Are We Ready For An Agent-Native Memory System?
Pith reviewed 2026-06-25 23:50 UTC · model grok-4.3
The pith
Agent memory systems succeed when their structure aligns with the specific workload bottleneck instead of any one design dominating all cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
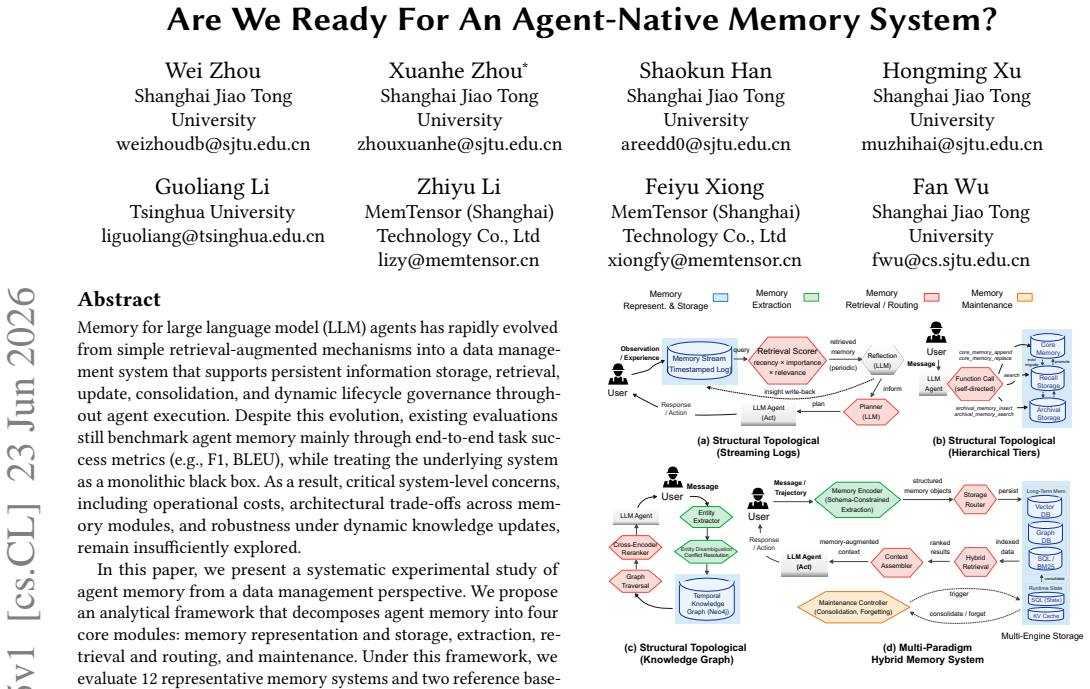
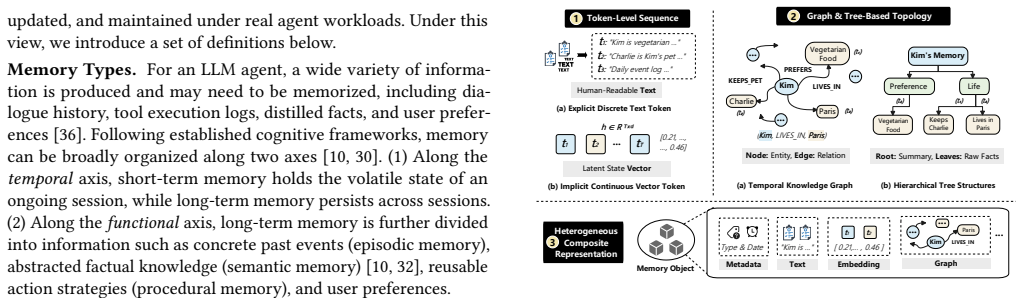
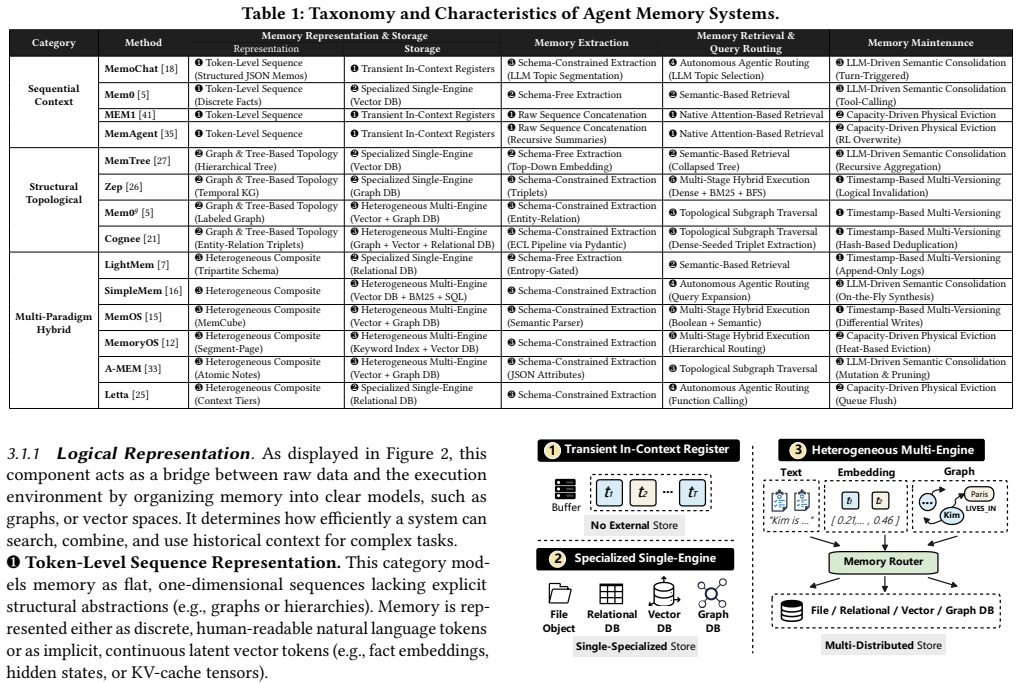
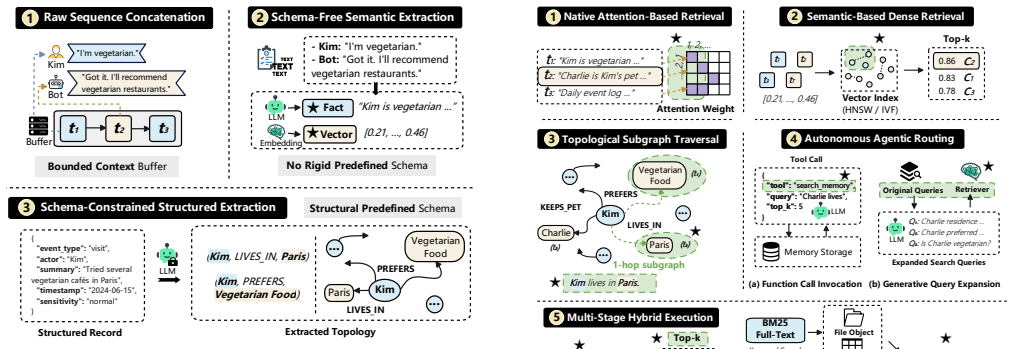
Agent memory for large language model agents has evolved into a full data management system, yet evaluations have remained limited to end-to-end task metrics. By decomposing memory into representation and storage, extraction, retrieval and routing, and maintenance modules, systematic testing of twelve systems across five workloads demonstrates that effectiveness is determined by alignment between memory structure and workload bottleneck, and that localized maintenance is more cost-efficient than global reorganization.
What carries the argument
The four-module analytical framework that decomposes agent memory into representation and storage, extraction, retrieval and routing, and maintenance.
If this is right
- Different agent workloads require different memory architectures depending on their dominant bottleneck.
- Localized maintenance strategies deliver lower operational cost than global reorganization under realistic update loads.
- Fine-grained module-level measurements are needed to predict effects on representation fidelity, retrieval precision, update correctness, and long-horizon stability.
- End-to-end task success metrics alone cannot reveal the system-level cost and robustness trade-offs in agent memory.
- Future agent memory systems should be designed around workload-specific module combinations rather than monolithic structures.
Where Pith is reading between the lines
- Agent builders may benefit from profiling expected workloads first and then selecting or composing memory modules to match the identified bottleneck.
- The module decomposition could be tested for completeness by adding workloads that involve frequent cross-agent knowledge sharing.
- Cost measurements under the localized approach may encourage deployment choices that favor incremental updates in production agent systems.
- Extending the evaluation to include multi-agent coordination scenarios could reveal additional interactions between retrieval and maintenance modules.
Load-bearing premise
The twelve chosen memory systems, five workloads, and eleven datasets adequately represent the range of agent memory scenarios and the four-module breakdown captures the essential functional aspects without important omissions or interactions.
What would settle it
A workload or dataset in which a poorly aligned architecture still achieves high performance on the measured metrics, or in which global reorganization proves cheaper than localized maintenance under the same update patterns.
Figures

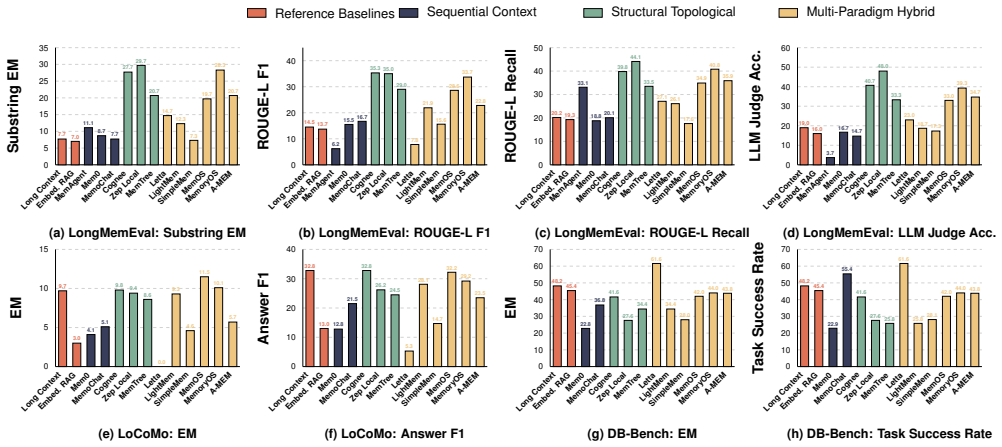
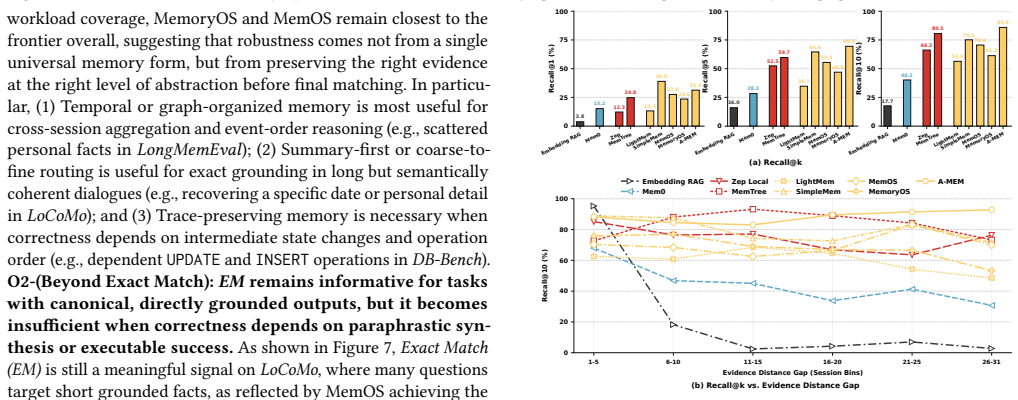
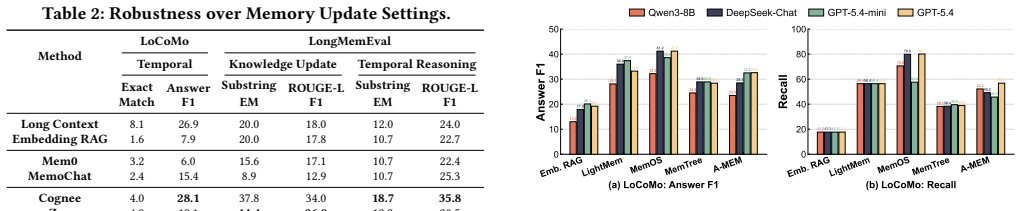
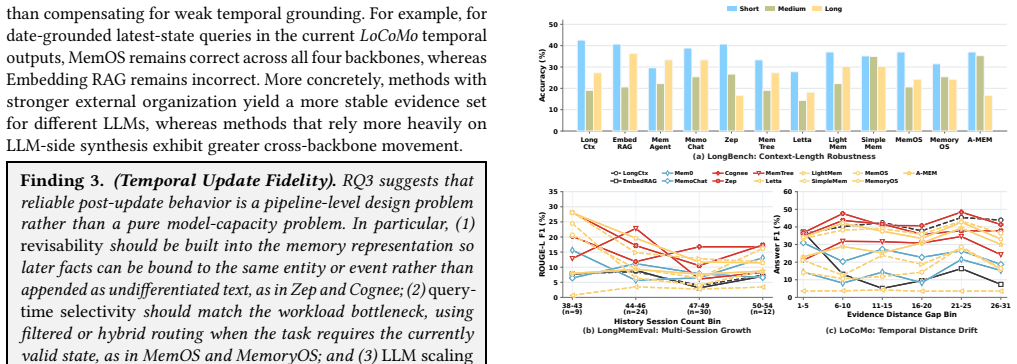
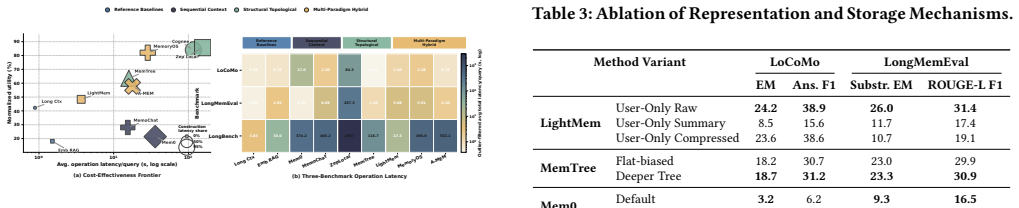
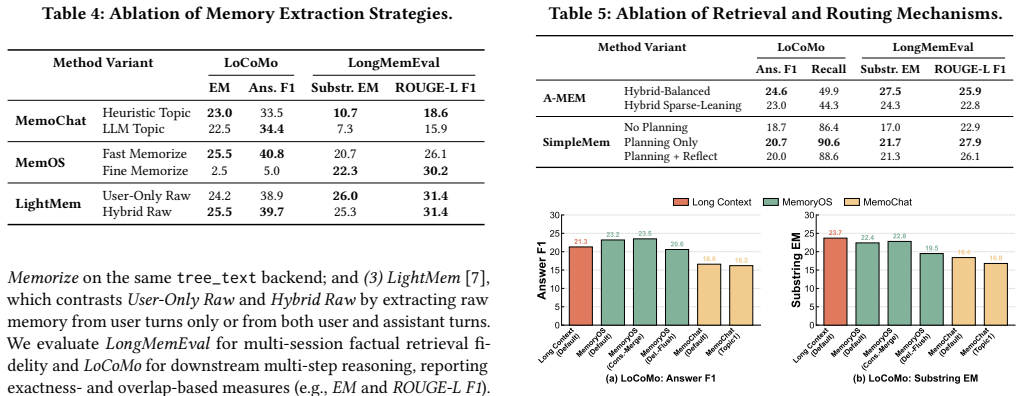
read the original abstract
Memory for large language model (LLM) agents has rapidly evolved from simple retrieval-augmented mechanisms into a data management system that supports persistent information storage, retrieval, update, consolidation, and dynamic lifecycle governance throughout agent execution. Despite this evolution, existing evaluations still benchmark agent memory mainly through end-to-end task success metrics (e.g., F1, BLEU), while treating the underlying system as a monolithic black box. As a result, critical system-level concerns, including operational costs, architectural trade-offs across memory modules, and robustness under dynamic knowledge updates, remain insufficiently explored. In this paper, we present a systematic experimental study of agent memory from a data management perspective. We propose an analytical framework that decomposes agent memory into four core modules: memory representation and storage, extraction, retrieval and routing, and maintenance. Under this framework, we evaluate 12 representative memory systems and two reference baselines across five benchmark workloads spanning 11 datasets. Our extensive end-to-end evaluation shows that no single architecture dominates across all scenarios; instead, effectiveness depends heavily on how well the memory structure aligns with the workload bottleneck. Furthermore, through fine-grained ablation studies, we quantify their individual effects on representation fidelity, retrieval precision, update correctness, and long-horizon stability. Finally, we reveal cost-performance trade-offs under realistic workloads, showing localized maintenance is more cost-efficient than global reorganization. Based on these findings, we identify promising directions towards building truly agent-native memory systems. The code is publicly available at https://github.com/OpenDataBox/MemoryData.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that agent memory for LLM agents should be analyzed via a four-module decomposition (representation/storage, extraction, retrieval/routing, maintenance); an evaluation of 12 representative systems plus baselines on five workloads spanning 11 datasets shows that no architecture dominates across scenarios, with performance instead depending on alignment to workload-specific bottlenecks, and that localized maintenance is more cost-efficient than global reorganization. These conclusions rest on end-to-end metrics, module ablations, and cost analyses, with code released publicly.
Significance. If the chosen systems and workloads prove representative, the work would supply concrete empirical evidence on architectural trade-offs and cost-performance frontiers that current end-to-end task-success benchmarks obscure. The public code release strengthens reproducibility and enables follow-on studies. The result would usefully shift the field from monolithic black-box evaluations toward modular, bottleneck-aware design.
major comments (2)
- [Experimental evaluation and workload description] The central claim that 'no single architecture dominates' (Abstract) is load-bearing on the representativeness of the 12 systems, 5 workloads, and 11 datasets; the manuscript must explicitly demonstrate that these selections expose distinct per-module bottlenecks and include scenarios such as continual lifelong consolidation with conflicting updates or strict latency constraints, otherwise the observed lack of dominance could be an artifact of the chosen slice rather than a general property.
- [Framework definition and ablation studies] The four-module decomposition is presented as capturing the essential functional aspects, yet the paper does not show that cross-module feedback loops (e.g., maintenance affecting retrieval routing) are negligible; if such interactions dominate in untested regimes, the fine-grained ablation results on individual module effects would not generalize.
minor comments (1)
- [Evaluation methodology] The abstract states that 'extensive end-to-end tests and ablations' were performed; the main text should report the exact statistical controls, number of runs, and any post-hoc workload filtering to allow readers to assess robustness.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help strengthen the manuscript. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experimental evaluation and workload description] The central claim that 'no single architecture dominates' (Abstract) is load-bearing on the representativeness of the 12 systems, 5 workloads, and 11 datasets; the manuscript must explicitly demonstrate that these selections expose distinct per-module bottlenecks and include scenarios such as continual lifelong consolidation with conflicting updates or strict latency constraints, otherwise the observed lack of dominance could be an artifact of the chosen slice rather than a general property.
Authors: We agree that demonstrating representativeness is essential to support the central claim. The five workloads were selected to target different module-level bottlenecks (e.g., storage/retrieval intensity in long-context QA, update frequency in conversational settings, and maintenance load in multi-session tasks), with the 11 datasets providing coverage across domains. In the revision we will add an explicit mapping in Section 3 (and a new table) that links each workload to the primary bottlenecks it stresses, supported by the module ablation results already reported. However, scenarios involving continual lifelong consolidation with conflicting updates or strict latency constraints are not present in the current evaluation suite. We will add a limitations paragraph acknowledging that the 'no single architecture dominates' finding is scoped to the tested workloads and may not extend to these unexamined regimes; we view these as valuable directions for follow-on work rather than changes feasible within the current experimental budget. revision: partial
-
Referee: [Framework definition and ablation studies] The four-module decomposition is presented as capturing the essential functional aspects, yet the paper does not show that cross-module feedback loops (e.g., maintenance affecting retrieval routing) are negligible; if such interactions dominate in untested regimes, the fine-grained ablation results on individual module effects would not generalize.
Authors: The four-module framework is offered as an analytical lens for isolating effects rather than an assertion of complete independence. Our ablations hold three modules fixed while varying the fourth, and the resulting performance patterns remain stable across the five workloads. That said, we did not explicitly measure or bound cross-module interactions such as maintenance-induced changes to retrieval routing. In the revised manuscript we will expand the framework section with a short discussion of potential feedback loops, cite any indirect evidence from the existing ablations (e.g., cases where maintenance updates produced only marginal shifts in retrieval metrics), and add a caveat that strong interactions in untested regimes could limit the generalizability of the per-module conclusions. revision: yes
Circularity Check
No circularity: purely empirical benchmarking with no derivations or self-referential predictions
full rationale
The paper is an experimental benchmarking study that decomposes agent memory into four modules, evaluates 12 existing systems on 5 workloads across 11 datasets, and reports observed performance trade-offs. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described methodology. Conclusions follow directly from the reported end-to-end and ablation results rather than reducing to any quantity defined by the paper's own inputs. This matches the default case of a self-contained empirical analysis with no circular steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- Selection of the 12 memory systems
- Selection of the 5 workloads and 11 datasets
axioms (1)
- domain assumption The four modules (representation/storage, extraction, retrieval/routing, maintenance) form a complete and non-overlapping decomposition of agent memory functionality.
Reference graph
Works this paper leans on
-
[1]
https://www.claude.com/product/claude-code
Claude Code.(Anthropic). https://www.claude.com/product/claude-code
-
[2]
Anthropic Engineering. 2025. Effective context engineering for AI agents. https:// www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
2025
-
[3]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. InACL (1). Association for Computational Linguistics, 3119– 3137
2024
-
[4]
Liana Caminal et al. 2025. Filtered Vector Search: State-of-the-art and Research Opportunities. InProceedings of the VLDB Endowment, Vol. 18. 5488–5491
2025
-
[5]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav
-
[6]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.arXiv preprint arXiv:2504.19413(2025)
Pith/arXiv arXiv 2025
-
[7]
Pengfei Du. 2026. Memory for Autonomous LLM Agents: Mechanisms, Evalua- tion, and Emerging Frontiers.arXiv preprint arXiv:2603.07670(2026)
arXiv 2026
-
[8]
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang
-
[9]
LightMem: Lightweight and Efficient Memory-Augmented Generation
LightMem: Lightweight and Efficient Memory-Augmented Generation. CoRRabs/2510.18866 (2025). arXiv:2510.18866 doi:10.48550/ARXIV.2510.18866
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.18866 2025
-
[10]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Qianyu Guo, Meng Wang, and Haofen Wang. 2023. Retrieval-Augmented Generation for Large Language Models: A Survey.CoRR abs/2312.10997 (2023)
Pith/arXiv arXiv 2023
-
[11]
Google. 2025. Memory – Agent Development Kit (ADK). https://google.github. io/adk-docs/sessions/memory/
2025
-
[12]
Yifan Hu, Siyin Liu, Yifei Yue, Guoqiang Zhang, Benyou Liu, Fengbin Zhu, Jingkuan Lin, et al . 2025. Memory in the Age of AI Agents.arXiv preprint arXiv:2512.13564(2025)
Pith/arXiv arXiv 2025
-
[13]
Guozhang Kang, Zhenying Ge, Jie Hu, Xinyuan Zhang, Li Wang, and Jianfeng Zhan. 2025. BigVectorBench: Heterogeneous Data Embedding and Compound Queries are Essential in Evaluating Vector Databases.Proceedings of the VLDB Endowment18, 6 (2025), 1536–1549
2025
-
[14]
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. 2025. Memory OS of AI Agent. InEMNLP. Association for Computational Linguistics, 25961–25970
2025
-
[15]
Arijit Khan, Yuyu Luo, Wenjie Zhang, Mingjie Zhou, and Xiaofang Zhou. 2025. Retrieval-augmented Generation (RAG): What is There for Data Management Researchers?ACM SIGMOD Record54, 4 (2025)
2025
-
[16]
Guoliang Li, Xuanhe Zhou, and Xinyang Zhao. 2024. LLM for Data Management. Proc. VLDB Endow.17, 12 (2024), 4213–4216
2024
-
[17]
Zhiyu Li, Shichao Song, Chenyang Xi, Hanyu Wang, Chen Tang, Simin Niu, Ding Chen, Jiawei Yang, Chunyu Li, Qingchen Yu, Jihao Zhao, Yezhaohui Wang, Peng Liu, Zehao Lin, Pengyuan Wang, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhen Tao, Junpeng Ren, Huayi Lai, Hao Wu, Bo Tang, Zhenren Wang, Zhaoxin Fan, Ningyu Zhang, Linfeng Zhang, Junchi Yan, Mingchuan...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.03724 2025
-
[18]
Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. 2026. SimpleMem: Efficient Lifelong Memory for LLM Agents.CoRRabs/2601.02553 (2026)
Pith/arXiv arXiv 2026
-
[19]
Gonzalez, and Aditya G
Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Stoica, Matei Zaharia, Alvin Cheung, Natacha Crooks, Joseph E. Gonzalez, and Aditya G. Parameswaran. 2026. Supporting Our AI Overlords: Redesigning Data Systems to be Agent-First. InProceedings of the 16th Annual Conference ...
2026
-
[20]
Junru Lu, Siyu An, Mingbao Lin, Gabriele Pergola, Yulan He, Di Yin, Xing Sun, and Yunsheng Wu. 2023. MemoChat: Tuning LLMs to Use Memos for Con- sistent Long-Range Open-Domain Conversation.CoRRabs/2308.08239 (2023). arXiv:2308.08239 doi:10.48550/ARXIV.2308.08239
-
[21]
Yuyu Luo, Guoliang Li, Ju Fan, and Nan Tang. 2026. Data Agents: Levels, State of the Art, and Open Problems.arXiv preprint arXiv:2602.04261(2026). SIGMOD 2026 Tutorial
arXiv 2026
-
[22]
Adyasha Maharana, Dong-Ho Lee, Sergey Turishcheva, Kezhen Nham, Golnaz Jandaghi, Jay Pujara, and Xiang Ren. 2024. Evaluating Very Long-Term Conver- sational Memory of LLM Agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
2024
-
[23]
Vasilije Markovic, Lazar Obradovic, László Hajdu, and Jovan Pavlovic. 2025. Optimizing the Interface Between Knowledge Graphs and LLMs for Complex Reasoning.CoRRabs/2505.24478 (2025)
arXiv 2025
-
[24]
MemoryAgentBench Team. 2026. Evaluating Memory in LLM Agents via In- cremental Multi-Turn Interactions. InFourteenth International Conference on Learning Representations (ICLR)
2026
-
[25]
Microsoft. 2025. Introducing Copilot Memory: A More Productive and Person- alized AI. https://techcommunity.microsoft.com/blog/microsoft365copilotblog/ introducing-copilot-memory
2025
-
[26]
OpenAI. 2026. Context Engineering for Personalization – State Management with Long-Term Memory Notes using OpenAI Agents SDK. https://developers. openai.com/cookbook/examples/agents_sdk/context_personalization/
2026
-
[27]
Patil, Kevin Lin, Sarah Wooders, and Joseph E
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. 2023. MemGPT: Towards LLMs as Operating Systems.arXiv preprint arXiv:2310.08560(2023)
Pith/arXiv arXiv 2023
-
[28]
Preston Rasmussen, Pavel Paliychuk, Travis Beauvais, and Jesse Ryan. 2025. Zep: A Temporal Knowledge Graph Architecture for Agent Memory.arXiv preprint arXiv:2501.13956(2025)
Pith/arXiv arXiv 2025
-
[29]
Alireza Rezazadeh, Zichao Li, Wei Wei, and Yujia Bao. 2025. From Isolated Conversations to Hierarchical Schemas: Dynamic Tree Memory Representation for LLMs. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net. https://openreview.net/ forum?id=moXtEmCleY
2025
-
[30]
Harmanpreet Singh, Nikhil Verma, Yixiao Wang, Manasa Bharadwaj, Homa Fashandi, Kevin Ferreira, and Chul Lee. 2024. Personal Large Language Model Agents: A Case Study on Tailored Travel Planning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. Association for Computational Linguistics, Miami, Florid...
2024
-
[31]
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong
-
[32]
InACL (Findings) (Findings of ACL)
MemBench: Towards More Comprehensive Evaluation on the Memory of LLM-based Agents. InACL (Findings) (Findings of ACL). Association for Compu- tational Linguistics, 19336–19352
-
[33]
Zhiwei Tang et al. 2026. LLM Agent Memory: A Survey from a Unified Repre- sentation.arXiv preprint arXiv:2603.0359(2026)
arXiv 2026
-
[34]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, and Kai-Wei Chang. 2024. LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory. arXiv preprint arXiv:2410.10813(2024)
Pith/arXiv arXiv 2024
-
[35]
Yanchen Wu, Tenghui Lin, Yingli Zhou, Fangyuan Zhang, Qintian Guo, Xun Zhou, Sibo Wang, Xilin Liu, Yuchi Ma, and Yixiang Fang. 2026. Memory in the LLM Era: Modular Architectures and Strategies in a Unified Framework. Proceedings of the VLDB Endowment(2026)
2026
-
[36]
Wujiang Xu et al. 2025. A-MEM: Agentic Memory for LLM Agents.arXiv preprint arXiv:2502.12110(2025)
Pith/arXiv arXiv 2025
-
[37]
Chao Yang, Chuan Zhou, Yanghua Xiao, Shuai Dong, Liang Zhuang, et al. 2026. Graph-based Agent Memory: Taxonomy, Techniques, and Applications.arXiv preprint arXiv:2602.05665(2026)
arXiv 2026
-
[38]
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. 2025. MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent.CoRRabs/2507.02259 (2025)
Pith/arXiv arXiv 2025
-
[39]
Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2025. A Survey on the Memory Mechanism of Large Language Model based Agents.ACM Transactions on Information Systems (2025)
2025
-
[40]
Junhao Zheng, Xidi Cai, Qiuke Li, Duzhen Zhang, Zhong-Zhi Li, Yingying Zhang, Le Song, and Qianli Ma. 2025. LifelongAgentBench: Evaluating LLM Agents as Lifelong Learners.CoRRabs/2505.11942 (2025)
arXiv 2025
-
[41]
Junhao Zheng, Chengming Shi, Xidi Cai, Qiuke Li, Duzhen Zhang, Chenxing Li, Dong Yu, and Qianli Ma. 2025. Lifelong Learning of Large Language Model based Agents: A Roadmap.IEEE Transactions on Pattern Analysis and Machine Intelligence(2025)
2025
-
[42]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2024. Mem- oryBank: Enhancing Large Language Models with Long-Term Memory. InAAAI. AAAI Press, 19724–19731
2024
-
[43]
Wei Zhou, Xuanhe Zhou, Qikang He, Guoliang Li, Bingsheng He, Quanqing Xu, and Fan Wu. 2026. Automating Database-Native Function Code Synthesis with LLMs.Proc. ACM Manag. Data3, 4 (2026), 141:1–141:26
2026
-
[44]
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. 2025. MEM1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents.CoRR abs/2506.15841 (2025). 14
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.