Breaking the Filter Bubble: A Semantic Pareto-DQN Framework for Multi-Objective Recommendation
Pith reviewed 2026-06-26 00:42 UTC · model grok-4.3
The pith
A Pareto-DQN framework treats engagement, diversity, and fairness as separate rewards to map the recommendation Pareto frontier.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
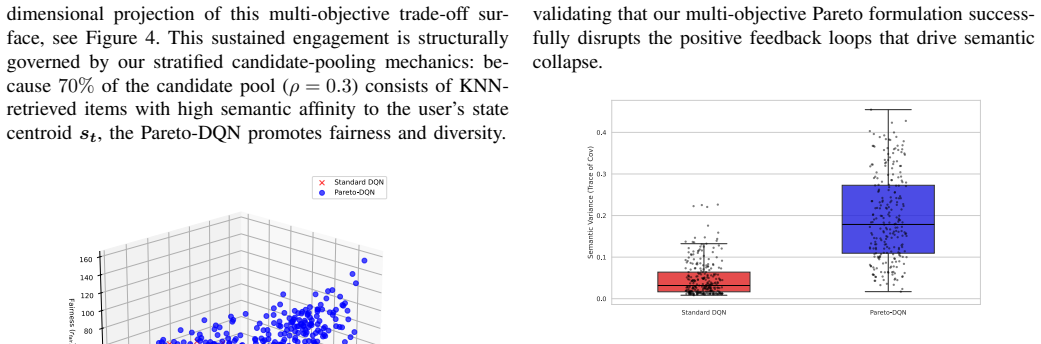
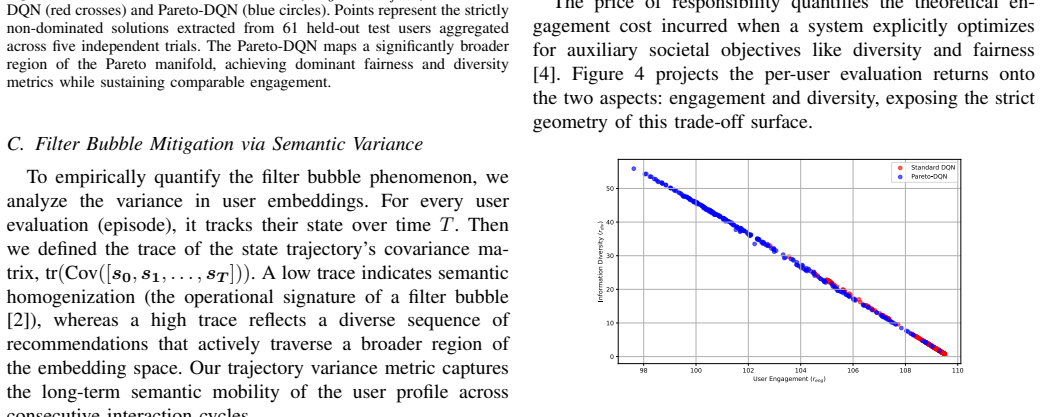
By integrating high-fidelity semantic embeddings with a Pareto-DQN agent in a semantic multi-objective Markov decision process, the framework treats engagement, diversity, and fairness as distinct reward signals. Hypervolume-based action selection disrupts the feedback loops responsible for semantic collapse. The Pareto-DQN sustains high state-trajectory variance to effectively map the Pareto frontier, achieving gains in auxiliary societal objectives with only marginal impacts on engagement.
What carries the argument
Pareto-DQN agent with hypervolume-based action selection that navigates non-aggregable multi-objective rewards in a semantic MDP.
If this is right
- Recommender systems can achieve information diversity and provider fairness alongside engagement without reward scalarization.
- Disrupting semantic collapse feedback loops becomes possible through maintained state-trajectory variance.
- Multi-objective RL provides a path to responsible recommender systems that balance platform and societal goals.
- Empirical results on MovieLens confirm the feasibility of mapping the Pareto frontier in recommendation tasks.
Where Pith is reading between the lines
- The method may extend to other recommendation domains like news or products where filter bubbles are a concern.
- Future work could explore scaling the approach to larger datasets or online A/B testing.
- Semantic embeddings appear central, so improvements in embedding quality could further enhance performance.
- Similar multi-objective setups might apply to other sequential decision problems with conflicting societal objectives.
Load-bearing premise
That integrating high-fidelity semantic embeddings with a Pareto-DQN agent and using hypervolume-based action selection will disrupt feedback loops responsible for semantic collapse without requiring reward scalarization.
What would settle it
A direct comparison on the MovieLens dataset where a standard scalarized DQN achieves comparable or better diversity and fairness metrics than the Pareto-DQN while maintaining engagement levels.
Figures

read the original abstract
Recommender systems often induce filter bubbles and semantic homogenization by monolithically optimizing for immediate user engagement. Standard single-objective models, including traditional Deep Q-Networks, are ill-equipped to navigate the trade-offs between platform retention and critical societal values like information diversity and provider fairness. To address these limitations, we introduce a multi-objective reinforcement learning framework that formalizes recommendation as a semantic multi-objective Markov decision process. By integrating high-fidelity semantic embeddings with a Pareto-DQN agent, our architecture treats engagement, diversity, and fairness as distinct, non-aggregable reward signals, avoiding the pitfalls of static reward scalarization. Empirical evaluations on the MovieLens small dataset shows that our hypervolume based action selection disrupts the feedback loops responsible for semantic collapse. By sustaining high state-trajectory variance, the Pareto-DQN effectively maps the Pareto frontier, achieving gains in auxiliary societal objectives with only marginal impacts on engagement. This work provides a path toward intrinsically aligned, responsible recommender systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a Semantic Pareto-DQN framework that models recommendation as a multi-objective MDP with separate, non-aggregable reward signals for engagement, diversity, and fairness. It integrates high-fidelity semantic embeddings into a Pareto-DQN agent and employs hypervolume-based action selection to approximate the Pareto frontier without static reward scalarization. On the MovieLens small dataset, the approach is claimed to disrupt semantic collapse feedback loops by sustaining high state-trajectory variance, yielding gains on auxiliary societal objectives while incurring only marginal engagement costs.
Significance. If the empirical claims are substantiated with detailed results, the work would illustrate a direct application of multi-objective RL techniques (Pareto-DQN and hypervolume selection) to the filter-bubble problem in recommender systems. This provides a concrete alternative to scalarized single-objective DQN and could inform the design of systems that jointly optimize platform retention and societal criteria. The explicit avoidance of reward aggregation is a methodological strength worth noting.
major comments (1)
- [Abstract] Abstract (empirical evaluations paragraph): the central claim that hypervolume-based selection 'disrupts the feedback loops responsible for semantic collapse' and achieves 'gains in auxiliary societal objectives with only marginal impacts on engagement' is presented without any quantitative metrics, baseline comparisons, ablation results, or reported values for state-trajectory variance or hypervolume. This absence prevents verification of the load-bearing empirical assertion.
Simulated Author's Rebuttal
We thank the referee for their review and the identification of a clear issue in the abstract. We address the comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (empirical evaluations paragraph): the central claim that hypervolume-based selection 'disrupts the feedback loops responsible for semantic collapse' and achieves 'gains in auxiliary societal objectives with only marginal impacts on engagement' is presented without any quantitative metrics, baseline comparisons, ablation results, or reported values for state-trajectory variance or hypervolume. This absence prevents verification of the load-bearing empirical assertion.
Authors: We agree that the abstract as submitted does not contain the requested quantitative support. The experimental section of the manuscript reports baseline comparisons, ablation results, state-trajectory variance values, and hypervolume metrics on MovieLens. In the revised manuscript we will update the abstract to include the specific numerical results (e.g., hypervolume achieved, variance sustained relative to DQN, percentage gains in diversity/fairness, and engagement delta) so that the central empirical claim is verifiable from the abstract alone. revision: yes
Circularity Check
No significant circularity identified
full rationale
The manuscript presents an empirical multi-objective RL architecture evaluated on MovieLens without any visible derivation chain, equations, or first-principles claims that reduce to fitted inputs or self-citations by construction. Performance assertions rest on experimental outcomes rather than tautological mappings or load-bearing self-references, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A systematic review and research perspective on recommender systems,
D. Roy and M. Dutta, “A systematic review and research perspective on recommender systems,”Journal of Big Data, vol. 9, no. 1, p. 59, May
-
[2]
Available: https://doi.org/10.1186/s40537-022-00592-5
[Online]. Available: https://doi.org/10.1186/s40537-022-00592-5
-
[3]
Exploring the filter bubble: the effect of using recommender systems on content diversity,
T. T. Nguyen, P.-M. Hui, F. M. Harper, L. Terveen, and J. A. Konstan, “Exploring the filter bubble: the effect of using recommender systems on content diversity,” ser. WWW ’14. New York, NY , USA: Association for Computing Machinery, 2014, p. 677–686. [Online]. Available: https://doi.org/10.1145/2566486.2568012
-
[4]
Q-ader: An effective q-learning for recommendation with diminishing action space,
F. Li, H. Qu, L. Zhang, M. Fu, W. Chen, and Z. Yi, “Q-ader: An effective q-learning for recommendation with diminishing action space,”IEEE Transactions on Neural Networks and Learning Systems, vol. 36, no. 5, pp. 8510–8524, 2025
2025
-
[5]
Toward pareto efficient fairness-utility trade-off in recommendation through reinforcement learning,
Y . Ge, X. Zhao, L. Yu, S. Paul, D. Hu, C.-C. Hsieh, and Y . Zhang, “Toward pareto efficient fairness-utility trade-off in recommendation through reinforcement learning,” inProceedings of the Fifteenth ACM International Conference on Web Search and Data Mining, ser. WSDM ’22. ACM, Feb. 2022, p. 316–324. [Online]. Available: http://dx.doi.org/10.1145/34885...
-
[6]
C. F. Hayes, R. R ˘adulescu, E. Bargiacchi, J. K ¨allstr¨om, M. Macfarlane, M. Reymond, T. Verstraeten, L. M. Zintgraf, R. Dazeley, F. Heintz, E. Howley, A. A. Irissappane, P. Mannion, A. Now ´e, G. Ramos, M. Restelli, P. Vamplew, and D. M. Roijers, “A practical guide to multi-objective reinforcement learning and planning,”Autonomous Agents and Multi-Agen...
-
[7]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using Siamese BERT-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), K. Inui, J. Jiang, V . Ng, and X. Wan, Eds. Hong Kong, China: Association for Comput...
2019
-
[8]
Deep learning based recommender system: A survey and new perspectives,
S. Zhang, L. Yao, A. Sun, and Y . Tay, “Deep learning based recommender system: A survey and new perspectives,”ACM Comput. Surv., vol. 52, no. 1, Feb. 2019. [Online]. Available: https://doi.org/10.1145/3285029
-
[9]
F. M. Harper and J. A. Konstan, “The movielens datasets: History and context,”ACM Trans. Interact. Intell. Syst., vol. 5, no. 4, Dec. 2015. [Online]. Available: https://doi.org/10.1145/2827872
-
[10]
Reinforcement learning based recommender systems: A survey,
M. M. Afsar, T. Crump, and B. Far, “Reinforcement learning based recommender systems: A survey,”ACM Comput. Surv., vol. 55, no. 7, Dec. 2022. [Online]. Available: https://doi.org/10.1145/3543846
-
[11]
Deep reinforcement learning: A survey,
X. Wang, S. Wang, X. Liang, D. Zhao, J. Huang, X. Xu, B. Dai, and Q. Miao, “Deep reinforcement learning: A survey,”IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 4, pp. 5064– 5078, 2024
2024
-
[12]
Multi-objective reinforcement learning for recommender systems: a comprehensive survey of methods, challenges, and future directions,
Z. Fatima Ezzahra, A. Sana, Q. Sara, and R. Said, “Multi-objective reinforcement learning for recommender systems: a comprehensive survey of methods, challenges, and future directions,”International Journal of Multimedia Information Retrieval, vol. 14, no. 4, p. 33, Oct
-
[13]
Available: https://doi.org/10.1007/s13735-025-00383-7
[Online]. Available: https://doi.org/10.1007/s13735-025-00383-7
-
[14]
D. Stamenkovic, A. Karatzoglou, I. Arapakis, X. Xin, and K. Katevas, “Choosing the best of both worlds: Diverse and novel recommendations through multi-objective reinforcement learning,” 2021. [Online]. Available: https://arxiv.org/abs/2110.15097
arXiv 2021
-
[15]
Multi-objective reinforcement learning approach for trip recommendation,
L. Chen, G. Zhu, W. Liang, and Y . Wang, “Multi-objective reinforcement learning approach for trip recommendation,”Expert Systems with Applications, vol. 226, p. 120145, 2023. [Online]. Available: https: //www.sciencedirect.com/science/article/pii/S0957417423006474
2023
-
[16]
Two-stage constrained actor-critic for short video recommendation,
Q. Cai, Z. Xue, C. Zhang, W. Xue, S. Liu, R. Zhan, X. Wang, T. Zuo, W. Xie, D. Zheng, P. Jiang, and K. Gai, “Two-stage constrained actor-critic for short video recommendation,” 2024. [Online]. Available: https://arxiv.org/abs/2302.01680
arXiv 2024
-
[17]
Intelligent electric vehicle charging recommendation based on multi- agent reinforcement learning,
W. Zhang, H. Liu, F. Wang, T. Xu, H. Xin, D. Dou, and H. Xiong, “Intelligent electric vehicle charging recommendation based on multi- agent reinforcement learning,” inProceedings of the Web Conference 2021, ser. WWW ’21. ACM, Apr. 2021, p. 1856–1867. [Online]. Available: http://dx.doi.org/10.1145/3442381.3449934
-
[18]
Y . Ren, K. Liang, Y . Shang, and X. Zhang, “Fully adaptive recommendation paradigm: top-enhanced recommender distillation for intelligent education systems,”Complex & Intelligent Systems, vol. 9, no. 2, pp. 2159–2176, Apr 2023. [Online]. Available: https://doi.org/10.1007/s40747-022-00905-4
-
[19]
Sequential recommendation for optimizing both immediate feedback and long-term retention,
Z. Liu, S. Liu, Z. Zhang, Q. Cai, X. Zhao, K. Zhao, L. Hu, P. Jiang, and K. Gai, “Sequential recommendation for optimizing both immediate feedback and long-term retention,” inProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, ser. SIGIR 2024. ACM, Jul. 2024, p. 1872–1882. [Online]. Available: h...
-
[20]
Deep reinforcement learning based recommendation with explicit user-item interactions modeling,
F. Liu, R. Tang, X. Li, W. Zhang, Y . Ye, H. Chen, H. Guo, and Y . Zhang, “Deep reinforcement learning based recommendation with explicit user-item interactions modeling,” 2019. [Online]. Available: https://arxiv.org/abs/1810.12027
arXiv 2019
-
[21]
Multi-objective reinforcement learning using sets of pareto dominating policies,
K. Van Moffaert and A. Now ´e, “Multi-objective reinforcement learning using sets of pareto dominating policies,”J. Mach. Learn. Res., vol. 15, no. 1, p. 3483–3512, Jan. 2014
2014
-
[22]
Hypervolume-based multi-objective reinforcement learning,
K. V . Moffaert, M. M. Drugan, and A. Now ´e, “Hypervolume-based multi-objective reinforcement learning,” inEvolutionary Multi-Criterion Optimization (EMO 2013), ser. Lecture Notes in Computer Science, vol
2013
-
[23]
Berlin, Heidelberg: Springer, 2013, pp. 352–366
2013
-
[24]
Deep pareto reinforcement learning for multi-objective recommender systems,
P. Li and A. Tuzhilin, “Deep pareto reinforcement learning for multi-objective recommender systems,”MIS Quarterly, p. 1–39, Nov
-
[25]
Available: http://dx.doi.org/10.25300/MISQ/2025/19488
[Online]. Available: http://dx.doi.org/10.25300/MISQ/2025/19488
-
[26]
Pymoo: Multi-objective optimization in python,
J. Blank and K. Deb, “Pymoo: Multi-objective optimization in python,” IEEE Access, vol. 8, pp. 89 497–89 509, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.