Themis: An explainable AI-enabled framework for Reinforcement Learning with Human Feedback
Pith reviewed 2026-06-25 23:33 UTC · model grok-4.3
The pith
Themis framework allows training of reward models from human preferences that match or outperform true environment rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Themis is an explainable AI-enabled framework for reinforcement learning with human feedback that supports over 200 environments and can train reward models using human preferences collected via its cloud platform, with results showing these models match or outperform the environment's true reward signal.
What carries the argument
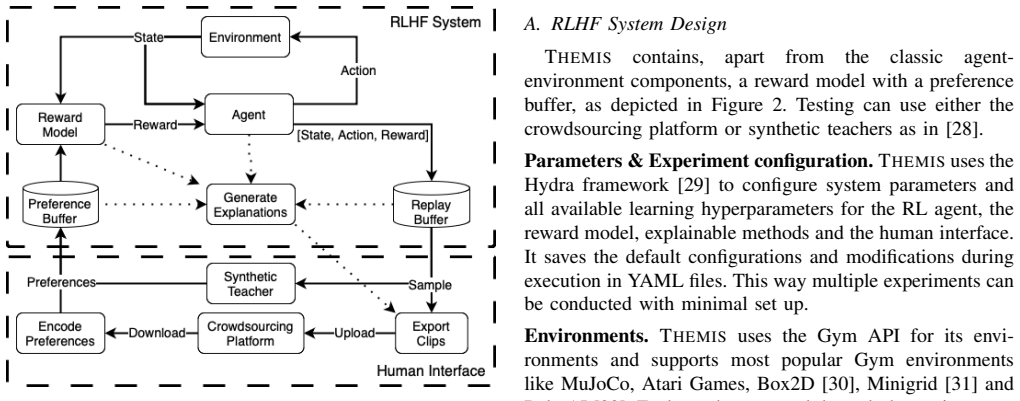
The Themis framework integrating XAI for transparency with RLHF for alignment, including a cloud-based platform for human feedback collection and experiment management.
If this is right
- RL systems can be trained without direct access to ground-truth rewards by using human preferences instead.
- Transparency features can be added to standard RLHF processes.
- Experiments in alignment can be conducted across a broad set of standard environments with minimal setup.
- Human feedback can be gathered from large groups efficiently using modest computing resources.
- Reward models can be evaluated and improved through the integrated testing tools.
Where Pith is reading between the lines
- The approach might help in domains where defining rewards is difficult, such as complex real-world tasks.
- Scaling the platform could support community-driven alignment efforts for AI models.
- Combining with other XAI methods could lead to better debugging of misaligned behaviors.
- The framework's configurability suggests applications in testing alignment across different RL algorithms.
Load-bearing premise
The assumption that human preference data can be used to train reward models that reliably generalize to or exceed the environment's ground-truth reward without introducing new biases or overfitting to the collected preferences.
What would settle it
Running Themis-trained reward models in environments where they underperform the true reward signal on metrics like task success rate or safety violations.
Figures


read the original abstract
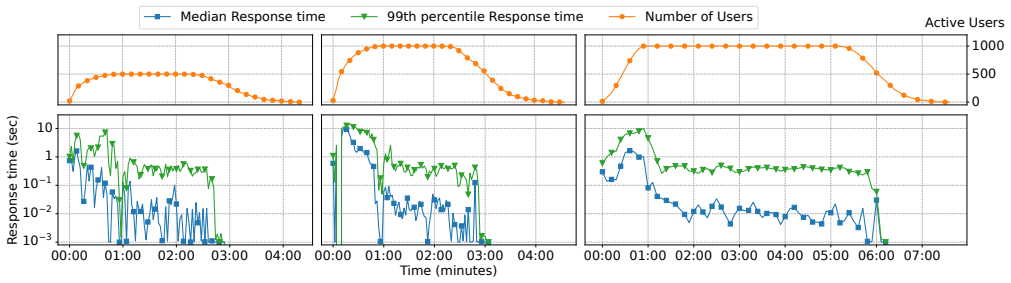
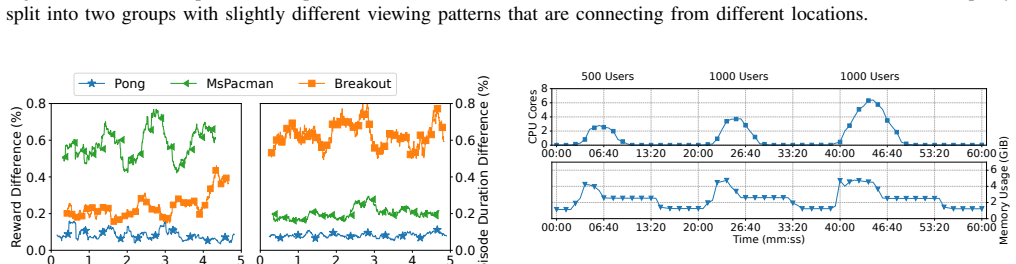
Training safe Reinforcement Learning (RL) systems is inherently challenging, with no guarantee of avoiding unwanted behaviors. The most effective defenses against this are (i) transparency through explainability and (ii) alignment via human feedback. While both show promising results, no publicly available framework currently combines them. To address this, we introduce Themis, an XAI-enabled testing and evaluation framework for Reinforcement Learning from Human Feedback. Themis supports over 200 widely used environments and is easily configurable for experiments in RL, transparency, and alignment. Our results show that Themis can train reward models that match or outperform the environment's true reward signal using human preferences. We also provide a cloud-based platform for collecting human feedback and managing experiments. It is user-friendly, auto-scalable, and supports large participant groups across multiple experiments without extra development overhead. Tests show Themis can support one thousand users in back-to-back experiments on a modest commercial machine.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Themis, an XAI-enabled framework for Reinforcement Learning from Human Feedback (RLHF) that supports over 200 environments, includes a configurable testing platform, and provides a cloud-based system for collecting and managing human preference data at scale. The central claim is that reward models trained via Themis using human preferences can match or outperform the environment's ground-truth reward signal, with additional tests showing the platform supports 1000 users on modest hardware.
Significance. If the reward-model performance claim were substantiated with proper experimental controls, the work would offer a practical open-source contribution for combining transparency and alignment in RL. The broad environment compatibility and auto-scalable feedback platform address real tooling gaps. However, the absence of any reported experimental protocol, metrics, or comparisons means the significance cannot be assessed beyond the framework description itself.
major comments (3)
- [Abstract] Abstract: The claim that 'Themis can train reward models that match or outperform the environment's true reward signal using human preferences' is stated without any description of experimental setup, preference collection protocol, number of participants or labels, evaluation metrics (e.g., reward correlation on held-out trajectories, policy return under true reward), baselines, or statistical tests. This renders the central empirical assertion impossible to evaluate for bias, overfitting, or selection effects.
- [Framework description] No section provides details on how the XAI components are integrated with the RLHF pipeline or how explainability is measured or used to improve reward model training; the framework description therefore does not support the 'XAI-enabled' positioning as a load-bearing contribution.
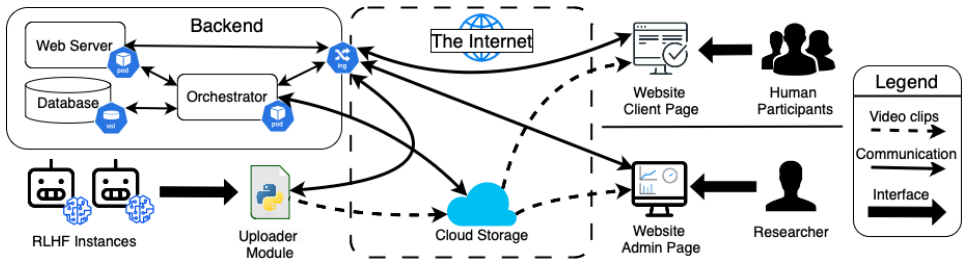
- [Platform evaluation] The scalability test ('support one thousand users in back-to-back experiments on a modest commercial machine') lacks any specification of hardware, concurrency model, data volume per experiment, or failure modes, preventing assessment of the platform's practical utility.
minor comments (2)
- [Abstract] The abstract and introduction use 'XAI-enabled' and 'transparency through explainability' without defining which XAI techniques are implemented or how they interface with the reward model.
- [Conclusion] No mention of code or data availability, which is standard for a framework paper claiming broad environment support.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating planned revisions to improve the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'Themis can train reward models that match or outperform the environment's true reward signal using human preferences' is stated without any description of experimental setup, preference collection protocol, number of participants or labels, evaluation metrics (e.g., reward correlation on held-out trajectories, policy return under true reward), baselines, or statistical tests. This renders the central empirical assertion impossible to evaluate for bias, overfitting, or selection effects.
Authors: We agree that the abstract presents an empirical claim without the necessary supporting details on experimental protocol, metrics, or comparisons. The current manuscript focuses primarily on the framework and platform, and the claim is not substantiated with reported experiments. We will revise the abstract to remove or qualify this claim and add a dedicated experimental evaluation section describing the setup, participant numbers, preference collection, metrics (including reward correlation and policy returns), baselines, and statistical tests. revision: yes
-
Referee: [Framework description] No section provides details on how the XAI components are integrated with the RLHF pipeline or how explainability is measured or used to improve reward model training; the framework description therefore does not support the 'XAI-enabled' positioning as a load-bearing contribution.
Authors: The manuscript positions Themis as XAI-enabled but does not detail the integration of XAI methods into the RLHF pipeline or how explainability is measured and applied to improve training. We acknowledge this as a gap in the current description. We will expand the framework section to specify the XAI components, their integration points, measurement approaches, and usage in reward model training. revision: yes
-
Referee: [Platform evaluation] The scalability test ('support one thousand users in back-to-back experiments on a modest commercial machine') lacks any specification of hardware, concurrency model, data volume per experiment, or failure modes, preventing assessment of the platform's practical utility.
Authors: We agree that the scalability evaluation lacks critical implementation details. We will revise the platform evaluation section to specify the hardware used, concurrency model, data volumes per experiment, and any observed failure modes or limitations. revision: yes
Circularity Check
No circularity: framework description with no derivation chain
full rationale
The paper introduces a software framework (Themis) for RLHF with XAI support across environments and a cloud platform for feedback collection. Its central claim is an empirical statement about reward models trained on human preferences matching or exceeding ground-truth rewards. No equations, derivations, fitted parameters presented as predictions, uniqueness theorems, or self-citations that bear load on a mathematical result appear in the abstract or described content. The work is self-contained as a tool description and experimental report rather than a closed-form result that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Themis framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A systematic study on reinforcement learning based applications,
K. Sivamayil, E. Rajasekar, B. Aljafari, S. Nikolovski, S. Vairavasun- daram, and I. Vairavasundaram, “A systematic study on reinforcement learning based applications,”Energies, vol. 16, no. 3, p. 1512, 2023
2023
-
[2]
Deep reinforcement learning for autonomous driving: A survey,
B. R. Kiran, I. Sobh, V . Talpaert, P. Mannion, A. A. Al Sallab, S. Yo- gamani, and P. P ´erez, “Deep reinforcement learning for autonomous driving: A survey,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 6, pp. 4909–4926, 2021
2021
-
[3]
Deep reinforcement learning for robotics: A survey of real-world successes,
C. Tang, B. Abbatematteo, J. Hu, R. Chandra, R. Mart ´ın-Mart´ın, and P. Stone, “Deep reinforcement learning for robotics: A survey of real-world successes,”Annual Review of Control, Robotics, and Autonomous Systems, vol. 8, 2024
2024
-
[4]
A review on reinforcement learning: Introduction and applications in industrial process control,
R. Nian, J. Liu, and B. Huang, “A review on reinforcement learning: Introduction and applications in industrial process control,”Computers & Chemical Engineering, vol. 139, p. 106886, 2020
2020
-
[5]
Training language models to follow instructions with human feedback
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” 2022. [Online]. Available: https://arxiv.org/abs/2203.02155
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Mastering the game of go with deep neural networks and tree search,
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. Van Den Driessche, J. Schrittwieser, I. Antonoglou, V . Panneershelvam, M. Lanctotet al., “Mastering the game of go with deep neural networks and tree search,”nature, vol. 529, no. 7587, pp. 484–489, 2016
2016
-
[7]
Defining and characterizing reward gaming,
J. Skalse, N. Howe, D. Krasheninnikov, and D. Krueger, “Defining and characterizing reward gaming,”Advances in Neural Information Processing Systems, vol. 35, pp. 9460–9471, 2022
2022
-
[8]
Reward learning from human preferences and demonstrations in atari,
B. Ibarz, J. Leike, T. Pohlen, G. Irving, S. Legg, and D. Amodei, “Reward learning from human preferences and demonstrations in atari,”NeurIPS, vol. 31, 2018
2018
-
[9]
Deep reinforcement learning from human preferences,
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” NeurIPS, vol. 30, 2017
2017
-
[10]
Human-in-the-loop deep reinforcement learning with application to autonomous driving,
J. Wu, Z. Huang, C. Huang, Z. Hu, P. Hang, Y . Xing, and C. Lv, “Human-in-the-loop deep reinforcement learning with application to autonomous driving,”preprint arXiv:2104.07246, 2021
-
[11]
The utility of explainable ai in ad hoc human-machine teaming,
R. Paleja, M. Ghuy, N. Ranawaka Arachchige, R. Jensen, and M. Gombolay, “The utility of explainable ai in ad hoc human-machine teaming,”Advances in Neural Information Processing Systems, vol. 34, pp. 610–623, 2021
2021
-
[12]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
S. Casper, X. Davies, C. Shi, T. K. Gilbert, J. Scheurer, J. Rando, R. Freedman, T. Korbak, D. Lindner, P. Freireet al., “Open problems and fundamental limitations of reinforcement learning from human feedback,”arXiv preprint arXiv:2307.15217, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
R. S. Sutton and A. G. Barto,Reinforcement learning: An introduction. MIT press, 2018
2018
-
[14]
An overview of the action space for deep reinforcement learning,
J. Zhu, F. Wu, and J. Zhao, “An overview of the action space for deep reinforcement learning,” inProceedings of the 2021 4th International Conference on Algorithms, Computing and Artificial Intelligence, 2021, pp. 1–10
2021
-
[15]
Human-level control through deep reinforcement learning,
V . Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[16]
Apprenticeship learning via inverse rein- forcement learning,
P. Abbeel and A. Y . Ng, “Apprenticeship learning via inverse rein- forcement learning,” inProceedings of the twenty-first international conference on Machine learning, 2004, p. 1
2004
-
[17]
DQN-TAMER: Human-in-the-Loop Reinforcement Learning with Intractable Feedback
R. Arakawa, S. Kobayashi, Y . Unno, Y . Tsuboi, and S.-i. Maeda, “Dqn- tamer: Human-in-the-loop reinforcement learning with intractable feedback,”preprint arXiv:1810.11748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
K. Lee, L. Smith, and P. Abbeel, “Pebble: Feedback-efficient interac- tive reinforcement learning via relabeling experience and unsupervised pre-training,”arXiv preprint arXiv:2106.05091, 2021
-
[19]
J. Park, Y . Seo, J. Shin, H. Lee, P. Abbeel, and K. Lee, “Surf: Semi-supervised reward learning with data augmentation for feedback- efficient preference-based reinforcement learning,”arXiv preprint arXiv:2203.10050, 2022
-
[20]
Human preference scaling with demonstrations for deep reinforcement learning,
Z. Cao, K. Wong, and C.-T. Lin, “Human preference scaling with demonstrations for deep reinforcement learning,”arXiv preprint arXiv:2007.12904, 2020
-
[21]
A survey on interactive reinforcement learning: Design principles and open challenges,
C. Arzate Cruz and T. Igarashi, “A survey on interactive reinforcement learning: Design principles and open challenges,” inProc. of the 2020 ACM Designing Interactive Systems Conference, ser. DIS ’20. New York, NY , USA: Association for Computing Machinery, 2020, p. 1195–1209. [Online]. Available: https://doi.org/10.1145/3357236. 3395525
-
[22]
Leveraging human guidance for deep reinforcement learning tasks,
R. Zhang, F. Torabi, L. Guan, D. H. Ballard, and P. Stone, “Leveraging human guidance for deep reinforcement learning tasks,” 2019
2019
-
[23]
Knowledge-based causal attribution: The abnormal conditions focus model
D. J. Hilton and B. R. Slugoski, “Knowledge-based causal attribution: The abnormal conditions focus model.”Psychological review, vol. 93, no. 1, p. 75, 1986
1986
-
[24]
Collective ex- plainable ai: Explaining cooperative strategies and agent contribution in multiagent reinforcement learning with shapley values,
A. Heuillet, F. Couthouis, and N. D ´ıaz-Rodr´ıguez, “Collective ex- plainable ai: Explaining cooperative strategies and agent contribution in multiagent reinforcement learning with shapley values,”IEEE Computational Intelligence Magazine, vol. 17, no. 1, pp. 59–71, 2022
2022
-
[25]
Visualizing and understanding atari agents,
S. Greydanus, A. Koul, J. Dodge, and A. Fern, “Visualizing and understanding atari agents,” inICML. PMLR, 2018, pp. 1792–1801
2018
-
[26]
A survey on explainable rein- forcement learning: Concepts, algorithms, challenges,
Y . Qing, S. Liu, J. Song, and M. Song, “A survey on explainable rein- forcement learning: Concepts, algorithms, challenges,”arXiv preprint arXiv:2211.06665, 2022
-
[27]
Explainable deep reinforcement learning: state of the art and challenges,
G. A. V ouros, “Explainable deep reinforcement learning: state of the art and challenges,”ACM Computing Surveys, vol. 55, no. 5, pp. 1–39, 2022
2022
-
[28]
B-pref: Benchmarking preference-based reinforcement learning,
K. Lee, L. Smith, A. Dragan, and P. Abbeel, “B-pref: Benchmarking preference-based reinforcement learning,” inThirty-fifth Conference on NeurIPS Datasets and Benchmarks Track, 2021
2021
-
[29]
Hydra - a framework for elegantly configuring complex applications,
O. Yadan, “Hydra - a framework for elegantly configuring complex applications,” Github, 2019. [Online]. Available: https: //github.com/facebookresearch/hydra
2019
-
[30]
M. Towers, J. K. Terry, A. Kwiatkowski, J. U. Balis, G. d. Cola, T. Deleu, M. Goul ˜ao, A. Kallinteris, A. KG, M. Krimmel, R. Perez-Vicente, A. Pierr ´e, S. Schulhoff, J. J. Tai, A. T. J. Shen, and O. G. Younis, “Gymnasium,” Mar. 2023. [Online]. Available: https://zenodo.org/record/8127025
-
[31]
M. Chevalier-Boisvert, B. Dai, M. Towers, R. de Lazcano, L. Willems, S. Lahlou, S. Pal, P. S. Castro, and J. Terry, “Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks,”CoRR, vol. abs/2306.13831, 2023
-
[32]
Babyai: A platform to study the sample efficiency of grounded language learning,
M. Chevalier-Boisvert, D. Bahdanau, S. Lahlou, L. Willems, C. Sa- haria, T. H. Nguyen, and Y . Bengio, “Babyai: A platform to study the sample efficiency of grounded language learning,”arXiv preprint arXiv:1810.08272, 2018
-
[33]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” inProceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsm ¨assan, Stockholm, Sweden, July 10-15, 2018, ser. Proceedings of Machine Learning Research, J. G. Dy and A. Kraus...
2018
-
[34]
Soft actor-critic for discrete action settings,
P. Christodoulou, “Soft actor-critic for discrete action settings,” 2019
2019
-
[35]
Rank analysis of incomplete block designs: I. the method of paired comparisons,
R. A. Bradley and M. E. Terry, “Rank analysis of incomplete block designs: I. the method of paired comparisons,”Biometrika, vol. 39, no. 3/4, pp. 324–345, 1952
1952
-
[36]
Maximizing the efficiency of human feedback in AI alignment: a comparative analysis
A. Chouliaras and D. Chatzopoulos, “Maximizing the efficiency of human feedback in ai alignment: a comparative analysis,”arXiv preprint arXiv:2511.12796, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Local and global explanations of agent behavior: Integrating strategy summaries with saliency maps,
T. Huber, K. Weitz, E. Andr ´e, and O. Amir, “Local and global explanations of agent behavior: Integrating strategy summaries with saliency maps,”Artificial Intelligence, vol. 301, p. 103571, 2021
2021
-
[38]
Captum: A unified and generic model inter- pretability library for pytorch,
N. Kokhlikyan, V . Miglani, M. Martin, E. Wang, B. Alsallakh, J. Reynolds, A. Melnikov, N. Kliushkina, C. Araya, S. Yan, and O. Reblitz-Richardson, “Captum: A unified and generic model inter- pretability library for pytorch,” 2020
2020
-
[39]
Axiomatic attribution for deep networks,
M. Sundararajan, A. Taly, and Q. Yan, “Axiomatic attribution for deep networks,” inICML. PMLR, 2017, pp. 3319–3328
2017
-
[40]
A unified approach to interpreting model predictions,
S. M. Lundberg and S.-I. Lee, “A unified approach to interpreting model predictions,”NeurIPS, vol. 30, 2017
2017
-
[41]
Estimating training data influence by tracing gradient descent,
G. Pruthi, F. Liu, S. Kale, and M. Sundararajan, “Estimating training data influence by tracing gradient descent,”NeurIPS, vol. 33, pp. 19 920–19 930, 2020
2020
-
[42]
Mongodb: The developer data platform,
M. Inc., “Mongodb: The developer data platform,” Github, 2009. [Online]. Available: https://github.com/mongodb/mongo
2009
-
[43]
Next.js: The react framework,
Vercel, “Next.js: The react framework,” Github, 2016. [Online]. Available: https://github.com/vercel/next.js
2016
-
[44]
The arcade learning environment: An evaluation platform for general agents,
M. G. Bellemare, Y . Naddaf, J. Veness, and M. Bowling, “The arcade learning environment: An evaluation platform for general agents,” Journal of Artificial Intelligence Research, vol. 47, pp. 253–279, 2013
2013
-
[45]
Loadster: A load testing & website stress testing tool,
Loadster, “Loadster: A load testing & website stress testing tool,”
-
[46]
Available: https://loadster.app/
[Online]. Available: https://loadster.app/
-
[47]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,” in2012 IEEE/RSJ international conference on intelligent robots and systems. IEEE, 2012, pp. 5026–5033
2012
-
[48]
Trust Region Policy Optimization
J. Schulman, “Trust region policy optimization,”arXiv preprint arXiv:1502.05477, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[49]
Asynchronous Methods for Deep Reinforcement Learning
V . Mnih, A. P. Badia, M. Mirza, A. Graves, T. P. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” 2016. [Online]. Available: https: //arxiv.org/abs/1602.01783
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[50]
Widening the pipeline in human-guided reinforcement learning with explanation and context-aware data augmentation,
L. Guan, M. Verma, S. Guo, R. Zhang, and S. Kambhampati, “Widening the pipeline in human-guided reinforcement learning with explanation and context-aware data augmentation,” 2021. APPENDIX A: USINGTHEMIS In this section, we explain how to set up THEMIS, deploy it, and use it to conduct experiments with synthetic teachers and human participants. We separat...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.