Efficient Analytic Uncertainty Quantification for Multi-Modal Regression
Pith reviewed 2026-06-25 23:37 UTC · model grok-4.3
The pith
Quantile regression and classification restoration admit variational Bayesian formulations that produce analytic evidence lower bounds and predictive densities for efficient uncertainty quantification in multi-modal regression tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that novel formulations of quantile regression and classification restoration inside the variational Bayesian inference framework yield analytic evidence lower bounds for training and closed-form or analytically approximated predictive densities for inference, thereby achieving accurate estimation of complex conditional distributions together with highly efficient uncertainty quantification.
What carries the argument
The unified distribution-agnostic variational Bayesian inference framework that reformulates quantile regression and classification restoration to admit analytic ELBOs and predictive densities.
If this is right
- The method outperforms state-of-the-art multi-modal regression baselines on three large-scale benchmarks with multi-modal label distributions.
- Predictive performance matches that of computationally expensive ensemble models.
- Epistemic uncertainty estimates enable highly data-efficient active learning strategies.
Where Pith is reading between the lines
- The same reformulation strategy could be applied to other semi-parametric density estimators that currently lack analytic uncertainty.
- The closed-form predictive densities may reduce the cost of propagating uncertainty through downstream decision pipelines.
- Because the approach is distribution-agnostic, it offers a route to uncertainty quantification in settings where label supports change over time.
Load-bearing premise
Quantile regression and classification restoration can be placed inside variational Bayesian inference so that the resulting evidence lower bounds and predictive densities remain analytic or cheaply approximated without substantial loss of multi-modal fidelity.
What would settle it
On a synthetic multi-modal regression dataset, compare the analytic predictive density against exact Monte Carlo sampling from the true conditional and check whether the total variation distance or negative log-likelihood gap exceeds a threshold that materially changes downstream active-learning performance.
Figures
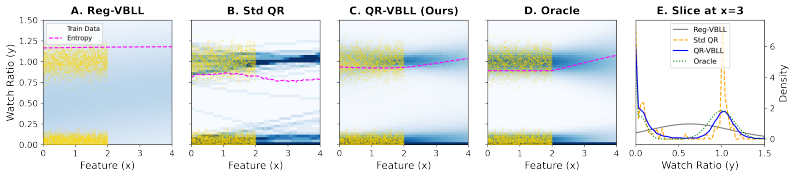




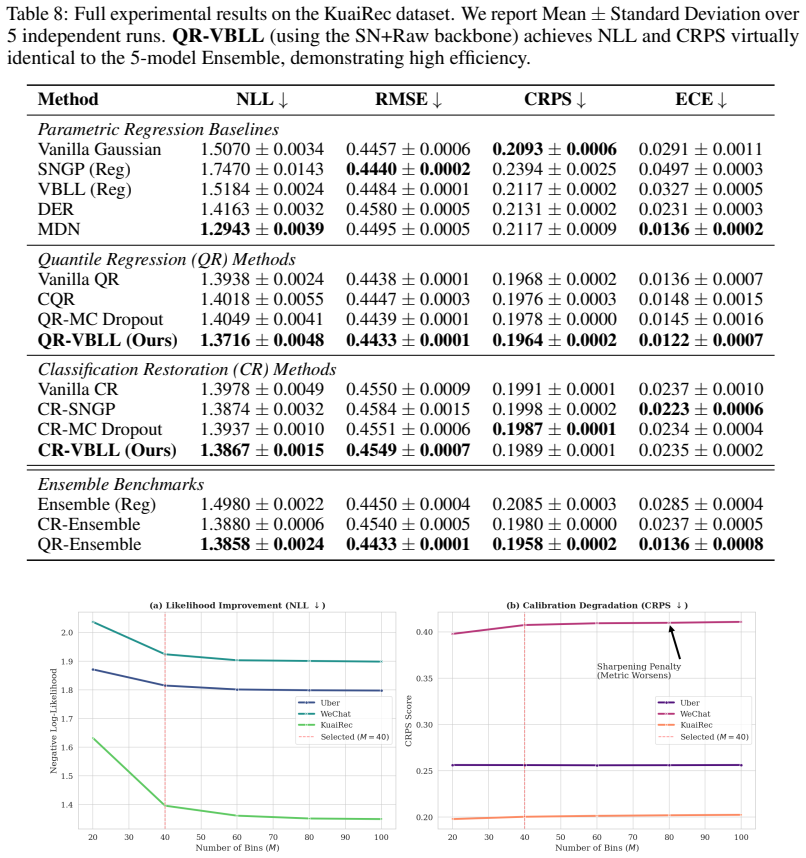
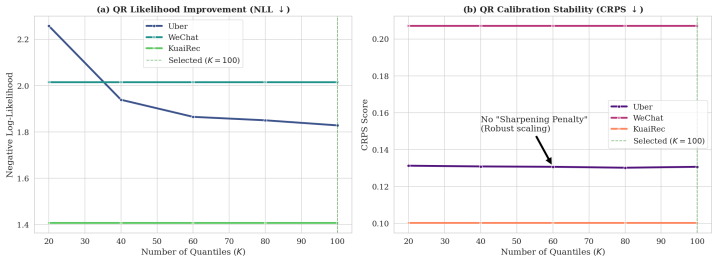
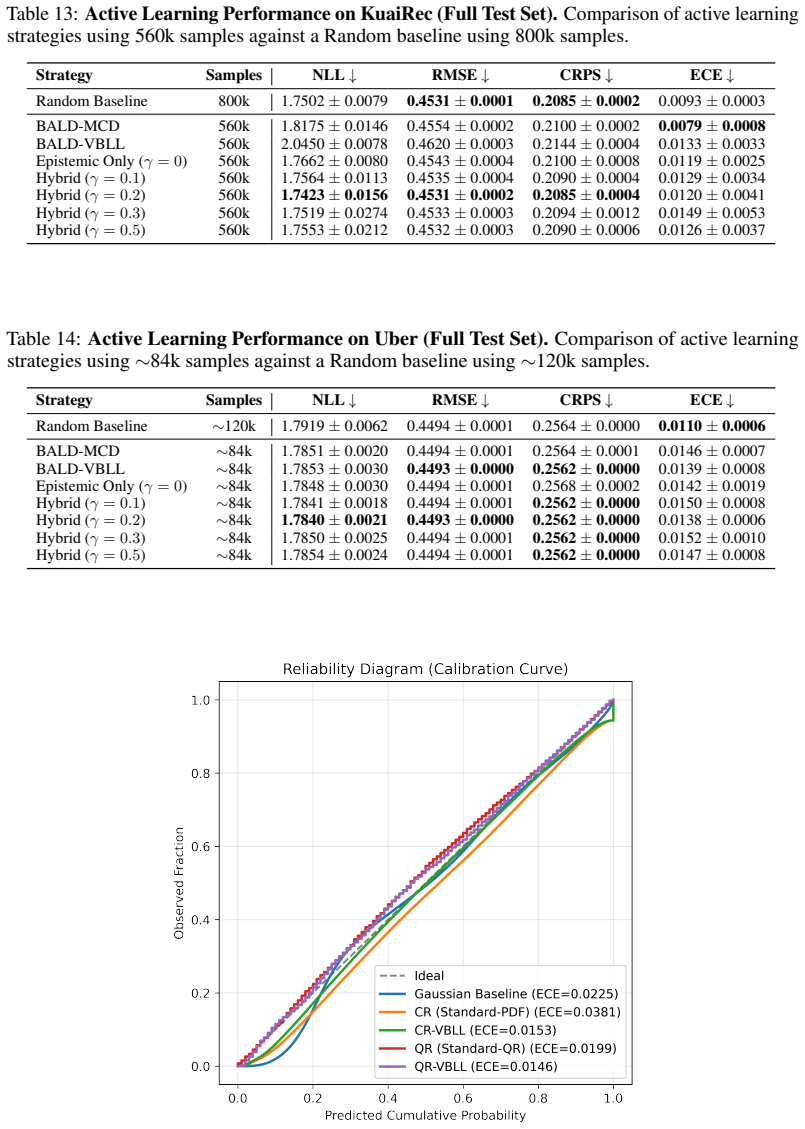
read the original abstract
Efficient uncertainty quantification (UQ) is essential for trustworthy large-scale learning. Existing UQ methods for regression tasks mainly operate under the assumption that the conditional label marginal satisfies single-peak parametric models, e.g., Gaussians, where the negative log-likelihood function simplifies to the mean square error. However, such single-peak assumptions fail in regression tasks featuring multi-modal distributions. On the other hand, semi-parametric methods which achieve strong regression performance for multi-modal distributions often lack efficient quantification on their prediction variances. In this work, we extend UQ techniques based on Variational Bayesian Inference (VBI) to two widely used semi-parametric regression models that yield histogram-like reconstructions of the conditional label densities: Quantile Regression (QR) and Classification Restoration (CR). Our approach introduces a unified, distribution-agnostic framework that simultaneously achieves accurate estimation of complex conditional distributions and highly efficient UQ. Theoretically, our method is grounded in novel formulations of QR and CR within the VBI framework, yielding analytic Evidence Lower Bounds (ELBO) to streamline training and a closed-form or analytically approximated predictive density for efficient inference. Empirically, we evaluate our methods on three large-scale regression benchmarks with multi-modal label distributions. Our framework outperforms state-of-the-art multi-modal regression baselines, and even matches predictive performance of computationally expensive ensemble models. Furthermore, by leveraging epistemic uncertainty estimation, our approach enables highly data-efficient active learning strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper extends variational Bayesian inference to quantile regression and classification restoration to handle multi-modal regression, claiming novel formulations that produce analytic ELBOs for training and closed-form or analytically approximated predictive densities for efficient UQ. It reports empirical outperformance over multi-modal baselines on three large-scale benchmarks and parity with ensembles, plus benefits for active learning via epistemic uncertainty.
Significance. If the analytic ELBO and predictive-density claims hold without hidden approximations that compromise multi-modality or distribution-agnosticism, the framework would supply a computationally lightweight UQ method for complex conditional distributions, with direct applicability to data-efficient active learning.
major comments (1)
- [Abstract] Abstract: the assertion of 'analytic Evidence Lower Bounds (ELBO)' and 'closed-form or analytically approximated predictive density' is presented without any explicit ELBO expression, derivation outline, variational family, or reparameterization. Because these properties are load-bearing for the central claim of efficient, distribution-agnostic UQ, their absence makes it impossible to assess whether the formulations are truly analytic or introduce fidelity loss.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address the single major comment below and will revise the abstract accordingly to improve clarity while preserving the paper's core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of 'analytic Evidence Lower Bounds (ELBO)' and 'closed-form or analytically approximated predictive density' is presented without any explicit ELBO expression, derivation outline, variational family, or reparameterization. Because these properties are load-bearing for the central claim of efficient, distribution-agnostic UQ, their absence makes it impossible to assess whether the formulations are truly analytic or introduce fidelity loss.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to immediately assess the analytic claims. The explicit ELBO derivations, variational family (a product of independent quantile or class-conditional distributions under a mean-field assumption), and reparameterization details appear in Sections 3.2–3.3 (QR-VBI) and 4.2–4.3 (CR-VBI). These yield closed-form ELBO terms for the chosen families without additional approximations that would compromise multi-modality. In the revised manuscript we will expand the abstract to briefly name the variational family and direct readers to the relevant sections, thereby addressing the concern without altering the distribution-agnostic character of the framework. revision: yes
Circularity Check
No circularity: novel VBI formulations of QR/CR presented as independent extensions yielding analytic ELBOs
full rationale
The paper's central claim rests on introducing novel formulations of quantile regression and classification restoration inside the variational Bayesian inference framework that produce analytic ELBOs and closed-form or approximated predictive densities. No equations, derivations, or self-citations are supplied in the provided text that reduce any claimed prediction or ELBO to a fitted parameter or prior result by construction. The description treats the VBI extension as supplying independent analytic structure rather than renaming or refitting existing quantities. This matches the default expectation of a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantile regression and classification restoration yield histogram-like reconstructions of conditional label densities that admit analytic or approximable ELBOs under VBI.
Reference graph
Works this paper leans on
-
[1]
Bayesian Analysis , year=
Bayesian regularized quantile regression , author=. Bayesian Analysis , year=
-
[2]
Journal of statistical computation and simulation , _volume=
Bayesian quantile inference , author=. Journal of statistical computation and simulation , _volume=. 2003 , _publisher=
2003
-
[3]
Journal of Money, Credit and Banking , _volume=
Constructing density forecasts from quantile regressions , author=. Journal of Money, Credit and Banking , _volume=. 2012 , _publisher=
2012
-
[4]
2005 , publisher=
Quantile regression , author=. 2005 , publisher=
2005
-
[5]
International Statistical Review , _volume=
Posterior inference in Bayesian quantile regression with asymmetric Laplace likelihood , author=. International Statistical Review , _volume=. 2016 , _publisher=
2016
-
[6]
Journal of statistical computation and simulation , _volume=
Gibbs sampling methods for Bayesian quantile regression , author=. Journal of statistical computation and simulation , _volume=. 2011 , _publisher=
2011
-
[7]
Under review , year=
Heteroscedastic Variational Last Layers , author=. Under review , year=
-
[8]
Econometrica , _pages=
Regression quantiles , author=. Econometrica , _pages=. 1978 , _publisher=
1978
-
[9]
Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence , year=
Variational inference for nonparametric Bayesian quantile regression , author=. Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence , year=
-
[10]
Statistics & Probability Letters , _volume=
Bayesian quantile regression , author=. Statistics & Probability Letters , _volume=. 2001 , _publisher=
2001
-
[11]
arXiv preprint arXiv:2407.12223 , year=
Conditional Quantile Estimation for Uncertain Watch Time in Short-Video Recommendation , author=. arXiv preprint arXiv:2407.12223 , year=
-
[12]
Proceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys '25) , pages=
Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network , author=. Proceedings of the Nineteenth ACM Conference on Recommender Systems (RecSys '25) , pages=. 2025 , organization=
2025
-
[13]
Proceedings of the 17th ACM Conference on Recommender Systems , pages=
Uncovering user interest from biased and noised watch time in video recommendation , author=. Proceedings of the 17th ACM Conference on Recommender Systems , pages=
-
[14]
Sun, Jie and Ding, Zhaoying and Wang, Ben and others , booktitle=
-
[15]
Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Tree based progressive regression model for watch-time prediction in short-video recommendation , author=. Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[16]
Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
Deconfounding duration bias in watch-time prediction for video recommendation , author=. Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining , pages=
-
[17]
Proceedings of the 17th ACM conference on recommender systems , pages=
Understanding and modeling passive-negative feedback for short-video sequential recommendation , author=. Proceedings of the 17th ACM conference on recommender systems , pages=
-
[18]
Proceedings of the 8th ACM Conference on Recommender systems , pages=
Beyond clicks: dwell time for personalization , author=. Proceedings of the 8th ACM Conference on Recommender systems , pages=
-
[19]
ECAI 2020 , pages=
Capturing attraction distribution: Sequential attentive network for dwell time prediction , author=. ECAI 2020 , pages=. 2020 , organization=
2020
-
[20]
Fisheries Research , volume=
Application of the Tweedie distribution to zero-catch data in CPUE analysis , author=. Fisheries Research , volume=. 2008 , publisher=
2008
-
[21]
1994 , booktitle=
Mixture density networks , author=. 1994 , booktitle=
1994
-
[22]
Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD '18) , pages=
Modeling task relationships in multi-task learning with multi-gate mixture-of-experts , author=. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD '18) , pages=. 2018 , organization=
2018
-
[23]
Proceedings of the 10th ACM conference on recommender systems , pages=
Deep neural networks for youtube recommendations , author=. Proceedings of the 10th ACM conference on recommender systems , pages=. 2016 , organization=
2016
-
[24]
Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Deep interest network for click-through rate prediction , author=. Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining , pages=. 2018 , organization=
2018
-
[25]
Proceedings of the 31st ACM international conference on information & knowledge management , pages=
Real-time short video recommendation on mobile devices , author=. Proceedings of the 31st ACM international conference on information & knowledge management , pages=. 2022 , organization=
2022
-
[26]
Proceedings of the 31st ACM International Conference on Information & Knowledge Management (CIKM '22) , pages=
KuaiRec: A Fully-Observed Dataset and Insights for Evaluating Recommender Systems , author=. Proceedings of the 31st ACM International Conference on Information & Knowledge Management (CIKM '22) , pages=. 2022 , organization=
2022
-
[27]
Annual review of statistics and its application , volume=
Finite mixture models , author=. Annual review of statistics and its application , volume=. 2019 , publisher=
2019
-
[28]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
Counteracting Duration Bias in Video Recommendation via Counterfactual Watch Time , author=. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining , pages=
-
[29]
Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
Overlapping experiment infrastructure: More, better, faster experimentation , author=. Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining , pages=
-
[30]
The annals of mathematical statistics , volume=
On information and sufficiency , author=. The annals of mathematical statistics , volume=
-
[31]
Companion Proceedings of the ACM Web Conference 2023 , pages=
Reinforcing user retention in a billion scale short video recommender system , author=. Companion Proceedings of the ACM Web Conference 2023 , pages=
2023
-
[32]
Journal of applied statistics , volume=
Beta regression for modelling rates and proportions , author=. Journal of applied statistics , volume=. 2004 , publisher=
2004
-
[33]
What uncertainties do we need in
Kendall, Alex and Gal, Yarin , booktitle=. What uncertainties do we need in
-
[34]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[35]
arXiv preprint arXiv:2006.07474 , year=
Efficient epistemic uncertainty estimation in regression ensemble models using pairwise-distance estimators , author=. arXiv preprint arXiv:2006.07474 , year=
-
[36]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Deep evidential regression , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[37]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Simple and principled uncertainty estimation with deterministic deep learning via distance awareness , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[38]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Conformalized quantile regression , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[39]
Proceedings of the 37th Conference on Uncertainty in Artificial Intelligence (UAI) , pages=
Integrating uncertainty awareness into conformalized quantile regression , author=. Proceedings of the 37th Conference on Uncertainty in Artificial Intelligence (UAI) , pages=
-
[40]
International Conference on Machine Learning (ICML) , pages=
A distributional perspective on reinforcement learning , author=. International Conference on Machine Learning (ICML) , pages=
-
[41]
Variational
Harrison, James and Willes, John and Snoek, Jasper , booktitle=. Variational
-
[42]
Biometrika , volume=
On optimal and data-based histograms , author=. Biometrika , volume=. 1979 , publisher=
1979
-
[43]
and Ruan, T
Lian, C. and Ruan, T. and Denoeux, T. , journal=
-
[44]
International Conference on Learning Representations (ICLR) , year=
Spectral normalization for generative adversarial networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[45]
International Conference on Machine Learning (ICML) , pages=
Dropout as a bayesian approximation: Representing model uncertainty in deep learning , author=. International Conference on Machine Learning (ICML) , pages=. 2016 , organization=
2016
-
[46]
Springer Science & Business Media , year=
Algorithmic learning in a random world , author=. Springer Science & Business Media , year=
-
[47]
The Annals of Statistics , volume=
Predictive inference with the jackknife+ , author=. The Annals of Statistics , volume=. 2021 , publisher=
2021
-
[48]
Springer , year=
Pattern recognition and machine learning , author=. Springer , year=
-
[49]
International Conference on Machine Learning (ICML) , pages=
Probabilistic backpropagation for scalable learning of bayesian neural networks , author=. International Conference on Machine Learning (ICML) , pages=. 2015 , organization=
2015
-
[50]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Single-model uncertainties for deep learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[51]
International Conference on Machine Learning (ICML) , pages=
On calibration of modern neural networks , author=. International Conference on Machine Learning (ICML) , pages=. 2017 , organization=
2017
-
[52]
International Conference on Machine Learning (ICML) , pages=
Uncertainty estimation using a single deep deterministic neural network , author=. International Conference on Machine Learning (ICML) , pages=. 2020 , organization=
2020
-
[53]
Biometrika , volume=
On the likelihood that one unknown probability exceeds another in view of the evidence of two samples , author=. Biometrika , volume=
-
[54]
Foundations and Trends® in Machine Learning , volume=
A tutorial on thompson sampling , author=. Foundations and Trends® in Machine Learning , volume=
-
[55]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Variational Dropout and the Local Reparameterization Trick , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[56]
NeurIPS , year=
What uncertainties do we need in bayesian deep learning for computer vision? , author=. NeurIPS , year=
-
[57]
2018 , publisher=
Foundations of machine learning , author=. 2018 , publisher=
2018
-
[58]
Engineering , volume=
Non-IID recommender systems: A review and framework of recommendation paradigm shifting , author=. Engineering , volume=. 2016 , note=
2016
-
[59]
ICML , year=
Weight uncertainty in neural network , author=. ICML , year=
-
[60]
Journal of the American Statistical Association , volume=
Strictly proper scoring rules, prediction, and estimation , author=. Journal of the American Statistical Association , volume=. 2007 , publisher=
2007
-
[61]
Journal of Machine Learning Research , volume=
Nonparametric quantile estimation , author=. Journal of Machine Learning Research , volume=
-
[62]
Soviet Mathematics , volume=
Estimation of an unknown distribution density from observations , author=. Soviet Mathematics , volume=
-
[63]
Bernoulli , volume=
Estimating conditional quantiles with the help of the pinball loss , author=. Bernoulli , volume=. 2011 , publisher=
2011
-
[64]
Proceedings of the 35th International Conference on Machine Learning , pages=
Decomposition of Uncertainty in Bayesian Deep Learning for Efficient and Risk-sensitive Learning , author=. Proceedings of the 35th International Conference on Machine Learning , pages=. 2018 , volume=
2018
-
[65]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Learning for Single-Shot Confidence Calibration in Deep Neural Networks through Stochastic Inferences , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[66]
Kristiadi, Agustinus and Hein, Matthias and Hennig, Philipp , booktitle=. Being. 2020 , publisher=
2020
-
[67]
Tashiro, Yusuke and Song, Jiaming and Song, Yang and Ermon, Stefano , booktitle=
-
[68]
2018 IEEE International Conference on Robotics and Automation (ICRA) , pages=
End-to-end driving via conditional imitation learning , author=. 2018 IEEE International Conference on Robotics and Automation (ICRA) , pages=. 2018 , organization=
2018
-
[69]
, booktitle=
Yang, Zhilin and Dai, Zihang and Salakhutdinov, Ruslan and Cohen, William W. , booktitle=. Breaking the Softmax Bottleneck: A High-Rank. 2018 , url=
2018
-
[70]
2000 , publisher=
Asymptotic statistics , author=. 2000 , publisher=
2000
-
[71]
2019 International Conference on Robotics and Automation (ICRA) , pages=
Multimodal trajectory predictions for autonomous driving using deep convolutional networks , author=. 2019 International Conference on Robotics and Automation (ICRA) , pages=. 2019 , organization=
2019
-
[72]
Bayesian Active Learning for Classification and Preference Learning
Bayesian active learning for classification and preference learning , author=. arXiv preprint arXiv:1112.5745 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=
Deep bayesian active learning with image data , author=. Proceedings of the 34th International Conference on Machine Learning (ICML) , pages=. 2017 , organization=
2017
-
[74]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
BatchBALD: Efficient and diverse batch active learning for deep neural networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[75]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Learning loss for active learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[76]
International Conference on Learning Representations (ICLR) , year=
Active Learning for Convolutional Neural Networks: A Core-Set Approach , author=. International Conference on Learning Representations (ICLR) , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.