test-time optimization framework that addresses both limitations of prior approaches. First, we adapt an existing single-view 3D reconstruction model to yield temporally consistent per-frame predictions via causal latent conditioning, providing a coherent initialization for a deformable 3D Gaussian Splatting representation. We then sculpt this representation to match the input video through an occlusion-aware optimization that faithfully recovers visible surface details while completing unobserved regions using a view-conditioned diffusion prior.
What carries the argument
causal latent conditioning on single-view 3D models to generate temporally consistent per-frame 3D predictions that initialize deformable 3D Gaussian Splatting optimized with occlusion-aware diffusion prior
If this is right
- Temporally consistent predictions provide coherent initialization for deformable representations.
- Occlusion-aware optimization recovers visible details and completes unobserved regions using diffusion prior.
- Improves over prior 4D reconstruction methods on in-the-wild sequences with severe occlusions and non-rigid motion.
Where Pith is reading between the lines
- The method may generalize if other single-view 3D models can be adapted with similar causal conditioning.
- Test-time sculpting with diffusion priors could apply to static 3D reconstruction tasks with partial observations.
Load-bearing premise
Adapting an existing single-view 3D reconstruction model via causal latent conditioning yields temporally consistent per-frame predictions that serve as a coherent initialization for the subsequent deformable representation.
What would settle it
Running the method on a benchmark of in-the-wild monocular videos with severe occlusions and non-rigid motion and finding no improvement in reconstruction quality metrics compared to prior methods would falsify the claim.
Figures





read the original abstract
Reconstructing dynamic non-rigid objects from monocular video requires integrating visual cues from direct observations with data-driven priors over geometry and appearance. Prior approaches either learn to directly predict 4D representations from visual input or initialize a 3D representation that is subsequently deformed and refined based on video evidence. However, the former are constrained by the scarcity of 4D training data, while the latter leverage priors only for the initial reconstruction and rely solely on video supervision thereafter; neither handles complex in-the-wild scenarios with large deformations and occlusions well. We present Lift4D, a test-time optimization framework that addresses both limitations. First, we adapt an existing single-view 3D reconstruction model to yield temporally consistent per-frame predictions via causal latent conditioning, providing a coherent initialization for a deformable 3D Gaussian Splatting representation. We then ``sculpt'' this representation to match the input video through an occlusion-aware optimization that faithfully recovers visible surface details while completing unobserved regions using a view-conditioned diffusion prior. We demonstrate that Lift4D clearly improves over prior 4D reconstruction methods, particularly on challenging in-the-wild sequences with severe occlusions and non-rigid motion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Lift4D, a test-time optimization framework for 4D reconstruction of dynamic non-rigid objects from monocular video. It first adapts an existing single-view 3D reconstruction model via causal latent conditioning to produce temporally consistent per-frame 3D predictions, which initialize a deformable 3D Gaussian Splatting representation. This is then refined through occlusion-aware optimization that recovers visible details and completes unobserved regions using a view-conditioned diffusion prior. The central claim is that Lift4D clearly improves over prior 4D reconstruction methods, especially on challenging in-the-wild sequences with severe occlusions and non-rigid motion.
Significance. If the quantitative results and ablations hold, the framework could meaningfully advance in-the-wild 4D reconstruction by effectively reusing single-view priors without requiring scarce 4D training data, while the combination of causal initialization and test-time sculpting addresses limitations of both direct 4D prediction and purely video-supervised deformation approaches.
major comments (1)
- [Abstract] Abstract: the central claim of clear improvement over prior methods rests on the adapted single-view model (via causal latent conditioning) supplying temporally consistent per-frame 3D predictions as a coherent initialization for the subsequent deformable representation and occlusion-aware optimization. No quantitative check (e.g., frame-to-frame 3D consistency metrics, variance in lifted geometry, or ablations isolating the conditioning from the diffusion prior and sculpting) is supplied to establish that this step is load-bearing; if independent per-frame lifts already suffice or the conditioning fails to reduce drift on non-rigid motion, the performance gain would be attributable to test-time optimization alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern regarding the lack of quantitative validation for the causal latent conditioning step is well-taken, and we will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of clear improvement over prior methods rests on the adapted single-view model (via causal latent conditioning) supplying temporally consistent per-frame 3D predictions as a coherent initialization for the subsequent deformable representation and occlusion-aware optimization. No quantitative check (e.g., frame-to-frame 3D consistency metrics, variance in lifted geometry, or ablations isolating the conditioning from the diffusion prior and sculpting) is supplied to establish that this step is load-bearing; if independent per-frame lifts already suffice or the conditioning fails to reduce drift on non-rigid motion, the performance gain would be attributable to test-time optimization alone.
Authors: We agree that the abstract's claim would benefit from explicit quantitative support for the contribution of causal latent conditioning. In the revised version we will add (i) frame-to-frame 3D consistency metrics (e.g., per-point variance of lifted geometry across consecutive frames) computed on the adapted single-view model with and without conditioning, and (ii) an ablation that isolates the conditioning from the subsequent diffusion prior and sculpting stages. These additions will directly test whether the conditioning reduces drift on non-rigid sequences and is load-bearing for the reported gains. We believe the overall experimental results already indicate that independent per-frame lifts are insufficient, but the requested metrics will make this explicit. revision: yes
Circularity Check
No circularity: pipeline adapts external single-view model and applies test-time optimization with independent priors
full rationale
The described derivation chain adapts a pre-existing single-view 3D reconstruction model (via causal latent conditioning) to produce per-frame predictions used as initialization for deformable 3D Gaussian Splatting, followed by occlusion-aware optimization and a view-conditioned diffusion prior. No equations, fitted parameters renamed as predictions, or self-citations are present in the abstract or described steps that would reduce any result to its own inputs by construction. The approach relies on external pretrained components and test-time sculpting rather than self-referential definitions or load-bearing self-citations, making the central claims independent of the kinds of circularity enumerated.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Recammaster: Camera-controlled generative ren- dering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative ren- dering from a single video. InProceedings of the Interna- tional Conference on Computer Vision (ICCV), 2025. 2
2025
-
[2]
Sam 3: Segment anything with concepts.arXiv, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman R¨adle, Triantafyllos Afouras, Effrosyni Mavroudi, Kather- ine Xu, Tsung-Han Wu, Yu Zhou, Lil...
2025
-
[3]
Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoub- hik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025. 5
Pith/arXiv arXiv 2025
-
[4]
Motion 3-to-4: 3d motion reconstruction for 4d synthesis.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026
Hongyuan Chen, Xingyu Chen, Youjia Zhang, Zexiang Xu, and Anpei Chen. Motion 3-to-4: 3d motion reconstruction for 4d synthesis.Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026. 2, 3
2026
-
[5]
V2m4: 4d mesh animation reconstruction from a single monocular video
Jianqi Chen, Biao Zhang, Xiangjun Tang, and Peter Wonka. V2m4: 4d mesh animation reconstruction from a single monocular video. InProceedings of the International Con- ference on Computer Vision (ICCV), 2025. 2, 3, 6, 7, 9
2025
-
[6]
Re- construct, inpaint, test-time finetune: Dynamic novel-view synthesis from monocular videos
Kaihua Chen, Tarasha Khurana, and Deva Ramanan. Re- construct, inpaint, test-time finetune: Dynamic novel-view synthesis from monocular videos. InAdvances in Neural In- formation Processing Systems (NeurIPS), 2025. 2, 3
2025
-
[7]
Easi3r: Estimating disentangled motion from dust3r without training
Xingyu Chen, Yue Chen, Yuliang Xiu, Andreas Geiger, and Anpei Chen. Easi3r: Estimating disentangled motion from dust3r without training. InProceedings of the International Conference on Computer Vision (ICCV), 2025. 2
2025
-
[8]
Dream- scene4d: Dynamic multi-object scene generation from monocular videos
Wen-Hsuan Chu, Lei Ke, and Katerina Fragkiadaki. Dream- scene4d: Dynamic multi-object scene generation from monocular videos. InAdvances in Neural Information Pro- cessing Systems (NeurIPS), 2024. 2, 3, 9
2024
-
[9]
Generative 4d scene gaussian splatting with object view-synthesis priors
Wen-Hsuan Chu, Lei Ke, Jianmeng Liu, Mingxiao Huo, Pavel Tokmakov, and Katerina Fragkiadaki. Generative 4d scene gaussian splatting with object view-synthesis priors. arXiv, 2025. 3
2025
-
[10]
Flow3r: Factored flow prediction for scalable vi- sual geometry learning
Zhongxiao Cong, Qitao Zhao, Minsik Jeon, and Shubham Tulsiani. Flow3r: Factored flow prediction for scalable vi- sual geometry learning. InProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[11]
Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Informa- tion Processing Systems (NeurIPS), 2023
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Informa- tion Processing Systems (NeurIPS), 2023. 3
2023
-
[12]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2023. 3
2023
-
[13]
Duisterhof, Zhao Mandi, Yunchao Yao, Jia- Wei Liu, Jenny Seidenschwarz, Mike Zheng Shou, Deva Ra- manan, Shuran Song, Stan Birchfield, Bowen Wen, and Jef- frey Ichnowski
Bardienus P. Duisterhof, Zhao Mandi, Yunchao Yao, Jia- Wei Liu, Jenny Seidenschwarz, Mike Zheng Shou, Deva Ra- manan, Shuran Song, Stan Birchfield, Bowen Wen, and Jef- frey Ichnowski. Deformgs: Scene flow in highly deformable scenes for deformable object manipulation. InThe 16th International Workshop on the Algorithmic Foundations of Robotics (WAFR), 2024. 2
2024
-
[14]
Black, Trevor Darrell, and Angjoo Kanazawa
Haiwen Feng, Junyi Zhang, Qianqian Wang, Yufei Ye, Pengcheng Yu, Michael J. Black, Trevor Darrell, and Angjoo Kanazawa. St4rtrack: Simultaneous 4d reconstruction and tracking in the world. InProceedings of the International Conference on Computer Vision (ICCV), 2025. 2
2025
-
[15]
Motion prompting: Controlling video generation with motion trajec- tories
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez-Guevara, Carl Doersch, Yusuf Aytar, Michael Rubinstein, Chen Sun, Oliver Wang, Andrew Owens, and Deqing Sun. Motion prompting: Controlling video generation with motion trajec- tories. InProceedings of the International Conference on Computer Vision (ICCV), 2025. 6
2025
-
[16]
Clipscore: A reference-free evaluation met- ric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation met- ric for image captioning. InConference on Empirical Meth- ods in Natural Language Processing (EMNLP), 2021. 6
2021
-
[17]
Sc-gs: Sparse-controlled gaussian splatting for editable dynamic scenes.Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
Yi-Hua Huang, Yang-Tian Sun, Ziyi Yang, Xiaoyang Lyu, Yan-Pei Cao, and Xiaojuan Qi. Sc-gs: Sparse-controlled gaussian splatting for editable dynamic scenes.Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2, 5, 13
2024
-
[18]
Consistent4d: Consistent 360° dynamic object generation from monocular video
Yanqin Jiang, Li Zhang, Jin Gao, Weiming Hu, and Yao Yao. Consistent4d: Consistent 360° dynamic object generation from monocular video. InProceedings of the International Conference on Learning Representations (ICLR), 2024. 2, 3, 7, 15
2024
-
[19]
Geo4d: Leveraging video generators for geometric 4d scene reconstruction
Zeren Jiang, Chuanxia Zheng, Iro Laina, Diane Larlus, and Andrea Vedaldi. Geo4d: Leveraging video generators for geometric 4d scene reconstruction. InProceedings of the International Conference on Computer Vision (ICCV), 2025. 2
2025
-
[20]
Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos
Linyi Jin, Richard Tucker, Zhengqi Li, David Fouhey, Noah Snavely, and Aleksander Holynski. Stereo4D: Learning How Things Move in 3D from Internet Stereo Videos. InProceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2
2025
-
[21]
Co- Tracker3: Simpler and better point tracking by pseudo- labelling real videos
Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- Tracker3: Simpler and better point tracking by pseudo- labelling real videos. InProceedings of the International Conference on Computer Vision (ICCV), 2025. 6
2025
-
[22]
Any4D: Unified feed-forward metric 4D reconstruction
Jay Karhade, Nikhil Keetha, Yuchen Zhang, Tanisha Gupta, Akash Sharma, Sebastian Scherer, and Deva Ramanan. Any4D: Unified feed-forward metric 4D reconstruction. arXiv, 2025. 2
2025
-
[23]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics (TOG), 2023. 2, 5
2023
-
[24]
Generative video motion editing with 3d point tracks
Yao-Chih Lee, Zhoutong Zhang, Jiahui Huang, Jui-Hsien Wang, Joon-Young Lee, Jia-Bin Huang, Eli Shechtman, and Zhengqi Li. Generative video motion editing with 3d point tracks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2
2025
-
[25]
Mosca: Dynamic gaussian fusion from casual videos via 4d motion scaffolds
Jiahui Lei, Yijia Weng, Adam Harley, Leonidas Guibas, and Kostas Daniilidis. Mosca: Dynamic gaussian fusion from casual videos via 4d motion scaffolds. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2025. 2
2025
-
[26]
Dreammesh4d: Video-to-4d generation with sparse-controlled gaussian- mesh hybrid representation
Zhiqi Li, Yiming Chen, and Peidong Liu. Dreammesh4d: Video-to-4d generation with sparse-controlled gaussian- mesh hybrid representation. InAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2024. 3, 6, 7
2024
-
[27]
Pad3r: Pose-aware dy- namic 3d reconstruction from casual videos
Ting-Hsuan Liao, Haowen Liu, Yiran Xu, Songwei Ge, Gengshan Yang, and Jia-Bin Huang. Pad3r: Pose-aware dy- namic 3d reconstruction from casual videos. InSIGGRAPH Asia, 2025. 2, 3, 6, 7, 9
2025
-
[28]
Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang
Haotong Lin, Sili Chen, Jun Hao Liew, Donny Y . Chen, Zhenyu Li, Yang Zhao, Sida Peng, Hengkai Guo, Xiaowei Zhou, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth any- thing 3: Recovering the visual space from any views. InPro- ceedings of the International Conference on Learning Rep- resentations (ICLR), 2026. 2, 4, 5, 6
2026
-
[29]
MoDGS: Dy- namic gaussian splatting from casually-captured monocular videos with depth priors
Qingming Liu, Yuan Liu, Jiepeng Wang, Xianqiang Lyu, Peng Wang, Wenping Wang, and Junhui Hou. MoDGS: Dy- namic gaussian splatting from casually-captured monocular videos with depth priors. InProceedings of the International Conference on Learning Representations (ICLR), 2025. 2
2025
-
[30]
Zero-1-to-3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to-3: Zero-shot one image to 3d object. InProceedings of the In- ternational Conference on Computer Vision (ICCV), 2023. 2, 4, 6, 13
2023
-
[31]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InProceedings of the International Confer- ence on Learning Representations (ICLR), 2023. 4
2023
-
[32]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProceedings of the International Confer- ence on Learning Representations (ICLR), 2019. 6
2019
-
[33]
Dynamic 3d gaussians: Tracking by per- sistent dynamic view synthesis
Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3d gaussians: Tracking by per- sistent dynamic view synthesis. InProceedings of the Inter- national Conference on 3D Vision (3DV), 2024. 2, 13
2024
-
[34]
4rc: 4d reconstruction via conditional querying anytime and anywhere.arXiv, 2026
Yihang Luo, Shangchen Zhou, Yushi Lan, Xingang Pan, and Chen Change Loy. 4rc: 4d reconstruction via conditional querying anytime and anywhere.arXiv, 2026. 2
2026
-
[35]
The 2017 davis challenge on video object segmentation.arXiv,
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alexander Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv,
2017
-
[36]
L4gm: Large 4d gaussian reconstruction model
Jiawei Ren, Kevin Xie, Ashkan Mirzaei, Hanxue Liang, Xi- aohui Zeng, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung Wook Kim, and Huan Ling. L4gm: Large 4d gaussian reconstruction model. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. 2, 3, 6, 7, 9
2024
-
[37]
Gen3c: 3d-informed world-consistent video generation with precise camera con- trol
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas M ¨uller, Alexan- der Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera con- trol. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 2, 3
2025
-
[38]
Mitra, and David Novotny
Remy Sabathier, Niloy J. Mitra, and David Novotny. Lim: Large interpolator model for dynamic reconstruction. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 3
2025
-
[39]
Mitra, and Tom Monnier
Remy Sabathier, David Novotny, Niloy J. Mitra, and Tom Monnier. Actionmesh: Animated 3d mesh generation with temporal 3d diffusion. InProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[40]
As-rigid-as-possible surface modeling
Olga Sorkine and Marc Alexa. As-rigid-as-possible surface modeling. InProceedings of Eurographics, 2007. 13
2007
-
[41]
Harley, Mikaela Uy, Florian Du- bost, Federico Tombari, Gordon Wetzstein, and Leonidas Guibas
Colton Stearns, Adam W. Harley, Mikaela Uy, Florian Du- bost, Federico Tombari, Gordon Wetzstein, and Leonidas Guibas. Dynamic gaussian marbles for novel view synthesis of casual monocular videos. InSIGGRAPH Asia, 2024. 2
2024
-
[42]
V-DPM: 4d video reconstruction with dynamic point maps.arXiv, 2026
Edgar Sucar, Eldar Insafutdinov, Zihang Lai, and Andrea Vedaldi. V-DPM: 4d video reconstruction with dynamic point maps.arXiv, 2026. 2
2026
-
[43]
Eg4d: Explicit generation of 4d object without score distil- lation
Qi Sun, Zhiyang Guo, Ziyu Wan, Jing Nathan Yan, Sheng- ming Yin, Wengang Zhou, Jing Liao, and Houqiang Li. Eg4d: Explicit generation of 4d object without score distil- lation. InICLR, 2025. 2, 3
2025
-
[44]
Sam 3d: 3dfy anything in images.arXiv, 2025
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, Aohan Lin, Jiawei Liu, Ziqi Ma, Anushka Sagar, Bowen Song, Xiaodong Wang, Jianing Yang, Bowen Zhang, Piotr Doll´ar, Georgia Gkioxari, Matt Feiszli, and Jitendra Malik. Sam 3d: 3dfy anything in images.arXiv, 2025...
2025
-
[45]
To- wards accurate generative models of video: A new metric & challenges.arXiv, 2019
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphael Marini, Marcin Michalski, and Sylvain Gelly. To- wards accurate generative models of video: A new metric & challenges.arXiv, 2019. 6
2019
-
[46]
Shape of mo- tion: 4d reconstruction from a single video
Qianqian Wang, Vickie Ye, Hang Gao, Weijia Zeng, Jake Austin, Zhengqi Li, and Angjoo Kanazawa. Shape of mo- tion: 4d reconstruction from a single video. InProceedings of the International Conference on Computer Vision (ICCV),
-
[47]
Gflow: Recovering 4d world from monocular video
Shizun Wang, Xingyi Yang, Qiuhong Shen, Zhenxiang Jiang, and Xinchao Wang. Gflow: Recovering 4d world from monocular video. InProceedings of the National Conference on Artificial Intelligence (AAAI), 2025. 2
2025
-
[48]
4d gaussian splatting for real-time dynamic scene rendering
Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene rendering. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[49]
Barron, and Aleksander Holynski
Rundi Wu, Ruiqi Gao, Ben Poole, Alex Trevithick, Changxi Zheng, Jonathan T. Barron, and Aleksander Holynski. Cat4d: Create anything in 4d with multi-view video diffu- sion models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 3
2025
-
[50]
Zijie Wu, Chaohui Yu, Yanqin Jiang, Chenjie Cao, Wang Fan, and Xiang. Bai. Sc4d: Sparse-controlled video-to-4d generation and motion transfer. InProceedings of the Eu- ropean Conference on Computer Vision (ECCV), 2024. 2, 3
2024
-
[51]
Lavr: Scene latent conditioned generative video trajectory re-rendering using large 4d reconstruction models.arXiv,
Mingyang Xie, Numair Khan, Tianfu Wang, Naina Dhin- gra, Seonghyeon Nam, Haitao Yang, Zhuo Hui, Christopher Metzler, Andrea Vedaldi, Hamed Pirsiavash, and Lei Luo. Lavr: Scene latent conditioned generative video trajectory re-rendering using large 4d reconstruction models.arXiv,
-
[52]
SV4D: Dynamic 3d content generation with multi-frame and multi-view consistency
Yiming Xie, Chun-Han Yao, Vikram V oleti, Huaizu Jiang, and Varun Jampani. SV4D: Dynamic 3d content generation with multi-frame and multi-view consistency. InProceed- ings of the International Conference on Learning Represen- tations (ICLR), 2025. 3
2025
-
[53]
Geometrycrafter: Consistent geometry estimation for open-world videos with diffusion priors
Tian-Xing Xu, Xiangjun Gao, Wenbo Hu, Xiaoyu Li, Song- Hai Zhang, and Ying Shan. Geometrycrafter: Consistent geometry estimation for open-world videos with diffusion priors. InProceedings of the International Conference on Computer Vision (ICCV), 2025. 2
2025
-
[54]
4dgt: Learning a 4d gaussian transformer using real-world monocular videos
Zhen Xu, Zhengqin Li, Zhao Dong, Xiaowei Zhou, Richard Newcombe, and Zhaoyang Lv. 4dgt: Learning a 4d gaussian transformer using real-world monocular videos. InAdvances in Neural Information Processing Systems (NeurIPS), 2025. 2
2025
-
[55]
Banmo: Build- ing animatable 3d neural models from many casual videos
Gengshan Yang, Minh V o, Natalia Neverova, Deva Ra- manan, Andrea Vedaldi, and Hanbyul Joo. Banmo: Build- ing animatable 3d neural models from many casual videos. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022. 2, 3, 6, 9
2022
-
[56]
Zhang, Zachary Manchester, and Deva Ramanan
Gengshan Yang, Shuo Yang, John Z. Zhang, Zachary Manchester, and Deva Ramanan. Physically plausible re- construction from monocular videos. InProceedings of the International Conference on Computer Vision (ICCV), 2023. 2, 3
2023
-
[57]
Deformable 3d gaussians for high- fidelity monocular dynamic scene reconstruction
Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high- fidelity monocular dynamic scene reconstruction. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 2
2024
-
[58]
SV4D2.0: Enhancing spatio-temporal consistency in multi-view video diffusion for high-quality 4d generation
Chun-Han Yao, Yiming Xie, Vikram V oleti, Huaizu Jiang, and Varun Jampani. SV4D2.0: Enhancing spatio-temporal consistency in multi-view video diffusion for high-quality 4d generation. InProceedings of the International Conference on Computer Vision (ICCV), 2025. 3
2025
-
[59]
Yeh, Peter Wonka, and Chaoyang Wang
Jiraphon Yenphraphai, Ashkan Mirzaei, Jianqi Chen, Jiaxu Zou, Sergey Tulyakov, Raymond A. Yeh, Peter Wonka, and Chaoyang Wang. Shapegen4d: Towards high quality 4d shape generation from videos. InProceedings of the In- ternational Conference on Learning Representations (ICLR),
-
[60]
Tra- jectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Tra- jectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models. InProceedings of the Interna- tional Conference on Computer Vision (ICCV), 2025. 2
2025
-
[61]
Stag4d: Spatial-temporal anchored generative 4d gaussians
Yifei Zeng, Yanqin Jiang, Siyu Zhu, Yuanxun Lu, Youtian Lin, Hao Zhu, Weiming Hu, Xun Cao, and Yao Yao. Stag4d: Spatial-temporal anchored generative 4d gaussians. InPro- ceedings of the European Conference on Computer Vision (ECCV), 2024. 3, 6, 7, 9
2024
-
[62]
Gaussian varia- tion field diffusion for high-fidelity video-to-4d synthesis
Bowen Zhang, Sicheng Xu, Chuxin Wang, Jiaolong Yang, Feng Zhao, Dong Chen, and Baining Guo. Gaussian varia- tion field diffusion for high-fidelity video-to-4d synthesis. In Proceedings of the International Conference on Computer Vision (ICCV), 2025. 3
2025
-
[63]
Barral, Raia Hadsell, Zoubin Ghahramani, Andrew Zisserman, Junlin Zhang, and Mehdi S
Chuhan Zhang, Guillaume Le Moing, Skanda Koppula, Ig- nacio Rocco, Liliane Momeni, Junyu Xie, Shuyang Sun, Rahul Sukthankar, Jo ¨elle K. Barral, Raia Hadsell, Zoubin Ghahramani, Andrew Zisserman, Junlin Zhang, and Mehdi S. M. Sajjadi. Efficiently reconstructing dynamic scenes one d4rt at a time.arXiv, 2025. 2
2025
-
[64]
4diffusion: Multi-view video dif- fusion model for 4d generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yun- hong Wang, and Yu Qiao. 4diffusion: Multi-view video dif- fusion model for 4d generation. InAdvances in Neural In- formation Processing Systems (NeurIPS), 2024. 3
2024
-
[65]
Monst3r: A simple approach for estimating ge- ometry in the presence of motion
Junyi Zhang, Charles Herrmann, Junhwa Hur, Varun Jam- pani, Trevor Darrell, Forrester Cole, Deqing Sun, and Ming- Hsuan Yang. Monst3r: A simple approach for estimating ge- ometry in the presence of motion. InProceedings of the In- ternational Conference on Learning Representations (ICLR),
-
[66]
Motion blender gaussian splatting for dynamic scene reconstruction
Xinyu Zhang, Haonan Chang, Yuhan Liu, and Abdeslam Boularias. Motion blender gaussian splatting for dynamic scene reconstruction. InConference on Robot Learning (CoRL), 2025. 2
2025
-
[67]
Sparsefusion: Distill- ing view-conditioned diffusion for 3d reconstruction
Zhizhuo Zhou and Shubham Tulsiani. Sparsefusion: Distill- ing view-conditioned diffusion for 3d reconstruction. InPro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 6 A. Supplementary We provide additional quantitative and qualitative results on an expanded dataset of in-the-wild data, as well as compar- isons to...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.