Vision-Language Model Reasoning for Contextual Semantic Mapping in Intralogistics
Pith reviewed 2026-07-01 06:43 UTC · model grok-4.3
The pith
Vision-language models enable zero-shot contextual semantic mapping for intralogistics robots by aggregating multi-view reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
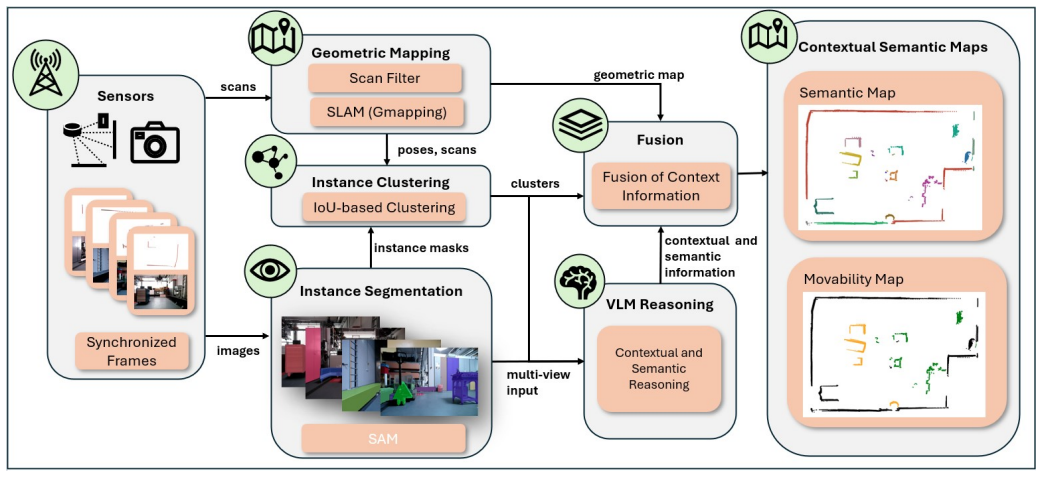
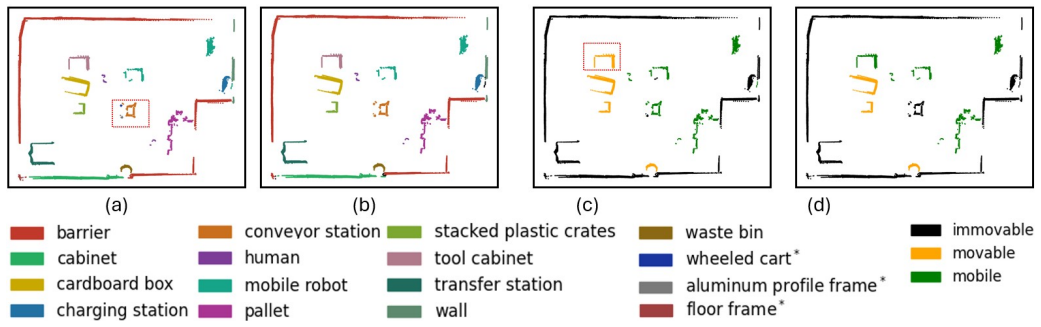
The proposed pipeline combines geometric mapping with multi-view VLM reasoning to produce contextual semantic maps encoding structure, class, and movability, achieving 98.93% mIoU for semantic classification and 89.17% mAcc for movability estimation in a zero-shot manner.
What carries the argument
The contextual semantic mapping pipeline that uses VLM multi-view reasoning to infer object movability from aggregated observations.
If this is right
- The resulting map supports context-aware filtering and robust navigation in dynamic environments.
- VLM reasoning is identified as the primary bottleneck for contextual understanding.
- Instance clustering limits panoptic performance.
- Three VLMs and two prompting strategies were evaluated for performance.
Where Pith is reading between the lines
- This method could extend to inferring other contextual properties like fragility or stackability without additional training.
- Integration with existing robot navigation systems might improve obstacle avoidance in warehouses.
- The approach may generalize to other indoor environments beyond intralogistics.
Load-bearing premise
The test environments and object instances represent real intralogistics variability, and VLM outputs can be reliably parsed into movability labels without calibration.
What would settle it
Evaluating the pipeline on a new set of intralogistics scenes with previously unseen objects and measuring if mAcc for movability drops below 80%.
Figures


read the original abstract
Autonomous mobile robots operating in intralogistics environments rely on geometric maps for localization and navigation, but lack semantic understanding of objects and their contextual properties. We present a contextual semantic mapping pipeline that combines SLAM-based geometric mapping, SAM-based instance segmentation, instance clustering, and VLM multi-view reasoning to produce a contextual semantic map representation encoding geometric structure, object class, and object movability. By aggregating observations across multiple viewpoints and querying a VLM in a zero-shot, open-vocabulary setting, the pipeline infers contextual object properties--here demonstrated through movability--without requiring task-specific training or predefined object categories. We evaluate three VLMs under two prompting strategies and conduct a component-wise analysis of the pipeline. The proposed pipeline achieves 98.93 % mIoU for semantic classification and 89.17 % mAcc for object movability estimation. Component analysis identifies VLM reasoning as the primary bottleneck for contextual understanding and instance clustering as the main limitation for panoptic performance. The resulting semantic map supports context-aware filtering and robust navigation in dynamic intralogistics environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a contextual semantic mapping pipeline for intralogistics robots that integrates SLAM-based geometric mapping, SAM instance segmentation, instance clustering, and zero-shot open-vocabulary VLM multi-view reasoning to produce maps encoding geometry, object class, and movability. It evaluates three VLMs under two prompting strategies, reports aggregate performance of 98.93% mIoU on semantic classification and 89.17% mAcc on movability estimation, and uses component analysis to identify VLM reasoning as the primary bottleneck and instance clustering as the main limit on panoptic quality.
Significance. If the reported metrics prove robust, the work offers a concrete demonstration that multi-view VLM aggregation can supply task-relevant contextual properties (movability) to geometric maps without task-specific training or closed vocabularies. The explicit component-wise breakdown is a strength that helps isolate where future improvements should focus, and the zero-shot open-vocabulary framing aligns with practical needs in variable intralogistics scenes.
major comments (2)
- [Evaluation / Results] The central empirical claims rest on headline metrics (98.93% mIoU, 89.17% mAcc) that are presented without error bars, without stating the number of scenes or object instances in the test set, and without describing how ground-truth movability labels were acquired. These omissions directly affect the ability to judge whether the numbers support the claim of reliable contextual mapping.
- [Evaluation / Results] The evaluation assumes that the selected intralogistics scenes and objects are representative of real-world variability in layout, lighting, occlusion, and object types, yet no quantitative characterization of test-set diversity or failure-mode breakdown by scene property is provided. Without this, the generalization argument for zero-shot deployment remains unanchored.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation and results section. We address each major comment below and will revise the manuscript accordingly to improve clarity and support for the reported claims.
read point-by-point responses
-
Referee: [Evaluation / Results] The central empirical claims rest on headline metrics (98.93% mIoU, 89.17% mAcc) that are presented without error bars, without stating the number of scenes or object instances in the test set, and without describing how ground-truth movability labels were acquired. These omissions directly affect the ability to judge whether the numbers support the claim of reliable contextual mapping.
Authors: We agree that these details are necessary for proper assessment of the results. The revised manuscript will include error bars (standard deviation across scenes), explicitly report the number of scenes and object instances in the evaluation set, and describe the ground-truth acquisition process for movability labels, which was performed via expert manual annotation following a defined protocol. revision: yes
-
Referee: [Evaluation / Results] The evaluation assumes that the selected intralogistics scenes and objects are representative of real-world variability in layout, lighting, occlusion, and object types, yet no quantitative characterization of test-set diversity or failure-mode breakdown by scene property is provided. Without this, the generalization argument for zero-shot deployment remains unanchored.
Authors: We acknowledge this limitation in the current presentation. The revision will add a quantitative characterization of test-set diversity (e.g., distributions over layout types, lighting conditions, occlusion levels, and object categories) along with a failure-mode analysis broken down by these scene properties to better anchor the generalization discussion. revision: yes
Circularity Check
No circularity; central results are empirical measurements on held-out data
full rationale
The paper describes a pipeline that aggregates existing components (SLAM, SAM segmentation, instance clustering, and zero-shot VLM queries) and reports performance via direct evaluation on test scenes (98.93% mIoU, 89.17% mAcc). These are measured quantities on held-out environments rather than quantities obtained by fitting parameters inside the paper's equations or by reducing a claimed derivation to its own inputs. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain. The method is self-contained against external benchmarks because success is defined by observable agreement with ground-truth labels on separate data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SAM instance segmentation produces masks that correspond to distinct physical objects in the scene
- domain assumption VLM responses can be deterministically parsed into object class and movability labels
Reference graph
Works this paper leans on
-
[1]
Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age,
C. Cadena, L. Carlone, H. Carrillo, Y . Latif, D. Scaramuzza, J. Neira, I. Reid, and J. J. Leonard, “Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age,”IEEE Transactions on Robotics, vol. 32, no. 6, pp. 1309–1332, 2016
2016
-
[2]
3D scene graph: A structure for unified semantics, 3D space, and camera,
I. Armeni, Z.-Y . He, A. Zamir, J. Gwak, J. Malik, M. Fischer, and S. Savarese, “3D scene graph: A structure for unified semantics, 3D space, and camera,” in2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 2019, pp. 5663–5672
2019
-
[3]
MultiMap3D: A multi-level semantic perceptual map construction based on SLAM and point cloud detection,
J. Zhou, A. Elksnis, Z. Fu, B. Chen, and C. Yang, “MultiMap3D: A multi-level semantic perceptual map construction based on SLAM and point cloud detection,” in2023 28th International Conference on Automation and Computing (ICAC). Birmingham, United Kingdom: IEEE, 2023, pp. 1–6
2023
-
[4]
A real-time semantic map production system for indoor robot naviga- tion,
R. Alqobali, R. Alnasser, A. Rashidi, M. Alshmrani, and T. Alhmiedat, “A real-time semantic map production system for indoor robot naviga- tion,”Sensors, vol. 24, no. 20, p. 6691, 2024
2024
-
[5]
Review of autonomous mobile robots in intralogistics: state-of-the-art, limitations and research gaps,
T. Lackner, J. Hermann, C. Kuhn, and D. Palm, “Review of autonomous mobile robots in intralogistics: state-of-the-art, limitations and research gaps,”Procedia CIRP, vol. 130, pp. 930–935, 2024
2024
-
[6]
Extending maps with semantic and contextual object information for robot navigation: A learning-based framework using visual and depth cues,
R. Martins, D. Bersan, M. F. M. Campos, and E. R. Nascimento, “Extending maps with semantic and contextual object information for robot navigation: A learning-based framework using visual and depth cues,”Journal of Intelligent & Robotic Systems, vol. 99, pp. 555–569, 2020
2020
-
[7]
Monocular camera and laser based semantic mapping system with temporal-spatial data as- sociation for indoor mobile robots,
X. Song, Z. Zhijiang, X. Liang, and Z. Huaidong, “Monocular camera and laser based semantic mapping system with temporal-spatial data as- sociation for indoor mobile robots,”Multimedia Tools and Applications, vol. 82, no. 22, pp. 34 459–34 484, 2023
2023
-
[8]
Open-vocabulary queryable scene represen- tations for real world planning,
B. Chen, F. Xia, B. Ichter, K. Rao, K. Gopalakrishnan, M. S. Ryoo, A. Stone, and D. Kappler, “Open-vocabulary queryable scene represen- tations for real world planning,” in2023 IEEE International Conference on Robotics and Automation (ICRA), London, United Kingdom, 2023, pp. 11 509–11 522
2023
-
[9]
Visual language maps for robot navigation,
C. Huang, O. Mees, A. Zeng, and W. Burgard, “Visual language maps for robot navigation,” in2023 IEEE International Conference on Robotics and Automation (ICRA). London, United Kingdom: IEEE, 2023, pp. 10 608–10 615
2023
-
[10]
Scene understanding: A survey to see the world at a single glance,
P. G. Pawar and V . Devendran, “Scene understanding: A survey to see the world at a single glance,” in2019 2nd International Conference on Intelligent Communication and Computational Techniques (ICCT). Jaipur, India: IEEE, 2019, pp. 182–186
2019
-
[11]
Structured generative models for scene understand- ing,
C. K. I. Williams, “Structured generative models for scene understand- ing,”International Journal of Computer Vision, vol. 133, no. 5, pp. 2845–2867, 2025
2025
-
[12]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,”Proceedings of the 38th International Conference on Machine Learning, vol. 139, pp. 8748–8763, 2021
2021
-
[13]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll´ar, and R. Girshick, “Segment anything,” 2023, arXiv preprint arXiv:2304.02643
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
S. Raychaudhuri and A. X. Chang, “Semantic mapping in indoor embodied AI: A survey on advances, challenges, and future directions,” 2025, arXiv preprint arXiv:2501.05750
-
[15]
Semantic SLAM system for mobile robots based on large visual model in complex environments,
C. Zheng, P. Zhang, and Y . Li, “Semantic SLAM system for mobile robots based on large visual model in complex environments,”Scientific Reports, vol. 15, no. 1, p. 8450, 2025
2025
-
[16]
Open-vocabulary online semantic mapping for SLAM,
T. B. Martins, M. R. Oswald, and J. Civera, “Open-vocabulary online semantic mapping for SLAM,”IEEE Robotics and Automation Letters, vol. 10, no. 11, pp. 11 745–11 752, 2025
2025
-
[17]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, J. Lei, T. Ma, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. R ¨adle, E. Mavroudi, K. Xu, T.-H. Wu, Y . Zhou, L. Momeni, R. Hazra, S. Ding, S. Vaze, F. Porcher, F. Li, S. Li, A. Kamath, H. Kei, P. Doll ´ar, N. Ravi, K. Saenko, P. Zhang, and C....
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection,
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang, “Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection,” inComputer Vision – ECCV 2024, A. Leonardis, E. Ricci, S. Roth, O. Russakovsky, T. Sattler, and G. Varol, Eds. Cham: Springer Nature Switzerland, 2025, vol. 1510...
2024
-
[19]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yan, Z. Zeng, H. Zhang, F. Li, J. Yang, H. Li, Q. Jiang, and L. Zhang, “Grounded SAM: assembling open-world models for diverse visual tasks,” 2024, arXiv preprint arXiv.2401.14159
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Leveraging vision-language models for open-vocabulary instance segmentation and tracking,
B. P ¨atzold, J. Nogga, and S. Behnke, “Leveraging vision-language models for open-vocabulary instance segmentation and tracking,”IEEE Robotics and Automation Letters, vol. 10, no. 11, pp. 11 578 – 11 585, 2025
2025
-
[21]
VISO-Grasp: Vision-language informed spatial object- centric 6-DoF active view planning and grasping in clutter and invisibil- ity,
Y . Shi, D. Wen, G. Chen, E. Welte, S. Liu, K. Peng, R. Stiefelhagen, and R. Rayyes, “VISO-Grasp: Vision-language informed spatial object- centric 6-DoF active view planning and grasping in clutter and invisibil- ity,” in2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Hangzhou, China: IEEE, 2025, pp. 14 931–14 938
2025
-
[22]
SegmATRon: Embodied adaptive semantic segmentation for indoor environment,
T. Zemskova, M. Kichik, D. Yudin, A. Staroverov, and A. Panov, “SegmATRon: Embodied adaptive semantic segmentation for indoor environment,”Neurocomputing, vol. 638, p. 130169, 2025
2025
-
[23]
VisionLLM: Large language model is also an open-ended decoder for vision-centric tasks,
W. Wang, Z. Chen, X. Chen, J. Wu, X. Zhu, G. Zeng, P. Luo, T. Lu, J. Zhou, Y . Qiao, and J. Dai, “VisionLLM: Large language model is also an open-ended decoder for vision-centric tasks,” inAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, Eds., vol. 36. Curran Associates, Inc., 2023, pp...
2023
-
[24]
SpatialRGPT: Grounded spatial reasoning in vision-language models,
A.-C. Cheng, H. Yin, Y . Fu, Q. Guo, R. Yang, J. Kautz, X. Wang, and S. Liu, “SpatialRGPT: Grounded spatial reasoning in vision-language models,”38th Conference on Neural Information Processing Systems, pp. 135 062 – 135 093, 2024
2024
-
[25]
Real-time indoor object SLAM with LLM-enhanced priors,
Y . Jiao, Y . Qiu, and H. I. Christensen, “Real-time indoor object SLAM with LLM-enhanced priors,” 2025, arXiv preprint arXiv:2509.21602
-
[26]
LLM-guided zero- shot visual object navigation with building semantic map,
J. Shi, S. Yagi, S. Yamamori, and J. Morimoto, “LLM-guided zero- shot visual object navigation with building semantic map,” in2025 IEEE/SICE International Symposium on System Integration (SII), Mu- nich, Germany, 2025, pp. 1274–1279
2025
-
[27]
Relationship-aware hierarchical 3D scene graph for task reasoning,
A. G. Puigjaner, A. Zacharia, and K. Alexis, “Relationship-aware hierarchical 3D scene graph for task reasoning,” 2026, arXiv preprint arXiv:2602.02456
-
[28]
DSM: Constructing a diverse semantic map for 3D visual grounding,
Q. Xie, Z. Liang, F. Li, and L. Zeng, “DSM: Constructing a diverse semantic map for 3D visual grounding,”IEEE Robotics and Automation Letters, vol. 11, no. 5, pp. 6344–6351, 2026
2026
-
[29]
osmAG-LLM: Zero-shot open- vocabulary object navigation via semantic maps and large language models reasoning,
F. Xie, S. Schwertfeger, and H. Blum, “osmAG-LLM: Zero-shot open- vocabulary object navigation via semantic maps and large language models reasoning,”IEEE Robotics and Automation Letters, vol. 11, no. 3, pp. 2426–2433, 2026
2026
-
[30]
MetaScenes: Towards automated replica cre- ation for real-world 3D scans,
H. Yu, B. Jia, Y . Chen, Y . Yang, P. Li, R. Su, J. Li, Q. Li, W. Liang, S.-C. Zhu, T. Liu, and S. Huang, “MetaScenes: Towards automated replica cre- ation for real-world 3D scans,” 2025, arXiv preprint arXiv:2505.02388
-
[31]
Agentic workflows for improving large language model reasoning in robotic object-centered planning,
J. Moncada-Ramirez, J.-L. Matez-Bandera, J. Gonzalez-Jimenez, and J.-R. Ruiz-Sarmiento, “Agentic workflows for improving large language model reasoning in robotic object-centered planning,”Robotics, vol. 14, no. 3, p. 24, 2025
2025
-
[32]
The future of MLLM prompting is adaptive: a comprehensive experimental evaluation of prompt engineering methods for robust multimodal performance,
A. Mohanty, V . B. Parthasarathy, and A. Shahid, “The future of MLLM prompting is adaptive: a comprehensive experimental evaluation of prompt engineering methods for robust multimodal performance,” Transactions on Machine Learning Research, 2025
2025
-
[33]
Panoptic segmentation,
A. Kirillov, K. He, R. Girshick, C. Rother, and P. Doll ´ar, “Panoptic segmentation,” in2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach, CA, USA: IEEE, 2019, pp. 9396–9405
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.