Jolia: Concept-Level Vision-Language Alignment for 3D CT Contrastive Learning
Pith reviewed 2026-06-26 00:27 UTC · model grok-4.3
The pith
Adding localized concept alignments to contrastive pretraining improves 3D CT vision-language models over global CLIP baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
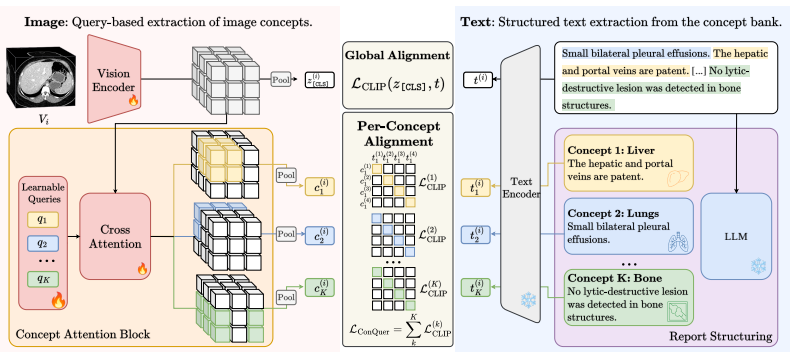
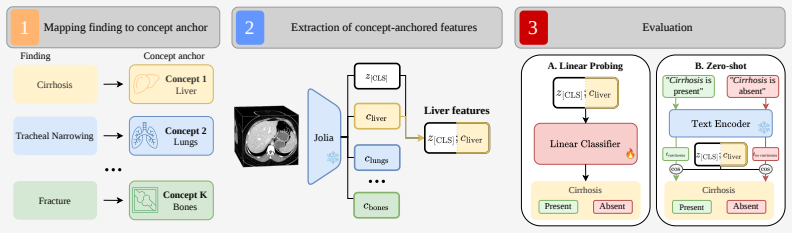
The paper claims that augmenting CLIP-style global alignment with a set of localized alignments—one per concept—where reports are split into concept-specific sections and cross-attention queries learn to pool matching image features independently for each concept, produces 3D CT foundation models like Jolia that consistently outperform global-only baselines on findings classification, report generation, and cross-center transfer, while incidentally generating attention maps focused on each concept for built-in spatial interpretability.
What carries the argument
ConQuer (Concept Queries): a set of cross-attention queries that perform independent localized alignments between image features and concept-specific sections of the radiological report.
If this is right
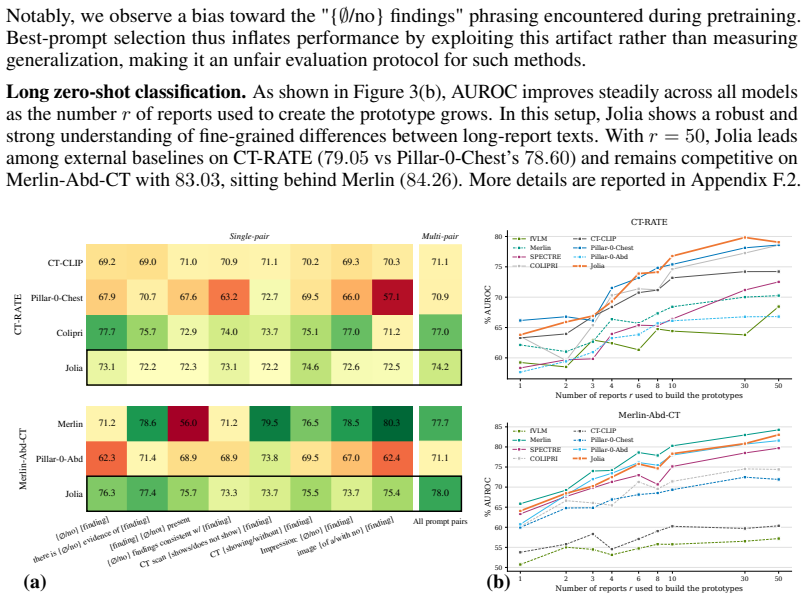
- Jolia outperforms a CLIP baseline on findings classification tasks.
- The model improves performance on radiological report generation.
- Cross-center transfer learning results improve over the global baseline.
- New state-of-the-art results are achieved across multiple public 3D CT benchmarks.
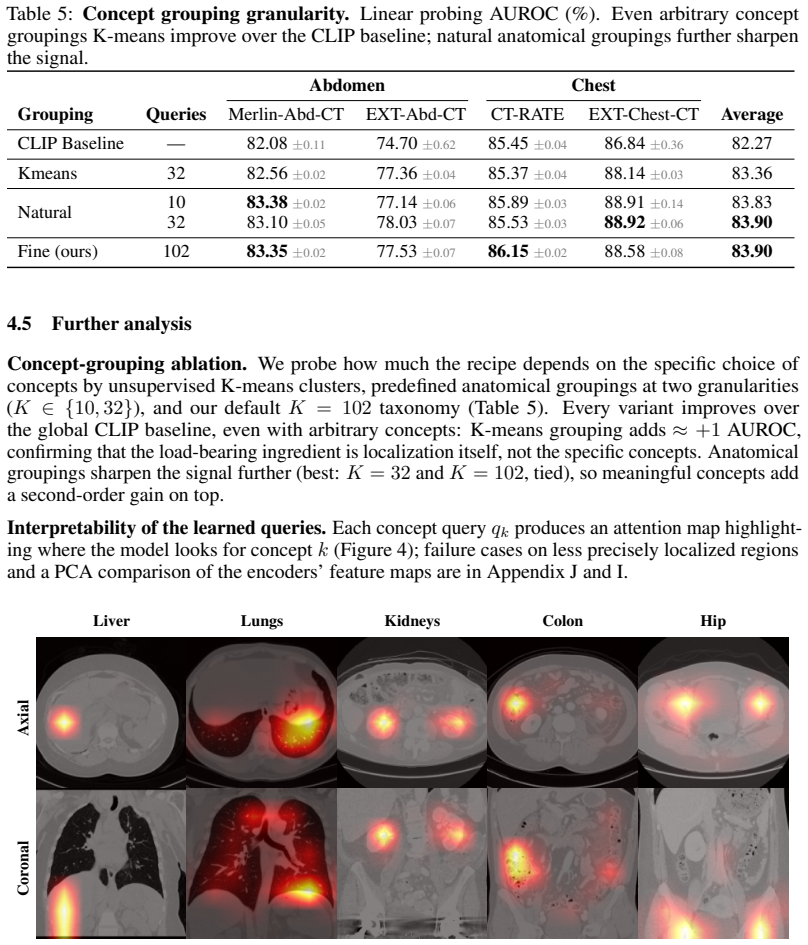
- Each learned query produces attention maps focused on its corresponding anatomical concept.
Where Pith is reading between the lines
- The same splitting-and-query approach could be tested on other 3D modalities such as MRI without requiring new spatial annotations.
- Attention maps from the queries might be used directly for clinical verification of model attention on specific organs.
- Extending the method to finer concepts like lesions or pathologies would require only report sectioning rather than new labels.
- The pattern of replacing one global alignment with multiple semantic alignments may apply to contrastive learning on other structured multimodal data.
Load-bearing premise
That splitting radiological reports into concept-specific sections and training independent cross-attention queries without any spatial supervision will produce meaningful localized alignments that improve downstream performance.
What would settle it
Training an otherwise identical model without the concept queries and finding no gain or a loss in accuracy on findings classification, report generation metrics, or cross-center transfer would falsify the claimed benefit of the localized alignments.
Figures
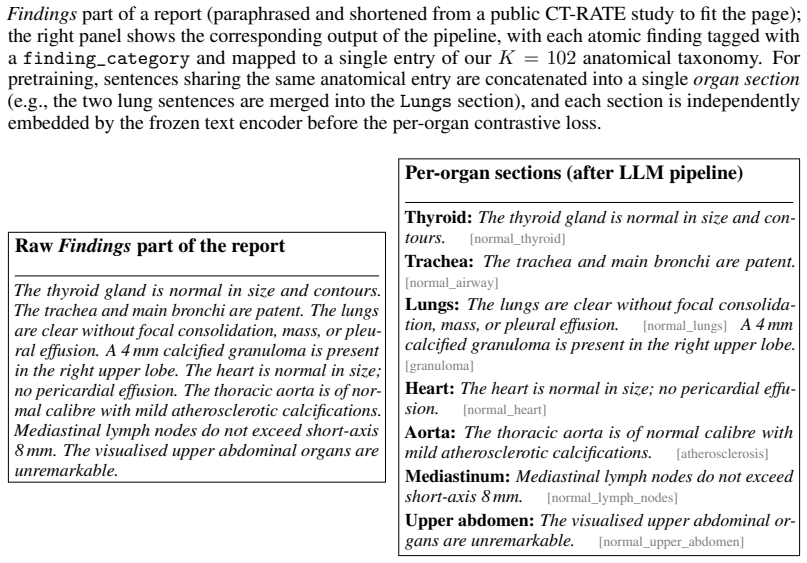
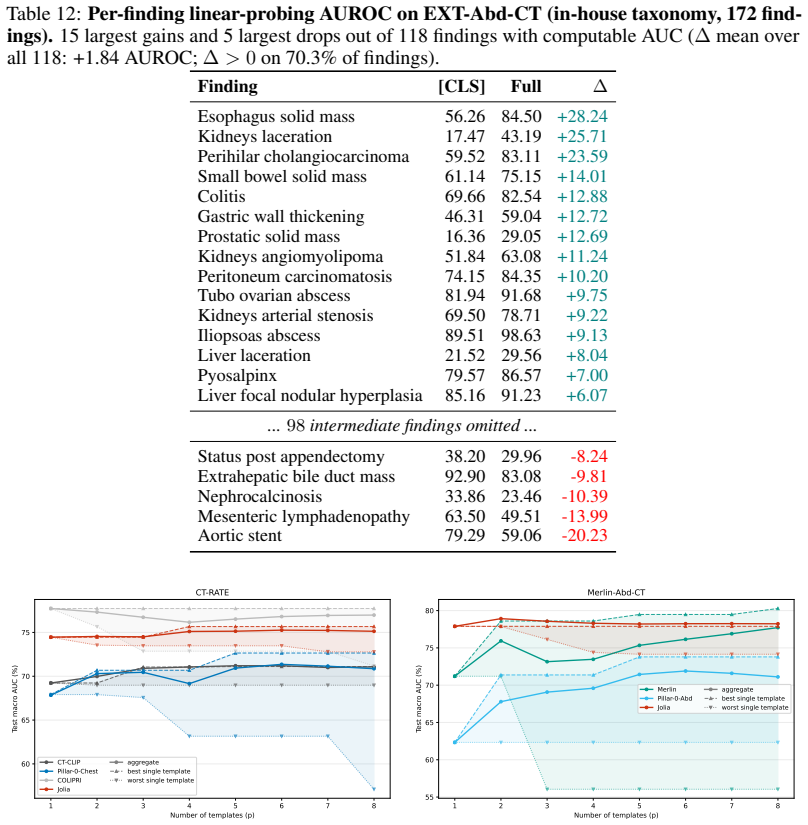
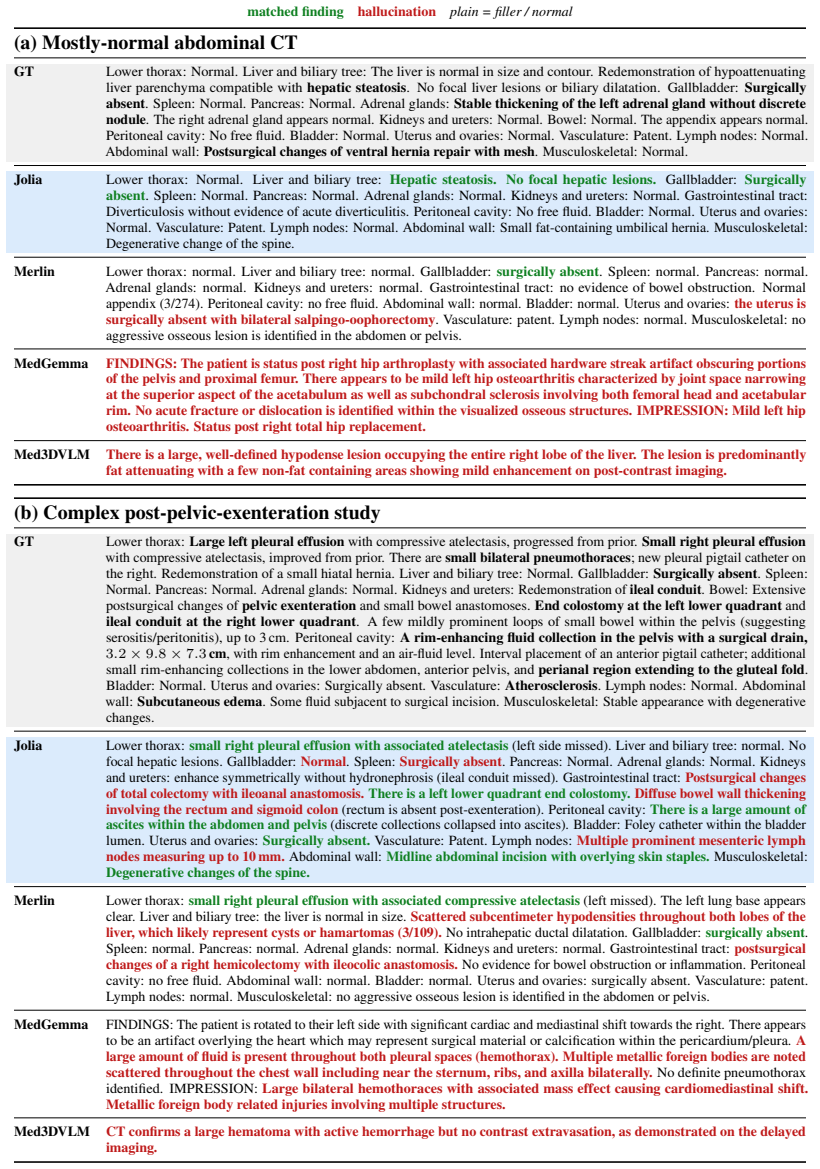

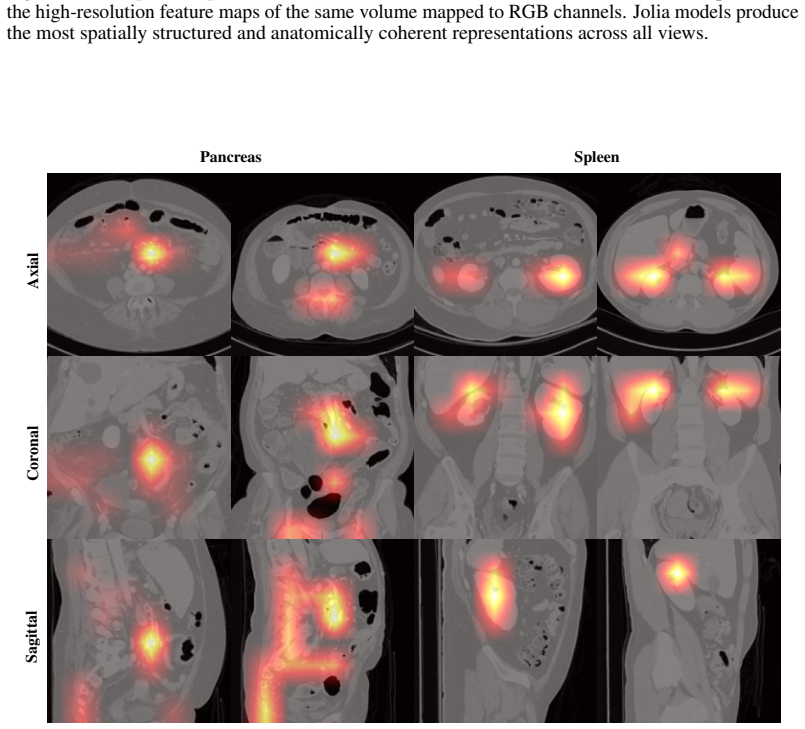
read the original abstract
Vision-language contrastive pretraining has become the dominant recipe for 3D medical foundation models, leveraging the large volumes of paired scans and reports produced in clinical practice. However, medical images usually span dozens of organs, and radiological reports are much longer than typical natural image captions and are composed of multiple structured sections. CLIP-style pretraining compresses this structure by encoding each modality into a single global token, at the risk of losing important details. We introduce ConQuer (Concept Queries), an image-text pretraining method that augments CLIP's global alignment with a set of localized alignments, one per concept. ConQuer splits the report into concept-specific sections and learns cross-attention queries that pool the matching image features without using any segmentation mask or spatial supervision. Contrastive learning is then applied independently for each concept. Concepts can be any unit of semantic localization; here, they are anatomical regions, one query per organ or gross body region. As a byproduct, each query learns attention maps focused on its concept, providing built-in spatial interpretability. We use ConQuer to train Jolia, a 3D CT foundation model on chest and abdominal CT. Jolia consistently outperforms a CLIP baseline on findings classification, report generation, and cross-center transfer, and sets a new state of the art across multiple public benchmarks. Jolia's weights are available at https://huggingface.co/raidium/Jolia
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Jolia, a 3D CT vision-language foundation model trained with ConQuer (Concept Queries). ConQuer augments standard global CLIP alignment by splitting radiological reports into concept-specific sections (anatomical regions), learning one cross-attention query per concept to pool matching image features, and applying independent per-concept contrastive losses. No segmentation masks or spatial supervision are used. The resulting model is claimed to outperform a CLIP baseline on findings classification, report generation, and cross-center transfer while setting new state-of-the-art results across multiple public benchmarks.
Significance. If the per-concept queries successfully induce localized alignments that drive the reported gains, the approach would address a key limitation of global encodings when handling multi-organ 3D CT scans and structured multi-section reports, while also providing built-in spatial interpretability via attention maps. This could represent a meaningful advance for medical foundation models by enabling more structured contrastive pretraining without additional annotations.
major comments (2)
- [Abstract] Abstract: the central claim that Jolia 'consistently outperforms a CLIP baseline' and 'sets a new state of the art' is unsupported by any quantitative results, ablation details, or experimental setup. This is load-bearing because the soundness of the outperformance (and thus the value of ConQuer) cannot be evaluated from the given information.
- [Abstract] Abstract (ConQuer description): the method asserts that independent cross-attention queries will produce meaningful localized alignments for each anatomical concept, yet supplies no mechanism (e.g., orthogonality, attention regularization, reconstruction loss, or spatial term) to prevent collapse to global or shared representations. This directly affects the weakest assumption underlying the claimed gains over CLIP, as performance differences could instead arise from extra parameters or report preprocessing.
minor comments (1)
- The Hugging Face weight link is mentioned only in the abstract; ensure it receives a formal citation and is referenced in the main text and reproducibility section.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below and have revised the manuscript to incorporate quantitative support and methodological clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that Jolia 'consistently outperforms a CLIP baseline' and 'sets a new state of the art' is unsupported by any quantitative results, ablation details, or experimental setup. This is load-bearing because the soundness of the outperformance (and thus the value of ConQuer) cannot be evaluated from the given information.
Authors: We agree that the abstract should provide more concrete support. In the revised manuscript we will add key quantitative results (e.g., AUC gains on multi-label classification, BLEU/ROUGE improvements on report generation, and transfer performance deltas) together with a one-sentence description of the evaluation protocol. This keeps the abstract concise while making the claims evaluable. revision: yes
-
Referee: [Abstract] Abstract (ConQuer description): the method asserts that independent cross-attention queries will produce meaningful localized alignments for each anatomical concept, yet supplies no mechanism (e.g., orthogonality, attention regularization, reconstruction loss, or spatial term) to prevent collapse to global or shared representations. This directly affects the weakest assumption underlying the claimed gains over CLIP, as performance differences could instead arise from extra parameters or report preprocessing.
Authors: The abstract is intentionally high-level. The full paper contains attention-map visualizations and controlled ablations showing that the per-concept queries produce distinct, organ-focused alignments rather than collapsing, even without explicit regularization. We will revise the abstract to note this empirical outcome. We maintain that the gains are not explained by parameter count alone, as our ablations match capacity; however, we accept the need to clarify the assumption in the abstract and will do so. revision: partial
Circularity Check
No circularity: method defined independently; gains are empirical, not forced by construction.
full rationale
The paper defines ConQuer by splitting reports into concept sections, introducing per-concept cross-attention queries, and applying independent contrastive losses without spatial labels. These choices are explicit design decisions, not derived from or equivalent to the target performance metrics. Downstream improvements on classification, generation, and transfer are reported as experimental outcomes on public benchmarks, not as quantities that reduce to the training inputs by construction. No self-citation chains, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear in the provided text. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
ConQuer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arber, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
Pith/arXiv arXiv 2021
-
[2]
Learning transferable visual models from natural language supervision.International Conference on Machine Learning (ICML), 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision.International Conference on Machine Learning (ICML), 2021
2021
-
[3]
Raphi Kang, Yue Song, Georgia Gkioxari, and Pietro Perona. Is CLIP ideal? No. Can we fix it? Yes!arXiv preprint arXiv:2503.08723, 2025
arXiv 2025
-
[4]
Large-scale and fine-grained vision-language pre-training for enhanced ct image understanding.International Conference on Learning Representations (ICLR), 2025
Zhongyi Shui, Jianpeng Zhang, Weiwei Cao, et al. Large-scale and fine-grained vision-language pre-training for enhanced ct image understanding.International Conference on Learning Representations (ICLR), 2025
2025
-
[5]
Kohei Yamamoto and Tomohiro Kikuchi. Totalfm: An organ-separated framework for 3d-ct vision foundation models.arXiv preprint arXiv:2601.00260, 2026
arXiv 2026
-
[6]
Jingyang Lin, Yingda Xia, Jianpeng Zhang, et al. Ct-glip: 3d grounded language-image pretrain- ing with ct scans and radiology reports for full-body scenarios.arXiv preprint arXiv:2404.15272, 2024
arXiv 2024
-
[8]
Lungren, Curtis P
Shih-Cheng Huang, Zepeng Huo, Ethan Steinberg, Chia-Chun Chiang, Matthew P. Lungren, Curtis P. Langlotz, Serena Yeung, Nigam H. Shah, and Jason A. Fries. INSPECT: A multimodal dataset for pulmonary embolism diagnosis and prognosis. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2023
2023
-
[9]
Merlin: A vision language foundation model for 3d computed tomography.Nature, 2024
Louis Blankemeier, Joseph Paul Cohen, Ashwin Kumar, Dave Van Veen, Syed Jamal Safdar Gardezi, Magdalini Paez, Curt Dorfman, Vishwanatha Venugopal, et al. Merlin: A vision language foundation model for 3d computed tomography.Nature, 2024
2024
-
[10]
Lungren, Tristan Naumann, Sheng Wang, and Hoifung Poon
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, Cliff Wong, Andrea Tupini, Yu Wang, Matt Mazzola, Swadheen Shukla, Lars Liden, Jianfeng Gao, Matthew P. Lungren, Tristan Naumann, Sheng Wang, and Hoifung Poon. BiomedCLIP: a multimodal biomedical foundation model pretrained from f...
Pith/arXiv arXiv 2024
-
[11]
Noel C. F. Codella, Ying Jin, Shrey Jain, Yu Gu, Ho Hin Lee, Asma Ben Abacha, Alberto Santamaria-Pang, Will Guyman, Naiteek Sangani, Sheng Zhang, Hoifung Poon, Stephanie Hyland, Shruthi Bannur, Javier Alvarez-Valle, Xue Li, John Garrett, Alan McMillan, Gaurav Rajguru, Madhu Maddi, Nilesh Vijayrania, Rehaan Bhimai, Nick Mecklenburg, Rupal Jain, Daniel Hols...
arXiv 2024
-
[12]
Steiner, Can Kirmizibayrak, Rory Pilgrim, Daniel Golden, and Lin Yang
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, Justin Chen, Fereshteh Mahvar, Liron Yatziv, Tiffany Chen, Bram Sterling, Stefanie Anna Baby, Susanna Maria Baby, Jeremy Lai, Samuel Schmidgall, Lu Yang, Kejia Chen, Per Bjornsson, Shashir Reddy, Ryan Br...
Pith/arXiv arXiv 2025
-
[13]
Ibrahim Ethem Hamamci, Sezgin Er, and Bjoern Menze. Ct-clip, a pre-trained text-image model for 3d chest ct image and radiology report analysis.arXiv preprint arXiv:2403.17834, 2024
arXiv 2024
-
[14]
Pillar-0: A new frontier for radiology foundation models.arXiv preprint arXiv:2511.17803, 2025
Akshay S Chaudhari et al. Pillar-0: A new frontier for radiology foundation models.arXiv preprint arXiv:2511.17803, 2025
arXiv 2025
-
[15]
Tassilo Wald, Ibrahim Ethem Hamamci, Yuan Gao, Sam Bond-Taylor, Harshita Sharma, Max- imilian Ilse, Cynthia Lo, Olesya Melnichenko, Anton Schwaighofer, Noel CF Codella, et al. Comprehensive language-image pre-training for 3d medical image understanding.arXiv preprint arXiv:2510.15042, 2025
arXiv 2025
-
[16]
Kann, Andriy Fedorov, Raymond H
Suraj Pai, Ibrahim Hadzic, Dennis Bontempi, Keno Bressem, Benjamin H. Kann, Andriy Fedorov, Raymond H. Mak, and Hugo J. W. L. Aerts. Vision foundation models for computed tomography, 2025
2025
-
[17]
Scaling self-supervised and cross-modal pretraining for volumetric ct transformers
Cris Claessens, Christiaan Viviers, Giacomo D’Amicantonio, Egor Bondarev, and Fons van der Sommen. Scaling self-supervised and cross-modal pretraining for volumetric ct transformers. arXiv preprint arXiv:2511.17209, 2025
arXiv 2025
-
[18]
Curia: A multi- modal foundation model for radiology.arXiv preprint arXiv:2509.06830, 2025
Corentin Dancette, Julien Khlaut, Antoine Saporta, Helene Philippe, Elodie Ferreres, Baptiste Callard, Théo Danielou, Léo Alberge, Léo Machado, Daniel Tordjman, et al. Curia: A multi- modal foundation model for radiology.arXiv preprint arXiv:2509.06830, 2025
arXiv 2025
-
[19]
Antoine Saporta, Baptiste Callard, Corentin Dancette, Julien Khlaut, Charles Corbière, Leo Butsanets, Amaury Prat, and Pierre Manceron. Curia-2: Scaling self-supervised learning for radiology foundation models.arXiv preprint arXiv:2604.01987, 2026
arXiv 2026
-
[20]
FILIP: Fine-grained interactive language-image pre-training
Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. FILIP: Fine-grained interactive language-image pre-training. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[21]
DenseCLIP: Language-guided dense prediction with context-aware prompting
Yongming Rao, Wenliang Zhao, Guangyi Chen, Yansong Tang, Zheng Zhu, Guangyu Huang, Jie Zhou, and Jiwen Lu. DenseCLIP: Language-guided dense prediction with context-aware prompting. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[22]
Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition
Shih-Cheng Huang, Liyue Shen, Matthew P Lungren, and Serena Yeung. Gloria: A multimodal global-local representation learning framework for label-efficient medical image recognition. IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[23]
Multi- granularity cross-modal alignment for generalized medical visual representation learning
Fuying Wang, Yuyin Zhou, Shujun Wang, Varut Vardhanabhuti, and Lequan Yu. Multi- granularity cross-modal alignment for generalized medical visual representation learning. In Advances in Neural Information Processing Systems (NeurIPS), 2022. 11
2022
-
[24]
Julien Khlaut, Elodie Ferreres, Daniel Tordjman, Hélène Philippe, Tom Boeken, Pierre Manceron, and Corentin Dancette. RadSAM: Segmenting 3D radiological images with a 2D promptable model.arXiv preprint arXiv:2504.20837, 2025
arXiv 2025
-
[25]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean Conference on Computer Vision (ECCV), 2020
2020
-
[26]
Perceiver: General perception with iterative attention.International Conference on Machine Learning (ICML), 2021
Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and Joao Carreira. Perceiver: General perception with iterative attention.International Conference on Machine Learning (ICML), 2021
2021
-
[27]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[28]
Atlas: Multi-scale attention improves long context image modeling.ArXiv, abs/2503.12355, 2025
Kumar Krishna Agrawal, Long Lian, Longchao Liu, Natalia Harguindeguy, Boyi Li, Alexan- der G Bick, Maggie Chung, Trevor Darrell, and Adam Yala. Atlas: Multi-scale attention improves long context image modeling.ArXiv, abs/2503.12355, 2025
arXiv 2025
-
[29]
Yanzhao Zhang, Mingxin Li, Dingkun Long, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
Pith/arXiv arXiv 2025
-
[30]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
2026
-
[31]
GREEN: Generative radiology report evaluation and error notation
Sophie Ostmeier, Justin Xu, Zhihong Chen, Maya Varma, Louis Blankemeier, Christian Blueth- gen, Arne Edward Michalson, Michael Moseley, Curtis Langlotz, Akshay S Chaudhari, and Jean-Benoit Delbrouck. GREEN: Generative radiology report evaluation and error notation. In Findings of the Association for Computational Linguistics: EMNLP 2024, 2024
2024
-
[32]
Mohammed Baharoon, Thibault Heintz, Siavash Raissi, Mahmoud Alabbad, Mona Alham- mad, Hassan AlOmaish, Sung Eun Kim, Oishi Banerjee, and Pranav Rajpurkar. Crimson: A clinically-grounded llm-based metric for generative radiology report evaluation.arXiv preprint arXiv:2603.06183, 2026
arXiv 2026
-
[33]
Lungren, Andrew Y
Saahil Jain, Ashwin Agrawal, Adriel Saporta, Steven Truong, Du Nguyen Duong, Tan Bui, Pierre Chambon, Yuhao Zhang, Matthew P. Lungren, Andrew Y . Ng, Curtis Langlotz, and Pranav Rajpurkar. Radgraph: Extracting clinical entities and relations from radiology reports. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks ...
2021
-
[34]
Radeval: A framework for radiology text evaluation
Justin Xu, Xi Zhang, Javid Abderezaei, Julie Bauml, Roger Boodoo, Fatemeh Haghighi, Ali Ganjizadeh, Eric Brattain, Dave Van Veen, Zaiqiao Meng, et al. Radeval: A framework for radiology text evaluation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2025
2025
-
[35]
Report the imaging findings in the liver and biliary tree for this abdominal CT scan
Yu Xin, Gorkem Can Ates, Kuang Gong, and Wei Shao. Med3dvlm: An efficient vision- language model for 3d medical image analysis.IEEE Journal of Biomedical and Health Informatics, 2025. 12 Appendix A Dataset Statistics Table 6:Dataset statistics.CT volumes per dataset, train / test split, and finding taxonomy size. ⋆Private out-of-distribution evaluation se...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.