Ingredient-Level Food Image Segmentation for Nutrition Awareness
Pith reviewed 2026-06-26 01:30 UTC · model grok-4.3
The pith
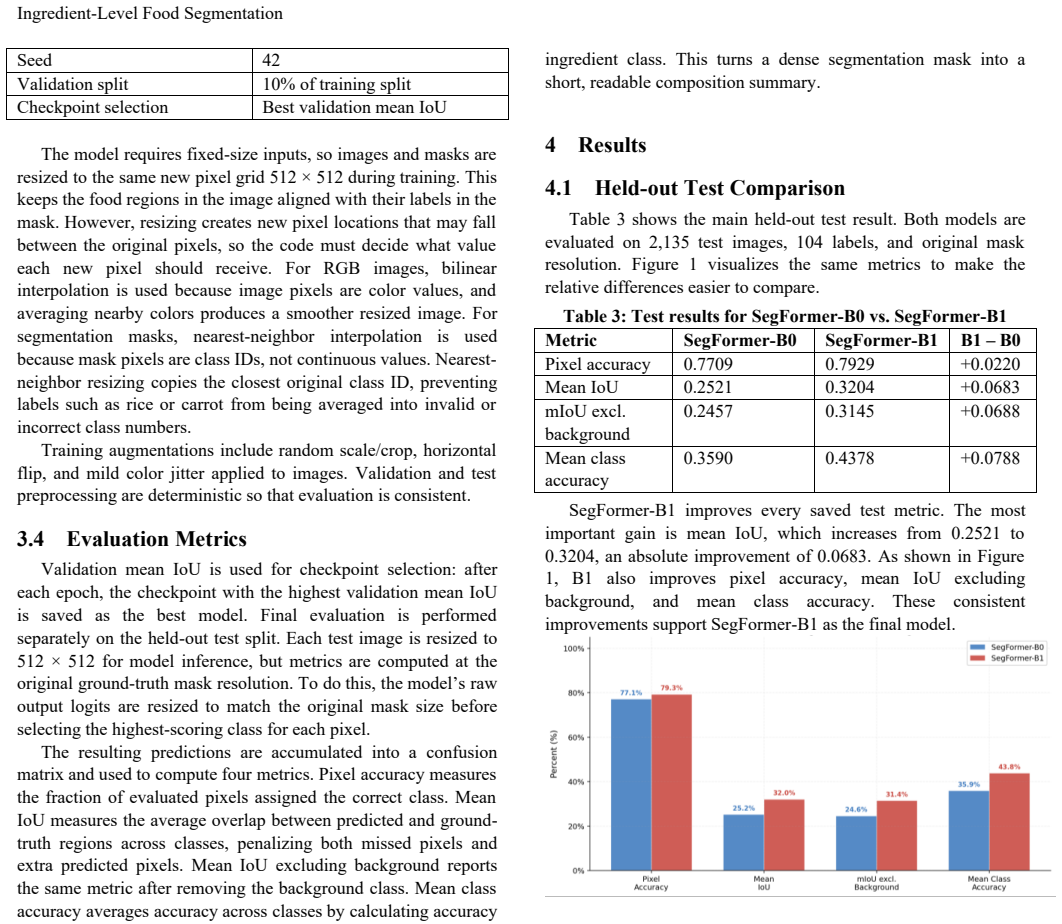
SegFormer-B1 fine-tuned on FoodSeg103 reaches 0.7929 pixel accuracy and 0.3204 mean IoU for per-pixel ingredient segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fine-tuning SegFormer-B1, which uses an ImageNet-pretrained MiT backbone and a newly initialized 104-class output layer, on FoodSeg103 produces 0.7929 pixel accuracy and 0.3204 mean IoU on the test split; the same pipeline converts the predicted masks into visible ingredient-area percentages that serve as a visual composition summary without estimating calories, macronutrients, mass, volume, density, or true portion size.
What carries the argument
SegFormer-B0 and B1 variants with MiT backbones that perform pixel-wise classification into 104 ingredient classes.
If this is right
- B1 improves every saved test metric over B0, including the 0.0683 gain in mean IoU.
- Predicted masks convert directly into visible ingredient-area percentages.
- The percentage summary acts as a visual alternative to detailed food tracking.
- The output aligns with plate-based meal guidance approaches.
Where Pith is reading between the lines
- The area-percentage output could be displayed in a mobile app as an at-a-glance meal log without requiring users to weigh portions.
- Segmentation quality on images with heavy occlusion or unusual plating would need separate testing beyond the FoodSeg103 test split.
- Pairing the 2D masks with depth sensing could later supply the missing volume dimension the paper explicitly sets aside.
Load-bearing premise
The FoodSeg103 pixel labels correctly mark all visible ingredients in the test images and the resulting area percentages remain a useful nutrition cue even without any volume, density, or mass information.
What would settle it
A new collection of food images where human annotators mark visible ingredient regions shows that the model's predicted area percentages deviate systematically from the human marks or where later volume measurements show the percentages bear no relation to actual nutrient content.
Figures
read the original abstract
Food images often contain several visible ingredients, so assigning one dish label to an entire image hides important visual structure. This work studies ingredient-level semantic segmentation on FoodSeg103, where the model predicts an ingredient class for each pixel. Two SegFormer variants were fine-tuned and evaluated under a controlled setup: SegFormer-B0 as the smaller baseline model and SegFormer-B1 as the larger final model. Both models use ImageNet-pretrained MiT backbones with newly initialized 104-class output layers. On the held-out FoodSeg103 test split of 2,135 images, B0 achieved 0.7709 pixel accuracy and 0.2521 mean IoU, while B1 achieved 0.7929 pixel accuracy and 0.3204 mean IoU. B1 improved every saved test metric, including a +0.0683 absolute gain in mean IoU. The system also converts predicted masks into visible ingredient-area percentages, giving a simple visual composition summary of the predicted meal. This summary can serve as a first-pass nutrition-awareness cue by providing a visual alternative to detailed food tracking similar to plate-based meal guidance, but it is not a direct estimate of calories, macronutrients, food mass, volume, density, or true portion size.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports an empirical evaluation of fine-tuning two SegFormer models (B0 and B1) for ingredient-level semantic segmentation on the FoodSeg103 dataset. It presents pixel accuracy and mean IoU results on a held-out test set of 2,135 images, with B1 showing improvements over B0, and describes a post-processing step to derive visible ingredient area percentages from the predicted masks as a visual cue for nutrition awareness, while explicitly disclaiming that this constitutes direct nutrition estimation.
Significance. If the reported metrics are reproducible under the claimed controlled conditions, the work establishes baseline performance numbers for this task on a public dataset and illustrates a straightforward downstream application. The significance is modest, as the approach is standard transfer learning and the nutrition utility is limited by the absence of volume or mass information, as the authors note.
major comments (1)
- [Abstract] The abstract states that the models were 'fine-tuned and evaluated under a controlled setup' but provides no information on training details, hyperparameters, data augmentation strategies, optimization settings, or error analysis. This omission leaves the central performance claims (0.7709/0.2521 for B0 and 0.7929/0.3204 for B1) without supporting evidence of the experimental controls.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment. We address the major comment on the abstract below and will make the necessary revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] The abstract states that the models were 'fine-tuned and evaluated under a controlled setup' but provides no information on training details, hyperparameters, data augmentation strategies, optimization settings, or error analysis. This omission leaves the central performance claims (0.7709/0.2521 for B0 and 0.7929/0.3204 for B1) without supporting evidence of the experimental controls.
Authors: We agree that the abstract, due to length constraints, does not enumerate the full experimental details. The manuscript body includes a dedicated Experimental Setup section describing the ImageNet-pretrained MiT backbones, newly initialized 104-class heads, the 2,135-image held-out test split, and the controlled fine-tuning protocol. To directly address the concern, we will revise the abstract to include a concise clause referencing the key controlled elements (e.g., "using ImageNet-pretrained MiT backbones on the 2,135-image test split") while preserving brevity. This revision will better anchor the reported metrics to the experimental controls detailed in the paper. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is a straightforward empirical report of fine-tuning two SegFormer variants (B0 and B1) on the public FoodSeg103 dataset, reporting standard pixel accuracy and mean IoU metrics on the held-out 2135-image test split, plus a simple post-processing step that converts masks to area percentages. No equations, fitted parameters renamed as predictions, self-citations, or derivations are present that would reduce any claim to its inputs by construction. The evaluation uses external public data and standard metrics with no internal reduction or load-bearing self-reference.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption FoodSeg103 test split labels are accurate ground truth for visible ingredients
Reference graph
Works this paper leans on
-
[1]
Xiongwei Wu, Xin Fu, Ying Liu, Ee -Peng Lim, Steven C. H. Hoi, and Qianru Sun. 2021. A Large -Scale Benchmark for Food Image Segmentation. In Proceedings of the 29th ACM International Conference on Multimedia (MM '21). Association for Computing Machinery, New York, NY, USA, 506 –515. https://doi.org/10.1145/3474085.3475201
-
[2]
Alvarez, and Ping Luo
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. 2021. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Advances in Neural Information Processing Systems 34 (NeurIPS 2021), 12077–12090
2021
-
[3]
Jonathan Long, Evan Shelhamer, and Trevor Darrell. 2015. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015). IEEE, 3431 –3440. https://doi.org/10.1109/CVPR.2015.7298965
-
[4]
Grant Sinha, Krish Parmar, Hilda Azimi, Amy Tai, Yuhao Chen, Alexander Wong, and Pengcheng Xi. 2023. Transferring Knowledge for Food Image Segmentation using Transformers and Convolutions. In Proceedings of the CVPR 2023 Workshop on Computer Vision in the Wild (CVinW)
2023
-
[5]
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. 2018. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Computer Vision – ECCV 2018, Lecture Notes in Computer Science, Vol. 11211. Springer, Cham, 833 –851. https://doi.org/10.1007/978-3-030-01234-2_49
-
[6]
Chan School of Public Health
Harvard T.H. Chan School of Public Health. n.d. Healthy Eating Plate. The Nutrition Source. Retrieved June 1, 2026 from https://nutritionsource.hsph.harvard.edu/healthy-eating-plate/
2026
-
[7]
Department of Agriculture, Agricultural Research Service
U.S. Department of Agriculture, Agricultural Research Service. n.d. FoodData Central API Guide. Retrieved June 1, 2026 from https://fdc.nal.usda.gov/api- guide/
2026
-
[8]
Christoph Höchsmann and Corby K. Martin. 2020. Review of the validity and feasibility of image -assisted methods for dietary assessment. International Journal of Obesity 44, 12 (2020), 2358 –2371. https://doi.org/10.1038/s41366- 020-00693-2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.