Best Preprocessing Techniques for Sentiment Analysis
Pith reviewed 2026-06-26 00:55 UTC · model grok-4.3
The pith
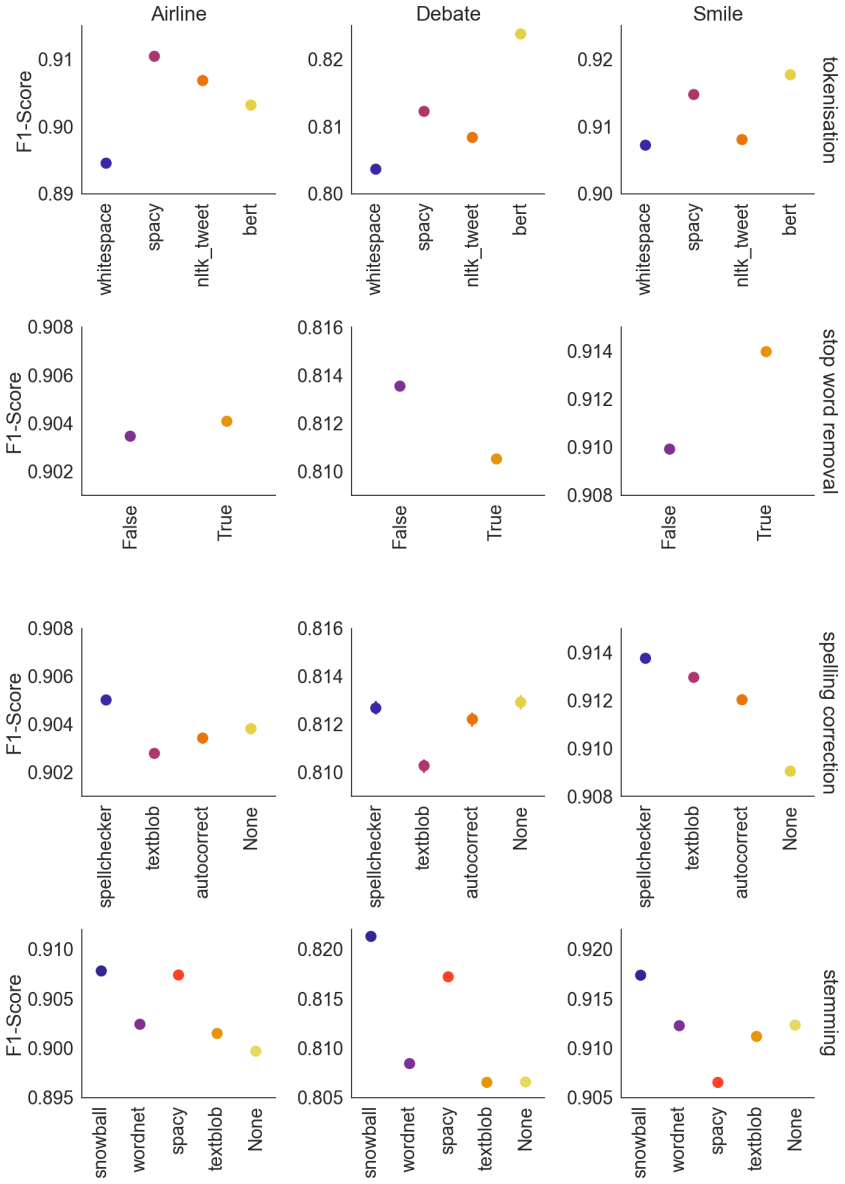
Tokenisation has the largest effect and spelling correction the smallest when ordering preprocessing steps for Twitter sentiment analysis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the order of application is taken into account, tokenisation produces the largest performance gain and spelling correction the smallest; stemming and stopword removal are largely interchangeable. The preferred sequence is tokenisation, followed by text cleaning, then stemming, and finally stopword removal. Removing negation words during stopword removal reduces accuracy, so negation terms should be retained.
What carries the argument
Controlled experiments that isolate the contribution of each preprocessing step while varying their order on Twitter sentiment datasets.
If this is right
- Tokenisation should be placed early in any preprocessing pipeline for this task.
- Spelling correction can be dropped or moved last to reduce runtime cost with little loss.
- Stopword lists should be edited to keep negation markers.
- Stemming can precede or follow stopword removal with similar results.
- A fixed order removes the need for per-project hyperparameter search over preprocessing.
Where Pith is reading between the lines
- The same ordering may reduce noise in sentiment tracking for other short social-media texts such as Reddit comments.
- Large-scale opinion monitoring systems could adopt the sequence to lower preprocessing compute without accuracy loss.
- The interchangeability of stemming and stopword removal suggests they overlap in the information they remove.
- Testing the sequence on transformer-based models would show whether the ordering effect persists beyond traditional classifiers.
Load-bearing premise
The measured differences in impact and the recommended order are not tied to the particular Twitter datasets, classifiers, or evaluation metrics used in the study.
What would settle it
Repeating the same order-swap experiments on a non-Twitter short-text corpus or with a neural classifier and obtaining a different ranking of step importance or a different best sequence.
Figures
read the original abstract
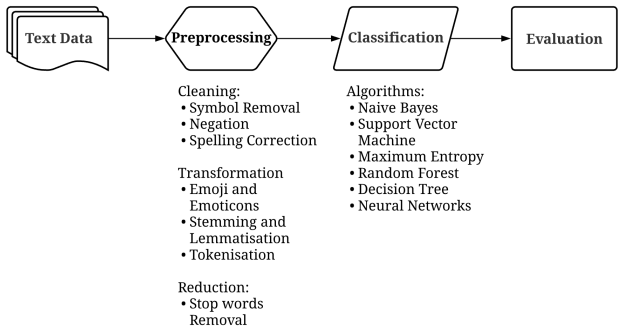
Sentiment analysis in Twitter datasets is important because it enables monitoring public opinion on products and analysis of political and social movements. One critical step is preprocessing: the automated processing of text for machine learning algorithms. Preprocessing plays a critical role in reducing noise and improving efficiency. However, little research has systematically examined the order in which preprocessing techniques are implemented. We find that, when accounting for order, spelling correction is the least impactful preprocessing technique, whereas tokenisation is the most impactful. Stemming and stop-word removal are interchangeable, and it is better to remove stop words without removing negation. The best order for applying the preprocessing techniques was tokenisation, text cleaning, stemming, and then stopword removal. Our results provide a systematic approach for practitioners to deploy preprocessing to improve model output without the costly preprocessing exploratory phase.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study of preprocessing techniques for sentiment analysis on Twitter datasets. It claims that, when order is accounted for, tokenisation is the most impactful technique while spelling correction is the least; stemming and stopword removal are interchangeable; stopword removal should preserve negation; and the optimal sequence is tokenisation, text cleaning, stemming, then stopword removal. The work positions these findings as a practical guide to avoid exploratory preprocessing.
Significance. If the reported rankings and ordering prove robust, the results would supply a concrete, reusable preprocessing pipeline for Twitter sentiment analysis, reducing ad-hoc experimentation for practitioners working on public-opinion monitoring tasks.
major comments (2)
- [Abstract] Abstract: the central claims that 'tokenisation is the most impactful' and that the 'best order' is tokenisation-text cleaning-stemming-stopword removal are stated without any reported performance deltas, tables of results, or description of how impact was quantified (e.g., accuracy/F1 change, permutation testing). This is load-bearing because the rankings could be artifacts of the specific Twitter corpora, classifiers, or metrics, exactly as flagged in the stress-test note.
- [Methods / Experimental Setup (missing)] No section describes the experimental design: the number or size of Twitter datasets, the machine-learning models used, the evaluation metrics, or any statistical testing for significance of the reported impacts and order effects. Without these details the reproducibility and generalizability of the 'least/most impactful' and 'best order' conclusions cannot be assessed.
minor comments (1)
- [Abstract] The term 'text cleaning' is used in the abstract without definition; a brief enumeration of its operations (e.g., lower-casing, punctuation removal) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract and experimental details require strengthening for clarity and reproducibility, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that 'tokenisation is the most impactful' and that the 'best order' is tokenisation-text cleaning-stemming-stopword removal are stated without any reported performance deltas, tables of results, or description of how impact was quantified (e.g., accuracy/F1 change, permutation testing). This is load-bearing because the rankings could be artifacts of the specific Twitter corpora, classifiers, or metrics, exactly as flagged in the stress-test note.
Authors: We agree that the abstract should include quantitative support. In the revision we will add specific performance deltas (F1 and accuracy changes) and a brief description of the quantification method based on comparative experiments across orders and techniques. The full result tables already exist in the manuscript and will be referenced to substantiate the rankings. revision: yes
-
Referee: [Methods / Experimental Setup (missing)] No section describes the experimental design: the number or size of Twitter datasets, the machine-learning models used, the evaluation metrics, or any statistical testing for significance of the reported impacts and order effects. Without these details the reproducibility and generalizability of the 'least/most impactful' and 'best order' conclusions cannot be assessed.
Authors: We acknowledge the absence of a dedicated methods section. The revised manuscript will include a new Methods section specifying the Twitter datasets and their sizes, the classifiers employed, the evaluation metrics, and the statistical tests used to assess significance of the preprocessing impacts and ordering effects. This will directly address reproducibility concerns. revision: yes
Circularity Check
Empirical comparison with no derivation chain or self-referential fitting
full rationale
The paper reports experimental results comparing the impact and optimal ordering of preprocessing techniques (tokenisation, text cleaning, stemming, stopword removal, spelling correction) on Twitter sentiment analysis datasets. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations are present in the provided text. The central claims rest on direct empirical measurements rather than any chain that reduces to its own inputs by construction. This is a standard empirical study whose validity depends on replication and controls, not on circular logic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Foundations and Trends
Opinion mining and sentiment analysis , author=. Foundations and Trends. 2008 , publisher=
2008
-
[2]
Dandannavar, P. S. and Mangalwede, S. R. and Deshpande, S. B. , editor =. Emoticons and. 2020 , series =. doi:10.1007/978-3-030-19562-5_19 , abstract =
-
[3]
Singh, Tajinder and Kumari, Madhu , year =. Role of. doi:10.1016/j.procs.2016.06.095 , url =
-
[4]
Angiani, Giulio and Ferrari, Laura and Fontanini, Tomaso and Fornacciari, Paolo and Iotti, Eleonora and Magliani, Federico and Manicardi, Stefano , booktitle =
-
[5]
2009 , publisher=
Natural language processing with Python: analyzing text with the natural language toolkit , author=. 2009 , publisher=
2009
-
[6]
doi:10.5281/zenodo.1212303 , url =
Honnibal, Matthew and Montani, Ines and Van Landeghem, Sofie and Boyd, Adriane , year = 2020, publisher =. doi:10.5281/zenodo.1212303 , url =
-
[7]
Release 0.16.0 , volume=
TextBlob Documentation , author=. Release 0.16.0 , volume=
-
[8]
2019 , howpublished =
pycontractions Package , author=. 2019 , howpublished =
2019
-
[9]
2021 , howpublished =
emoji Package , author=. 2021 , howpublished =
2021
-
[10]
2021 , howpublished =
demoji Package , author=. 2021 , howpublished =
2021
-
[11]
2020 , howpublished =
emot Package , author=. 2020 , howpublished =
2020
-
[12]
2021 , note =
pyspellchecker Package , author=. 2021 , note =
2021
-
[13]
2020 , note =
symspellpy Package , author=. 2020 , note =
2020
-
[14]
doi:10.5281/zenodo.4642379 , url =
Rajat Goel , title =. doi:10.5281/zenodo.4642379 , url =
-
[15]
Hugging Face , title =
-
[16]
Sondej, Filip , title =
-
[17]
Wang,Bo and Tsakalidis,Adam and Liakata, Maria and Zubiaga, Arkaitz and Procter, Rob and Jensen, Eric , title =. 2016 , howpublished =. doi:10.6084/m9.figshare.3187909.v2
-
[18]
, title =
Crowdflower's Data for Everyone library. , title =. 2016 , howpublished =
2016
-
[19]
, title =
Crowdflower's Data for Everyone library. , title =. 2015 , howpublished =
2015
-
[20]
2015 , howpublished =
International Workshop on Semantic Evaluation , title =. 2015 , howpublished =
2015
-
[21]
2016 , howpublished =
International Workshop on Semantic Evaluation , title =. 2016 , howpublished =
2016
-
[22]
Alam, Saqib and Yao, Nianmin , journal =
-
[23]
Jianqiang, Zhao , booktitle =
-
[24]
Yue, Lin and Chen, Weitong and Li, Xue and Zuo, Wanli and Yin, Minghao , journal =
-
[25]
Giachanou, Anastasia and Crestani, Fabio , booktitle =. doi:10.1145/2938640 , file =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.