Low-rank Updates in Slowly Time-varying Graphs for Spatial-Temporal Signal Interpolation
Pith reviewed 2026-06-26 06:19 UTC · model grok-4.3
The pith
Modeling the difference between consecutive adjacency matrices as low-rank enables joint optimization of the signal and the evolving graph for better interpolation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given an initial adjacency matrix at time t=1, the method jointly recovers the signal at t=2 and the new adjacency matrix by alternating between solving a linear system for the signal under the graph smoothness prior and performing proximal gradient steps on the graph under the low-rank prior on their difference; the proximal mapping is approximated in linear time by selecting a sparse combination of eigenvector outer products via orthogonal matching pursuit.
What carries the argument
The low-rank prior on the difference matrix P = W^(2) - W^(1), whose proximal mapping is approximated by fast orthogonal matching pursuit over a dictionary of outer products formed from the eigenvectors of W^(1).
If this is right
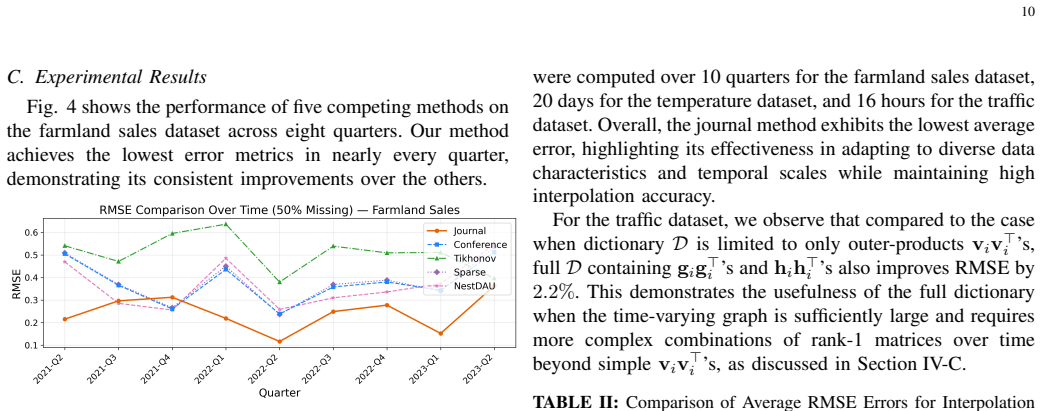
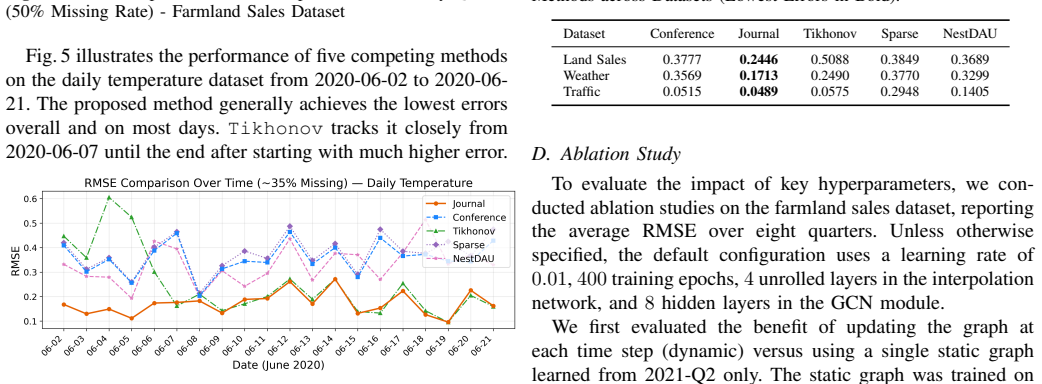
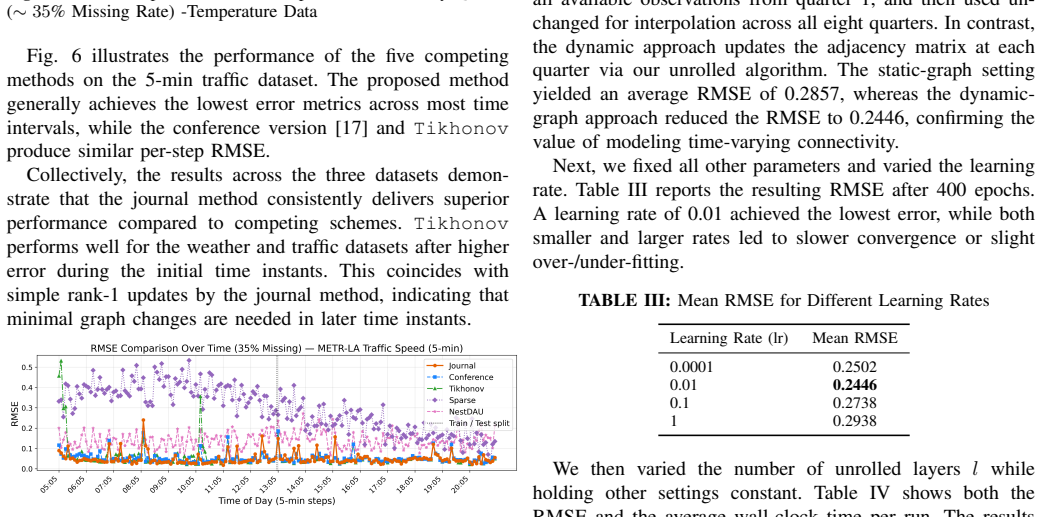
- The alternating scheme produces more accurate interpolated signals than methods that treat the graph as fixed or update it separately.
- The orthogonal matching pursuit approximation reduces the cost of each proximal step to linear time in the number of nodes.
- Unrolling the iterations yields a compact neural network that tunes a small number of parameters from limited training examples.
- The low-rank model directly encodes the slow-variation assumption without requiring a parametric form for the entire graph sequence.
Where Pith is reading between the lines
- Sequential application of the two-time-step update could handle longer time series by propagating the estimated graph forward.
- The same low-rank difference model might be inserted into other graph signal tasks such as denoising or semi-supervised learning on slowly evolving networks.
- If real sensor or traffic data exhibit low-rank adjacency changes, the approach could lower the sample complexity of graph learning compared with full-matrix estimation.
Load-bearing premise
The change between two consecutive adjacency matrices can be captured well by a low-rank matrix.
What would settle it
A controlled test in which the true graph difference is constructed to be full-rank and the joint method shows no accuracy gain or a clear loss relative to separate estimation baselines.
Figures


read the original abstract
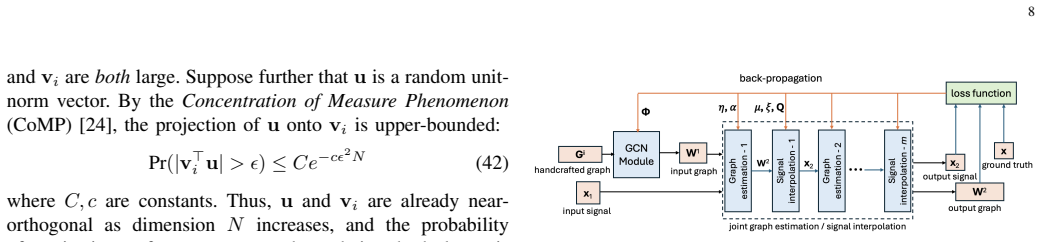
A crucial assumption in graph signal processing (GSP) is the existence of an underlying graph that captures the pairwise similarities between nodes, allowing filters to be designed based on this graph for tasks such as denoising. For spatial-temporal data in which node-to-node similarities evolve over time, a static spatial graph is insufficient. In this paper, to represent slowly time-varying pairwise relationships, we model the graph changes in two consecutive adjacency matrices $P = W^{(2)} - W^{(1)}$ across time as a low-rank matrix. % Specifically, given an initial adjacency matrix $W^{(1)}$ at time $t=1$, we jointly interpolate a signal $x_2$ and estimate $W^{(2)}$ at $t=2$ using both a graph signal smoothness prior for $x_2$ and a low-rank prior on $\P$. We alternate optimization steps. With $W^{(2)}$ fixed, $x_2$ is interpolated by solving a linear system. Alternatively, holding $x_2$ fixed, $W^{(2)}$ is updated via proximal gradient descent (PGD). The proximal mapping of the rank term $Gamma(W^{(2)} - W^{(1)})$ is approximated in linear time using a fast orthogonal matching pursuit (OMP) algorithm that selects a sparse combination of atoms from a dictionary $cR$ formed by the outer products of $W^{(1)}$'s eigenvectors. We unroll iterations of our algorithm into layers to build a lightweight neural network for limited data-driven parameter tuning. Experiments show that our joint optimization achieves better signal interpolation compared to existing time-varying graph models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes modeling the difference P = W^(2) - W^(1) between consecutive adjacency matrices in slowly time-varying graphs as low-rank. It develops an alternating optimization procedure that interpolates the signal x_2 via a linear system (with W^(2) fixed) and updates W^(2) via proximal gradient descent whose rank proximal operator is approximated in linear time by OMP on a dictionary of outer products of W^(1) eigenvectors. The iterations are unrolled into a lightweight neural network; experiments are claimed to show improved signal interpolation relative to existing time-varying graph models.
Significance. If the low-rank modeling of graph evolution is appropriate for the target data and the performance gains are shown to arise from this prior rather than other factors, the approach would supply a computationally attractive, interpretable mechanism for dynamic-graph signal processing. The OMP-based proximal step and the unrolling into a lightweight network are concrete engineering strengths that could aid deployment under limited data.
major comments (2)
- [Experiments section] The low-rank prior on P is load-bearing for both the objective and the proximal-gradient step, yet the manuscript supplies no diagnostic (singular-value decay plots of estimated P matrices, comparison of OMP rank-k reconstructions, or ablation removing the rank term) confirming that the assumption holds on the experimental data. Without this evidence the performance gains cannot be attributed to the proposed modeling choice.
- [Experiments section] §4 (or equivalent experimental section): the superiority claim is stated without quantitative metrics, baseline descriptions, error bars, or statistical tests, and without reporting the accuracy of the OMP approximation relative to exact proximal mapping. These omissions leave the central empirical claim unsupported.
minor comments (2)
- [Abstract] Notation for the OMP dictionary is rendered as cR; clarify whether this is a calligraphic R or a different symbol.
- [Method section] The description of the alternating scheme would benefit from an explicit algorithm box listing the two sub-problems and the stopping criterion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the experimental validation.
read point-by-point responses
-
Referee: [Experiments section] The low-rank prior on P is load-bearing for both the objective and the proximal-gradient step, yet the manuscript supplies no diagnostic (singular-value decay plots of estimated P matrices, comparison of OMP rank-k reconstructions, or ablation removing the rank term) confirming that the assumption holds on the experimental data. Without this evidence the performance gains cannot be attributed to the proposed modeling choice.
Authors: We agree that explicit diagnostics are needed to support attribution of gains to the low-rank model. In the revised manuscript we will add singular-value decay plots of the estimated P matrices on the experimental datasets together with an ablation that removes the rank penalty term, allowing direct assessment of whether the low-rank assumption holds for the data. revision: yes
-
Referee: [Experiments section] §4 (or equivalent experimental section): the superiority claim is stated without quantitative metrics, baseline descriptions, error bars, or statistical tests, and without reporting the accuracy of the OMP approximation relative to exact proximal mapping. These omissions leave the central empirical claim unsupported.
Authors: We acknowledge the need for more rigorous quantitative reporting. The revised experimental section will include mean-squared-error metrics with error bars, full baseline descriptions, statistical significance tests, and a direct comparison of OMP approximation error versus the exact proximal mapping on the same data. revision: yes
Circularity Check
No significant circularity; modeling assumption is explicit input
full rationale
The paper introduces a low-rank prior on P = W^(2) - W^(1) as an explicit modeling choice to represent slowly time-varying graphs. It then applies standard alternating minimization (linear system solve for x_2 with W^(2) fixed; proximal gradient descent for W^(2) with OMP approximation of the rank proximal operator) and unrolls the iterations into a network for parameter tuning. None of these steps reduce a claimed prediction or result to the inputs by construction; the low-rank assumption is not derived from the optimization but supplied as a prior, and the algorithmic components are external standard methods. No self-citations or fitted quantities renamed as predictions appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The change matrix P = W^(2) - W^(1) is low-rank for slowly time-varying pairwise relationships
Reference graph
Works this paper leans on
-
[1]
Graph signal processing: Overview, challenges, and appli- cations,
A. Ortega, P. Frossard, J. Kovacevic, J. M. F. Moura, and P. Van- dergheynst, “Graph signal processing: Overview, challenges, and appli- cations,”Proceedings of the IEEE, vol. 106, no. 5, pp. 808–828, 2018
2018
-
[2]
Graph spectral image processing,
G. Cheung, E. Magli, Y . Tanaka, and M. K. Ng, “Graph spectral image processing,”Proceedings of the IEEE, vol. 106, no. 5, pp. 907–930, 2018
2018
-
[3]
Topology identi- fication and learning over graphs: Accounting for nonlinearities and dynamics,
G. B. Giannakis, Y . Shen, and G. V . Karanikolas, “Topology identi- fication and learning over graphs: Accounting for nonlinearities and dynamics,”Proceedings of the IEEE, vol. 106, no. 5, pp. 787–807, 2018
2018
-
[4]
Learning graphs from data: A signal representation perspective,
X. Dong, D. Thanou, M. Rabbat, and P. Frossard, “Learning graphs from data: A signal representation perspective,”IEEE Signal Processing Magazine, vol. 36, no. 3, pp. 44–63, 2019
2019
-
[5]
Signed graph metric learning via Gershgorin disc perfect alignment,
C. Yang, G. Cheung, and W. Hu, “Signed graph metric learning via Gershgorin disc perfect alignment,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 7219–7234, 2022
2022
-
[6]
Efficient signed graph sampling via balancing & Gershgorin disc perfect alignment,
C. Dinesh, G. Cheung, S. Bagheri, and I. V . Baji ´c, “Efficient signed graph sampling via balancing & Gershgorin disc perfect alignment,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 4, pp. 2330–2348, 2025
2025
-
[7]
Graph Laplacian regularization for image denoising: Analysis in the continuous domain,
J. Pang and G. Cheung, “Graph Laplacian regularization for image denoising: Analysis in the continuous domain,”IEEE Transactions on Image Processing, vol. 26, no. 4, pp. 1770–1785, 2017
2017
-
[8]
Random walk graph Laplacian based smoothness prior for soft decoding of JPEG images,
X. Liu, G. Cheung, X. Wu, and D. Zhao, “Random walk graph Laplacian based smoothness prior for soft decoding of JPEG images,”IEEE Transactions on Image Processing, vol. 26, no.2, pp. 509–524, February 2017
2017
-
[9]
Manifold graph signal restoration using gradient graph Laplacian regularizer,
F. Chen, G. Cheung, and X. Zhang, “Manifold graph signal restoration using gradient graph Laplacian regularizer,”IEEE Transactions on Signal Processing, vol. 72, pp. 744–761, 2024. 13
2024
-
[10]
Crop yield estimation model for iowa using remote sensing and surface parameters,
A. K. Prasad, L. B. Chai, R. P. Singh, and M. C. Kafatos, “Crop yield estimation model for iowa using remote sensing and surface parameters,”International Journal of Applied Earth Observation and Geoinformation, vol. 8, pp. 26–33, 2006
2006
-
[11]
Crop Yield Predictions - High Resolution Statistical Model for Intra- season Forecasts Applied to Corn in the US,
Y . Cai, A. Elhaddad, J. Lessel, C. Townsend, Y . Zhao, and N. Semret, “Crop Yield Predictions - High Resolution Statistical Model for Intra- season Forecasts Applied to Corn in the US,” inAGU Fall Meeting Abstracts, vol. 2017, Dec. 2017, pp. GC31G–07
2017
-
[12]
Time-varying graph learning based on sparseness of temporal variation,
K. Yamada, Y . Tanaka, and A. Ortega, “Time-varying graph learning based on sparseness of temporal variation,” inICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019, pp. 5411–5415
2019
-
[13]
Learning time varying graphs,
V . Kalofolias, A. Loukas, D. Thanou, and P. Frossard, “Learning time varying graphs,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 2826–2830
2017
-
[14]
Incremental singular value decomposition algorithms for highly scalable recommender sys- tems,
B. Sarwar, G. Karypis, J. Konstan, and J. Riedl, “Incremental singular value decomposition algorithms for highly scalable recommender sys- tems,” inProceedings of the 5th International Conference on Computer and Information Science (ICIS). International Association for Computer and Information Science, 2002, pp. 27–28
2002
-
[15]
Colibri: Fast mining of large static and dynamic graphs,
H. Tong, S. Papadimitriou, J. Sun, P. S. Yu, and C. Faloutsos, “Colibri: Fast mining of large static and dynamic graphs,” inProceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ser. KDD ’08. New York, NY , USA: Association for Computing Machinery, 2008, p. 686–694
2008
-
[16]
Low-rank sparse decomposition of graph adjacency matrices for extracting clean clusters,
T. Kanada, M. Onuki, and Y . Tanaka, “Low-rank sparse decomposition of graph adjacency matrices for extracting clean clusters,” in2018 Asia- Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 2018, pp. 1153–1159
2018
-
[17]
Joint signal inter- polation / time-varying graph estimation via smoothness and low-rank priors,
S. Bagheri, G. Cheung, T. Eadie, and A. Ortega, “Joint signal inter- polation / time-varying graph estimation via smoothness and low-rank priors,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 9646– 9650
2024
-
[18]
On the eigen-functions of dynamic graphs: Fast tracking and attribution algorithms: Eigen-functions of dynamic graphs,
C. Chen and H. Tong, “On the eigen-functions of dynamic graphs: Fast tracking and attribution algorithms: Eigen-functions of dynamic graphs,” Statistical Analysis and Data Mining: The ASA Data Science Journal, vol. 10, 06 2016
2016
-
[19]
Attributed network embedding for learning in a dynamic environment,
J. Li, H. Dani, X. Hu, J. Tang, Y . Chang, and H. Liu, “Attributed network embedding for learning in a dynamic environment,” inProceedings of the 2017 ACM on Conference on Information and Knowledge Manage- ment. ACM, nov 2017
2017
-
[20]
Grarep: Learning graph representations with global structural information,
S. Cao, W. Lu, and Q. Xu, “Grarep: Learning graph representations with global structural information,” inProceedings of the 24th ACM Inter- national on Conference on Information and Knowledge Management, ser. CIKM ’15. New York, NY , USA: Association for Computing Machinery, 2015, p. 891–900
2015
-
[21]
Robust principal component analysis?
E. J. Cand `es, X. Li, Y . Ma, and J. Wright, “Robust principal component analysis?”J. ACM, vol. 58, no. 3, Jun. 2011
2011
-
[22]
Fast DCT+: A family of fast transforms based on rank-one updates of the path graph,
S. F. Mendui ˜na, E. Pavez, and A. Ortega, “Fast DCT+: A family of fast transforms based on rank-one updates of the path graph,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[23]
Power and centrality: A family of measures,
P. Bonacich, “Power and centrality: A family of measures,”American Journal of Sociology, vol. 92, no. 5, pp. 1170–1182, 1987
1987
-
[24]
Ledoux,The Concentration of Measure Phenomenon, ser
M. Ledoux,The Concentration of Measure Phenomenon, ser. Mathemat- ical Surveys and Monographs. Providence, RI: American Mathematical Society, 2001, vol. 89
2001
-
[25]
Graph-based blind image deblurring from a single photograph,
Y . Bai, G. Cheung, X. Liu, and W. Gao, “Graph-based blind image deblurring from a single photograph,”IEEE Transactions on Image Processing, vol. 28, no. 3, pp. 1404–1418, 2019
2019
-
[26]
Proximal algorithms,
N. Parikh and S. Boyd, “Proximal algorithms,” inFoundations and Trends in Optimization, vol. 1, no.3, 2013, pp. 123–231
2013
-
[27]
Greed is good: Algorithmic results for sparse approxima- tion,
J. A. Tropp, “Greed is good: Algorithmic results for sparse approxima- tion,”IEEE Transactions on Information Theory, vol. 50, no. 10, pp. 2231–2242, 2004
2004
-
[28]
Learning time-varying graphs from online data,
A. Natali, E. Isufi, M. Coutino, and G. Leus, “Learning time-varying graphs from online data,”IEEE Open Journal of Signal Processing, vol. 3, pp. 212–228, 2022
2022
-
[29]
Network topology inference with sparsity and laplacian constraints,
J. Ying, X. Han, R. Zhou, X. Wang, and H. C. So, “Network topology inference with sparsity and laplacian constraints,” in2023 IEEE 11th International Conference on Information, Communication and Networks (ICICN), 2023, pp. 283–288
2023
-
[30]
Spatio-temporal graph convolutional net- works: a deep learning framework for traffic forecasting,
B. Yu, H. Yin, and Z. Zhu, “Spatio-temporal graph convolutional net- works: a deep learning framework for traffic forecasting,” inProceedings of the 27th International Joint Conference on Artificial Intelligence, ser. IJCAI’18. AAAI Press, 2018, p. 3634–3640
2018
-
[31]
T-GCN: A temporal graph convolutional network for traffic prediction,
L. Zhao, Y . Song, C. Zhang, Y . Liu, P. Wang, T. Lin, M. Deng, and H. Li, “T-GCN: A temporal graph convolutional network for traffic prediction,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 9, pp. 3848–3858, 2020
2020
-
[32]
GMAN: A graph multi-attention network for traffic prediction,
C. Zheng, X. Fan, C. Wang, and J. Qi, “GMAN: A graph multi-attention network for traffic prediction,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 01, 2020, pp. 1234–1241
2020
-
[33]
Dynamic graph convolutional networks,
F. Manessi, A. Rozza, and M. Manzo, “Dynamic graph convolutional networks,”Pattern Recognition, vol. 97, p. 107000, Jan. 2020
2020
-
[34]
Predicting path failure in time-evolving graphs,
J. Li, Z. Han, H. Cheng, J. Su, P. Wang, J. Zhang, and L. Pan, “Predicting path failure in time-evolving graphs,” inProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD ’19. New York, NY , USA: Association for Computing Machinery, 2019, p. 1279–1289
2019
-
[35]
DynGEM: Deep embedding method for dynamic graphs,
P. Goyal, N. Kamra, X. He, and Y . Liu, “DynGEM: Deep embedding method for dynamic graphs,” 05 2018
2018
-
[36]
Lifelong graph learning,
C. Wang, Y . Qiu, D. Gao, and S. Scherer, “Lifelong graph learning,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2022, pp. 13 709–13 718
2022
-
[37]
Overcoming catastrophic forgetting in graph neural networks with experience replay,
F. Zhou and C. Cao, “Overcoming catastrophic forgetting in graph neural networks with experience replay,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 4714–4722, 05 2021
2021
-
[38]
Hierarchical attention prototypical networks for few-shot text classification,
S. Sun, Q. Sun, K. Zhou, and T. Lv, “Hierarchical attention prototypical networks for few-shot text classification,” 01 2019, pp. 476–485
2019
-
[39]
Dual constrained TV-based regularization on graphs,
C. Couprie, L. Grady, L. Najman, J.-C. Pesquet, and H. Talbot, “Dual constrained TV-based regularization on graphs,” vol. 6, no. 3, 2013
2013
-
[40]
Graph signal recovery via primal- dual algorithms for total variation minimization,
P. Berger, G. Hannak, and G. Matz, “Graph signal recovery via primal- dual algorithms for total variation minimization,”IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 6, pp. 842–855, 2017
2017
-
[41]
Deep graph Laplacian regularization for robust denoising of real images,
J. Zeng, J. Pang, W. Sun, and G. Cheung, “Deep graph Laplacian regularization for robust denoising of real images,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2019, pp. 1759–1768
2019
-
[42]
Unrolling of deep graph total variation for image denoising,
H. Vu, G. Cheung, and Y . C. Eldar, “Unrolling of deep graph total variation for image denoising,” inIEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, Canada, June 2017
2017
-
[43]
Un- rolling graph total variation for light field image denoising,
R. Yoshida, K. Kodama, H. Vu, G. Cheung, and T. Hamamoto, “Un- rolling graph total variation for light field image denoising,” in2022 IEEE International Conference on Image Processing (ICIP), 2022, pp. 2162–2166
2022
-
[44]
Graph signal restoration using nested deep algorithm unrolling,
M. Nagahama, K. Yamada, Y . Tanaka, S. H. Chan, and Y . C. Eldar, “Graph signal restoration using nested deep algorithm unrolling,”IEEE Transactions on Signal Processing, vol. 70, pp. 3296–3311, 2022
2022
-
[45]
Interpretable lightweight transformer via unrolling of learned graph smoothness priors,
T. Thuc, P. Eftekhar, S. A. Hosseini, G. Cheung, and P. A. Chou, “Interpretable lightweight transformer via unrolling of learned graph smoothness priors,” inAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, Eds., vol. 37. Curran Associates, Inc., 2024, pp. 6393–6416
2024
-
[46]
An introduction to the conjugate gradient method without the agonizing pain,
J. R. Shewchuk, “An introduction to the conjugate gradient method without the agonizing pain,” USA, Tech. Rep., 1994
1994
-
[47]
Sparse inverse covariance estimation with the graphical lasso,
J. Friedman, T. Hastie, and R. Tibshirani, “Sparse inverse covariance estimation with the graphical lasso,” inBiostatistics, vol. 9, no.3, 2008, pp. 432–441
2008
-
[48]
A constrainedℓ1 minimization approach to sparse precision matrix estimation,
W. L. Tony Cai and X. Luo, “A constrainedℓ1 minimization approach to sparse precision matrix estimation,”Journal of the American Statistical Association, vol. 106, no. 494, pp. 594–607, 2011
2011
-
[49]
Cauchy and the spectral theory of matrices,
T. Hawkins, “Cauchy and the spectral theory of matrices,”Historia Mathematica, vol. 2, no. 1, pp. 1–29, 1975
1975
-
[50]
Toward the optimal preconditioned eigensolver: Locally optimal block preconditioned conjugate gradient method,
A. V . Knyazev, “Toward the optimal preconditioned eigensolver: Locally optimal block preconditioned conjugate gradient method,” SIAM Journal on Scientific Computing, vol. 23, no. 2, pp. 517–541,
-
[51]
[Online]. Available: https://doi.org/10.1137/S1064827500366124
-
[52]
R. A. Horn and C. R. Johnson,Matrix Analysis, 2nd ed. Cambridge University Press, 2012
2012
-
[53]
Semi-supervised classification with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” inInternational Conference on Learning Representations, 2017. [Online]. Available: https://openreview.net/ forum?id=SJU4ayYgl
2017
-
[54]
A comprehensive survey on graph neural networks,
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and P. S. Yu, “A comprehensive survey on graph neural networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 1, p. 4–24, Jan. 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.