DTT-BSR+: A Generative-Regression Cascade for Music Source Restoration
Pith reviewed 2026-06-25 23:13 UTC · model grok-4.3
The pith
A generative first stage followed by regression refinement improves music source restoration by decoupling distribution fitting from signal reconstruction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
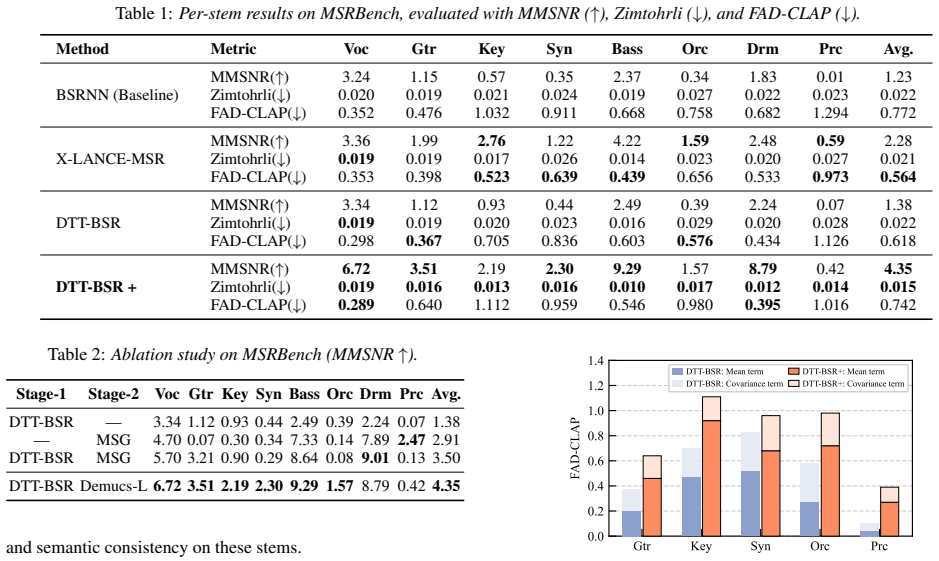
DTT-BSR+ is a two-stage cascade MSR system where a generative DTT-BSR separator first produces stems matching the prior of clean sources, and a modified Demucs network in the second stage enhances the output using time-domain and multi-resolution spectral losses. This produces improved MMSNR over the single-stage DTT-BSR across all stems and surpasses the X-LANCE MSR system on five stems, while FAD decomposition reveals an implicit trade-off between signal reconstruction accuracy and semantic distribution fitting across stems.
What carries the argument
The generative-regression cascade that separates distribution fitting in the first stage from signal reconstruction in the second stage.
If this is right
- MMSNR improves over the single-stage DTT-BSR across every evaluated stem.
- The system surpasses the prior X-LANCE MSR baseline on five stems.
- FAD decomposition identifies a trade-off between reconstruction accuracy and semantic distribution fitting that differs across stems.
- Separating the two objectives allows each stage to optimize its target without direct conflict.
Where Pith is reading between the lines
- The same staged separation could be applied to other audio tasks that require both semantic consistency and precise waveform recovery.
- Single-stage models may face an inherent limit when forced to optimize distribution and reconstruction simultaneously.
- Adding a third stage focused on a remaining objective could be tested if the two-stage trade-off persists.
Load-bearing premise
The generative first-stage separator produces stems whose distribution is close enough to clean sources that the second-stage regression network can meaningfully improve reconstruction without introducing new inconsistencies or losing critical information.
What would settle it
A test showing that MMSNR does not increase or decreases when the regression stage is applied to the generative stage outputs, or that the full system fails to surpass X-LANCE on the five claimed stems.
Figures


read the original abstract
Music source restoration (MSR) requires jointly addressing source unmixing and the inversion of non-linear production effects. Current methods struggle to achieve accurate target signal reconstruction while maintaining semantic consistency. To address this limitation, we propose DTT-BSR+, a two-stage cascade MSR system that decouples distribution fitting from signal reconstruction into separate stages. A generative DTT-BSR separator in the first stage produces stems matching the prior of clean sources, and a modified Demucs network in the second stage enhances the first stage output using time-domain and multi-resolution spectral losses. DTT-BSR+ improves multi-mel signal-to-noise ratio (MMSNR) over the single-stage DTT-BSR across all stems, and surpasses the state-of-the-art X-LANCE MSR system on five stems. We also reveal through Fr\'echet Audio Distance (FAD) decomposition an implicit trade-off between signal reconstruction accuracy and semantic distribution fitting across stems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DTT-BSR+, a two-stage cascade for music source restoration (MSR) that decouples distribution fitting from signal reconstruction. The first stage employs a generative DTT-BSR separator to produce stems whose distribution matches clean sources; the second stage applies a modified Demucs network trained with time-domain and multi-resolution spectral losses. The central empirical claims are that DTT-BSR+ improves multi-mel signal-to-noise ratio (MMSNR) over the single-stage DTT-BSR baseline across all stems and surpasses the X-LANCE MSR system on five stems, together with an observed trade-off between reconstruction accuracy and semantic distribution fitting revealed by Fréchet Audio Distance (FAD) decomposition.
Significance. If the reported MMSNR gains and the FAD-based trade-off analysis hold under rigorous controls, the explicit cascade design would offer a useful architectural insight for MSR systems that must jointly solve unmixing and non-linear effect inversion. The decomposition of FAD into reconstruction and distribution components is a constructive analytical contribution that could generalize beyond this specific architecture.
major comments (2)
- [Abstract / Results] Abstract and results section: the claims of MMSNR improvement over DTT-BSR across all stems and over X-LANCE on five stems are stated without any accompanying experimental protocol, dataset description, number of test items, statistical tests, or error bars. These omissions render the quantitative claims unverifiable from the supplied text and constitute a load-bearing gap for the central empirical contribution.
- [Method / Experiments] The weakest modeling assumption—that the generative first-stage output lies sufficiently close to the clean-source distribution for the regression stage to improve reconstruction without introducing new inconsistencies—is tested only by the single-stage vs. cascade comparison. No ablation isolating the effect of distribution mismatch (e.g., via controlled noise injection or distribution-distance metrics between first-stage output and clean references) is described.
minor comments (2)
- [Abstract] Notation: “multi-mel signal-to-noise ratio (MMSNR)” is introduced without an explicit formula or reference to its definition; a short equation or citation would improve reproducibility.
- [Method] The phrase “modified Demucs network” is used without specifying which architectural changes (e.g., loss weights, input conditioning, or layer modifications) distinguish it from the original Demucs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve verifiability and analysis of the modeling assumptions.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and results section: the claims of MMSNR improvement over DTT-BSR across all stems and over X-LANCE on five stems are stated without any accompanying experimental protocol, dataset description, number of test items, statistical tests, or error bars. These omissions render the quantitative claims unverifiable from the supplied text and constitute a load-bearing gap for the central empirical contribution.
Authors: We agree that the abstract and results statements as written omit key experimental details. The full manuscript describes the evaluation protocol, datasets, and test configurations in the Experiments section, but to make the central claims self-contained and verifiable, we will expand the Results section with a concise summary of the protocol, number of test items, and any statistical measures or error bars available. revision: yes
-
Referee: [Method / Experiments] The weakest modeling assumption—that the generative first-stage output lies sufficiently close to the clean-source distribution for the regression stage to improve reconstruction without introducing new inconsistencies—is tested only by the single-stage vs. cascade comparison. No ablation isolating the effect of distribution mismatch (e.g., via controlled noise injection or distribution-distance metrics between first-stage output and clean references) is described.
Authors: The single-stage vs. cascade MMSNR comparison provides empirical support that the regression stage yields net improvement, indicating the generative outputs are close enough for beneficial refinement. We acknowledge that an explicit ablation (e.g., controlled mismatch metrics) would more directly isolate the assumption. We will add discussion of this point and, where feasible, supplementary distribution-distance analysis in the revision. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical two-stage MSR cascade (generative DTT-BSR separator followed by modified Demucs regression) and reports direct performance gains on MMSNR and an observed FAD trade-off. No equations, derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided abstract or claim structure. The central results are external empirical comparisons against single-stage baselines and X-LANCE, with the cascade assumption tested by the reported single-vs-two-stage contrast. This is self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Music source restoration (MSR) [1] aims to estimate clean, un- processed stems from a mixture. The difficulty lies in the non- linear production effects applied to each stem during music cre- ation, such as dynamic range compression [2, 3] and codec encoding [4]. Accurate estimation requires jointly addressing source unmixing and the inversio...
Pith/arXiv arXiv 2026
-
[2]
Problem Formulation In MSS, the time-domain observed mixturey∈R T is mod- eled as a sum ofCsource signals, i.e.,y= PC c=1 xc, where xc ∈R T denotes thec-th source, and the goal is to estimate eachx c fromy[8]. MSR extends this by modeling each source asx c =f c(sc), wheres c ∈R T is the clean, unprocessed stem andf c models the production effects, which m...
-
[3]
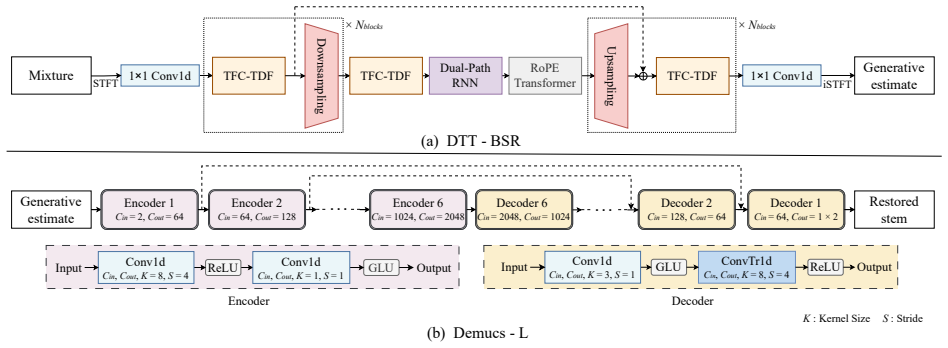
Proposed Method: DTT-BSR+ We propose DTT-BSR+, a two-stage cascade MSR system il- lustrated in Figure 2. The first stage employs a GAN-based separator to separate the target stem from the degraded mixture, with the adversarial objective constraining the output distribu- tion toward that of the clean and unprocessed stem. The second stage enhances the firs...
-
[4]
Experiment 4.1. Dataset The proposed system is trained and evaluated on MSR- Bench [22], a benchmark dataset for music source restora- tion comprising3250stereo clips at48kHz, each10seconds in duration, with parallel degraded mixtures and unprocessed ground-truth stems. The dataset is split into2600training,325 validation, and325test clips. The first stag...
-
[5]
Results and Analysis We evaluate DTT-BSR+ against three systems. BSRNN [25] is a single-stage system serving as the official baseline of the ICASSP 2026 MSR Challenge. X-LANCE-MSR is a multi- stage system and the challenge winner representing the current state-of-the-art. DTT-BSR is a competitive single-stage system that also serves as the first stage com...
arXiv 2026
-
[6]
Conclusion We present DTT-BSR+, a two-stage cascade MSR system de- coupling semantic distribution fitting from signal reconstruc- tion into separate stages, achieving consistent MMSNR im- provements over the single-stage DTT-BSR across all stems. Through FAD decomposition, we reveal an implicit trade-off between signal reconstruction accuracy and semantic...
-
[7]
The numerical calculations in this paper have been done on the supercomput- ing system in the Supercomputing Center of Wuhan University
Acknowledgments This work was supported by the National Natural Science Foun- dation (NSFC) of China under Grant 62471340. The numerical calculations in this paper have been done on the supercomput- ing system in the Supercomputing Center of Wuhan University
-
[8]
Generative AI Use Disclosure Google Gemini was used in this paper only for polishing the manuscript
-
[9]
Music Source Restoration,
Y . Zang, Z. Dai, M. D. Plumbley, and Q. Kong, “Music Source Restoration,” in2025 IEEE International Workshop on Multime- dia Signal Processing (MMSP), 2025, pp. 138–143
2025
-
[10]
Digital Dynamic Range Compressor Design—A Tutorial and Analysis,
D. Giannoulis, M. Massberg, and J. Reiss, “Digital Dynamic Range Compressor Design—A Tutorial and Analysis,”AES: Journal of the Audio Engineering Society, vol. 60, 07 2012
2012
-
[11]
Dynamic range control of digital audio signals,
G. W. McNally, “Dynamic range control of digital audio signals,” Journal of the Audio Engineering Society, vol. 32, no. 5, pp. 316– 327, 1984
1984
-
[12]
MP3 Decoder in Theory and Practice,
P. Sripada, “MP3 Decoder in Theory and Practice,” 2006. [Online]. Available: https://api.semanticscholar.org/CorpusID: 61103574
2006
-
[13]
Hybrid Transformers for Music Source Separation,
S. Rouard, F. Massa, and A. D ´efossez, “Hybrid Transformers for Music Source Separation,” inICASSP 2023 - 2023 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5
2023
-
[14]
Mel-RoFormer for V ocal Sep- aration and V ocal Melody Transcription,
J.-C. Wang, W.-T. Lu, and J. Chen, “Mel-RoFormer for V ocal Sep- aration and V ocal Melody Transcription,” inProceedings of the 25th International Society for Music Information Retrieval Con- ference, 2024, pp. 454–461
2024
-
[15]
Towards Practical Real-Time Low-Latency Music Source Separation,
J. Wu, J. Liu, T. Pan, J. Tang, and G. Wu, “Towards Practical Real-Time Low-Latency Music Source Separation,” in2025 IEEE International Conference on Multimedia and Expo (ICME), 2025, pp. 1–6
2025
-
[16]
Musical source separation: An introduction,
E. Cano, D. FitzGerald, A. Liutkus, M. D. Plumbley, and F.-R. St¨oter, “Musical source separation: An introduction,”IEEE Sig- nal Processing Magazine, vol. 36, no. 1, pp. 31–40, 2019
2019
-
[17]
Summary of the inaugural music source restoration challenge,
Y . Zang, J. Hai, W. Ge, Q. Kong, Z. Dai, H. Wang, Y . Mitsufuji, and M. D. Plumbley, “Summary of the inaugural music source restoration challenge,” 2026. [Online]. Available: https://arxiv.org/abs/2601.04343
arXiv 2026
-
[18]
The SJTU X-LANCE Lab System for MSR Challenge 2025,
J. Zhu, H. Qiu, H. Zhu, J. Yu, K. Yu, and X. Chen, “The SJTU X-LANCE Lab System for MSR Challenge 2025,” 2026. [Online]. Available: https://arxiv.org/abs/2602.09042
arXiv 2025
-
[19]
Music source separation with band-split rope transformer,
W.-T. Lu, J.-C. Wang, Q. Kong, and Y .-N. Hung, “Music source separation with band-split rope transformer,” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 481–485
2024
-
[20]
DTT-BSR: GAN-based DTTNet with RoPE Transformer Enhancement for Music Source Restoration,
S. Tan, H. Wang, Y . Ni, Y . Hou, J. Luo, Z. Hu, H. Dou, Z. Han, N. Pan, Y . Wang, and G. Huang, “DTT-BSR: GAN-based DTTNet with RoPE Transformer Enhancement for Music Source Restoration,” 2026. [Online]. Available: https://arxiv.org/abs/2602.19825
arXiv 2026
-
[21]
Music Source Separation Based on a Lightweight Deep Learning Framework (DTTNET: DUAL-PATH TFC-TDF UNET),
J. Chen, S. Vekkot, and P. Shukla, “Music Source Separation Based on a Lightweight Deep Learning Framework (DTTNET: DUAL-PATH TFC-TDF UNET),” inICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2024, pp. 656–660
2024
-
[22]
Fr ´echet Au- dio Distance: A Reference-Free Metric for Evaluating Music En- hancement Algorithms,
K. Kilgour, M. Zuluaga, D. Roblek, and M. Sharifi, “Fr ´echet Au- dio Distance: A Reference-Free Metric for Evaluating Music En- hancement Algorithms,” inInterspeech 2019, 2019, pp. 2350– 2354
2019
-
[23]
Music source separation in the waveform domain,
A. D ´efossez, N. Usunier, L. Bottou, and F. Bach, “Music source separation in the waveform domain,” 2019. [Online]. Available: https://arxiv.org/abs/1911.13254
arXiv 2019
-
[24]
Music Separation Enhancement with Generative Modeling,
N. Schaffer, B. Cogan, E. Manilow, M. Morrison, P. Seetharaman, and B. Pardo, “Music Separation Enhancement with Generative Modeling,” inProceedings of the 23rd International Society for Music Information Retrieval Conference, 2022. [Online]. Available: https://archives.ismir.net/ismir2022/paper/000093.pdf
2022
-
[25]
Sparse graphic equalizer design,
M. Antonelli, J. Liski, and V . V¨alim¨aki, “Sparse graphic equalizer design,”IEEE Signal Processing Letters, vol. 29, pp. 1659–1663, 2022
2022
-
[26]
Audio nonlinear modeling through hyperbolic tangent functionals,
A. Schuck Jr and B. E. J. Bodmann, “Audio nonlinear modeling through hyperbolic tangent functionals,” inProceedings of the 19th International Conference on Digital Audio Effects (DAFx- 16), Brno, Czech Republic, 2016, pp. 5–9
2016
-
[27]
J. O. Smith III,Physical audio signal processing: For virtual mu- sical instruments and audio effects. W3K Publishing, 2010, on- line book available at https://ccrma.stanford.edu/ jos/pasp/
2010
-
[28]
Language modeling with gated convolutional networks,
Y . N. Dauphin, A. Fan, M. Auli, and D. Grangier, “Language modeling with gated convolutional networks,” inInternational conference on machine learning. PMLR, 2017, pp. 933–941
2017
-
[29]
Parallel wavegan: A fast waveform generation model based on generative adversarial net- works with multi-resolution spectrogram,
R. Yamamoto, E. Song, and J.-M. Kim, “Parallel wavegan: A fast waveform generation model based on generative adversarial net- works with multi-resolution spectrogram,” inICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 6199–6203
2020
-
[30]
MSRBench: A Benchmarking Dataset for Music Source Restoration,
Y . Zang, J. Hai, W. Ge, Q. Kong, Z. Dai, H. Wang, Y . Mitsufuji, and M. D. Plumbley, “MSRBench: A Benchmarking Dataset for Music Source Restoration,” 2025. [Online]. Available: https://arxiv.org/abs/2510.10995
arXiv 2025
-
[31]
Adam: A method for stochastic opti- mization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic opti- mization,” in3rd International Conference on Learning Repre- sentations, ICLR 2015, 2015
2015
-
[32]
Zimtohrli: An efficient psychoacoustic audio similarity metric,
J. Alakuijala, M. Bruse, S. Boukortt, J. M. Coldenhoff, and M. Cernak, “Zimtohrli: An efficient psychoacoustic audio similarity metric,” 2025. [Online]. Available: https: //arxiv.org/abs/2509.26133
arXiv 2025
-
[33]
Music source separation with band-split rnn,
Y . Luo and J. Yu, “Music source separation with band-split rnn,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 31, pp. 1893–1901, 2023
1901
-
[34]
Tf- locoformer: Transformer with local modeling by convolution for speech separation and enhancement,
K. Saijo, G. Wichern, F. G. Germain, Z. Pan, and J. L. Roux, “Tf- locoformer: Transformer with local modeling by convolution for speech separation and enhancement,” in2024 18th International Workshop on Acoustic Signal Enhancement (IWAENC), 2024, pp. 205–209
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.