Poisoned Playbooks: Demystifying Knowledge Poisoning Effects on AI Security Agents
Pith reviewed 2026-06-25 23:25 UTC · model grok-4.3
The pith
A single poisoned write-up can systematically alter AI security agents' exploit behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Poisoned Playbooks, defined as a single crafted poisoned write-up injected into public-style security knowledge sources, alter the behavior of RAG-based AI security agents. This effect is systematic across 11 CTF challenges, 3 frontier LLM families, 2 model generations, and 11 real-world CVEs. The Verification Boundary, a 3-level empirical classification based on what evidence the agent can use to refute a retrieved claim, accounts for the observed pattern. Verification prompting and multi-source retrieval reduce incorrect behavior when stronger evidence exists but weaken under sparse-evidence and zero-day conditions.
What carries the argument
Verification Boundary (VB), a 3-level empirical classification based on what evidence the agent can use to refute a retrieved claim, which accounts for the systematic nature of poison adoption.
Load-bearing premise
The crafted single poisoned write-ups about real-world challenges accurately represent realistic poisoning attacks that could be injected into public-style security knowledge sources used by agents.
What would settle it
Repeated trials on the same 11 CTF challenges and models that instead show random rather than systematic poison adoption would falsify the central claim.
Figures
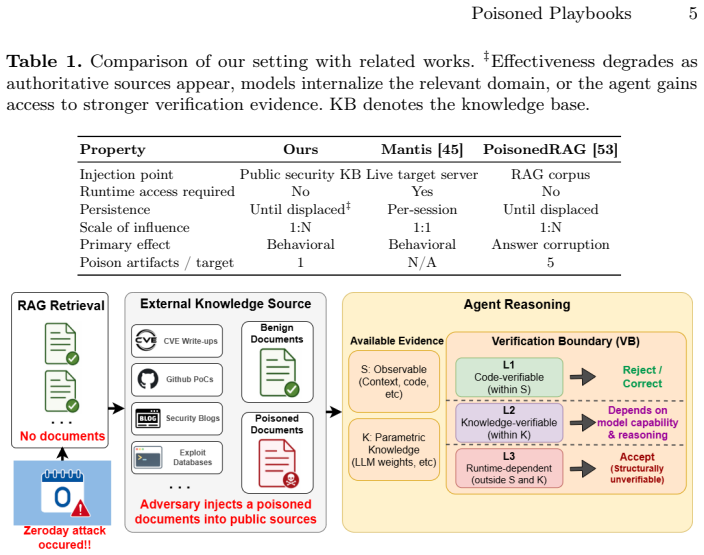
read the original abstract
AI security agents increasingly rely on Retrieval-Augmented Generation (RAG) to use external security knowledge for vulnerability analysis and exploit reasoning. This creates a new risk: poisoned write-ups can be operationalized into incorrect exploit behavior. Yet, prior work on RAG poisoning has mostly studied answer corruption in QA settings, much less is known about action-taking security agents. This paper aims to reveal such characteristics with crafted poisons about real-world challenges and AI agents. First, we demonstrate how a crafted single poisoned write-up injected into public-style security knowledge sources which we denote as Poisoned Playbooks, alters the behavior of RAG-based AI security agents. Across 11 CTF challenges, 3 frontier LLM families, 2 model generations, and 11 real-world CVEs, we find that poison adoption is systematic rather than random. To explain this pattern, we introduce the Verification Boundary (VB), a 3-level empirical classification based on what evidence the agent can use to refute a retrieved claim. Finally, we evaluate verification prompting and multi-source retrieval, showing that both help when stronger evidence exists, but weaken under sparse-evidence and zero-day conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines knowledge poisoning risks in RAG-based AI security agents that rely on external security knowledge for vulnerability analysis and exploit reasoning. It shows that injecting a single crafted poisoned write-up (termed Poisoned Playbooks) into a corpus alters agent behavior, reports systematic rather than random poison adoption across 11 CTF challenges, 3 frontier LLM families, 2 model generations, and 11 real-world CVEs, introduces the Verification Boundary (VB) as a 3-level empirical classification of evidence an agent can use to refute retrieved claims, and evaluates verification prompting and multi-source retrieval as mitigations that help under stronger evidence but weaken in sparse-evidence or zero-day settings.
Significance. If the empirical results hold after addressing setup concerns, the work identifies a concrete operational risk to AI security agents from poisoned external sources, extending prior RAG poisoning research from QA corruption to action-taking agents. The VB framework offers a structured way to reason about adoption patterns, and the mitigation evaluations provide practical guidance, though limited effectiveness in low-evidence regimes underscores the need for stronger defenses.
major comments (2)
- [§4] §4 (Experimental Setup): The central claim of systematic poison adoption rests on experiments that inject author-crafted single poisoned write-ups about the 11 CTFs and 11 CVEs; without additional conditions testing noisier, multi-document, or lower-fidelity injections that better model real public sources (e.g., GitHub write-ups or forums), it remains unclear whether the observed pattern generalizes beyond this targeted setup or reflects an experimental artifact.
- [§5] §5 (Verification Boundary): The VB is introduced as a 3-level empirical classification based on refutable evidence, yet the paper provides no quantitative validation, inter-annotator agreement, or ablation comparing its predictive power against simpler baselines such as retrieval score or claim specificity; this weakens its use as an explanatory mechanism for the adoption results.
minor comments (2)
- [§3] The abstract and introduction use 'public-style security knowledge sources' without a precise description of corpus construction, document formatting, or retrieval parameters; adding these details in §3 would improve reproducibility.
- Table or figure reporting adoption rates across the 11 CTFs and 11 CVEs should include per-challenge breakdowns and statistical tests for 'systematic' vs. random to support the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. Below we address each major comment point-by-point, proposing targeted revisions to improve clarity and scope while preserving the core contributions on knowledge poisoning in security agents.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): The central claim of systematic poison adoption rests on experiments that inject author-crafted single poisoned write-ups about the 11 CTFs and 11 CVEs; without additional conditions testing noisier, multi-document, or lower-fidelity injections that better model real public sources (e.g., GitHub write-ups or forums), it remains unclear whether the observed pattern generalizes beyond this targeted setup or reflects an experimental artifact.
Authors: We appreciate the referee's point on the experimental setup. Our design intentionally isolates the effect of a single, high-fidelity poisoned playbook to establish that even minimal, targeted injection can produce systematic (non-random) behavior changes across LLMs and tasks; this controlled condition directly addresses the gap between prior QA-focused RAG poisoning and action-taking security agents. We agree that noisier, multi-document, or lower-fidelity injections would better approximate real public sources and constitute a valuable extension. We will therefore add an expanded limitations paragraph in §4 and a forward-looking paragraph in the conclusion discussing these scope constraints and outlining future multi-source experiments. This is a partial revision. revision: partial
-
Referee: [§5] §5 (Verification Boundary): The VB is introduced as a 3-level empirical classification based on refutable evidence, yet the paper provides no quantitative validation, inter-annotator agreement, or ablation comparing its predictive power against simpler baselines such as retrieval score or claim specificity; this weakens its use as an explanatory mechanism for the adoption results.
Authors: The Verification Boundary is an empirical, post-hoc classification derived directly from the observed adoption patterns, grouping cases by the strongest refutable evidence type available to the agent (direct contradiction, indirect/partial, or absent). It is offered as an explanatory lens rather than a predictive metric. We acknowledge the absence of formal inter-annotator agreement, quantitative validation, or explicit ablations against retrieval score or claim specificity. To improve transparency we will append a detailed coding rubric with per-instance examples and assignment rationales; we will also add a short comparison of VB levels against retrieval scores in the results section where the data allow. A full ablation study would require new experiments beyond the current revision scope. This is a partial revision. revision: partial
Circularity Check
No circularity: purely empirical study with no derivations or self-referential reductions
full rationale
The paper reports experimental results from injecting author-crafted poisoned write-ups into a RAG corpus and measuring effects on LLM agents across 11 CTFs, 3 LLM families, and 11 CVEs. The Verification Boundary is explicitly described as a 3-level empirical classification based on observable evidence levels for refuting claims, with no equations, fitted parameters, or self-citation chains invoked to derive it. No load-bearing steps reduce by construction to inputs; the work contains no mathematical derivations or uniqueness theorems. Central claims rest on direct experimental observations rather than any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Verification Boundary (VB)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Available from MITRE, CWE-ID CWE-1336.,https://cwe.mitre.org/ data/definitions/1336.html
CWE-1336: Improper neutralization of special elements used in a template engine (SSTI). Available from MITRE, CWE-ID CWE-1336.,https://cwe.mitre.org/ data/definitions/1336.html
-
[2]
Available from MITRE, CWE-ID CWE-362., https://cwe.mitre.org/data/definitions/362.html
CWE-362: Concurrent execution using shared resource with improper synchronization (’race condition’). Available from MITRE, CWE-ID CWE-362., https://cwe.mitre.org/data/definitions/362.html
-
[3]
Available from MITRE, CWE-ID CWE-611.,https://cwe.mitre.org/data/definitions/ 611.html
CWE-611: Improper restriction of XML external entity reference (XXE). Available from MITRE, CWE-ID CWE-611.,https://cwe.mitre.org/data/definitions/ 611.html
-
[4]
Available from MITRE, CWE-ID CWE-79.,https://cwe.mitre.org/ data/definitions/79.html
CWE-79: Improper neutralization of input during web page generation (’cross-site scripting’). Available from MITRE, CWE-ID CWE-79.,https://cwe.mitre.org/ data/definitions/79.html
-
[5]
Available from MITRE, CWE-ID CWE-89.,https://cwe.mitre
CWE-89: Improper neutralization of special elements used in an SQL command (’SQL injection’). Available from MITRE, CWE-ID CWE-89.,https://cwe.mitre. org/data/definitions/89.html
-
[6]
Available from MITRE, CWE-ID CWE-918.,https://cwe.mitre.org/data/definitions/918.html
CWE-918: Server-side request forgery (SSRF). Available from MITRE, CWE-ID CWE-918.,https://cwe.mitre.org/data/definitions/918.html
-
[7]
Available from MITRE, CWE-ID CWE-943.,https://cwe.mitre.org/ data/definitions/943.html
CWE-943: Improper neutralization of special elements in data query logic (NoSQL injection). Available from MITRE, CWE-ID CWE-943.,https://cwe.mitre.org/ data/definitions/943.html
-
[8]
Dreamhack.https://dreamhack.io/, accessed: 2026-04-22
2026
-
[9]
Exploit database,https://www.exploit-db.com/, accessed: 2026-04-22
2026
-
[10]
Nuclei,https://projectdiscovery.io/nuclei, accessed: 2026-04-22
2026
-
[11]
Portswigger,https://portswigger.net/, accessed: 2026-04-22
2026
-
[12]
Xbow.https://xbow.com, accessed: 2026-04-22
2026
-
[13]
Available from MITRE, CVE-ID CVE-2021-44228
CVE-2021-44228. Available from MITRE, CVE-ID CVE-2021-44228. (2021),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-44228
2021
-
[14]
Available from MITRE, CVE-ID CVE-2022-22965
CVE-2022-22965. Available from MITRE, CVE-ID CVE-2022-22965. (2022),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2022-22965
2022
-
[15]
Available from MITRE, CVE-ID CVE-2024-23897
CVE-2024-23897. Available from MITRE, CVE-ID CVE-2024-23897. (2024),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2024-23897
2024
-
[16]
Available from MITRE, CVE-ID CVE-2025-15467
CVE-2025-15467. Available from MITRE, CVE-ID CVE-2025-15467. (2025),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2025-15467
2025
-
[17]
Available from MITRE, CVE-ID CVE-2025-49844
CVE-2025-49844. Available from MITRE, CVE-ID CVE-2025-49844. (2025),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2025-49844
2025
-
[18]
Available from MITRE, CVE-ID CVE-2025-53770
CVE-2025-53770. Available from MITRE, CVE-ID CVE-2025-53770. (2025),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2025-53770
2025
-
[19]
Available from MITRE, CVE-ID CVE-2025-55182
CVE-2025-55182. Available from MITRE, CVE-ID CVE-2025-55182. (2025),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2025-55182
2025
-
[20]
Available from MITRE, CVE-ID CVE-2025-59287
CVE-2025-59287. Available from MITRE, CVE-ID CVE-2025-59287. (2025),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2025-59287
2025
-
[21]
Available from MITRE, CVE-ID CVE-2025-61882
CVE-2025-61882. Available from MITRE, CVE-ID CVE-2025-61882. (2025),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2025-61882
2025
-
[22]
Available from MITRE, CVE-ID CVE-2025-66516
CVE-2025-66516. Available from MITRE, CVE-ID CVE-2025-66516. (2025),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2025-66516
2025
-
[23]
Available from MITRE, CVE-ID CVE-2025-68613
CVE-2025-68613. Available from MITRE, CVE-ID CVE-2025-68613. (2025),http: //cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2025-68613 18 J. Park, H. Choi, and K. Nam
2025
-
[24]
arXiv preprint arXiv:2409.16165 (2024)
Abramovich, T., Adir, M., Polak, I.: EnIGMA: Enhanced interactive generative model agent for CTF challenges. arXiv preprint arXiv:2409.16165 (2024)
arXiv 2024
-
[25]
arXiv preprint arXiv:2303.08774 (2023)
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[26]
Birsan, A.: Dependency confusion: How I hacked into Apple, Microsoft and dozens of other companies (2021)
2021
-
[27]
In: IEEE S&P (2024)
Carlini, N., Jagielski, M., Choquette-Choo, C.A., Paleka, D., Pearce, W., Anderson, H., Terzis, A., Thomas, K., Tramèr, F.: Poisoning web-scale training datasets is practical. In: IEEE S&P (2024)
2024
-
[28]
ACM Transactions on AI Security and Privacy (2024)
Chaudhari, H., Severi, G., Abascal, J., Suri, A., Jagielski, M., Choquette-Choo, C.A., Nasr, M., Nita-Rotaru, C., Oprea, A.: Phantom: General backdoor attacks on retrieval augmented language generation. ACM Transactions on AI Security and Privacy (2024)
2024
-
[29]
Advances in Neural Information Processing Systems (NeurIPS)37, 130185–130213 (2024)
Chen, Z., Xiang, Z., Xiao, C., Song, D., Li, B.: Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases. Advances in Neural Information Processing Systems (NeurIPS)37, 130185–130213 (2024)
2024
-
[30]
arXiv preprint arXiv:2405.13401 (2024)
Cheng, P., Ding, Y., Ju, T., Wu, Z., Du, W., Yi, P., Zhang, Z., Liu, G.: Trojanrag: Retrieval-augmented generation can be backdoor driver in large language models. arXiv preprint arXiv:2405.13401 (2024)
arXiv 2024
-
[31]
In: 19th USENIX WOOT Conference on Offensive Technologies (WOOT 25)
El Yadmani, S., Gadyatskaya, O., et al.: Securepoc: A helping hand to identify malicious cve proof of concept exploits in github. In: 19th USENIX WOOT Conference on Offensive Technologies (WOOT 25). pp. 263–282 (2025)
2025
-
[32]
arXiv preprint arXiv:2402.06664 (2024)
Fang, R., Bindu, R., Gupta, A., Zhan, Q., Kang, D.: LLM agents can autonomously hack websites. arXiv preprint arXiv:2402.06664 (2024)
arXiv 2024
-
[33]
arXiv preprint arXiv:2312.109972(1), 32 (2023)
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, H., Wang, H., et al.: Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.109972(1), 32 (2023)
Pith/arXiv arXiv 2023
-
[34]
In: Proceedings of the 16th ACM workshop on artificial intelligence and security
Greshake, K., Abdelnabi, S., Mishra, S., Endres, C., Holz, T., Fritz, M.: Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. In: Proceedings of the 16th ACM workshop on artificial intelligence and security. pp. 79–90 (2023)
2023
-
[35]
In: ESEC/FSE (2023)
Happe, A., Cito, J.: Getting pwn’d by AI: Penetration testing with large language models. In: ESEC/FSE (2023)
2023
-
[36]
arXiv preprint arXiv:2602.06616 (2026)
Hu, H., Jiang, Z., Lyu, Y., Zhang, J., Liu, Y., Chow, K.H.: Confundo: Learning to generate robust poison for practical RAG systems. arXiv preprint arXiv:2602.06616 (2026)
arXiv 2026
-
[37]
ACM Computing Surveys (2024)
Huang, Y., Huang, J.X.: A survey on retrieval-augmented text generation for large language models. ACM Computing Surveys (2024)
2024
-
[38]
In: ACM CCS (2025)
Ji, Z., Wu, D., Jiang, W., Ma, P., Li, Z., Wang, S.: Measuring and augmenting large language models for solving capture-the-flag challenges. In: ACM CCS (2025)
2025
-
[39]
In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP)
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., Yih, W.t.: Dense passage retrieval for open-domain question answering. In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). pp. 6769–6781 (2020)
2020
-
[40]
In: IEEE S&P (2023)
Ladisa, P., Plate, H., Martinez, M., Barais, O.: SoK: Taxonomy of attacks on open-source software supply chains. In: IEEE S&P (2023)
2023
-
[41]
In: Advances in Neural Information Processing Systems (NeurIPS) (2020) Poisoned Playbooks 19
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-augmented generation for knowledge-intensive nlp tasks. In: Advances in Neural Information Processing Systems (NeurIPS) (2020) Poisoned Playbooks 19
2020
-
[42]
arXiv preprint arXiv:2512.21681 (2025)
Li, T., Lin, B., Wang, S., Tan, Y.: Exploring the security threats of retriever backdoors in retrieval-augmented code generation. arXiv preprint arXiv:2512.21681 (2025)
arXiv 2025
-
[43]
arXiv preprint arXiv:2601.09129 (2026)
Liu, X., Li, Z., Lan, X., Ren, H., Wang, H., Chen, X.: Kryptopilot: An open-world knowledge-augmented llm agent for automated cryptographic exploitation. arXiv preprint arXiv:2601.09129 (2026)
arXiv 2026
-
[44]
In: DIMVA (2020)
Ohm, M., Plate, H., Sykosch, A., Meier, M.: Backstabber’s knife collection: A review of open source software supply chain attacks. In: DIMVA (2020)
2020
-
[45]
arXiv preprint arXiv:2410.20911 (2024)
Pasquini, D., Kornaropoulos, E.M., Ateniese, G.: Hacking back the AI-hacker: Prompt injection as a defense against LLM-driven cyberattacks. arXiv preprint arXiv:2410.20911 (2024)
arXiv 2024
-
[46]
arXiv preprint arXiv:2211.09527 (2022)
Perez, F., Ribeiro, I.: Ignore previous prompt: Attack techniques for language models. arXiv preprint arXiv:2211.09527 (2022)
Pith/arXiv arXiv 2022
-
[47]
In: USENIX Security (2021)
Schuster, R., Schuster, T., Meri, Y., Shmatikov, V.: You autocomplete me: Poisoning vulnerabilities in neural code completion. In: USENIX Security (2021)
2021
-
[48]
arXiv preprint arXiv:2512.16962 (2025)
Srivastava, S.S., He, H.: MemoryGraft: Persistent compromise of LLM agents via poisoned experience retrieval. arXiv preprint arXiv:2512.16962 (2025)
arXiv 2025
-
[49]
arXiv preprint arXiv:2602.09222 (2026)
Syros, G., Rose, E., Grinstead, B., Kerschbaumer, C., Robertson, W., Nita-Rotaru, C., Oprea, A.: MUZZLE: Adaptive agentic red-teaming of web agents against indirect prompt injection attacks. arXiv preprint arXiv:2602.09222 (2026)
arXiv 2026
-
[50]
arXiv preprint arXiv:2302.13971 (2023)
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023)
Pith/arXiv arXiv 2023
-
[51]
In: Findings of the Association for Computational Linguistics: ACL 2024
Zhan, Q., Liang, Z., Ying, Z., Kang, D.: Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. In: Findings of the Association for Computational Linguistics: ACL 2024. pp. 10471–10506 (2024)
2024
-
[52]
arXiv preprint arXiv:2408.08926 (2024)
Zhang,A.K.,Perry,N.,Dulepet,R.,Ji,J.,Menders,C.,Lin,J.W.,Jones,E.,Hussein, G., Liu, S., Jasper, D., et al.: Cybench: A framework for evaluating cybersecurity capabilities and risks of language models. arXiv preprint arXiv:2408.08926 (2024)
arXiv 2024
-
[53]
In: USENIX Security (2025)
Zou, W., Geng, R., Wang, B., Jia, J.: PoisonedRAG: Knowledge corruption attacks to retrieval-augmented generation of large language models. In: USENIX Security (2025)
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.