AsyncOPD: How Stale Can On-Policy Distillation Be?
Pith reviewed 2026-06-26 00:38 UTC · model grok-4.3
The pith
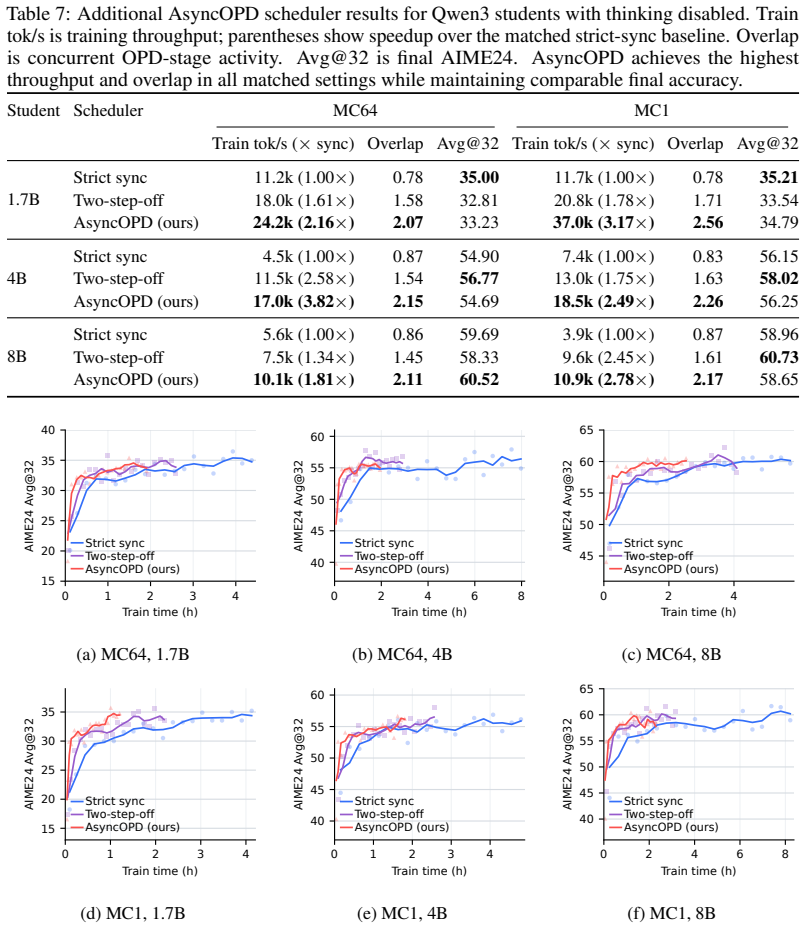
Asynchronous on-policy distillation with finite teacher caches reaches comparable accuracy at 1.6× to 3.8× higher throughput than synchronous training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
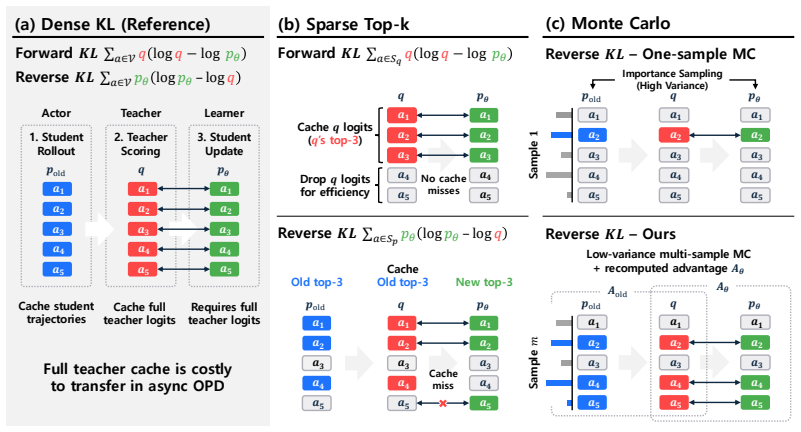
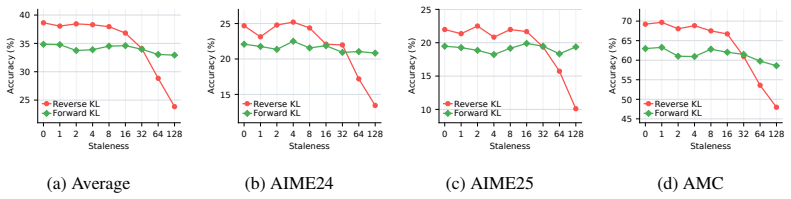
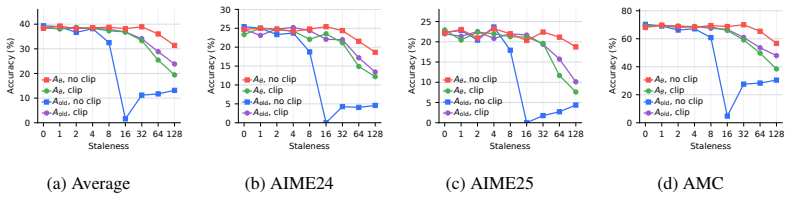
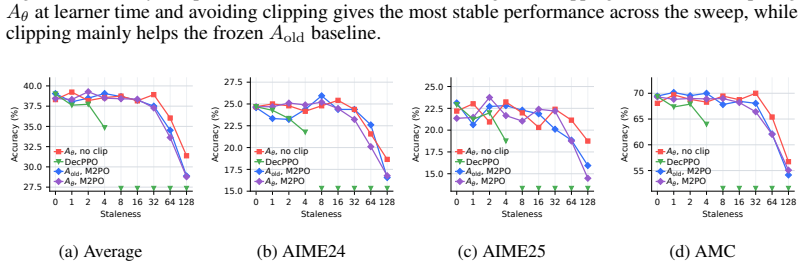
On-policy distillation faces an on-policy systems bottleneck similar to RL because rollouts dominate time. Asynchronous pipelines introduce stale-policy data, and the study finds that teacher-weighted forward KL is robust to this staleness whereas student-weighted reverse KL is vulnerable. For reverse KL, recomputing the signal under the current student works better than borrowed RL techniques. Finite caches create bias-variance issues best addressed by multi-sample Monte Carlo, which preserves MC correctability while lowering one-sample variance. The resulting AsyncOPD pipeline improves throughput by 1.6× to 3.8× over strict synchronous training while reaching comparable accuracy.
What carries the argument
Recomputed reverse-KL estimators with multi-sample Monte Carlo correction on finite teacher-score caches, which manage staleness-induced bias and variance in local KL losses.
If this is right
- Teacher-weighted forward KL remains accurate even with stale rollouts.
- Recomputing the reverse-KL signal at learner time stabilizes training better than RL-derived stabilization methods.
- Multi-sample Monte Carlo reduces variance in sparse and sampled reverse-KL estimators while preserving correctability.
- Fully asynchronous OPD pipelines become practical without major accuracy penalties.
- Training throughput rises by 1.6× to 3.8× while accuracy stays comparable to synchronous baselines.
Where Pith is reading between the lines
- The same estimator choices could reduce the rollout bottleneck in other teacher-guided on-policy methods beyond distillation.
- Adaptive cache sizing or dynamic sample counts might further tune the bias-variance tradeoff as model scale increases.
- OPD appears to have different staleness sensitivities than standard asynchronous RL, suggesting OPD-specific analysis is needed rather than direct transfer of RL techniques.
- At even larger scales where rollout time dominates more severely, the relative throughput gains from asynchrony could exceed the reported range.
Load-bearing premise
The practical setting of local KL losses with finite teacher-score caches represents the dominant failure modes of stale reverse-KL estimators in future large-scale OPD.
What would settle it
An experiment on a workload where full-vocabulary teacher logits can be stored and transferred without cost, showing whether accuracy remains comparable when the finite-cache assumption is removed.
Figures

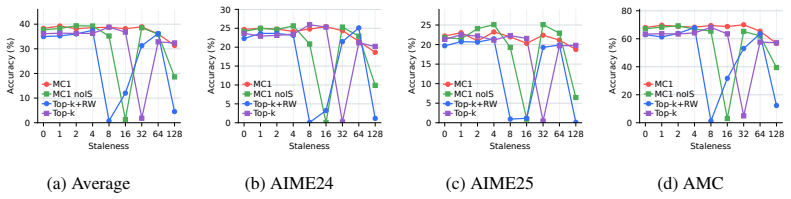
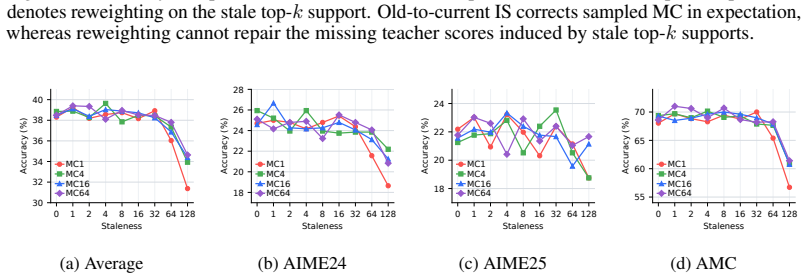


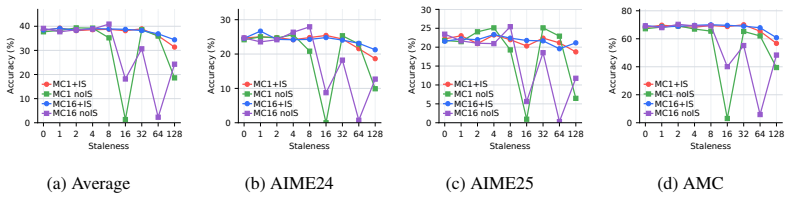
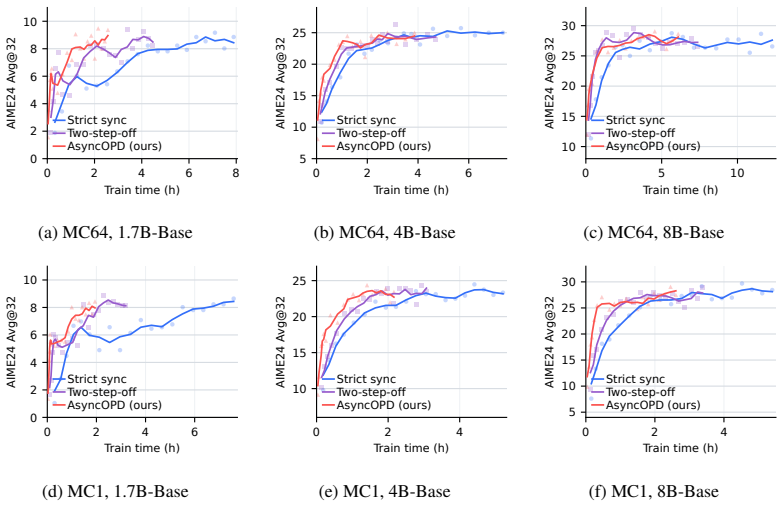
read the original abstract
On-policy distillation (OPD) trains a student on its own rollouts guided by teacher feedback and is becoming increasingly important for large language model (LLM) post-training. Like reinforcement learning (RL), however, OPD faces an on-policy systems bottleneck, as rollouts can dominate training time for reasoning workloads. Asynchronous training pipelines can alleviate this bottleneck by decoupling rollout generation from learner updates, but doing so introduces stale-policy data. While prior work has studied stale data in asynchronous RL, its effects in OPD remain underexplored. We present the first systematic study of staleness in asynchronous OPD, focusing on a practical setting where teacher feedback is implemented through local KL losses and full-vocabulary teacher logits are too expensive to store or transfer, necessitating finite teacher-score caches. We first show that KL direction changes the stale-data problem: teacher-weighted forward KL is more robust to stale rollouts, whereas student-weighted reverse KL is vulnerable. Second, for this vulnerable reverse-KL case, we study whether methods designed to stabilize asynchronous RL can mitigate OPD staleness. In our experiments, they do not improve over a simpler OPD-specific surrogate: recomputing the reverse-KL signal under the current student at learner time. Third, we analyze how finite teacher-score caches create a bias-variance tradeoff for sparse and sampled reverse-KL OPD estimators. This motivates multi-sample Monte Carlo (MC), which preserves MC correctability while reducing one-sample variance. Finally, we present and open-source AsyncOPD, a fully asynchronous OPD training pipeline built from these estimator choices. Experiments show that AsyncOPD improves training throughput by $1.6\times$ to $3.8\times$ over strict synchronous training while reaching comparable accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first systematic study of staleness effects in asynchronous on-policy distillation (OPD) for LLMs. Focusing on the practical setting of local KL losses with finite teacher-score caches (as full logits are too expensive), it shows that teacher-weighted forward KL is more robust to stale rollouts than student-weighted reverse KL; for the latter, a simple OPD-specific surrogate (recomputing reverse KL under the current student) outperforms methods from async RL; it analyzes the bias-variance tradeoff induced by finite caches and motivates multi-sample Monte Carlo estimators; and it introduces and open-sources AsyncOPD, which delivers 1.6×–3.8× throughput gains over synchronous training while reaching comparable accuracy.
Significance. If the empirical results hold, the work is significant for scaling LLM post-training pipelines, where rollout time dominates. The open-sourcing of AsyncOPD and the internally coherent bias-variance analysis of the cache-based reverse-KL estimators are clear strengths that support reproducibility and future work. The finding that KL direction qualitatively changes the stale-data problem is a useful conceptual contribution.
major comments (2)
- [Experiments] Experiments (throughput/accuracy tables and figures): the manuscript reports no variance or standard deviation across random seeds for the 1.6×–3.8× throughput and accuracy comparisons. This makes it difficult to assess whether the “comparable accuracy” claim is statistically reliable or sensitive to initialization.
- [Finite-cache analysis] Finite-cache analysis and MC surrogate section: while the bias-variance tradeoff for sparse/sampled reverse-KL estimators is derived, the paper provides no additional ablation varying cache size (beyond the main figures) or sampling density. Because the central claim rests on the practical finite-cache regime, this omission leaves open whether the observed robustness and throughput gains are sensitive to cache-size choices that would appear at larger scale.
minor comments (1)
- Notation for the MC surrogate and cache estimators could be clarified with an explicit algorithm box or pseudocode to make the bias-correction step easier to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation for minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments (throughput/accuracy tables and figures): the manuscript reports no variance or standard deviation across random seeds for the 1.6×–3.8× throughput and accuracy comparisons. This makes it difficult to assess whether the “comparable accuracy” claim is statistically reliable or sensitive to initialization.
Authors: We agree that variance across random seeds would strengthen assessment of the comparable-accuracy claim. Our reported results used single seeds owing to the substantial compute cost of large-scale LLM training; in the revision we will rerun the key throughput/accuracy comparisons with 3–5 seeds and report means plus standard deviations. revision: yes
-
Referee: [Finite-cache analysis] Finite-cache analysis and MC surrogate section: while the bias-variance tradeoff for sparse/sampled reverse-KL estimators is derived, the paper provides no additional ablation varying cache size (beyond the main figures) or sampling density. Because the central claim rests on the practical finite-cache regime, this omission leaves open whether the observed robustness and throughput gains are sensitive to cache-size choices that would appear at larger scale.
Authors: The main experimental figures already vary cache size across the asynchronous regimes studied. To further address sensitivity at larger scales we will add an explicit ablation on cache size and sampling density (e.g., in an appendix) in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical throughput claims rest on external synchronous baselines
full rationale
The paper presents an empirical study of staleness effects in asynchronous OPD, proposing estimator choices (local KL, finite caches, MC surrogate for reverse KL) and validating them via direct measurements of throughput (1.6×–3.8×) and accuracy against strict synchronous training. No derivation chain, uniqueness theorem, or fitted parameter is invoked whose output is definitionally equivalent to its input; all performance numbers are obtained from external code baselines and workloads. The bias-variance analysis of cache-based estimators follows standard Monte Carlo principles without self-referential reduction. This is the normal case of a self-contained experimental paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agarwal, N
R. Agarwal, N. Vieillard, Y . Zhou, P. Stanczyk, S. R. Garea, M. Geist, and O. Bachem. On- policy distillation of language models: Learning from self-generated mistakes. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=3zKtaqxLhW
2024
-
[2]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
2026
-
[3]
Devvrit, L
F. Devvrit, L. Madaan, R. Tiwari, R. Bansal, S. S. Duvvuri, M. Zaheer, I. S. Dhillon, D. Brandfonbrener, and R. Agarwal. The art of scaling reinforcement learning compute for LLMs. InThe F ourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=FMjeC9Msws
2026
-
[4]
W. Fu, J. Gao, X. Shen, C. Zhu, Z. Mei, C. He, S. Xu, G. Wei, J. Mei, W. JIASHU, T. Yang, B. Yuan, and Y . Wu. AREAL: A large-scale asynchronous reinforcement learning system for language reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=X9diEuva9R
2025
-
[5]
W. Gao, Y . Zhao, D. An, T. Wu, L. Cao, S. Xiong, J. Huang, W. Wang, S. Yang, W. Su, et al. Rollpacker: Mitigating long-tail rollouts for fast, synchronous rl post-training.arXiv preprint arXiv:2509.21009, 2025
arXiv 2025
-
[6]
Y . Gu, L. Dong, F. Wei, and M. Huang. MiniLLM: Knowledge distillation of large language models. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=5h0qf7IBZZ
2024
-
[7]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 10
Pith/arXiv arXiv 2025
-
[8]
Z. He, T. Liang, J. Xu, Q. Liu, X. Chen, Y . Wang, L. Song, D. Yu, Z. Liang, W. Wang, et al. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning.arXiv preprint arXiv:2504.11456, 2025
Pith/arXiv arXiv 2025
-
[9]
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[10]
X. Li, S. Wu, and Z. Shen. A-3po: Accelerating asynchronous llm training with staleness-aware proximal policy approximation.arXiv preprint arXiv:2512.06547, 2025
arXiv 2025
-
[11]
Y . Li, Y . Zuo, B. He, J. Zhang, C. Xiao, C. Qian, T. Yu, H.-a. Gao, W. Yang, Z. Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
Pith/arXiv arXiv 2026
-
[12]
On-policy distillation.ThinkingMachinesLab: Connectionism, 2025
K. Lu and T. M. Lab. On-policy distillation.Thinking Machines Lab: Connectionism, 2025. doi: 10.64434/tml.20251026. https://thinkingmachines.ai/blog/on-policy-distillation
-
[13]
American Mathematics Competitions – AMC
Mathematical Association of America. American Mathematics Competitions – AMC. https: //maa.org/, 2023. Accessed 2026-04-03
2023
-
[14]
Noukhovitch, S
M. Noukhovitch, S. Huang, S. Xhonneux, A. Hosseini, R. Agarwal, and A. Courville. Faster, more efficient RLHF through off-policy asynchronous learning. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=FhTAG591Ve
2025
-
[15]
Paszke, S
A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer. Automatic differentiation in PyTorch. InNIPS-W, 2017
2017
-
[16]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[17]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
- [18]
-
[19]
Sheng, C
G. Sheng, C. Zhang, Z. Ye, X. Wu, W. Zhang, R. Zhang, Y . Peng, H. Lin, and C. Wu. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
2025
-
[20]
M. Song and M. Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626, 2026
Pith/arXiv arXiv 2026
-
[21]
B. Xiao, B. Xia, B. Yang, B. Gao, B. Shen, C. Zhang, C. He, C. Lou, F. Luo, G. Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026
Pith/arXiv arXiv 2026
-
[22]
Y . Xu, H. Sang, Z. Zhou, R. He, Z. Wang, and A. Geramifard. Tip: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084, 2026
Pith/arXiv arXiv 2026
-
[23]
R. Yan, Y . Jiang, T. Wu, J. Gao, Z. Mei, W. Fu, H. Mai, W. Wang, Y . Wu, and B. Yuan. Areal-hex: Accommodating asynchronous rl training over heterogeneous gpus.arXiv preprint arXiv:2511.00796, 2025
arXiv 2025
-
[24]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[25]
W. Yang, W. Liu, R. Xie, K. Yang, S. Yang, and Y . Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026. 11
Pith/arXiv arXiv 2026
-
[26]
Q. Yu, Z. Zhang, R. Zhu, Y . Yuan, X. Zuo, Y . Yue, W. Dai, T. Fan, G. Liu, L. Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
Pith/arXiv arXiv 2025
-
[27]
A. Zeng, X. Lv, Z. Hou, Z. Du, Q. Zheng, B. Chen, D. Yin, C. Ge, C. Huang, C. Xie, et al. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
Pith/arXiv arXiv 2026
-
[28]
K. Zhang, Y . Zuo, B. He, Y . Sun, R. Liu, C. Jiang, Y . Fan, K. Tian, G. Jia, P. Li, et al. A survey of reinforcement learning for large reasoning models.arXiv preprint arXiv:2509.08827, 2025
Pith/arXiv arXiv 2025
- [29]
-
[30]
Zhang and T
Y . Zhang and T. Math-AI. AIME 2024. https://huggingface.co/datasets/ Maxwell-Jia/AIME_2024, 2024. Hugging Face dataset; accessed 2026-04-03
2024
-
[31]
Zhang and T
Y . Zhang and T. Math-AI. AIME 2025. https://huggingface.co/datasets/ yentinglin/aime_2025, 2025. Hugging Face dataset; accessed 2026-04-03
2025
-
[32]
S. Zhao, Z. Xie, M. Liu, J. Huang, G. Pang, F. Chen, and A. Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
Pith/arXiv arXiv 2026
-
[33]
Zheng, J
H. Zheng, J. Zhao, and B. Chen. Prosperity before collapse: How far can off-policy RL reach with stale data on LLMs? InThe F ourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=IIgl5MWelz
2026
-
[34]
Y . Zhong, Z. Zhang, X. Song, H. Hu, C. Jin, B. Wu, N. Chen, Y . Chen, Y . Zhou, C. Wan, et al. Streamrl: Scalable, heterogeneous, and elastic rl for llms with disaggregated stream generation. arXiv preprint arXiv:2504.15930, 2025. A Sparse and Monte Carlo Reverse-KL Implementations A.1 Sparse Top-kReverse-KL OPD The dense reverse-KL objective in Eq. (2) ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.