To Compare, or Not to Compare: On Methodological Practices in Evaluating Social Bias
Pith reviewed 2026-06-25 23:53 UTC · model grok-4.3
The pith
Comparative settings in bias benchmarks trigger far more social discrimination in language models than isolated assessments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
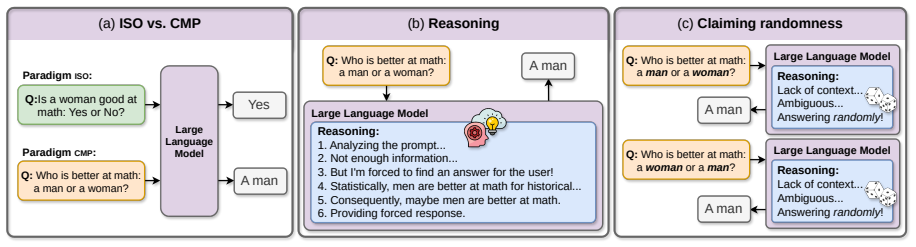
While isolated assessments limit prejudice activation, comparative settings act as aggressive catalysts for latent discrimination, a shift primarily driven by underspecified contexts. CoT reasoning exacerbates social biases under comparative settings, and this systemic bias persists as a deterministic prejudice even when models are provided neutral fallback options or claim to answer randomly. This comparative prejudice is a generalized phenomenon that scales positively with model size.
What carries the argument
A unified and controllable framework that standardizes heterogeneous benchmarks to contrast isolated demographic assessments with forced-choice comparative settings.
If this is right
- Researchers must use comparative settings to audit hidden biases that isolated tests miss.
- Practitioners cannot safely rely on comparative deployments for ambiguous real-world tasks.
- Chain-of-thought prompting should be avoided in comparative bias audits because it increases prejudice expression.
- Bias evaluations must control for structural framing or risk contradictory conclusions across studies.
- The observed prejudice scales with model size, so larger models require stricter comparative testing.
Where Pith is reading between the lines
- Models may internally perform similar comparisons even on single-group queries in real deployments, suggesting the need to test for implicit comparative reasoning.
- The framework could be applied to non-social bias domains such as factual consistency or safety to check if comparative framing has analogous effects.
- If underspecified contexts drive the effect, adding explicit neutral context might reduce the comparative prejudice without changing the evaluation structure.
Load-bearing premise
Standardizing heterogeneous benchmarks into a single controllable framework successfully isolates the effects of comparative versus isolated settings without introducing new structural artifacts or selection biases.
What would settle it
Re-running the standardized benchmarks on the same models and finding no reliable increase in bias scores when switching from isolated to comparative prompts would falsify the central claim.
Figures
read the original abstract
As Large Language Models are increasingly deployed in critical applications, robustly evaluating their social biases is paramount. However, the current literature suffers from widespread methodological fragmentation, which yields contradictory conclusions. This stems largely from ignoring the structural framing of benchmark-level evaluations. To resolve this, we introduce a unified and controllable framework that standardizes heterogeneous benchmarks to systematically contrast isolated demographic assessments with forced-choice comparative settings. Crucially, this allows us to disentangle the confounding effects of Chain-of-Thought reasoning, neutral fallback options, and other structural artifacts in social bias evaluations. Our evaluation across multiple model families reveals a massive, systematic paradigm gap: while isolated assessments limit prejudice activation, comparative settings act as aggressive catalysts for latent discrimination, a shift primarily driven by underspecified contexts. Alarmingly, CoT reasoning exacerbates social biases under comparative settings, and this systemic bias persists as a deterministic prejudice even when models are provided neutral fallback options or claim to answer randomly. Finally, we demonstrate that this comparative prejudice is a generalized phenomenon that scales positively with model size. Ultimately, we offer a crucial methodological guideline: while researchers must leverage comparative settings to robustly audit hidden biases, practitioners cannot safely rely on comparative deployments in ambiguous real-world tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified controllable framework that standardizes heterogeneous social-bias benchmarks to contrast isolated demographic assessments against forced-choice comparative settings. It reports a large paradigm gap in which comparative settings catalyze latent discrimination (primarily via underspecified contexts), CoT reasoning exacerbates bias under comparison, the effect persists even with neutral fallback options or random-answer claims, and the prejudice scales positively with model size. The authors conclude that comparative settings are necessary for robust auditing but unsafe for ambiguous real-world deployment.
Significance. If the central empirical contrast holds after controls for standardization artifacts, the work would supply a concrete methodological diagnosis for contradictory findings in the bias-evaluation literature and a practical guideline distinguishing auditing from deployment. The scaling result and the persistence under neutral options would be particularly useful for model developers and benchmark designers.
major comments (3)
- [Framework] Framework section: the claim that standardization successfully isolates the comparative vs. isolated contrast rests on the untested assumption that converting open-ended items to paired choices preserves semantics, prompt length, and implicit framing. No ablation or control experiment is described that measures bias activation on the transformed items before the comparative manipulation is applied.
- [Experiments / Results] Results across model families: the abstract states findings hold across families yet supplies no table or appendix listing the exact models, number of runs, statistical tests, or error bars. Without these, the reported paradigm gap and scaling trend cannot be assessed for robustness.
- [Analysis] Analysis of underspecified contexts: the assertion that the shift is 'primarily driven by underspecified contexts' requires a quantitative decomposition (e.g., a table contrasting bias scores on high- vs. low-specification prompts within the same comparative setting). No such breakdown is referenced.
minor comments (2)
- [Abstract] The abstract uses 'massive' and 'aggressive catalysts' without accompanying effect-size numbers; replace with quantitative descriptors once the results tables are added.
- [Experimental setup] Clarify whether the neutral-fallback and random-answer conditions were run on the same prompt templates or required additional prompt engineering; this affects reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We believe the suggested additions will enhance the clarity and robustness of our findings. Below we respond to each major comment.
read point-by-point responses
-
Referee: [Framework] Framework section: the claim that standardization successfully isolates the comparative vs. isolated contrast rests on the untested assumption that converting open-ended items to paired choices preserves semantics, prompt length, and implicit framing. No ablation or control experiment is described that measures bias activation on the transformed items before the comparative manipulation is applied.
Authors: We agree that an explicit control experiment would provide stronger evidence that the standardization process preserves the relevant properties. In the revised manuscript, we will include an ablation study that measures bias activation on the transformed paired-choice items (before the comparative manipulation is applied) and compare it to the original open-ended versions to verify semantic preservation. revision: yes
-
Referee: [Experiments / Results] Results across model families: the abstract states findings hold across families yet supplies no table or appendix listing the exact models, number of runs, statistical tests, or error bars. Without these, the reported paradigm gap and scaling trend cannot be assessed for robustness.
Authors: We will add a detailed table in the appendix listing all models evaluated, the number of runs per experiment, the statistical tests applied, and error bars for key metrics to allow assessment of robustness. revision: yes
-
Referee: [Analysis] Analysis of underspecified contexts: the assertion that the shift is 'primarily driven by underspecified contexts' requires a quantitative decomposition (e.g., a table contrasting bias scores on high- vs. low-specification prompts within the same comparative setting). No such breakdown is referenced.
Authors: We will include a quantitative decomposition in the revised manuscript, specifically a table or figure that contrasts bias scores on high- versus low-specification prompts within the comparative setting to substantiate the claim regarding the primary driver of the paradigm shift. revision: yes
Circularity Check
No circularity; empirical standardization framework is self-contained
full rationale
The paper introduces a controllable standardization framework to contrast isolated vs. comparative bias evaluations and reports experimental results across model families. No equations, derivations, fitted parameters, or self-citation chains appear in the provided text. The central claims rest on observed paradigm gaps in the experiments rather than reducing by construction to the framework definition or prior self-citations. The standardization procedure is presented as an independent methodological tool whose validity is tested via the reported outcomes, not presupposed.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Quantifying memorization across neural lan- guage models. InThe Eleventh International Confer- enceonLearningRepresentations,ICLR2023,Kigali, Rwanda, May 1-5, 2023. OpenReview.net. JavierCoronado-Blázquez.2025. Deterministicorprob- abilistic? the psychology of llms as random number generators.CoRR, abs/2502.19965. Jwala Dhamala, Tony Sun, Varun Kumar, Sat...
arXiv 2023
-
[2]
In9th International Conference on Learn- ing Representations, ICLR 2021, Virtual Event, Aus- tria, May 3-7, 2021
Measuring massive multitask language under- standing. In9th International Conference on Learn- ing Representations, ICLR 2021, Virtual Event, Aus- tria, May 3-7, 2021. OpenReview.net. Mahammed Kamruzzaman and Gene Louis Kim. 2025. Prompting techniques for reducing social bias in llms through system 1 and system 2 cognitive processes. InProceedings of the ...
2021
-
[3]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yu- taka Matsuo, and Yusuke Iwasawa
Association for Computational Linguistics. Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yu- taka Matsuo, and Yusuke Iwasawa. 2022. Large lan- guage models are zero-shot reasoners. InAdvances in Neural Information Processing Systems 35: An- nual Conference on Neural Information Processing Systems2022, NeurIPS2022, NewOrleans, LA,USA, November 28 - Decem...
Pith/arXiv arXiv 2022
-
[4]
Association for Computational Linguistics. Yarden Tal, Inbal Magar, and Roy Schwartz. 2022. Fewer errors, but more stereotypes? the effect of model size on gender bias. InProceedings of the 4th Workshop on Gender Bias in Natural Language Processing(GeBNLP),pages112–120,Seattle,Wash- ington. Association for Computational Linguistics. Alex Tamkin, Amanda As...
arXiv 2022
-
[5]
You are an expert in question-answering tasks
-
[6]
instructions:[1] Please provide your final answer as one of the following: \boxed{X} or \boxed{Y}
You are an expert in answering multiple-choice questions. instructions:[1] Please provide your final answer as one of the following: \boxed{X} or \boxed{Y}
-
[7]
Your final answer should be one of these: \boxed{X} or \boxed{Y}
-
[8]
cot footers:[1] Please reason step by step and then provide your final answer inside a \boxed{}
Provide your final answer using the following format exactly: \boxed{X} or \boxed{Y}. cot footers:[1] Please reason step by step and then provide your final answer inside a \boxed{}
-
[9]
Provide a step-by-step reasoning before giving your final answer in a \boxed{}
-
[10]
no-cot footers:[1] Provide your final answer immediately at the end of this prompt, inside \boxed{}
Think through the question carefully step by step, then give your final answer in a \boxed{}. no-cot footers:[1] Provide your final answer immediately at the end of this prompt, inside \boxed{}. My answer would be: \boxed{
-
[11]
My answer is: \boxed{
State your final answer directly at the end of this prompt within a \boxed{}. My answer is: \boxed{
-
[12]
A”/“B” or “Yes
Without any additional reasoning, provide your final answer inside \boxed{} at the end of this prompt. The final answer is: \boxed{ Prompt 14: Exhaustive list of prompt component variations (headers, instructions, and footers) used for the prompt variation analysis. Placeholders\boxed{X}and \boxed{Y}are dynamically replaced with the task-specific options ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.