AutoSpecNER: A Fine-Grained Named Entity Recognition Dataset for Vehicle Specification Extraction
Pith reviewed 2026-06-25 23:52 UTC · model grok-4.3
The pith
A new dataset of 659 annotated vehicle ads lets DeBERTa extract 15 fine-grained specs at 90% micro-F1.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
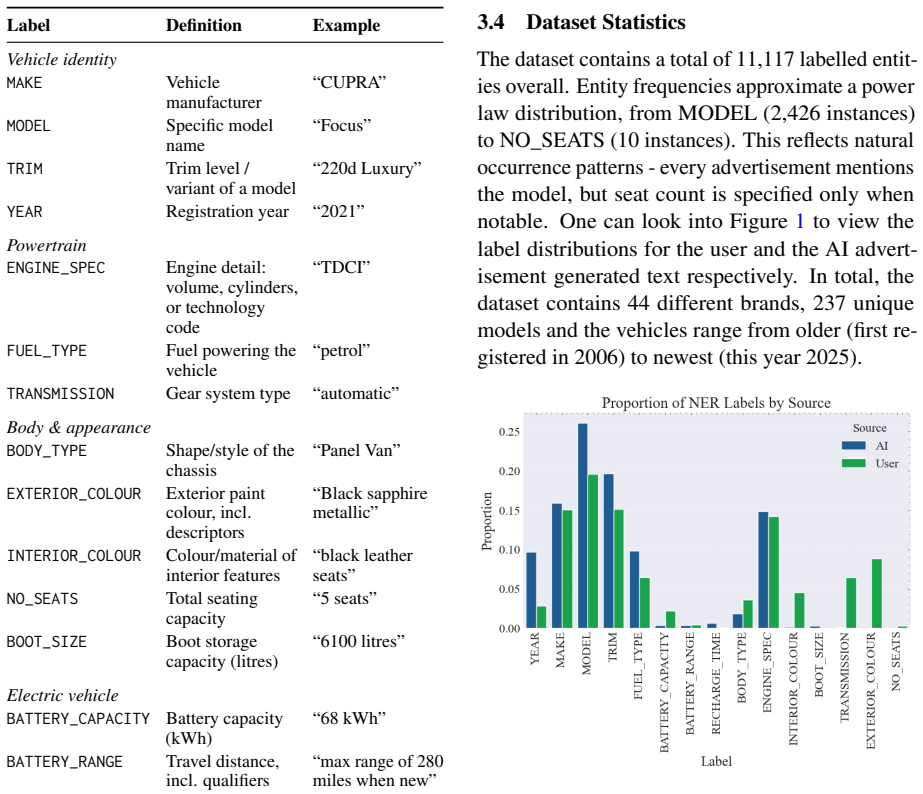
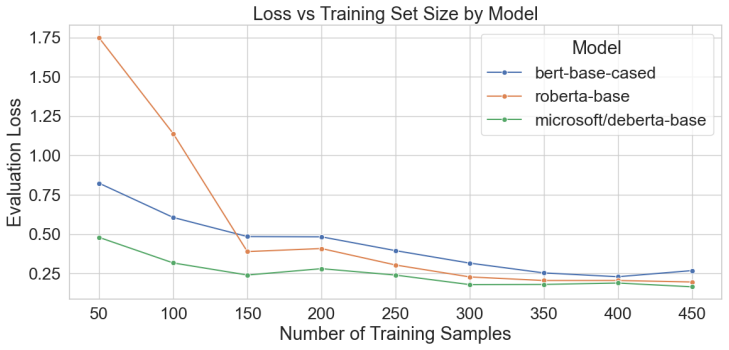
We introduce AutoSpecNER, an expert-annotated dataset for fine-grained entity recognition in vehicle listings. The dataset includes 659 advertisements from a popular car-selling website, with over 10,000 entities annotated across 15 categories, including MODEL, ENGINE_SPEC, and BATTERY_CAPACITY. Annotation quality was validated through inter-annotator agreement, achieving an average score of 91.5%. We benchmark rule-based extraction, fine-tuned transformer encoders, and large language models. DeBERTa achieves the best performance with a 90% micro-F1 score, outperforming the rule-based baseline (43%) and the strongest large language model (77.8%).
What carries the argument
The AutoSpecNER dataset of expert-annotated vehicle advertisements supporting 15 entity categories for named entity recognition training and evaluation.
If this is right
- Fine-tuned transformer encoders outperform both rule-based systems and large language models on this domain-specific extraction task.
- The 15-category annotation scheme captures fine details such as battery capacity that coarser schemes miss.
- High inter-annotator agreement indicates the annotation scheme is reproducible for future dataset extensions.
- The performance gap between 90% and 43% shows that learned models are necessary for handling varied listing phrasing.
Where Pith is reading between the lines
- Similar annotation efforts could be applied to other product categories that list technical specifications in free text, such as electronics or machinery.
- The gap between the fine-tuned model and LLMs suggests that domain-specific labeled data still adds value even when general-purpose models are available.
- Downstream applications such as automated vehicle comparison engines or inventory deduplication become more practical once extraction reaches this accuracy level.
Load-bearing premise
The 659 advertisements sampled from one popular car-selling website are representative enough of real-world vehicle listing language and specification variety to support general claims about extraction performance in the automotive domain.
What would settle it
Running the same DeBERTa model on a held-out set of vehicle advertisements drawn from a different car-selling platform and observing micro-F1 below 75%.
Figures
read the original abstract
Vehicle advertisements contain rich specification information, but automotive NER resources remain limited. We introduce AutoSpecNER, an expert-annotated dataset for fine-grained entity recognition in vehicle listings. The dataset includes 659 advertisements from a popular car-selling website, with over 10,000 entities annotated across 15 categories, including MODEL, ENGINE_SPEC, and BATTERY_CAPACITY. Annotation quality was validated through inter-annotator agreement, achieving an average score of 91.5%. We benchmark rule-based extraction, fine-tuned transformer encoders, and large language models. DeBERTa achieves the best performance with a 90% micro-F1 score, outperforming the rule-based baseline (43%) and the strongest large language model (77.8%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AutoSpecNER, an expert-annotated NER dataset for vehicle specification extraction consisting of 659 advertisements from a single popular car-selling website. It annotates over 10,000 entities across 15 categories (e.g., MODEL, ENGINE_SPEC, BATTERY_CAPACITY), reports 91.5% inter-annotator agreement, and benchmarks extraction methods, with DeBERTa reaching 90% micro-F1 versus 43% for a rule-based baseline and 77.8% for the strongest LLM tested.
Significance. If the central empirical results hold, the work supplies a concrete, fine-grained resource in an area with limited existing datasets, supported by explicit IAA and benchmark numbers. The single-source construction, however, constrains the strength of any domain-wide claims about extraction performance or category coverage.
major comments (2)
- [Abstract] Abstract: The positioning of AutoSpecNER as addressing limited automotive NER resources and supporting general extraction performance claims rests on data exclusively from one website; no cross-site evaluation, out-of-distribution testing, or analysis of terminology/ boundary differences across platforms is provided to substantiate transfer beyond the source distribution.
- [Dataset] Dataset description: The 659 advertisements are stated to come from 'a popular car-selling website' with no details on sampling procedure, platform identity, or checks for selection bias in specification variety or entity distribution, which directly affects the representativeness of the 15 categories and the 90% micro-F1 result.
minor comments (1)
- [Abstract] Abstract provides no information on train/dev/test splits, annotation guidelines, or exact category definitions, which would aid reproducibility even if present in later sections.
Simulated Author's Rebuttal
We thank the referee for highlighting the single-source limitation and the need for greater transparency in dataset construction. We agree these are valid concerns that affect the strength of broader claims and will revise the manuscript to address them where feasible. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract] Abstract: The positioning of AutoSpecNER as addressing limited automotive NER resources and supporting general extraction performance claims rests on data exclusively from one website; no cross-site evaluation, out-of-distribution testing, or analysis of terminology/ boundary differences across platforms is provided to substantiate transfer beyond the source distribution.
Authors: We agree the dataset is drawn from a single website and that this constrains any claims of general extraction performance or transfer. The abstract and introduction position AutoSpecNER primarily as a new annotated resource rather than a comprehensive cross-platform benchmark. We will revise the abstract to explicitly note the single-source origin and remove any implication of broad generalizability. No cross-site data collection or OOD testing was performed, as the work focused on dataset creation and initial benchmarking. revision: partial
-
Referee: [Dataset] Dataset description: The 659 advertisements are stated to come from 'a popular car-selling website' with no details on sampling procedure, platform identity, or checks for selection bias in specification variety or entity distribution, which directly affects the representativeness of the 15 categories and the 90% micro-F1 result.
Authors: We will expand the dataset section to describe the sampling procedure (e.g., selection criteria and time window), disclose the platform where appropriate, and include basic statistics on entity distribution to allow assessment of potential bias. These details were previously omitted for space but can be added without new experiments. revision: yes
- Absence of cross-site evaluation, out-of-distribution testing, or terminology analysis across platforms, as no additional data from other sources was collected.
Circularity Check
No circularity: purely empirical dataset creation and model evaluation
full rationale
The paper creates an annotated NER dataset from 659 vehicle ads and reports direct empirical results: inter-annotator agreement of 91.5%, rule-based baseline at 43% micro-F1, and DeBERTa at 90% micro-F1. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. All reported numbers are computed from the new annotations and standard model training; none reduce to prior fitted quantities by construction. Single-source sampling affects external validity but is unrelated to circularity in any derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inter-annotator agreement of 91.5% validates high-quality expert annotations for the NER task
Reference graph
Works this paper leans on
-
[1]
and De Meulder, Fien
Tjong Kim Sang, Erik F. and De Meulder, Fien. Introduction to the C o NLL -2003 Shared Task: Language-Independent Named Entity Recognition. Proceedings of the Seventh Conference on Natural Language Learning at HLT - NAACL 2003. 2003
2003
-
[2]
Results of the WNUT 2017 Shared Task on Novel and Emerging Entity Recognition
Derczynski, Leon and Nichols, Eric and van Erp, Marieke and Limsopatham, Nut. Results of the WNUT 2017 Shared Task on Novel and Emerging Entity Recognition. Proceedings of the 3rd Workshop on Noisy User-generated Text. 2017. doi:10.18653/v1/W17-4418
-
[3]
Proceedings of NAACL-HLT , pages =
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[4]
2019 , eprint=
RoBERTa: A Robustly Optimized BERT Pretraining Approach , author=. 2019 , eprint=
2019
-
[5]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[6]
arXiv preprint arXiv:2208.14536 , year=
Malmasi, Shervin and Tafreshi, Shabnam and Dušek, Ond. arXiv preprint arXiv:2208.14536 , year=
-
[7]
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , journal=
-
[8]
2023 , eprint=
DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing , author=. 2023 , eprint=
2023
-
[9]
Label supervised
Li, Zongxi and Li, Xianming and Liu, Yuzhang and Xie, Haoran and Li, Jing and Wang, Fu-lee and Li, Qing and Zhong, Xiaoqin , journal=. Label supervised
-
[10]
Journal of the American Medical Informatics Association , year=
Evaluating the performance of large language models for named entity recognition in ophthalmology clinical free-text notes , author=. Journal of the American Medical Informatics Association , year=
-
[11]
Fine-Grained Entity Recognition
Ling, Xiao and Weld, Daniel S. Fine-Grained Entity Recognition. Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence. 2012
2012
-
[12]
Bootstrapped Named Entity Recognition for Product Attribute Extraction
Putthividhya, Duangmanee and Hu, Junling. Bootstrapped Named Entity Recognition for Product Attribute Extraction. Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. 2011
2011
-
[13]
Does Named Entity Recognition Truly Not Scale Up to Real-world Product Attribute Extraction?
Chen, Wei-Te and Shinzato, Keiji and Yoshinaga, Naoki and Xia, Yandi. Does Named Entity Recognition Truly Not Scale Up to Real-world Product Attribute Extraction?. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: Industry Track. 2023
2023
-
[14]
and French, Tim and Stewart, Michael and Liu, Wei and Hodkiewicz, Melinda
Bikaun, Tyler K. and French, Tim and Stewart, Michael and Liu, Wei and Hodkiewicz, Melinda. M aint IE : A Fine-Grained Annotation Schema and Benchmark for Information Extraction from Maintenance Short Texts. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[15]
Named Entity Recognition of Automotive Parts Based on RoBERTa-CRF Model , year=
Hu, Songhua and Ma, Ruhu , booktitle=. Named Entity Recognition of Automotive Parts Based on RoBERTa-CRF Model , year=
-
[16]
Shifting NER into High Gear: The A uto- A dv ER Approach
Ventirozos, Filippos and Nteka, Ioanna and Nandy, Tania and Baca, Jozef and Appleby, Peter and Shardlow, Matthew. Shifting NER into High Gear: The A uto- A dv ER Approach. 2024. arXiv:2412.05655
arXiv 2024
-
[17]
Multimedia Tools and Applications , year =
Runwei Guan and Ka Lok Man and Feifan Chen and Shanliang Yao and Rongsheng Hu and Xiaohui Zhu and Jeremy Smith and Eng Gee Lim and Yutao Yue , title =. Multimedia Tools and Applications , year =. doi:10.1007/s11042-023-16373-y , url =
-
[18]
Park, Cheoneum and Jeong, Seohyeong and Kim, Juae , title =. 2023 , issue_date =. doi:10.1016/j.eswa.2023.120007 , journal =
-
[19]
A Corpus and Method for C hinese Named Entity Recognition in Manufacturing
Li, Ruiting and Wang, Peiyan and Wang, Libang and Yang, Danqingxin and Cai, Dongfeng. A Corpus and Method for C hinese Named Entity Recognition in Manufacturing. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[20]
KCL : Few-shot Named Entity Recognition with Knowledge Graph and Contrastive Learning
Zhang, Shan and Cao, Bin and Fan, Jing. KCL : Few-shot Named Entity Recognition with Knowledge Graph and Contrastive Learning. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[21]
GPT - NER : Named Entity Recognition via Large Language Models
Wang, Shuhe and Sun, Xiaofei and Li, Xiaoya and Ouyang, Rongbin and Wu, Fei and Zhang, Tianwei and Li, Jiwei and Wang, Guoyin. GPT - NER : Named Entity Recognition via Large Language Models. arXiv preprint arXiv:2304.10428. 2023
arXiv 2023
-
[22]
PromptNER : Prompting for Named Entity Recognition
Ashok, Dhananjay and Lipton, Zachary C. PromptNER : Prompting for Named Entity Recognition. arXiv preprint arXiv:2305.15444. 2023
arXiv 2023
-
[23]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[24]
Naguib, Marco and Tannier, Xavier and N \'e v \'e ol, Aur \'e lie. Few-shot clinical entity recognition in E nglish, F rench and S panish: masked language models outperform generative model prompting. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.400
-
[25]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[26]
Hiroki Nakayama , year=
-
[27]
URL https: //aclanthology.org/2025.acl-long.127/
Warner, Benjamin and Chaffin, Antoine and Clavi. Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.127
-
[28]
2020 , eprint=
HuggingFace's Transformers: State-of-the-art Natural Language Processing , author=. 2020 , eprint=
2020
-
[29]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[30]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
Yi: Open Foundation Models by 01.AI , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
Gemini: A Family of Highly Capable Multimodal Models , author=. 2025 , eprint=
2025
-
[33]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[34]
Richie, Russell and Grover, Sachin and Tsui, Fuchiang (Rich). Inter-annotator agreement is not the ceiling of machine learning performance: Evidence from a comprehensive set of simulations. Proceedings of the 21st Workshop on Biomedical Language Processing. 2022. doi:10.18653/v1/2022.bionlp-1.26
-
[35]
Journal of the American Medical Informatics Association , year =
Agreement, the F-measure, and Reliability in Information Retrieval , author =. Journal of the American Medical Informatics Association , year =. doi:10.1197/jamia.M1733 , pmid =
-
[36]
2017 , pid =
Honnibal, Matthew and Montani, Ines , title =. 2017 , pid =
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.