NeuroSonic: Conditional Flow Matching for EEG-to-Speech Reconstruction
Pith reviewed 2026-06-26 00:52 UTC · model grok-4.3
The pith
NeuroSonic reconstructs speech from EEG by learning a deterministic flow that transports noisy acoustic states to clean waveforms under brain-signal conditioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
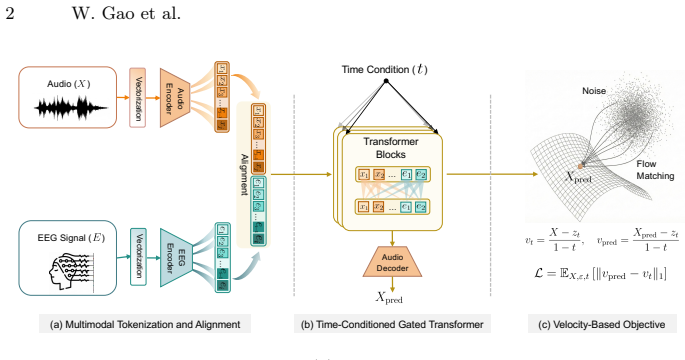
NeuroSonic learns a deterministic probability-flow velocity field that transports a noise-corrupted acoustic state toward clean speech under EEG conditioning. EEG and audio are embedded into a shared token space and processed by a time-conditioned gated Transformer that parameterizes the transport ordinary differential equation, yielding more stable reconstructions than direct regression or stochastic sampling.
What carries the argument
The conditional probability-flow velocity field, parameterized by a time-conditioned gated Transformer on shared EEG-audio token embeddings, that defines the ODE for deterministic transport from noisy to clean speech.
If this is right
- Deterministic ODE integration removes sensitivity to stochastic sampling artifacts that arise when conditioning is variable.
- The performance gap widens precisely where EEG conditioning is least stable, indicating the flow formulation directly addresses that mismatch.
- Cross-subject generalization holds on both CineBrain and EAV without subject-specific fine-tuning.
- The same velocity-field parameterization could support other continuous brain-to-signal mappings that require coherent temporal structure.
Where Pith is reading between the lines
- If the shared embedding proves robust, the same architecture might transfer to other non-stationary biosignal-to-audio tasks such as EMG-to-speech.
- Real-time inference becomes feasible because each sample requires only a single ODE solve rather than many diffusion steps.
- Subject-specific drift in EEG statistics might still require lightweight adapters even if the core flow is subject-agnostic.
Load-bearing premise
Embedding EEG and audio into a shared token space processed by a time-conditioned gated Transformer can reliably parameterize the transport ODE despite EEG spatial diffuseness, artifact variability, and cross-subject differences.
What would settle it
Absence of the reported perceptual-quality gains on artifact-heavy segments of the EAV benchmark under cross-subject evaluation would falsify the advantage of the conditional flow-matching formulation.
Figures
read the original abstract
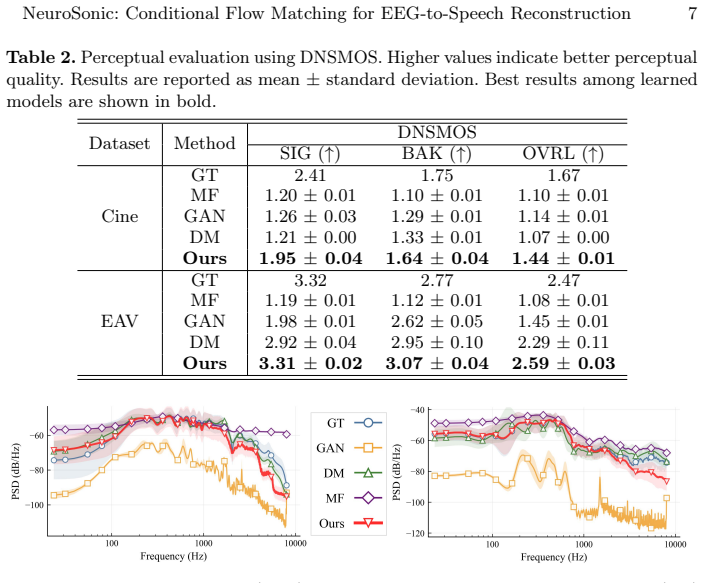
Reconstructing continuous speech from scalp electroencephalography (EEG) remains fundamentally challenging. EEG provides a weak, spatially diffuse, and highly variable measurement of distributed cortical activity, whereas speech is organized as a coherent acoustic trajectory with strong harmonic and temporal structure. The resulting mismatch makes waveform regression unstable and causes stochastic multi-step generation to be sensitive to artifact-dependent conditioning and subject variability. We introduce NeuroSonic, a conditional flow-matching framework for EEG-to-speech reconstruction. Instead of predicting waveforms directly or refining them through stochastic denoising, NeuroSonic learns a deterministic probability-flow velocity field that transports a noise-corrupted acoustic state toward clean speech under EEG conditioning. EEG and audio are embedded into a shared token space and processed by a time-conditioned gated Transformer that parameterizes the transport ordinary differential equation. This formulation models trajectory evolution explicitly while avoiding iterative stochastic sampling. We evaluate NeuroSonic on the CineBrain and EAV benchmarks under cross-subject evaluation. Across both datasets, the proposed method improves distributional realism, spectral fidelity, and perceptual quality over representative GAN-, diffusion-, and mean-flow baselines, with up to a 26.3\% gain in overall perceptual quality. The performance gap is most evident in artifact-heavy segments, where conditioning variability is strongest. These findings indicate that deterministic conditional transport provides a stable and effective formulation for EEG-driven speech reconstruction. Code is available at https://github.com/Y-Research-SBU/NeuroSonic/ .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces NeuroSonic, a conditional flow-matching model for EEG-to-speech reconstruction. It embeds EEG and audio into a shared token space processed by a time-conditioned gated Transformer to parameterize a deterministic probability-flow velocity field that transports noise-corrupted acoustic states to clean speech. The method is evaluated on the CineBrain and EAV benchmarks under cross-subject protocols, claiming improvements in distributional realism, spectral fidelity, and perceptual quality over GAN, diffusion, and mean-flow baselines, with gains up to 26.3% in overall perceptual quality, particularly in artifact-heavy segments. Code is stated to be available.
Significance. If the reported gains are reproducible and statistically supported, the work would offer a stable deterministic alternative to stochastic diffusion or GAN-based EEG-to-speech methods, addressing challenges of EEG spatial diffuseness and variability through explicit trajectory modeling. The use of conditional flow matching with shared tokens is a natural extension of existing transport frameworks and could benefit non-invasive speech BCIs. Code availability supports potential reproducibility.
major comments (2)
- [Abstract] Abstract: The central empirical claim of up to 26.3% gain in perceptual quality (and improvements in distributional realism and spectral fidelity) is presented without any accompanying statistical tests, error bars, baseline reproduction details, ablation results, or specification of the exact perceptual metric and cross-subject splits. This information is load-bearing for assessing whether the gains support the proposed formulation over the cited baselines.
- [Abstract] Abstract: No implementation details, model hyperparameters, training procedures, or dataset preprocessing steps are supplied despite the performance claims on CineBrain and EAV; without these, the reported advantages of the time-conditioned gated Transformer parameterization of the transport ODE cannot be independently verified.
minor comments (1)
- [Abstract] The abstract refers to 'representative GAN-, diffusion-, and mean-flow baselines' without naming the specific methods or citations; adding these would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where the abstract could better support the empirical claims. We address each point below and will revise the manuscript accordingly to improve clarity, reproducibility, and verifiability of the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of up to 26.3% gain in perceptual quality (and improvements in distributional realism and spectral fidelity) is presented without any accompanying statistical tests, error bars, baseline reproduction details, ablation results, or specification of the exact perceptual metric and cross-subject splits. This information is load-bearing for assessing whether the gains support the proposed formulation over the cited baselines.
Authors: We agree that the abstract would be strengthened by explicit references to these elements. In the revised version, we will specify the perceptual metric (overall perceptual quality), the cross-subject evaluation protocol on CineBrain and EAV, and add a parenthetical reference to the statistical tests, error bars, and ablation results presented in the experimental sections. Baseline reproduction details are already described in Section 4; we will ensure the abstract points readers to these supporting analyses without exceeding length constraints. revision: yes
-
Referee: [Abstract] Abstract: No implementation details, model hyperparameters, training procedures, or dataset preprocessing steps are supplied despite the performance claims on CineBrain and EAV; without these, the reported advantages of the time-conditioned gated Transformer parameterization of the transport ODE cannot be independently verified.
Authors: The abstract is intentionally concise, but the full manuscript details the model architecture, hyperparameters, training procedures, and preprocessing in the Methods and Experimental Setup sections, with the linked code repository providing the complete implementation. We will revise the abstract to include a brief high-level description of the time-conditioned gated Transformer and EEG/audio tokenization, along with a pointer to the code and supplementary material for full reproducibility. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces NeuroSonic as an application of standard conditional flow matching, where EEG and audio are embedded into shared tokens processed by a time-conditioned gated Transformer to parameterize a deterministic velocity field for the transport ODE. This follows directly from established flow-matching formulations without any reduction of the claimed transport or performance gains to fitted inputs by construction, self-definitional mappings, or load-bearing self-citations. All reported gains (e.g., 26.3% perceptual quality) are empirical results on external benchmarks (CineBrain, EAV) under cross-subject evaluation, with no enumerated circularity patterns present in the derivation chain or abstract claims.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neuroimage194, 82–92 (2019)
Bréchet, L., Brunet, D., Birot, G., Gruetter, R., Michel, C.M., Jorge, J.: Capturing the spatiotemporal dynamics of self-generated, task-initiated thoughts with eeg and fmri. Neuroimage194, 82–92 (2019)
2019
-
[2]
(eds.): Semi-Supervised Learning
Chapelle, O., Schölkopf, B., Zien, A. (eds.): Semi-Supervised Learning. MIT Press, Cambridge, MA (2006)
2006
-
[3]
In: ICASSP
Chen, N., Liu, F., You, C., Zhou, P., Zou, Y.: Adaptive bi-directional attention: Exploring multi-granularity representations for machine reading comprehension. In: ICASSP. IEEE (2021)
2021
-
[4]
arXiv preprint arXiv:2106.02182 (2021)
Chen, N., You, C., Zou, Y.: Self-supervised dialogue learning for spoken conversa- tional question answering. arXiv preprint arXiv:2106.02182 (2021)
arXiv 2021
-
[5]
arXiv preprint arXiv:2401.10278 (2024)
Chen, Y., Ren, K., Song, K., Wang, Y., Wang, Y., Li, D., Qiu, L.: Eegformer: Towards transferable and interpretable large-scale eeg foundation model. arXiv preprint arXiv:2401.10278 (2024)
arXiv 2024
-
[6]
arXiv preprint arXiv:2503.06940 (2025)
Gao, J., Liu, Y., Yang, B., Feng, J., Fu, Y.: Cinebrain: A large-scale multi-modal brain dataset during naturalistic audiovisual narrative processing. arXiv preprint arXiv:2503.06940 (2025)
arXiv 2025
-
[7]
arXiv preprint arXiv:2505.13447 (2025)
Geng, Z., Deng, M., Bai, X., Kolter, J.Z., He, K.: Mean flows for one-step generative modeling. arXiv preprint arXiv:2505.13447 (2025)
Pith/arXiv arXiv 2025
-
[8]
Advances in neural information processing systems27(2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in neural information processing systems27(2014)
2014
-
[9]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention (2023)
Han, K., Xiong, Y., You, C., Khosravi, P., Sun, S., Yan, X., Duncan, J.S., Xie, X.: Medgen3d: A deep generative framework for paired 3d image and mask generation. In: International Conference on Medical Image Computing and Computer-Assisted Intervention (2023)
2023
-
[10]
Advances in neural information processing systems33, 6840–6851 (2020) 10 W
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 10 W. Gao et al
2020
-
[11]
Advances in neural information processing systems33, 17022–17033 (2020)
Kong, J., Kim, J., Bae, J.: HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in neural information processing systems33, 17022–17033 (2020)
2020
-
[12]
Scientific data11(1), 1026 (2024)
Lee, M.H., Shomanov, A., Begim, B., Kabidenova, Z., Nyssanbay, A., Yazici, A., Lee, S.W.: EAV: EEG-audio-video dataset for emotion recognition in conversational contexts. Scientific data11(1), 1026 (2024)
2024
-
[13]
In: Proceedings of the AAAI conference on artificial intelligence (2023)
Lee, Y.E., Lee, S.H., Kim, S.H., Lee, S.W.: Towards voice reconstruction from eeg during imagined speech. In: Proceedings of the AAAI conference on artificial intelligence (2023)
2023
-
[14]
arXiv preprint arXiv:2511.13720 (2025)
Li, T., He, K.: Back to basics: Let denoising generative models denoise. arXiv preprint arXiv:2511.13720 (2025)
Pith/arXiv arXiv 2025
-
[15]
arXiv preprint arXiv:2210.02747 (2022)
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
Pith/arXiv arXiv 2022
-
[16]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2021)
Liu, F., Wu, X., You, C., Ge, S., Zou, Y., Sun, X.: Aligning source visual and target language domains for unpaired video captioning. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021)
2021
-
[17]
Scientific Data 9(1), 531 (2022)
Ma, J., Yang, B., Qiu, W., Li, Y., Gao, S., Xia, X.: A large eeg dataset for studying cross-session variability in motor imagery brain-computer interface. Scientific Data 9(1), 531 (2022)
2022
-
[18]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention (2023)
Ma, J., Zhu, Y., You, C., Wang, B.: Pre-trained diffusion models for plug-and- play medical image enhancement. In: International Conference on Medical Image Computing and Computer-Assisted Intervention (2023)
2023
-
[19]
Oxford university press (2006)
Nunez, P.L., Srinivasan, R.: Electric fields of the brain: the neurophysics of EEG. Oxford university press (2006)
2006
-
[20]
In: IEEE International Conference on Acoustics, Speech and Signal Processing
Reddy, C.K., Gopal, V., Cutler, R.: DNSMOS: A non-intrusive perceptual objec- tive speech quality metric to evaluate noise suppressors. In: IEEE International Conference on Acoustics, Speech and Signal Processing. pp. 6493–6497 (2021)
2021
-
[21]
arXiv preprint arXiv:2511.19917 (2025)
Ren, Q., Wang, Y., Guo, L., Zhang, W., Fan, Z., You, C.: Scale where it matters: Training-free localized scaling for diffusion models. arXiv preprint arXiv:2511.19917 (2025)
arXiv 2025
-
[22]
arXiv preprint arXiv:2301.11757 (2023)
Schneider, F., Kamal, O., Jin, Z., Schölkopf, B.: Mo\ˆ usai: Text-to-music generation with long-context latent diffusion. arXiv preprint arXiv:2301.11757 (2023)
arXiv 2023
-
[23]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
Sun, S., Wang, Y., Zhang, H., Xiong, Y., Ren, Q., Fang, R., Xie, X., You, C.: Ouroboros: Single-step diffusion models for cycle-consistent forward and inverse rendering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (2025)
2025
-
[24]
arXiv e-prints pp
Vo, T.N., Vu, S.T., Tran, T.T., Nguyen, M.D., Do, T., Lin, C.T., et al.: Inter-and intra-subject variability in eeg: A systematic survey. arXiv e-prints pp. arXiv–2602 (2026)
2026
-
[25]
arXiv preprint arXiv:2605.21280 (2026)
Wang, Y., Ma, Y., Li, W., You, C.: Let eeg models learn eeg. arXiv preprint arXiv:2605.21280 (2026)
Pith/arXiv arXiv 2026
-
[26]
Bioengineering13(3), 370 (2026)
Xiang, S., Ling, H., Wu, M.: Cross-modal alignment and rectified flow-based latent representation synthesis for enhanced speech-driven alzheimer’s disease detection. Bioengineering13(3), 370 (2026)
2026
-
[27]
Frontiers in human neuroscience14, 103 (2020)
Xu, L., Xu, M., Ke, Y., An, X., Liu, S., Ming, D.: Cross-dataset variability problem in eeg decoding with deep learning. Frontiers in human neuroscience14, 103 (2020)
2020
-
[28]
Yang, D., Zhang, Y., Yu, X., Hou, L., Tao, X., Wan, P., Qi, X., Liao, R.: Stable velocity: A variance perspective on flow matching. arXiv preprint arXiv:2602.05435 (2026) NeuroSonic: Conditional Flow Matching for EEG-to-Speech Reconstruction 11
Pith/arXiv arXiv 2026
-
[29]
Nature Communications (2025)
You, C., Dai, H., Min, Y., Sekhon, J.S., Joshi, S., Duncan, J.S.: Uncovering memorization effect in the presence of spurious correlations. Nature Communications (2025)
2025
-
[30]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
You, C., Mint, Y., Dai, W., Sekhon, J.S., Staib, L., Duncan, J.S.: Calibrating multi-modal representations: A pursuit of group robustness without annotations. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.