VieSpeaker: A Large-Scale Vietnamese Speaker Recognition Dataset Beyond Visual Dependency
Pith reviewed 2026-06-25 22:56 UTC · model grok-4.3
The pith
A face-independent pipeline builds a 902-hour Vietnamese speaker dataset using text metadata and LLM reasoning to label identities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a face-independent dataset construction pipeline, which infers speaker identities from textual metadata and large language model reasoning over transcripts and context, successfully produces VieSpeaker containing approximately 902 hours of speech from 4715 speakers, and that models trained on this resource achieve improved robustness and generalization relative to models trained on existing Vietnamese datasets.
What carries the argument
The face-independent dataset construction pipeline that leverages textual metadata and large language model reasoning to infer speaker identities from transcripts and contextual information.
If this is right
- Speaker recognition models trained on VieSpeaker exhibit greater robustness and generalization than those trained on prior Vietnamese datasets.
- The approach removes the requirement for on-camera recordings, allowing collection of speech with wider acoustic conditions.
- The same text-and-LLM method supplies a template for constructing large speech resources in other languages that lack visual archives.
- VieSpeaker demonstrates that scale and diversity can be increased while remaining independent of facial identification.
Where Pith is reading between the lines
- The method may enable inclusion of spontaneous speech from sources such as podcasts or meetings that rarely include video.
- Accuracy of the LLM-based labeling step could be measured directly by comparing a subset of inferences against human review.
- If the pipeline generalizes, it could lower the cost barrier for creating speaker datasets in additional low-resource languages.
- The resulting models might show particular gains on test conditions that differ from typical video-recorded speech.
Load-bearing premise
Textual metadata combined with large language model reasoning can reliably identify the correct speaker for each recording without visual confirmation.
What would settle it
A manual verification of speaker labels on a random sample of several hundred segments from VieSpeaker that reveals a substantial fraction of incorrect identities would falsify the pipeline's reliability.
Figures
read the original abstract
Speaker recognition has advanced rapidly with large-scale training datasets, yet Vietnamese remains under-resourced, with existing corpora limited in scale and acoustic diversity. Most large-scale datasets rely on facial cues to link speech with speaker identities, restricting data collection to recordings where speakers appear on camera. We propose a face-independent dataset construction pipeline and introduce VieSpeaker, a large-scale Vietnamese speaker recognition dataset. Our approach leverages textual metadata and large language model reasoning to infer speaker identities from transcripts and contextual information. VieSpeaker contains approximately 902 hours of speech from 4,715 speakers. Experiments show that models trained on VieSpeaker achieve improved robustness and generalization compared to existing Vietnamese datasets. This work demonstrates the feasibility of face-independent dataset construction and provides a new direction for building large-scale speech resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VieSpeaker, a large-scale Vietnamese speaker recognition dataset containing approximately 902 hours of speech from 4,715 speakers. It proposes a face-independent construction pipeline that uses textual metadata and large language model reasoning to infer speaker identities from transcripts and contextual information, claiming that models trained on this dataset achieve improved robustness and generalization compared to existing Vietnamese datasets.
Significance. If the label accuracy and experimental results hold, the work would be significant for demonstrating a scalable, vision-free approach to building speaker recognition resources for under-resourced languages. The dataset scale is substantial and addresses a clear gap, though the absence of validation on the core labeling step limits immediate impact.
major comments (2)
- [Abstract] Abstract: the claim that 'models trained on VieSpeaker achieve improved robustness and generalization' is asserted without any quantitative results, baselines, metrics (e.g., EER), or experimental details, making it impossible to evaluate whether the data supports the central empirical claim.
- [Dataset construction pipeline] Dataset construction pipeline: the inference of the 4,715 speaker identities via LLM reasoning on textual metadata and transcripts is presented without any reported validation, human audit, cross-validation against known recordings, or quantitative error analysis. This is load-bearing for the performance claims, as systematic mislabeling could produce or mask the reported gains independently of the face-independent method.
minor comments (1)
- The abstract would be strengthened by including at least one key quantitative comparison (e.g., a performance delta or table reference) to support the generalization claim.
Simulated Author's Rebuttal
We appreciate the referee's feedback on our work introducing VieSpeaker. The comments highlight areas where the presentation can be improved, and we respond to each major comment below. We are committed to revising the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'models trained on VieSpeaker achieve improved robustness and generalization' is asserted without any quantitative results, baselines, metrics (e.g., EER), or experimental details, making it impossible to evaluate whether the data supports the central empirical claim.
Authors: We agree with the observation that the abstract makes a claim about improved robustness and generalization without providing quantitative details. The experiments section of the manuscript does include comparisons using metrics such as Equal Error Rate (EER) against baselines from existing Vietnamese datasets. We will update the abstract to incorporate specific quantitative results to better support the claim. revision: yes
-
Referee: [Dataset construction pipeline] Dataset construction pipeline: the inference of the 4,715 speaker identities via LLM reasoning on textual metadata and transcripts is presented without any reported validation, human audit, cross-validation against known recordings, or quantitative error analysis. This is load-bearing for the performance claims, as systematic mislabeling could produce or mask the reported gains independently of the face-independent method.
Authors: We acknowledge that the manuscript does not include a validation study or error analysis for the LLM-based speaker identity inference process. This is a substantive point, as the accuracy of labels is crucial. We will revise the paper to include a human validation experiment on a subset of the data to quantify the labeling accuracy and address this concern. revision: yes
Circularity Check
No circularity; empirical dataset creation and evaluation
full rationale
The paper presents a pipeline for constructing VieSpeaker via LLM-based inference on textual metadata and transcripts, followed by empirical training and comparison of speaker recognition models. No equations, fitted parameters renamed as predictions, self-citation chains, uniqueness theorems, or ansatzes appear in the provided text. The central claim of improved robustness rests on reported experimental outcomes rather than any reduction to inputs by construction. This matches the default expectation of a non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Speaker recognition refers to the automatic analysis of speech signals to determine a speaker’s identity or verify a claimed identity. Recently, significant progress in speaker recognition has been largely driven by the availability of large-scale train- ing corpora, which enable deep neural networks to effectively model both intra-speaker va...
-
[2]
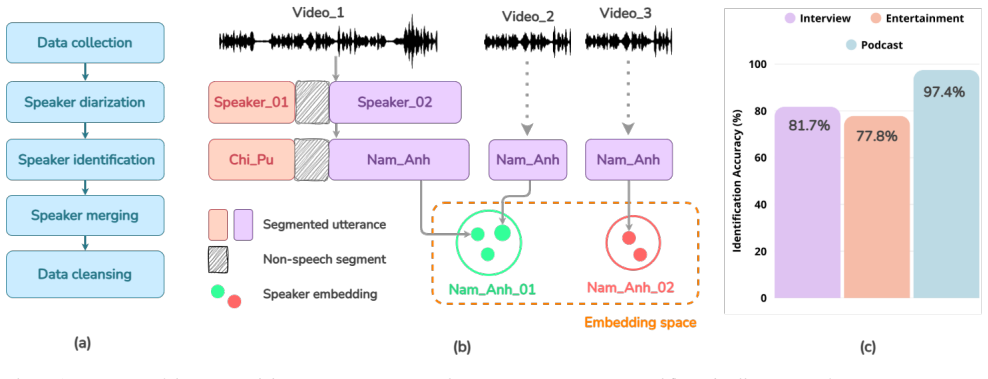
Dataset construction pipeline In this section, we describe the proposed dataset construction pipeline, as illustrated in Fig. 1, and detail each of its key stages. 2.1. Data collection Our data collection begins with manually curating playlists from publicly accessible YouTube channels across three do- mains: interviews, entertainment, and podcasts. Unlik...
Pith/arXiv arXiv 2026
-
[3]
VieSpeaker becomes the largest and most comprehen- sive dataset for Vietnamese speaker recognition to date
Data description After completing the proposed data construction process, we obtain the finalized VieSpeaker dataset comprising 365,874 ut- terances from 4,715 unique speakers, totaling 902.03 hours of speech. VieSpeaker becomes the largest and most comprehen- sive dataset for Vietnamese speaker recognition to date. 3.1. Utterance and genre distribution T...
-
[4]
Experimental setup All experiments are conducted with the WeSpeaker [17] frame- work using the ECAPA-TDNN architecture with 1024-channel encoder blocks
Experiments 4.1. Experimental setup All experiments are conducted with the WeSpeaker [17] frame- work using the ECAPA-TDNN architecture with 1024-channel encoder blocks. During training, input audio is randomly cropped into 3-second segments. We extract 80-dimensional log Mel-filterbank features with a 25 ms frame length and 10 ms frame shift. The model i...
-
[5]
Our approach integrates speaker diariza- tion and LLM-based identity reasoning to enable scalable iden- tity annotation without relying on visual cues
Conclusion In this work, we introduced VieSpeaker, a large-scale Vietnamese speaker recognition dataset built using a face- independent pipeline. Our approach integrates speaker diariza- tion and LLM-based identity reasoning to enable scalable iden- tity annotation without relying on visual cues. VieSpeaker com- prises 4,715 speakers and over 900 hours of...
-
[6]
Acknowledgments This research was funded by the Ministry of Education and Training of Vietnam under project code CT2025.EA.BKA.04
-
[7]
We thoroughly reviewed all suggestions and re- main fully responsible and accountable for the final content of this work
Generative AI Use Disclosure During the preparation of this manuscript, the authors utilized ChatGPT strictly for editing and polishing the text, ensuring that the AI tool was not used to produce any significant part of the manuscript. We thoroughly reviewed all suggestions and re- main fully responsible and accountable for the final content of this work....
-
[8]
V oxCeleb2: Deep Speaker Recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxCeleb2: Deep Speaker Recognition,” inInterspeech 2018, 2018, pp. 1086–1090
2018
-
[9]
Cn-celeb: Multi-genre speaker recognition,
L. Li, R. Liu, J. Kang, Y . Fan, H. Cui, Y . Cai, R. Vipperla, T. F. Zheng, and D. Wang, “Cn-celeb: Multi-genre speaker recognition,”Speech Communication, vol. 137, pp. 77– 91, 2022. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0167639322000024
2022
-
[10]
Vlsp 2021-sv chal- lenge: Vietnamese speaker verification in noisy environments,
V . T. Dat, P. V . Thanh, and N. T. T. Trang, “Vlsp 2021-sv chal- lenge: Vietnamese speaker verification in noisy environments,” VNU Journal of Science: Computer Science and Communication Engineering, vol. 38, no. 1, 2022
2021
-
[11]
Vietnam-Celeb: a large-scale dataset for Vietnamese speaker recognition,
V . T. Pham, X. T. H. Nguyen, V . Hoang, and T. T. T. Nguyen, “Vietnam-Celeb: a large-scale dataset for Vietnamese speaker recognition,” inInterspeech 2023, 2023, pp. 1918–1922
2023
-
[12]
V oxvietnam: a large-scale multi-genre dataset for vietnamese speaker recognition,
H. L. Vu, P. T. Dat, P. T. Nhi, N. S. Hao, and N. T. Thu Trang, “V oxvietnam: a large-scale multi-genre dataset for vietnamese speaker recognition,” inICASSP 2025 - 2025 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[13]
VSASV: a Vietnamese Dataset for Spoofing-Aware Speaker Verification,
V . Hoang, V . T. Pham, H. N. Xuan, P. Nhi, P. Dat, and T. T. T. Nguyen, “VSASV: a Vietnamese Dataset for Spoofing-Aware Speaker Verification,” inInterspeech 2024, 2024, pp. 4288–4292
2024
-
[14]
Meta-generalization for domain-invariant speaker verification,
H. Zhang, L. Wang, K. A. Lee, M. Liu, J. Dang, and H. Meng, “Meta-generalization for domain-invariant speaker verification,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 31, pp. 1024–1036, 2023
2023
-
[15]
Bayesian Learning for Domain-Invariant Speaker Verification and Anti-Spoofing,
J. Li, M.-W. Mak, J. Rohdin, K. A. Lee, and H. Hermansky, “Bayesian Learning for Domain-Invariant Speaker Verification and Anti-Spoofing,” inInterspeech 2025, 2025, pp. 1123–1127
2025
-
[16]
Self-supervised learning based domain regularization for mask- wearing speaker verification,
R. Zhang, J. Wei, X. Lu, W. Lu, D. Jin, L. Zhang, Y . Ji, and J. Xu, “Self-supervised learning based domain regularization for mask- wearing speaker verification,”Speech Communication, vol. 152, p. 102953, 2023
2023
-
[17]
Y .-W. Chen, W. Ho, M. Topaz, J. Hirschberg, and Z. Kos- tic, “From who said what to who they are: Modular training- free identity-aware llm refinement of speaker diarization,”arXiv preprint arXiv:2509.15082, 2025
arXiv 2025
-
[18]
M3-slu: Evaluating speaker-attributed reasoning in multimodal large language mod- els,
Y . Kwon, T. Kang, H. Yoon, and C. Kim, “M3-slu: Evaluating speaker-attributed reasoning in multimodal large language mod- els,”arXiv preprint arXiv:2510.19358, 2025
arXiv 2025
-
[19]
Just asr + llm? a study on speech large language models’ ability to identify and understand speaker in spoken dialogue,
J. Wu, X. Fan, B.-R. Lu, X. Jiang, N. Mesgarani, M. Hasegawa- Johnson, and M. Ostendorf, “Just asr + llm? a study on speech large language models’ ability to identify and understand speaker in spoken dialogue,” in2024 IEEE Spoken Language Technology Workshop (SLT), 2024, pp. 1137–1143
2024
-
[20]
Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,” inInterspeech 2020. ISCA, Oct. 2020. [Online]. Available: http://dx.doi.org/10.21437/ Interspeech.2020-2650
2020
-
[21]
Outlier detection: How to threshold outlier scores?
J. Yang, S. Rahardja, and P. Fr ¨anti, “Outlier detection: How to threshold outlier scores?” inProceedings of the international conference on artificial intelligence, information processing and cloud computing, 2019, pp. 1–6
2019
-
[22]
V oxceleb: A large- scale speaker identification dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxceleb: A large- scale speaker identification dataset,” inInterspeech 2017. ISCA, Aug. 2017
2017
-
[23]
Cn-celeb: A challenging chinese speaker recognition dataset,
Y . Fan, J. Kang, L. Li, K. Li, H. Chen, S. Cheng, P. Zhang, Z. Zhou, Y . Cai, and D. Wang, “Cn-celeb: A challenging chinese speaker recognition dataset,” inICASSP 2020 - 2020 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2020, pp. 7604–7608
2020
-
[24]
Wespeaker: A research and production oriented speaker embedding learning toolkit,
H. Wang, C. Liang, S. Wang, Z. Chen, B. Zhang, X. Xiang, Y . Deng, and Y . Qian, “Wespeaker: A research and production oriented speaker embedding learning toolkit,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[25]
Ar- cface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, J. Yang, N. Xue, I. Kotsia, and S. Zafeiriou, “Ar- cface: Additive angular margin loss for deep face recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, p. 5962–5979, Oct. 2022
2022
-
[26]
Musan: A music, speech, and noise corpus,
D. Snyder, G. Chen, and D. Povey, “Musan: A music, speech, and noise corpus,” 2015. [Online]. Available: https: //arxiv.org/abs/1510.08484
Pith/arXiv arXiv 2015
-
[27]
Building and evaluation of a real room impulse response dataset,
I. Szoke, M. Skacel, L. Mosner, J. Paliesek, and J. Cer- nocky, “Building and evaluation of a real room impulse response dataset,”IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 4, p. 863–876, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.