No 3D Matrices: A Unified Tensor-Product View of Matrix-Free Cartesian PDE Solvers
Pith reviewed 2026-06-25 22:33 UTC · model grok-4.3
The pith
Cartesian three-dimensional PDE operators factor exactly into one-dimensional line solves along each axis and are never assembled or stored.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
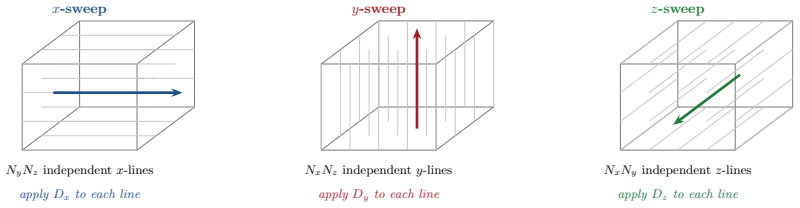
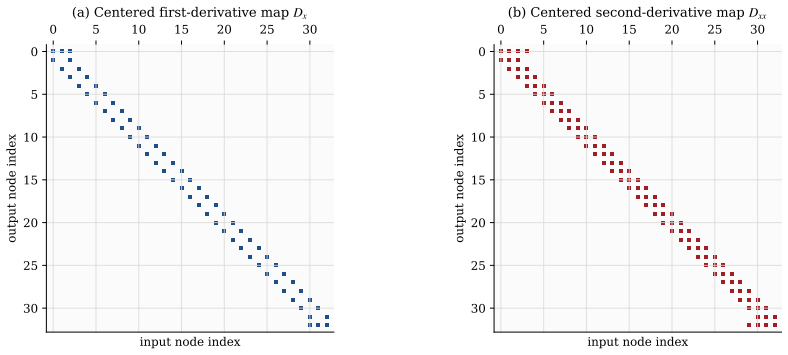
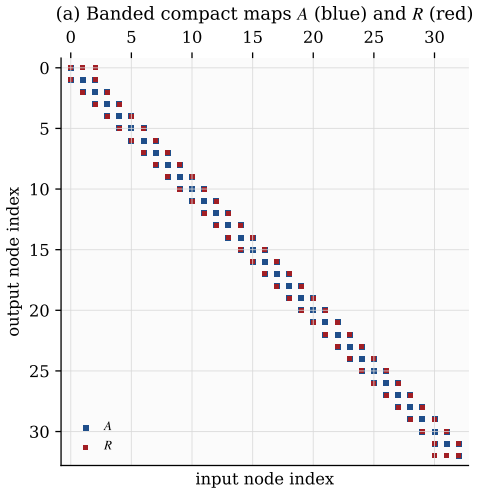
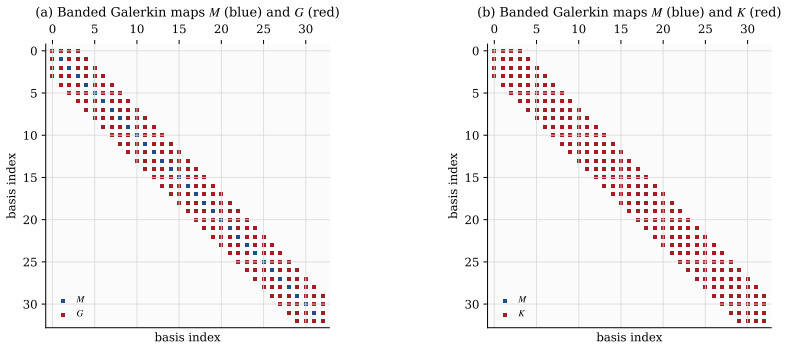
Every Cartesian three-dimensional PDE solver hides a structural secret: the derivative matrices, compact Padé line solves, Galerkin mass inversions, alternating-direction-implicit substeps, and fast Poisson and Helmholtz diagonalization transforms all factor along the coordinate axes and collapse into repeated one-dimensional banded kernels executed along the grid lines. The three-dimensional operator exists only on paper; it is never assembled, factored, or stored.
What carries the argument
The Kronecker-product algebra that makes the exact factorization of multi-dimensional operators into independent one-dimensional factors along each coordinate axis.
If this is right
- For fixed stencil width or polynomial degree, compute cost stays O(N) in the total number of unknowns N = Nx Ny Nz.
- Operator storage drops to O(Nx + Ny + Nz) up to bandwidth constants.
- Direct separable Poisson and Helmholtz solvers add only the expected transform cost.
- The line kernels are embarrassingly parallel.
- The multi-right-hand-side reshape exposes sweeps as batched line kernels, and sum factorization keeps high-order Galerkin costs linear.
Where Pith is reading between the lines
- The same algebraic reduction supplies a single organizing principle that explains why several otherwise unrelated numerical techniques all achieve the same scaling.
- Implementations can therefore allocate all optimization effort to one-dimensional kernels and their batched execution rather than to three-dimensional data layouts.
- The approach suggests a template for constructing new separable discretizations by first designing the one-dimensional factors and then lifting them via Kronecker products.
Load-bearing premise
The PDE discretization must be posed on a Cartesian product grid so that every operator factors exactly into independent one-dimensional factors along each coordinate axis.
What would settle it
Demonstrating a standard discretization of a Cartesian PDE whose three-dimensional operator cannot be expressed as a product of one-dimensional operators along the axes, or measuring a computational cost that scales worse than linear in the total number of grid points.
Figures

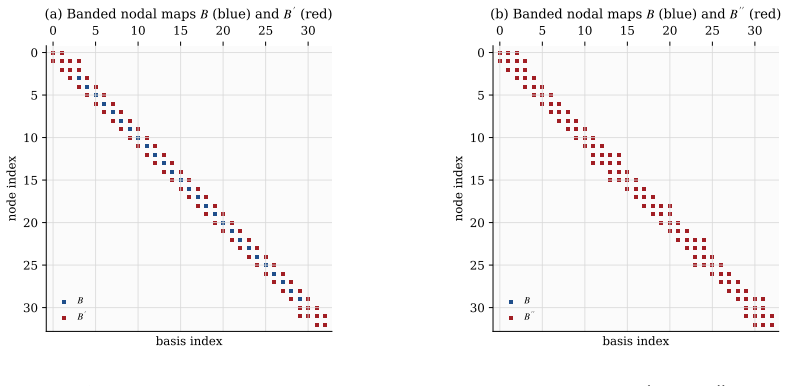
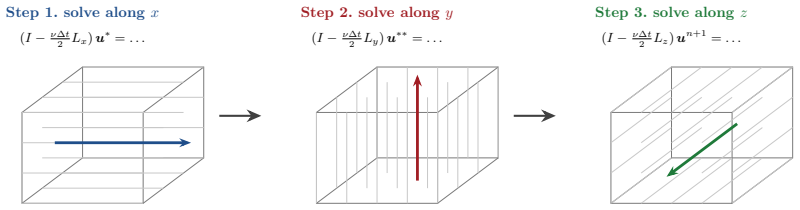
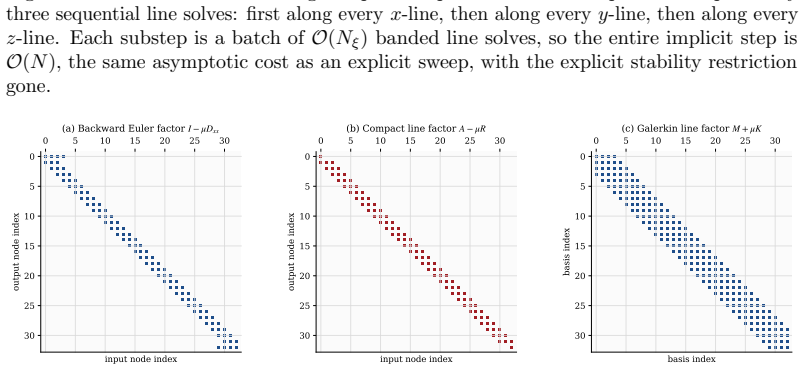

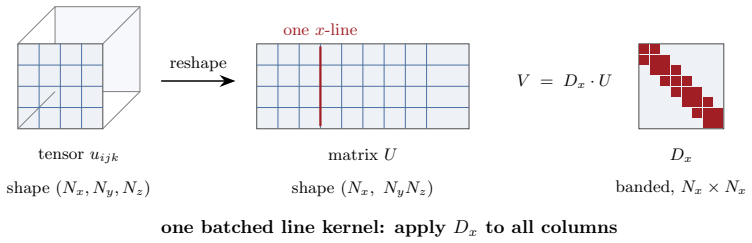
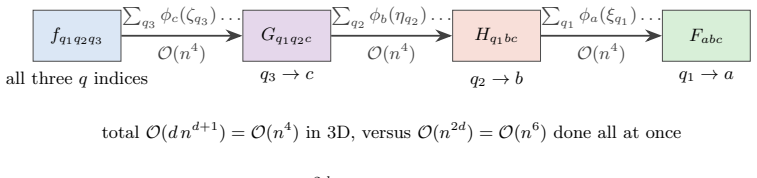
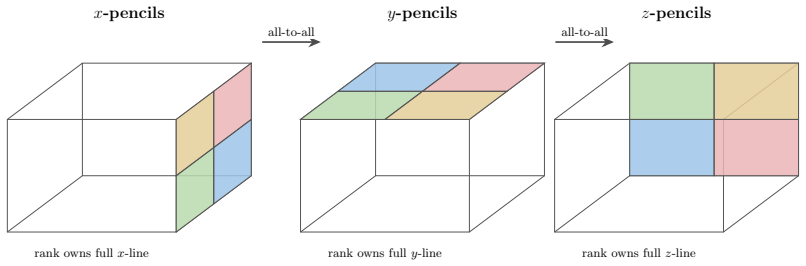
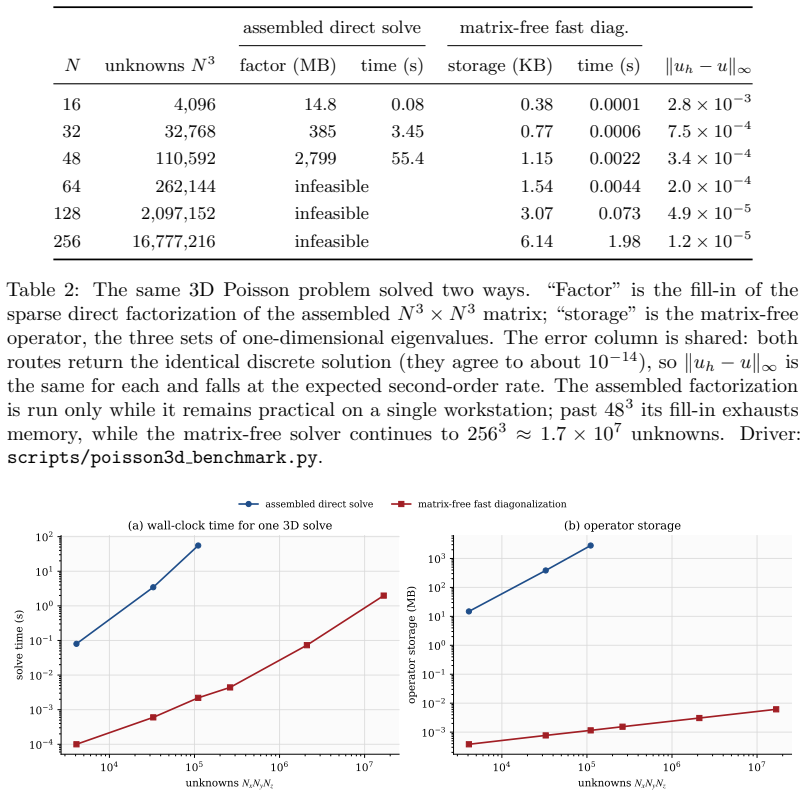
read the original abstract
Every Cartesian three-dimensional PDE solver hides a structural secret that production CFD codes have used for half a century and that graduate-level textbooks rarely state plainly. The derivative matrices, the compact Pad\'e line solves, the Galerkin mass inversions, the alternating-direction-implicit substeps, and even the fast Poisson and Helmholtz diagonalization transforms all factor along the coordinate axes and collapse into repeated one-dimensional banded kernels executed along the grid lines. The three-dimensional operator exists only on paper; it is never assembled, factored, or stored. This paper is the manual for that collapse. We derive the Kronecker-product algebra that makes it exact, carry it cleanly through central differences, compact schemes, tensor-product Galerkin, B-spline and isogeometric methods, collocation, ADI time stepping, and direct Poisson and Helmholtz solves, and bring into the open the three production tricks that turn the reduction into hardware-conscious floating-point throughput on real machines: the multi-right-hand-side reshape that exposes a sweep as one batched line kernel (a dense BLAS-3 GEMM when the line factor is dense or element-local, a banded or stencil kernel when it is not), the sum factorization that rescues high-order Galerkin from the $O(p^{2d})$ quadrature trap, and the pencil decomposition that keeps every direction contiguous across an MPI cluster. For fixed stencil width or fixed polynomial degree, the compute cost stays $O(N)$ in the total number of unknowns $N = N_x N_y N_z$; the operator storage drops to $O(N_x + N_y + N_z)$ up to bandwidth constants; direct separable Poisson and Helmholtz solvers add the expected transform cost; the line kernels are embarrassingly parallel. These facts are familiar to practitioners but rarely assembled in one place; this paper collects them and shows how to use them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that every three-dimensional Cartesian PDE solver on a product grid factors exactly via Kronecker products into repeated one-dimensional banded or stencil kernels executed along coordinate lines, so that the full 3D operator is never assembled, factored, or stored. It derives the relevant algebra for central differences, compact Padé schemes, tensor-product Galerkin and isogeometric methods, collocation, ADI time stepping, and separable Poisson/Helmholtz solvers, then details three implementation devices (multi-RHS reshape to batched line kernels, sum factorization, and pencil decomposition) that realize O(N) work and O(Nx+Ny+Nz) storage with embarrassingly parallel line sweeps.
Significance. If the algebraic reductions hold, the paper supplies a single, explicit reference that assembles a body of established but scattered practitioner knowledge. Its value lies in the clean Kronecker derivations, the explicit treatment of the three performance tricks, and the consistent emphasis on matrix-free execution; these elements can shorten the path from textbook discretization to hardware-efficient code. The work is not presented as containing new theorems but as a unifying manual, which is a legitimate and useful contribution when executed with the care shown in the abstract.
minor comments (2)
- [Abstract] Abstract, final paragraph: the sentence listing the three production tricks would be clearer if the tricks were enumerated (1. multi-RHS reshape, 2. sum factorization, 3. pencil decomposition) rather than described in a single clause.
- [Introduction] The manuscript should include a short table or diagram in the introduction that maps each listed method (central differences, compact schemes, ADI, etc.) to the corresponding Kronecker identity or section number where its factorization is derived.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation to accept the manuscript. The referee's summary correctly identifies the paper's purpose as a unifying reference that assembles the Kronecker-product reductions and implementation devices for matrix-free Cartesian solvers.
Circularity Check
No significant circularity identified
full rationale
The paper presents a unified view of matrix-free Cartesian PDE solvers by invoking the standard Kronecker-product factorization of separable operators on product grids. This is an external algebraic fact (not derived or fitted within the paper) that applies by definition to the listed methods (central differences, compact schemes, tensor-product Galerkin, ADI, separable Poisson solvers). The work explicitly frames itself as collecting established techniques rather than proving new results or introducing self-referential definitions, fitted parameters called predictions, or load-bearing self-citations. No equations or steps reduce the central claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Kronecker product algebra permits exact factorization of separable multidimensional operators into repeated one-dimensional kernels
Reference graph
Works this paper leans on
-
[1]
Journal of Computational Physics , volume=
Compact finite difference schemes with spectral-like resolution , author=. Journal of Computational Physics , volume=. 1992 , publisher=
1992
-
[2]
Journal of the Society for Industrial and Applied Mathematics , volume=
The numerical solution of parabolic and elliptic differential equations , author=. Journal of the Society for Industrial and Applied Mathematics , volume=. 1955 , publisher=
1955
-
[3]
Numerische Mathematik , volume=
Alternating direction methods for three space variables , author=. Numerische Mathematik , volume=. 1962 , publisher=
1962
-
[4]
Numerische Mathematik , volume=
A general formulation of alternating direction methods , author=. Numerische Mathematik , volume=. 1964 , publisher=
1964
-
[5]
Numerische Mathematik , volume=
Direct solution of partial difference equations by tensor product methods , author=. Numerische Mathematik , volume=. 1964 , publisher=
1964
-
[6]
The accurate solution of
Haidvogel, Dale B and Zang, Thomas , journal=. The accurate solution of. 1979 , publisher=
1979
-
[7]
2013 , publisher=
Matrix Computations , author=. 2013 , publisher=
2013
-
[8]
The ubiquitous
Van Loan, Charles F , journal=. The ubiquitous. 2000 , publisher=
2000
-
[9]
2007 , publisher=
Computational Science and Engineering , author=. 2007 , publisher=
2007
-
[10]
2009 , publisher=
Tensor decompositions and applications , author=. 2009 , publisher=
2009
-
[11]
Application of a fractional-step method to incompressible
Kim, John and Moin, Parviz , journal=. Application of a fractional-step method to incompressible. 1985 , publisher=
1985
-
[12]
Journal of Computational Physics , volume=
An implicit finite-difference algorithm for hyperbolic systems in conservation-law form , author=. Journal of Computational Physics , volume=. 1976 , publisher=
1976
-
[13]
Mathematics of Computation , volume=
Generation of finite difference formulas on arbitrarily spaced grids , author=. Mathematics of Computation , volume=. 1988 , publisher=
1988
-
[14]
2007 , publisher=
Finite Difference Methods for Ordinary and Partial Differential Equations , author=. 2007 , publisher=
2007
-
[15]
2007 , publisher=
Numerical Computation of Internal and External Flows , author=. 2007 , publisher=
2007
-
[16]
Watson Scientific Computing Laboratory Report , year=
Elliptic problems in linear difference equations over a network , author=. Watson Scientific Computing Laboratory Report , year=
-
[17]
2009 , publisher=
A First Course in the Numerical Analysis of Differential Equations , author=. 2009 , publisher=
2009
-
[18]
Costa, Pedro , journal=. A. 2018 , publisher=
2018
-
[19]
2001 , publisher=
Bewley, Thomas R and Moin, Parviz and Temam, Roger , journal=. 2001 , publisher=
2001
-
[20]
1978 , publisher=
A Practical Guide to Splines , author=. 1978 , publisher=
1978
-
[21]
An Energy-Conservative Cut-Cell Method and Advanced
Bay, Yong Yi , school=. An Energy-Conservative Cut-Cell Method and Advanced. 2019 , note=
2019
-
[22]
Isogeometric analysis:
Hughes, Thomas JR and Cottrell, John A and Bazilevs, Yuri , journal=. Isogeometric analysis:. 2005 , publisher=
2005
-
[23]
Isogeometric Analysis: Toward Integration of
Cottrell, J Austin and Hughes, Thomas JR and Bazilevs, Yuri , year=. Isogeometric Analysis: Toward Integration of
-
[24]
2002 , publisher=
High-Order Methods for Incompressible Fluid Flow , author=. 2002 , publisher=
2002
-
[25]
Higher order
Johnson, Richard W , journal=. Higher order. 2005 , publisher=
2005
-
[26]
Li, Ning and Laizet, Sylvain , booktitle=
-
[27]
Rolfo, Stefano and Flageul, C. The. Journal of Open Source Software , volume=. 2023 , doi=
2023
-
[28]
, journal=
Frigo, Matteo and Johnson, Steven G. , journal=. The Design and Implementation of. 2005 , doi=
2005
-
[30]
, journal=
Bay, Yong Yi and Yearick, Kathleen A. , journal=. Solve for the Hyperparameter, Skip the Search:. 2026 , eprint=
2026
-
[31]
2DECOMP&FFT : A highly scalable 2d decomposition library and FFT interface
Ning Li and Sylvain Laizet. 2DECOMP&FFT : A highly scalable 2d decomposition library and FFT interface. In Cray User Group 2010 Conference, Edinburgh, United Kingdom, 2010
2010
-
[32]
A Practical Guide to Splines
Carl de Boor. A Practical Guide to Splines. Springer, 1978
1978
-
[33]
Application of a fractional-step method to incompressible N avier-- S tokes equations
John Kim and Parviz Moin. Application of a fractional-step method to incompressible N avier-- S tokes equations. Journal of Computational Physics, 59 0 (2): 0 308--323, 1985
1985
-
[34]
An Energy-Conservative Cut-Cell Method and Advanced B -Spline-Based Filtering Method for Flow Simulation
Yong Yi Bay. An Energy-Conservative Cut-Cell Method and Advanced B -Spline-Based Filtering Method for Flow Simulation . Ph.D. dissertation, University of Illinois at Urbana-Champaign, 2019. https://hdl.handle.net/2142/106215
2019
-
[35]
Yong Yi Bay and Kathleen A. Yearick. Solve for the hyperparameter, skip the search: K olmogorov-optimal scaling laws for spline regression. arXiv preprint arXiv:2606.23575, 2026
Pith/arXiv arXiv 2026
-
[36]
Yong Yi Bay and Kathleen A. Yearick. Machine learning vs deep learning: the generalization problem. arXiv preprint arXiv:2403.01621, 2024
arXiv 2024
-
[37]
The ubiquitous K ronecker product
Charles F Van Loan. The ubiquitous K ronecker product. Journal of Computational and Applied Mathematics, 123 0 (1--2): 0 85--100, 2000
2000
-
[38]
Compact finite difference schemes with spectral-like resolution
Sanjiva K Lele. Compact finite difference schemes with spectral-like resolution. Journal of Computational Physics, 103 0 (1): 0 16--42, 1992
1992
-
[39]
An implicit finite-difference algorithm for hyperbolic systems in conservation-law form
Richard M Beam and Robert F Warming. An implicit finite-difference algorithm for hyperbolic systems in conservation-law form. Journal of Computational Physics, 22 0 (1): 0 87--110, 1976
1976
-
[40]
Matrix Computations
Gene H Golub and Charles F Van Loan. Matrix Computations. Johns Hopkins University Press, 4 edition, 2013
2013
-
[41]
A FFT -based finite-difference solver for massively-parallel direct numerical simulations of turbulent flows
Pedro Costa. A FFT -based finite-difference solver for massively-parallel direct numerical simulations of turbulent flows. Computers & Mathematics with Applications, 76 0 (8): 0 1853--1862, 2018
2018
-
[42]
Matteo Frigo and Steven G. Johnson. The design and implementation of FFTW3 . Proceedings of the IEEE, 93 0 (2): 0 216--231, 2005. doi:10.1109/JPROC.2004.840301
-
[43]
Tensor decompositions and applications
Tamara G Kolda and Brett W Bader. Tensor decompositions and applications. SIAM Review , 51 0 (3): 0 455--500, 2009
2009
-
[44]
Direct solution of partial difference equations by tensor product methods
Robert E Lynch, John R Rice, and David H Thomas. Direct solution of partial difference equations by tensor product methods. Numerische Mathematik, 6 0 (1): 0 185--199, 1964
1964
-
[45]
The 2DECOMP&FFT library: an update with new CPU/GPU capabilities
Stefano Rolfo, C \'e dric Flageul, Paul Bartholomew, Filippo Spiga, and Sylvain Laizet. The 2DECOMP&FFT library: an update with new CPU/GPU capabilities. Journal of Open Source Software, 8 0 (91): 0 5813, 2023. doi:10.21105/joss.05813
-
[46]
DNS -based predictive control of turbulence: an optimal benchmark for feedback algorithms
Thomas R Bewley, Parviz Moin, and Roger Temam. DNS -based predictive control of turbulence: an optimal benchmark for feedback algorithms. Journal of Fluid Mechanics, 447: 0 179--225, 2001
2001
-
[47]
Isogeometric analysis: CAD , finite elements, NURBS , exact geometry and mesh refinement
Thomas JR Hughes, John A Cottrell, and Yuri Bazilevs. Isogeometric analysis: CAD , finite elements, NURBS , exact geometry and mesh refinement. Computer Methods in Applied Mechanics and Engineering, 194 0 (39--41): 0 4135--4195, 2005
2005
-
[48]
Numerical Computation of Internal and External Flows
Charles Hirsch. Numerical Computation of Internal and External Flows. Butterworth-Heinemann, 2 edition, 2007
2007
-
[49]
Computational Science and Engineering
Gilbert Strang. Computational Science and Engineering. Wellesley-Cambridge Press, 2007
2007
-
[50]
Elliptic problems in linear difference equations over a network
Llewellyn H Thomas. Elliptic problems in linear difference equations over a network. Watson Scientific Computing Laboratory Report, 1949
1949
-
[51]
Alternating direction methods for three space variables
Jim Douglas. Alternating direction methods for three space variables. Numerische Mathematik, 4 0 (1): 0 41--63, 1962
1962
-
[52]
A general formulation of alternating direction methods
Jim Douglas, Jr and James E Gunn. A general formulation of alternating direction methods. Numerische Mathematik, 6 0 (1): 0 428--453, 1964
1964
-
[53]
A First Course in the Numerical Analysis of Differential Equations
Arieh Iserles. A First Course in the Numerical Analysis of Differential Equations. Cambridge University Press, 2 edition, 2009
2009
-
[54]
High-Order Methods for Incompressible Fluid Flow
Michel O Deville, Paul F Fischer, and Ernest H Mund. High-Order Methods for Incompressible Fluid Flow. Cambridge University Press, 2002
2002
-
[55]
Higher order B -spline collocation at the G reville abscissae
Richard W Johnson. Higher order B -spline collocation at the G reville abscissae. Applied Numerical Mathematics, 52 0 (1): 0 63--75, 2005
2005
-
[56]
Finite Difference Methods for Ordinary and Partial Differential Equations
Randall J LeVeque. Finite Difference Methods for Ordinary and Partial Differential Equations. SIAM, 2007
2007
-
[57]
Isogeometric Analysis: Toward Integration of CAD and FEA
J Austin Cottrell, Thomas JR Hughes, and Yuri Bazilevs. Isogeometric Analysis: Toward Integration of CAD and FEA . Wiley, 2009
2009
-
[58]
Generation of finite difference formulas on arbitrarily spaced grids
Bengt Fornberg. Generation of finite difference formulas on arbitrarily spaced grids. Mathematics of Computation, 51 0 (184): 0 699--706, 1988
1988
-
[59]
The numerical solution of parabolic and elliptic differential equations
Donald W Peaceman and Henry H Rachford, Jr. The numerical solution of parabolic and elliptic differential equations. Journal of the Society for Industrial and Applied Mathematics, 3 0 (1): 0 28--41, 1955
1955
-
[60]
The accurate solution of P oisson's equation by expansion in C hebyshev polynomials
Dale B Haidvogel and Thomas Zang. The accurate solution of P oisson's equation by expansion in C hebyshev polynomials. Journal of Computational Physics, 30 0 (2): 0 167--180, 1979
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.