Domain-Driven Design in Practice: A Mining Study of Maintenance and Evolution in Open-Source Repositories
Pith reviewed 2026-06-26 06:54 UTC · model grok-4.3
The pith
A pre-registered mining study will collect GitHub repositories to measure how Domain-Driven Design building blocks are distributed, evolve, violate boundaries, and connect to maintenance effort.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper sets out a pre-registered plan to gather DDD-related open-source repositories from GitHub, apply automated keyword filtering followed by manual relevance assessment, and analyze the resulting corpus through four research questions that together trace the static distribution and co-usage of tactical building blocks, their longitudinal evolution across commit histories, the prevalence and maintenance consequences of Bounded Context violations, and the temporal association between maintenance events and building-block churn or violations.
What carries the argument
Four research questions that systematically examine the lifecycle of DDD tactical building blocks from initial distribution through evolution, boundary violations, and maintenance associations.
If this is right
- Data will quantify how often Entities, Aggregates, and other blocks appear together and differ across repository types.
- Commit-history analysis will show whether the blocks are added, removed, or refactored over project lifetimes.
- Measurement of Bounded Context violations will establish their frequency and any measurable effect on maintenance quality.
- Temporal correlation analysis will reveal whether spikes in maintenance work coincide with changes in building blocks or with violations.
Where Pith is reading between the lines
- The collected dataset could later be reused to test automated detectors for Bounded Context violations.
- Observed patterns might suggest concrete adjustments to DDD adoption guidelines for open-source teams.
- If the study succeeds, similar mining methods could be applied to closed-source or industry codebases for comparison.
Load-bearing premise
Keyword search on the GitHub API plus manual review will return a sufficiently large and unbiased collection of repositories that genuinely apply DDD tactics.
What would settle it
Manual relevance assessment after the initial keyword filter returning fewer than 100 repositories that actually contain DDD tactical building blocks.
Figures
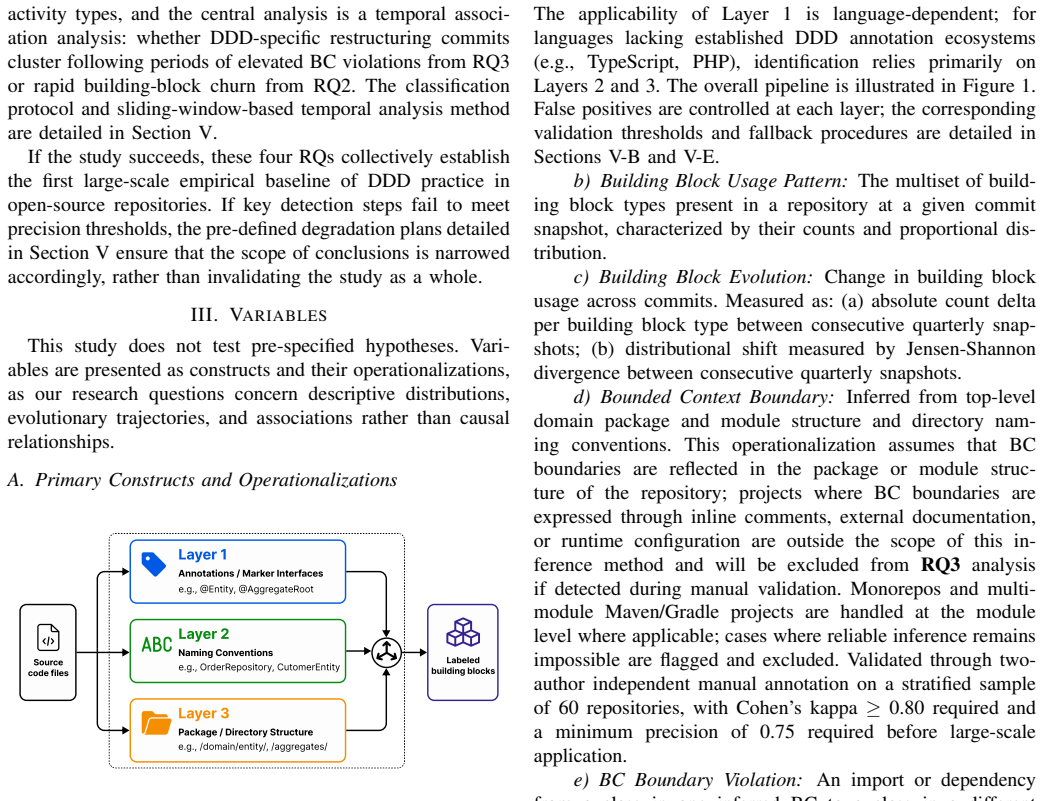
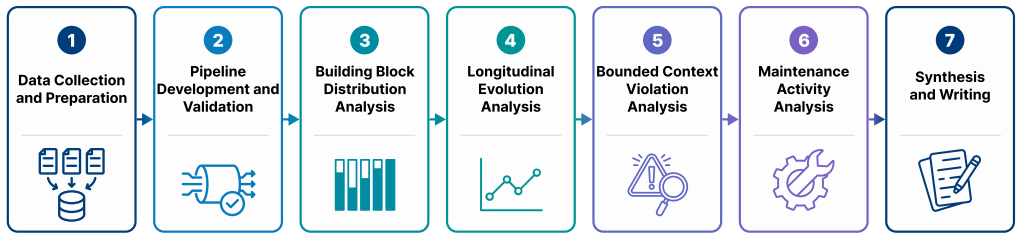
read the original abstract
Domain-Driven Design (DDD) is an influential software development methodology that structures software around business domain complexity through tactical building blocks such as Entities, Value Objects, Aggregates, and Repositories. Despite its prominence in software engineering, large-scale empirical evidence on how DDD is practiced, how it evolves, and how it relates to software maintenance quality in open-source projects remains scarce. This study presents a pre-registered empirical investigation of the distribution, evolution, and maintenance implications of DDD tactical building blocks in open-source GitHub repositories, addressing the call for large-scale empirical evaluations identified in a recent systematic literature review. We will collect DDD-related repositories from GitHub using the Search API, apply automated keyword filtering and manual relevance assessment, and analyze the resulting dataset through four research questions covering: (RQ1) the static distribution and co-usage of DDD building blocks across repository types, (RQ2) their longitudinal evolution over commit history, (RQ3) the extent and maintenance implications of Bounded Context boundary violations (the primary technical challenge in DDD adoption, unquantified at scale), and (RQ4) the temporal association between maintenance activities and building block churn or Bounded Context violations in DDD repositories. Together, these RQs trace the full maintenance and evolution lifecycle of open-source DDD projects and establish an empirical foundation for future DDD tool support and methodology refinement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This manuscript presents a pre-registered protocol for a large-scale empirical mining study of Domain-Driven Design (DDD) tactical building blocks (Entities, Value Objects, Aggregates, Repositories) in open-source GitHub repositories. Data will be collected via the GitHub Search API with automated keyword filtering and manual relevance assessment; the resulting dataset will be analyzed via four RQs on static distribution and co-usage (RQ1), longitudinal evolution over commit history (RQ2), extent and maintenance implications of Bounded Context violations (RQ3), and temporal associations between maintenance activities and building-block churn or violations (RQ4).
Significance. If executed, the study would supply the first large-scale empirical evidence on DDD practice, evolution, and maintenance links in OSS, directly addressing the gap identified in recent systematic reviews. Pre-registration is a clear strength that reduces selective reporting risk and supports reproducibility. The protocol's value hinges on whether the sampling and measurement steps can be made sufficiently concrete and unbiased.
major comments (3)
- [Abstract (data collection)] Abstract, data collection paragraph: the protocol relies on 'automated keyword filtering and manual relevance assessment' of Search API results but supplies no keyword set, no explicit inclusion/exclusion criteria for manual review, and no mitigation strategy for API result caps or missing deep-code indexing. This selection step is load-bearing for the representativeness of the sample used in every RQ.
- [Abstract (RQ3)] Abstract (RQ3): no operational definition, detection heuristic, or validation procedure is given for identifying Bounded Context boundary violations. Without a concrete, replicable method, the quantification of violations and their maintenance implications cannot be performed at scale.
- [Abstract (RQ4)] Abstract (RQ4): the temporal association between maintenance activities and building-block churn or violations is stated as an analysis goal but no metrics, time-window definitions, or statistical approach are specified, leaving the RQ unexecutable in its current form.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for greater concreteness in our pre-registered protocol. We address each major comment below and will revise the manuscript to incorporate the requested details, ensuring the protocol is fully executable and replicable.
read point-by-point responses
-
Referee: [Abstract (data collection)] Abstract, data collection paragraph: the protocol relies on 'automated keyword filtering and manual relevance assessment' of Search API results but supplies no keyword set, no explicit inclusion/exclusion criteria for manual review, and no mitigation strategy for API result caps or missing deep-code indexing. This selection step is load-bearing for the representativeness of the sample used in every RQ.
Authors: We agree that the current description is insufficiently concrete. In the revised manuscript we will add the specific keyword set, explicit inclusion criteria (e.g., repositories must contain Java or C# source files and at least one DDD-related term in README or code), exclusion criteria (e.g., forks, non-software projects, repositories with fewer than 10 stars), and a mitigation subsection addressing Search API result caps via multiple paginated queries and acknowledging potential indexing biases. revision: yes
-
Referee: [Abstract (RQ3)] Abstract (RQ3): no operational definition, detection heuristic, or validation procedure is given for identifying Bounded Context boundary violations. Without a concrete, replicable method, the quantification of violations and their maintenance implications cannot be performed at scale.
Authors: This observation is correct. The revised protocol will include an operational definition of Bounded Context violations (e.g., cross-package references or dependency violations between presumed context boundaries), a concrete detection heuristic based on static analysis of imports and class relationships, and a validation procedure using manual review of a pilot sample with inter-rater reliability metrics. These elements will be added to both the abstract and the RQ3 methods subsection. revision: yes
-
Referee: [Abstract (RQ4)] Abstract (RQ4): the temporal association between maintenance activities and building-block churn or violations is stated as an analysis goal but no metrics, time-window definitions, or statistical approach are specified, leaving the RQ unexecutable in its current form.
Authors: We accept this point. The revision will specify the metrics (churn as line additions/deletions of DDD elements; maintenance activities via commit-message classification), time windows (quarterly intervals over commit history), and statistical approach (e.g., lagged regression or survival analysis). These details will be incorporated into the abstract and the full RQ4 description. revision: yes
Circularity Check
Empirical study protocol with no derivations or fitted quantities
full rationale
The document is a pre-registered empirical mining study protocol. It outlines plans to collect GitHub repositories via Search API + keyword filtering + manual assessment, then analyze them via four RQs on distribution, evolution, Bounded Context violations, and maintenance associations. No equations, models, parameters, or first-principles derivations are present. No predictions reduce to inputs by construction, and no self-citation chains or ansatzes support any central claim. The reader's assessment of 0.0 is correct; this is the normal non-finding for a pure data-collection protocol.
Axiom & Free-Parameter Ledger
free parameters (1)
- Keyword set for DDD repository identification
axioms (2)
- domain assumption GitHub repositories identified via Search API and manual review form a representative sample of open-source DDD practice
- domain assumption Bounded Context boundary violations can be reliably detected from static code structure and commit history
Reference graph
Works this paper leans on
-
[1]
Evans,Domain-driven design: tackling complexity in the heart of software
E. Evans,Domain-driven design: tackling complexity in the heart of software. Addison-Wesley Professional, 2004
2004
-
[2]
Vernon,Implementing domain-driven design
V . Vernon,Implementing domain-driven design. Addison-Wesley, 2013
2013
-
[3]
Domain-driven design in software development: A systematic literature review on implementation, challenges, and effectiveness,
O. ¨Ozkan, ¨O. Babur, and M. van den Brand, “Domain-driven design in software development: A systematic literature review on implementation, challenges, and effectiveness,”J. Syst. Softw., vol. 230, p. 112537,
-
[4]
Available: https://doi.org/10.1016/j.jss.2025.112537
[Online]. Available: https://doi.org/10.1016/j.jss.2025.112537
-
[5]
Domain-driven design for microservices: An evidence-based investigation,
C. Zhong, S. Li, H. Huang, X. Liu, Z. Chen, Y . Zhang, and H. Zhang, “Domain-driven design for microservices: An evidence-based investigation,”IEEE Trans. Software Eng., vol. 50, no. 6, pp. 1425–1449,
-
[6]
Available: https://doi.org/10.1109/TSE.2024.3385835
[Online]. Available: https://doi.org/10.1109/TSE.2024.3385835
-
[7]
Manual abstraction in the wild: A multiple-case study on oss systems’ class diagrams and implementations,
W. Zhang, W. Zhang, D. Str ¨uber, and R. Hebig, “Manual abstraction in the wild: A multiple-case study on oss systems’ class diagrams and implementations,” in2023 ACM/IEEE 26th International Conference on Model Driven Engineering Languages and Systems (MODELS). IEEE, 2023, pp. 36–46
2023
-
[8]
An empirical study of manual abstraction between class diagrams and code of open-source systems,
W. Zhang, W. Zhang, D. Str ¨uber, and R. Hebig, “An empirical study of manual abstraction between class diagrams and code of open-source systems,”Softw. Syst. Model., vol. 24, no. 6, pp. 1797–1823, 2025. [Online]. Available: https://doi.org/10.1007/s10270-025-01289-y
-
[9]
Round-trip engineering for tactical DDD: A constraint- based vision for the masses,
W. Zhang, M. Herb, M. Armbruster, B. Jiang, M. Vielsack, and A. Koziolek, “Round-trip engineering for tactical DDD: A constraint- based vision for the masses,” inCompanion Proceedings of the 34th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ser. FSE Companion ’26. Montreal, QC, Canada: ACM, J...
2026
-
[10]
Understanding software architecture erosion: A systematic mapping study,
R. Li, P. Liang, M. Soliman, and P. Avgeriou, “Understanding software architecture erosion: A systematic mapping study,”Journal of Software: Evolution and Process, vol. 34, no. 3, p. e2423, 2022
2022
-
[11]
Mining architectural violations from version history,
C. Maffort, M. T. Valente, R. Terra, M. Bigonha, N. Anquetil, and A. Hora, “Mining architectural violations from version history,”Em- pirical Software Engineering, vol. 21, no. 3, pp. 854–895, 2016
2016
-
[12]
A systematic mapping study on architectural smells detection,
H. Mumtaz, P. Singh, and K. Blincoe, “A systematic mapping study on architectural smells detection,”Journal of Systems and Software, vol. 173, p. 110885, 2021
2021
-
[13]
Domain-driven architecture modeling and rapid prototyping with context mapper,
S. Kapferer and O. Zimmermann, “Domain-driven architecture modeling and rapid prototyping with context mapper,” inInternational Conference on Model-Driven Engineering and Software Development. Springer, 2020, pp. 250–272
2020
-
[14]
ArchUnit: A Java architecture test library,
TNG Technology Consulting GmbH, “ArchUnit: A Java architecture test library,” https://github.com/TNG/ArchUnit, 2017, accessed: 2026-06-07
2017
-
[15]
jMolecules: Libraries to help developers express architectural abstractions in Java code,
xMolecules Contributors, “jMolecules: Libraries to help developers express architectural abstractions in Java code,” 2021, accessed: 2025- 05-02. [Online]. Available: https://github.com/xmolecules/jmolecules
2021
-
[16]
@Repository annotation — Spring Framework 7.0.x JavaDoc API,
VMware, Inc., “@Repository annotation — Spring Framework 7.0.x JavaDoc API,” 2025, accessed: 2025-05-02. [Online]. Avail- able: https://docs.spring.io/spring-framework/docs/current/javadoc-api/ org/springframework/stereotype/Repository.html
2025
-
[17]
E. Kalliamvakou, G. Gousios, K. Blincoe, L. Singer, D. M. Germ ´an, and D. E. Damian, “The promises and perils of mining github,” in 11th Working Conference on Mining Software Repositories, MSR 2014, Proceedings, May 31 - June 1, 2014, Hyderabad, India, P. T. Devanbu, S. Kim, and M. Pinzger, Eds. ACM, 2014, pp. 92–101. [Online]. Available: https://doi.org...
-
[18]
Tales from 1002 repositories: Development and evolution of xtext-based dsls on github,
W. Zhang and D. Struber, “Tales from 1002 repositories: Development and evolution of xtext-based dsls on github,” in2024 50th Euromi- cro Conference on Software Engineering and Advanced Applications (SEAA). IEEE, 2024, pp. 172–179
2024
-
[19]
Development and evolution of xtext-based dsls on github: an empirical investigation,
W. Zhang, D. Str ¨uber, and R. Hebig, “Development and evolution of xtext-based dsls on github: an empirical investigation,”Empirical Software Engineering, vol. 31, no. 3, p. 48, 2026
2026
-
[20]
Forking without clicking: on how to identify software repository forks,
A. Pietri, G. Rousseau, and S. Zacchiroli, “Forking without clicking: on how to identify software repository forks,” inProceedings of the 17th international conference on mining software repositories, 2020, pp. 277–287
2020
-
[21]
JavaParser: Java 1–21 parser and abstract syntax tree for Java,
JavaParser Contributors, “JavaParser: Java 1–21 parser and abstract syntax tree for Java,” 2013, accessed: 2025-05-02. [Online]. Available: https://github.com/javaparser/javaparser
2013
-
[22]
Roslyn: The .NET compiler platform,
Microsoft, “Roslyn: The .NET compiler platform,” 2014, accessed: 2025-05-02. [Online]. Available: https://github.com/dotnet/roslyn
2014
-
[23]
Using the TypeScript compiler API,
——, “Using the TypeScript compiler API,” 2015, accessed: 2025-05-
2015
-
[24]
Available: https://github.com/microsoft/TypeScript/wiki/ Using-the-Compiler-API
[Online]. Available: https://github.com/microsoft/TypeScript/wiki/ Using-the-Compiler-API
-
[25]
Pydriller: Python framework for mining software repositories,
D. Spadini, M. F. Aniche, and A. Bacchelli, “Pydriller: Python framework for mining software repositories,” inProceedings of the 2018 ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2018, Lake Buena Vista, FL, USA, November 04-09, 2018, G. T. Leavens, A. Garcia, and C...
arXiv 2018
-
[26]
Use of ranks in one-criterion variance analysis,
W. H. Kruskal and W. A. Wallis, “Use of ranks in one-criterion variance analysis,”Journal of the American statistical Association, vol. 47, no. 260, pp. 583–621, 1952
1952
-
[27]
Multiple significance tests: the bonfer- roni method,
J. M. Bland and D. G. Altman, “Multiple significance tests: the bonfer- roni method,”Bmj, vol. 310, no. 6973, p. 170, 1995
1995
-
[28]
Multiple comparisons using rank sums,
O. J. Dunn, “Multiple comparisons using rank sums,”Technometrics, vol. 6, no. 3, pp. 241–252, 1964
1964
-
[29]
The proof and measurement of association between two things
C. Spearman, “The proof and measurement of association between two things.” 1961
1961
-
[30]
Divergence measures based on the shannon entropy,
J. Lin, “Divergence measures based on the shannon entropy,”IEEE Transactions on Information theory, vol. 37, no. 1, pp. 145–151, 2002
2002
-
[31]
B. P. Lientz and E. B. Swanson,Software maintenance management. Addison-Wesley Longman Publishing Co., Inc., 1980
1980
-
[32]
Mining the temporal evolution of the android bug reporting community via sliding windows,
F. Jiang, J. Wang, A. Hindle, and M. A. Nascimento, “Mining the temporal evolution of the android bug reporting community via sliding windows,”arXiv preprint arXiv:1310.7469, 2013. The 42nd IEEE International Conference on Software Maintenance and Evolution (ICSME 2026) – Registered Reports
Pith/arXiv arXiv 2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.