MorfFlex: Handling Rich Morphology
Pith reviewed 2026-06-25 23:57 UTC · model grok-4.3
The pith
MorfFlex encodes Czech morphology via inflectional and derivational patterns to manage a dictionary of over 100 million wordforms and one million lemmas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MorfFlex CZ is distributed as an unstructured list of wordform-lemma-tag triplets whose manually maintained, unpublished source files and conversion scripts encode a sophisticated system of inflectional and derivational patterns; these patterns dramatically reduce the otherwise enormous size of the dictionary, which contains over 100 million wordforms and more than one million lemmas, and the resource serves as the basis for consistent morphological annotation and advanced NLP applications.
What carries the argument
The system of inflectional and derivational patterns maintained in source files and expanded by conversion scripts, which generates the complete set of wordforms from a compact representation.
Load-bearing premise
The manually maintained source files and conversion scripts correctly and completely encode the full system of inflectional and derivational patterns for Czech without systematic gaps or errors.
What would settle it
A large-scale audit that finds many Czech wordforms missing from the generated dictionary or produced with incorrect tags would show the pattern system is incomplete.
Figures
read the original abstract
We present MorfFlex, a morphological dictionary architecture suitable for languages with extensive regularity in both inflection and derivation. As the primary example of MorfFlex in use we introduce MorfFlex CZ, a morphological dictionary of Czech. It is distributed as a simple, unstructured list of <wordform, lemma, tag> triplets, however, its manually maintained, unpublished source files and conversion scripts encode a sophisticated system of inflectional and derivational patterns. These patterns dramatically reduce the otherwise enormous size of the dictionary, which currently contains over 100 million wordforms and more than 1 million lemmas. The MorfFlex CZ dictionary serves as an essential resource for ensuring the consistency of manual morphological annotation in the Prague Dependency Treebanks and underpins state-of-the-art automatic tools such as MorphoDiTa. In this paper, we focus on: (i) presenting an effective method for managing the rich morphological system within the dictionary, and (ii) demonstrating the utility of such a language resource for maintaining annotation consistency in corpora and supporting the development of advanced NLP applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MorfFlex, a morphological dictionary architecture for languages with rich inflection and derivation. Using MorfFlex CZ for Czech as the main example, it describes a system where the distributed resource is a flat list of <wordform, lemma, tag> triplets, while the manually maintained (but unpublished) source files and conversion scripts encode sophisticated inflectional and derivational patterns. These patterns are stated to reduce the otherwise enormous size of a dictionary containing over 100 million wordforms and more than 1 million lemmas. The resource underpins annotation consistency in the Prague Dependency Treebanks and tools such as MorphoDiTa. The paper focuses on the management method and its utility for corpora and NLP applications.
Significance. If the patterns prove complete and correct, the architecture could provide an efficient, maintainable approach to large-scale morphological resources for morphologically complex languages, aiding annotation consistency and downstream tool development. The approach has potential applicability beyond Czech, but the manuscript supplies no concrete pattern examples, quantitative size-reduction measurements, or coverage/error analysis, so the practical significance cannot be evaluated from the provided text.
major comments (2)
- [Abstract] Abstract: the claim that the patterns 'dramatically reduce' the dictionary size (currently >100M wordforms, >1M lemmas) is unsupported; the manuscript contains no quantitative comparison of storage before/after pattern application, no count of patterns versus expanded forms, and no coverage statistics against an independent lexicon.
- [Abstract] Abstract: the size-reduction claim rests entirely on unpublished source files and conversion scripts whose completeness and correctness cannot be inspected; without at least a public subset of the pattern definitions or an independent verification experiment, the central efficiency argument remains unverifiable.
minor comments (1)
- The manuscript would be strengthened by including at least one worked example of an inflectional or derivational pattern together with the resulting triplet list.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. The paper's focus is the MorfFlex architecture for managing rich morphology and its role in annotation consistency and tool development, not a quantitative evaluation of storage efficiency. We address the two major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the patterns 'dramatically reduce' the dictionary size (currently >100M wordforms, >1M lemmas) is unsupported; the manuscript contains no quantitative comparison of storage before/after pattern application, no count of patterns versus expanded forms, and no coverage statistics against an independent lexicon.
Authors: We agree the manuscript provides no quantitative before/after measurements, pattern counts, or independent coverage statistics. The paper scope is limited to describing the management method and its utility for corpora and NLP tools; the size figures (>100M wordforms, >1M lemmas) are given only to indicate scale. The adverb 'dramatically' is therefore unsupported by data in the text. We will revise the abstract to remove this phrasing and any implication of measured efficiency gains. revision: yes
-
Referee: [Abstract] Abstract: the size-reduction claim rests entirely on unpublished source files and conversion scripts whose completeness and correctness cannot be inspected; without at least a public subset of the pattern definitions or an independent verification experiment, the central efficiency argument remains unverifiable.
Authors: The source files and scripts are maintained internally and are not released. The distributed resource consists solely of the public <wordform, lemma, tag> triplets, which have been used for years in the Prague Dependency Treebanks and MorphoDiTa, providing indirect validation through downstream applications. The paper does not present the size-reduction claim as a verified experimental result but as a description of the architecture that enables the observed scale. We cannot supply pattern definitions or run the requested verification experiment. revision: no
- Request for a public subset of the unpublished pattern definitions or an independent verification experiment on the source files
Circularity Check
No circularity; descriptive resource paper with no derivations or self-referential predictions
full rationale
The paper describes MorfFlex CZ as a morphological dictionary whose size reduction (to >100M wordforms, >1M lemmas) is attributed to manually maintained unpublished source files and conversion scripts that encode inflectional/derivational patterns. No equations, fitted parameters, predictions, uniqueness theorems, or ansatzes appear. No self-citations are load-bearing for any derivation. The size-reduction statement is presented as a factual consequence of the pattern system rather than a result derived from or equivalent to its own inputs by construction. This is a standard self-contained resource description without any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Over the course of many years of annotation work, numerous valuable linguistic resources (corpora and dictionaries) have been developed, forming the foundation for a wide range of successful appli- cationsandtoolsinthefieldofNLP.However,today the future of linguistic annotation lies at the inter- section of traditional computational linguisti...
Pith/arXiv arXiv 2004
-
[2]
SánchezGutiérrezetal.,2017)
Related Work In the context of NLP, morphology is primarily em- ployed in the development of tools that recognize relationships between wordforms (morphological analyzers, e.g.Voikko, 4 Hunmorph(Trón et al., 2005)) or between related words (derivative tools, e.g. SánchezGutiérrezetal.,2017). Manyofthese tools were originally created for spellchecking pur-...
2005
-
[3]
The lemma11 is the basic form of the wordform (usually such a form that is used as an entry in general dictionaries)
Morphological Dictionary MorfFlex The MorfFlex dictionary is a list of <wordform, lemma, tag> triplets. The lemma11 is the basic form of the wordform (usually such a form that is used as an entry in general dictionaries). The tag codes morphological properties of the wordform. The set of all wordforms with the same lemma is called a paradigm. The lemma is...
2017
-
[4]
creating derivations (new words), namely their lemmas
-
[5]
They are used for:
assigning inflectional patterns to every derived lemma The patterns in the intermediate format arein- flectional. They are used for:
-
[6]
generating wordforms associated with lemma
-
[7]
trans- lated
assigningthetagdescribingthemorphological properties of every wordform It is thus not necessary to include some (actu- ally, many) words in the dictionary; they are de- rived using regular patterns for large sets of words. For instance, there is one record in the source for- mat for the verblétat‘to fly’ (cf. the first row in Table 4). Its derivational pa...
-
[8]
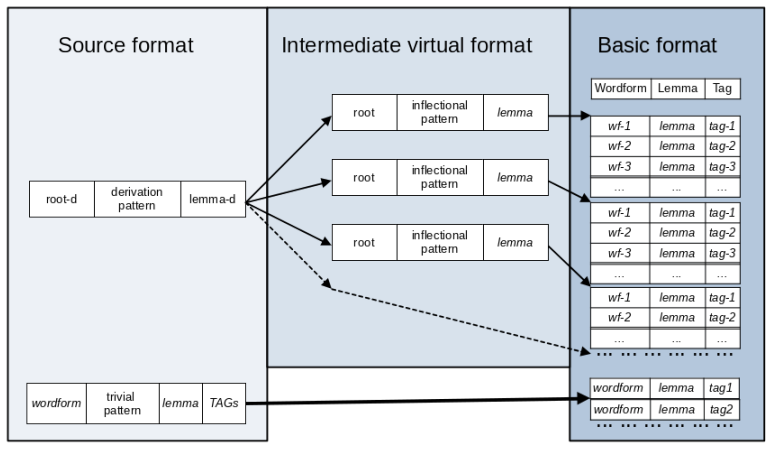
MorfFlex Formats In this section, all three MorfFlex formats are de- scribed: source(Sect.4.1), intermediate(Sect.4.2) and basic (Sect. 4.3). 12An exception is formed by the so-called trivial pat- terns (see Sect. 5.3). 3 Figure 1:MorfFlex scheme. There are three formats: source, intermediate and basic. In thesource format,twotypesofrecordsareused. Theupp...
-
[9]
First, the source format is converted into a virtual intermediate format (Sect
MorfFlex Procedure The procedure for creating a dictionary from the sourceformatisnotstraightforward; itiscarriedout in two steps. First, the source format is converted into a virtual intermediate format (Sect. 5.1), from which the basic format is subsequently generated (Sect. 5.2). Those source format records, that con- tain a trivial pattern (and theref...
-
[10]
SC1 ky,ns3n,r0,kyně,0,0
-
[11]
SC1 kynin,in,r0,kynin,r0,kyně Table 8: Derivational rules for theSC1d-pattern. i-root i-pattern i-lemma_back-link 1 dár sc1 dárce 2 dárc uv dárcův_dárce 3 dárky ns3n dárkyně_dárce 4 dárkynin in dárkynin_dárkyně Table9: Recordsoftheintermediateformatderived from the source format record presented in Table 7 – according to derivational rules presented in Ta...
-
[12]
They usually represent initial steps of language process- ing
Use of MorfFlex Morphological analysis, part-of-speech tagging are important components of NLP applications. They usually represent initial steps of language process- ing. Despite recent advances in part-of-speech and morphological tagging, the old truth that more data always gives better results (Banko and Brill, 2001; Church and Mercer, 1993) still hold...
2001
-
[13]
Conclusion Inconclusion,MorfFlexexemplifieshowasystemat- ically organized morphological dictionary can effec- tively manage the complexity of a highly inflective language such as Czech. By combining manually maintained source files with derivational and inflec- tional patterns, the dictionary achieves a remark- able balance between comprehensiveness and e...
-
[14]
Acknowledgements The research and language resource work re- ported in the paper has been supported by the LINDAT/CLARIN and LINDAT/CLARIAH-CZ projectsfundedbyMinistryofEducation,Youthand SportsoftheCzechRepublic(projectsLM2015071, LM2018101, LM2023062). The original annotation hasbeensupportedbymultipleprojectsinthepast, funded both nationally by the Min...
-
[15]
For languages of an agglutinative type, it would need to be adapted
Limitations The presented pattern-based management of rich morphological systems is limited to inflectional lan- guages (primarily Slavic ones). For languages of an agglutinative type, it would need to be adapted. On the one hand, the pattern-based system makes it possible to efficiently generate a huge number of lemmas and wordforms; on the other hand, e...
-
[16]
Bibliographical References Michele Banko and Eric Brill. 2001. Scaling to Very Very Large Corpora for Natural Language Dis- ambiguation. InProceedings of the 39th Annual MeetingoftheAssociationforComputationalLin- guistics, pages 26–33, Toulouse, France. Asso- ciation for Computational Linguistics. Khuyagbaatar Batsuren, Omer Goldman, Salam Khalifa, Nizar...
2001
-
[17]
The Sloleks Morphological Lexicon and its Future Development. In Vojko Gorjanc, Polona Gantar, Iztok Kosem, and Simon Krek, editors, DictionaryofModernSlovene: ProblemsandSo- lutions, pages 42–63. Založba Univerze v Ljubl- jani, Ljubljana, SI. Jan Hajič. 2004.Disambiguation of Rich In- flection (Computational Morphology of Czech). Karolinum, Prague, Czech...
-
[18]
InProceedings of Workshop on Software, pages 77–85, Ann Arbor, Michigan
Hunmorph: Open Source Word Analy- sis. InProceedings of Workshop on Software, pages 77–85, Ann Arbor, Michigan. Association for Computational Linguistics. Jonáš Vidra, Zdeněk Žabokrtský, Magda Ševčíková, and Lukáš Kyjánek. 2019. DeriNet 2.0: Towards an All-in-One Word-Formation Resource. InProceedings of the Second International Workshop on Resources and ...
2019
-
[19]
2024a.Prague Depen- dency Treebank - Consolidated 2.0 (PDT-C 2.0)
Language Resource References Hajič, Jan and Bejček, Eduard and Bémová, Alevtina and Buráňová, Eva and Fučíková, Eva and Hajičová, Eva and Havelka, Jiří and Hlaváčová, Jaroslava and Homola, Petr and Ircing, Pavel and Kárník, Jiří and Kettnerová, Václava and Klyueva, Natalia and Kolářová, Veronika and Kučová, Lucie and Lopatková, Markéta and Mareček, David ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.