Can Language Model Agents be Helpful Circuit Explainers in Mechanistic Interpretability?
Pith reviewed 2026-06-26 00:45 UTC · model grok-4.3
The pith
LM agents can produce useful explanations for identified transformer circuits via iterative hypothesis and validation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
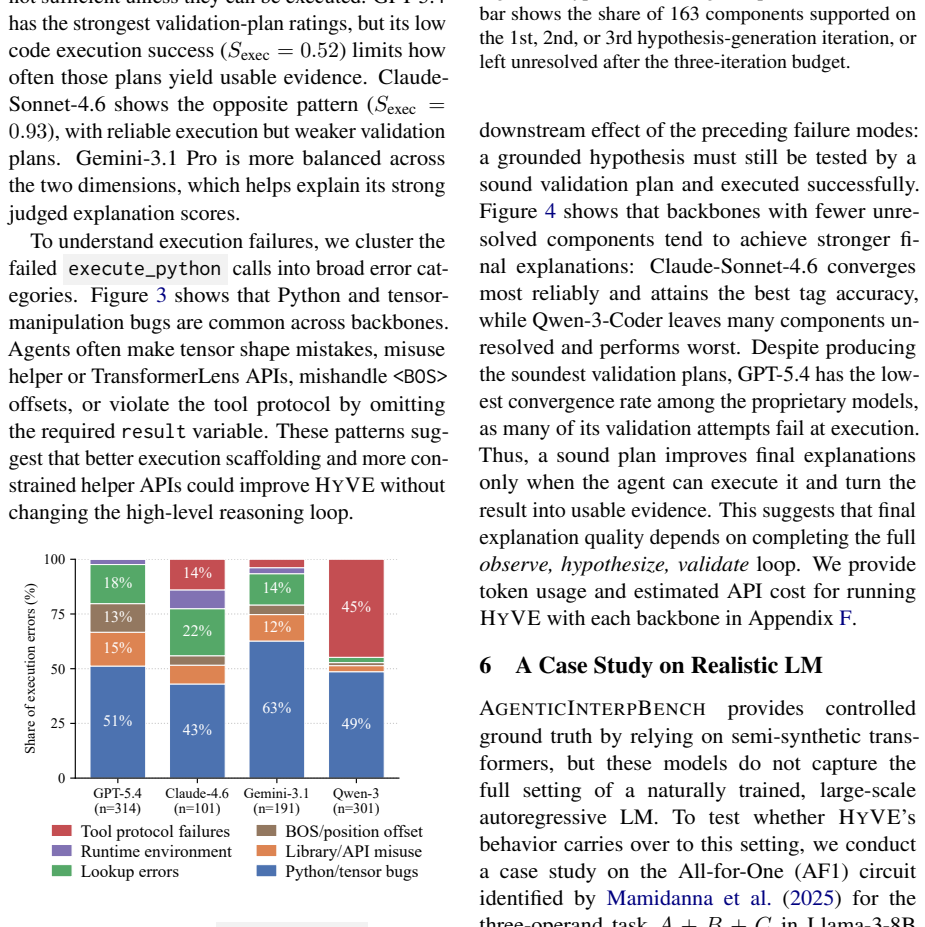
HyVE recovers useful component-level explanations and circuit-level task descriptions from the benchmark by running an iterative loop of observation, hypothesis generation, and causal validation for each component; the same loop extends to a real arithmetic circuit in Llama-3-8B, though no single backbone dominates and validation remains the main failure point.
What carries the argument
HyVE (Hypothesize, Validate, Explain) agentic explainer that processes each circuit component through repeated cycles of observation, hypothesis generation, and causal validation before emitting a component explanation and circuit task description.
If this is right
- LM agents can reduce the manual labor of turning localized circuits into human-readable descriptions.
- Stronger backbones tend to produce observation-grounded hypotheses, while later validation steps determine overall success.
- The same agent loop can be applied directly to circuits found in models such as Llama-3-8B.
- Reliable validation planning and code execution are the primary remaining obstacles to consistent performance.
Where Pith is reading between the lines
- Improving the validation stage with better causal testing tools could raise success rates without changing the backbone.
- The benchmark could be extended with circuits that contain known failure modes such as superposition or polysemanticity to test robustness.
- If HyVE-style agents scale, they might be combined with automated circuit discovery methods to create end-to-end interpretability pipelines.
Load-bearing premise
The 84 semi-synthetic circuits and 163 annotations capture the main difficulties that appear when explaining circuits inside naturally trained models.
What would settle it
Run HyVE on a larger set of circuits extracted from naturally trained models and compare the generated explanations against independent human expert annotations; systematic mismatch would falsify the claim that the benchmark and method transfer.
Figures



read the original abstract
Mechanistic interpretability has made substantial progress in automatically localizing circuits, but explaining what localized components do remains labor-intensive and difficult to standardize. In this work, we study whether language model (LM) agents can assist with this explanation problem once a circuit has already been identified. We introduce AgenticInterpBench, a benchmark for circuit explanation built from 84 semi-synthetic transformer circuits with 163 component-level annotations. We propose HyVE (Hypothesize, Validate, Explain), an agentic explainer that analyzes each component through an iterative loop of observation, hypothesis generation, and causal validation, eventually producing a component-level explanation and a circuit-level task description. Across four LM backbones, HyVE recovers useful component- and task-level explanations, but no backbone is uniformly best. Our analysis shows that strong backbones usually form observation-grounded hypotheses, while failures more often arise later in the validation loop, through incomplete validation plans, code execution errors, or unresolved hypotheses. A case study on an arithmetic circuit in Llama-3-8B shows that the same formulation can extend beyond semi-synthetic benchmarks to naturally trained models. Overall, LM agents are promising circuit explainers, but reliable validation remains the key obstacle.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that language model agents can assist with explaining already-localized circuits in mechanistic interpretability. It introduces AgenticInterpBench (84 semi-synthetic transformer circuits with 163 component-level annotations), proposes the HyVE agent (iterative Hypothesize-Validate-Explain loop), evaluates it across four LM backbones, reports that useful component- and task-level explanations are recovered (with no backbone uniformly best), analyzes failure modes in the validation loop, and includes a qualitative case study extending the approach to an arithmetic circuit in naturally trained Llama-3-8B.
Significance. If the central claim holds, this work would establish a promising direction for automating the explanation stage of circuit analysis, addressing a key scalability bottleneck in mechanistic interpretability. The new benchmark and the breakdown of where agents succeed or fail (observation-grounded hypotheses vs. incomplete validation) would provide concrete starting points for future agent designs. The case study, even if preliminary, signals potential transfer beyond synthetic settings.
major comments (2)
- [Evaluation] Evaluation section: the central claim that HyVE 'recovers useful component- and task-level explanations' across four backbones is not supported by any quantitative metrics, baseline comparisons, inter-annotator agreement, or statistical tests. Without these, the data-to-claim link cannot be verified.
- [Case study] Case study section: the claim of extension beyond semi-synthetic benchmarks rests on a single qualitative example in Llama-3-8B. This does not quantify whether validation failures, hypothesis grounding, or explanation fidelity degrade when confronting superposition, polysemantic neurons, or training-induced correlations typical of natural circuits.
minor comments (1)
- [Benchmark construction] The criteria used to judge an explanation as 'useful' (and how the 163 annotations were produced) should be stated explicitly, including any rubrics or agreement procedures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central claim that HyVE 'recovers useful component- and task-level explanations' across four backbones is not supported by any quantitative metrics, baseline comparisons, inter-annotator agreement, or statistical tests. Without these, the data-to-claim link cannot be verified.
Authors: We agree that the evaluation would be strengthened by explicit quantitative metrics. The current manuscript relies on qualitative assessment against the 163 component annotations and detailed failure-mode categorization, but lacks direct numerical scores or baselines. In revision we will add: (1) component-level explanation fidelity as the fraction of annotations recovered by the final HyVE output, (2) per-backbone success rates for completing the validation loop without unresolved hypotheses, (3) a simple non-iterative baseline (direct prompting), and (4) inter-annotator agreement on a subset of human judgments together with statistical comparisons where appropriate. These metrics will be reported in a revised Evaluation section. revision: yes
-
Referee: [Case study] Case study section: the claim of extension beyond semi-synthetic benchmarks rests on a single qualitative example in Llama-3-8B. This does not quantify whether validation failures, hypothesis grounding, or explanation fidelity degrade when confronting superposition, polysemantic neurons, or training-induced correlations typical of natural circuits.
Authors: We concur that the case study is a single qualitative example and does not quantify degradation relative to the semi-synthetic setting. We will revise the text to frame the case study explicitly as a preliminary proof-of-concept rather than a comparative evaluation, and we will add a paragraph discussing the expected additional difficulties (superposition, polysemanticity, training correlations) as open challenges for future work. Because expanding to multiple natural circuits would require new circuit-localization effort outside the scope of the present benchmark, we treat this as a limitation rather than a claim of quantified transfer. revision: partial
Circularity Check
No circularity: empirical evaluation on newly introduced benchmark with no self-referential reductions
full rationale
The paper introduces AgenticInterpBench (84 semi-synthetic circuits, 163 annotations) and HyVE agent, then reports empirical success rates across LM backbones plus one qualitative Llama-3-8B case study. No equations, parameter fits, or derivations appear in the provided text. No self-citations are invoked as load-bearing uniqueness theorems. Success metrics are direct performance measures on the benchmark rather than quantities defined or fitted inside the same loop. This matches the default non-circular case for new-benchmark empirical papers; the skeptic concern about semi-synthetic vs. natural circuits is a generalizability issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Javier Ferrando, Gabriele Sarti, Arianna Bisazza, and Marta R
Towards automated circuit discovery for mech- anistic interpretability.Advances in Neural Informa- tion Processing Systems, 36:16318–16352. Javier Ferrando, Gabriele Sarti, Arianna Bisazza, and Marta R. Costa-jussà. 2024. A primer on the in- ner workings of transformer-based language models. Preprint, arXiv:2405.00208. Atticus Geiger, Zhengxuan Wu, Hanson...
-
[2]
Michael Hanna, Sandro Pezzelle, and Yonatan Be- linkov
How does gpt-2 compute greater-than?: In- terpreting mathematical abilities in a pre-trained lan- guage model.Preprint, arXiv:2305.00586. Michael Hanna, Sandro Pezzelle, and Yonatan Be- linkov. 2024. Have faith in faithfulness: Going be- yond circuit overlap when finding model mechanisms. Preprint, arXiv:2403.17806. 9 Subhash Kantamneni and Max Tegmark. 2...
-
[3]
LLM Evaluators Recognize and Favor Their Own Generations
Llm evaluators recognize and favor their own generations.Preprint, arXiv:2404.13076. Gonçalo Paulo, Alex Mallen, Caden Juang, and Nora Belrose. 2024. Automatically Interpreting Millions of Features in Large Language Models.arXiv e- prints, arXiv:2410.13928. Qwen. 2025. Qwen3 technical report.Preprint, arXiv:2505.09388. Daking Rai, Yilun Zhou, Shi Feng, Ab...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Thinking like transformers.Preprint, arXiv:2106.06981. Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shen- gran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. 2025. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search. arXiv preprint arXiv:2504.08066. 10 A Prompt Templates In this section, we include the templ...
-
[5]
See the Task Information below for input- output examples
Task:The model performs a sequence-processing task. See the Task Information below for input- output examples
-
[6]
3.Localized components:{ALL_COMPONENTS} 4.Target component:{COMPONENT_IDENTIFIER}
Target model:A decoder-only transformer with {NUM_LAYERS} layers, {NUM_HEADS} atten- tion heads per layer, and an MLP sublayer in each block. 3.Localized components:{ALL_COMPONENTS} 4.Target component:{COMPONENT_IDENTIFIER}
-
[7]
Your goal is to explain the functional role of the target component within this circuit
Component Localization:The listed components have been identified as causally relevant to the task. Your goal is to explain the functional role of the target component within this circuit
-
[8]
7.Iterative Workflow: (a) Observation:Gather descriptive evidence about the behavior and activation patterns of COMPONENT_IDENTIFIER using the avail- able analysis tools
Previously validated components: {VALIDATED}. 7.Iterative Workflow: (a) Observation:Gather descriptive evidence about the behavior and activation patterns of COMPONENT_IDENTIFIER using the avail- able analysis tools. (b) Hypothesis Generation:Propose a hy- pothesis about the functional role of COMPONENT_IDENTIFIER, grounded in your observations. (c) Hypot...
-
[9]
Do not include ablations or causal interven- tions
The plan must be purely descriptive and observa- tional. Do not include ablations or causal interven- tions
-
[10]
After this step, Python code will be generated directly from this plan
Be concrete and implementable. After this step, Python code will be generated directly from this plan
-
[11]
OBSERVATION PLAN for {COMPONENT_IDENTIFIER}
Keep each field concise, using 1-3 sentences. Analysis tools are available in the execution environment and will be discovered during code execution. Respond with a JSON object containing exactly the following fields, and do not include any text outside the JSON: •stage : "OBSERVATION PLAN for {COMPONENT_IDENTIFIER}" •goal : what aspect of the component s...
-
[12]
Call list_directory() to discover available helper files
-
[13]
Read the file most relevant to the observation plan to learn the available function signatures
-
[14]
The code must implement the observation plan, assign all outputs to a dictionary namedresult
Generate executable Python code for the observa- tion and call execute_python . The code must implement the observation plan, assign all outputs to a dictionary namedresult. Each execute_python call runs in a fresh subprocess. Variables, imports, and state do not persist across calls. Every call must be self-contained. Do not perform causal interventions....
-
[15]
Do not contradict observed evidence
Your hypothesis must be grounded in the prior observation. Do not contradict observed evidence
-
[16]
If previous hypotheses were refuted, explicitly ad- dress why they failed and constrain the new pro- posal accordingly
-
[17]
A good hypothesis specifies: (a) what the compo- nent computes, (b) which input positions or tokens it operates on, and (c) what it contributes down- stream
-
[18]
we hypothesize that
Use language that reflects a testable claim, such as “we hypothesize that . . . ” Respond with a JSON object containing exactly the fol- lowing fields, and do not include any text outside the JSON: •hypothesis : the proposed hypothesis about the functional role of{COMPONENT_IDENTIFIER}. •reasoning : 1-3 sentences explaining why the hy- pothesis is consist...
-
[19]
Appropriate methods include activation patching, mean ablation, interchange intervention etc
The experiment must be causal or interventional. Appropriate methods include activation patching, mean ablation, interchange intervention etc
-
[20]
The expected result should follow logically from what the hypothesis predicts
The plan must be directly motivated by the hypoth- esis. The expected result should follow logically from what the hypothesis predicts
-
[21]
In the next step, Python code will be generated directly from this plan
Be concrete and implementable. In the next step, Python code will be generated directly from this plan
-
[22]
VALIDATION PLAN for COMPONENT_IDENTIFIER
Keep each field concise, using 1-3 sentences. Respond with a JSON object containing exactly the fol- lowing fields, and do not include any text outside the JSON: •stage : "VALIDATION PLAN for COMPONENT_IDENTIFIER" •goal : the specific prediction of the hypothesis being tested. •procedure : a short list of concrete experimental steps. •inputs : the model t...
-
[23]
Call list_directory() to discover available helper files with template code
-
[24]
Helper functions are already defined in the execution environment and should be called directly, without import statements
Read the file most relevant to the validation task to learn the available causal-intervention function signatures. Helper functions are already defined in the execution environment and should be called directly, without import statements
-
[25]
The code must implement the validation plan, assign all outputs to a dictionary namedresult
Generate executable Python code for validating the hypothesis and call execute_python . The code must implement the validation plan, assign all outputs to a dictionary namedresult. Each execute_python call runs in a fresh subprocess; variables, imports, and state do not persist across calls. Every call must be self-contained. The experiment must include a...
-
[26]
Assign exactly one tag to each component based on the validated hypothesis and the taxonomy def- initions
-
[27]
When tags overlap, choose based on the compo- nent’s functional input-output behavior
-
[28]
Write a concise one-sentence description of what the component does in the context of this specific task
-
[29]
Ground the description in the hypothesis, not in the generic taxonomy definition
-
[30]
Respond with a JSON object containing one entry for each component
Do not output anything outside the JSON. Respond with a JSON object containing one entry for each component. Each entry should contain exactly two fields: •tag : one of INDICATOR, AGGREGATOR, ROUTER, MAPPER, orCOMBINER. •description : a one-sentence task-specific role description. A.6 Summarization Stage Circuit Summarization Prompt You are in theCircuit ...
-
[31]
Synthesize a coherent account of how information flows through the localized circuit and what task is being implemented
-
[32]
Describe the computational stages and the explicit interactions between components
-
[33]
If the mechanisms conflict with the examples, prioritize the examples
Infer the underlying task using both the input- output examples and the validated component mechanisms. If the mechanisms conflict with the examples, prioritize the examples
-
[34]
Do not include these checks in the final output
Before finalizing the derived task description, check it against at least two input-output examples at non-boundary positions and revise if needed. Do not include these checks in the final output
-
[35]
x").named(
Write the derived task description as a concise task specification. Do not copy example values, or restate component-level operations. Respond with a valid JSON object containing the fol- lowing fields, and do not include any text outside the JSON: 13 •information_flow : 1-2 sentences describing the sequential dependencies among components. •derived_task_...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.