Reflective VLA: In-Context Action Consequences Make VLAs Generalize
Pith reviewed 2026-06-26 00:00 UTC · model grok-4.3
The pith
Conditioning VLAs on observation-action-consequence triplets improves generalization under distribution shift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
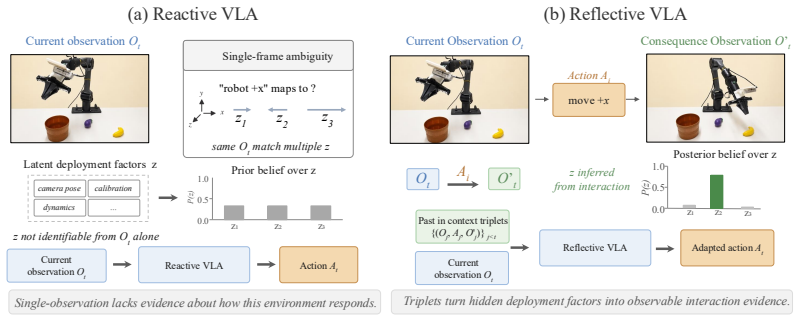
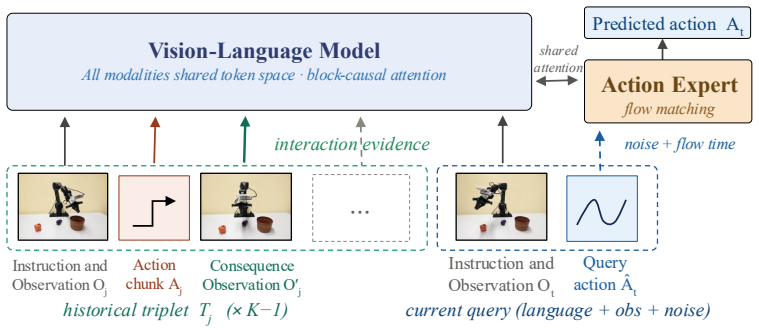
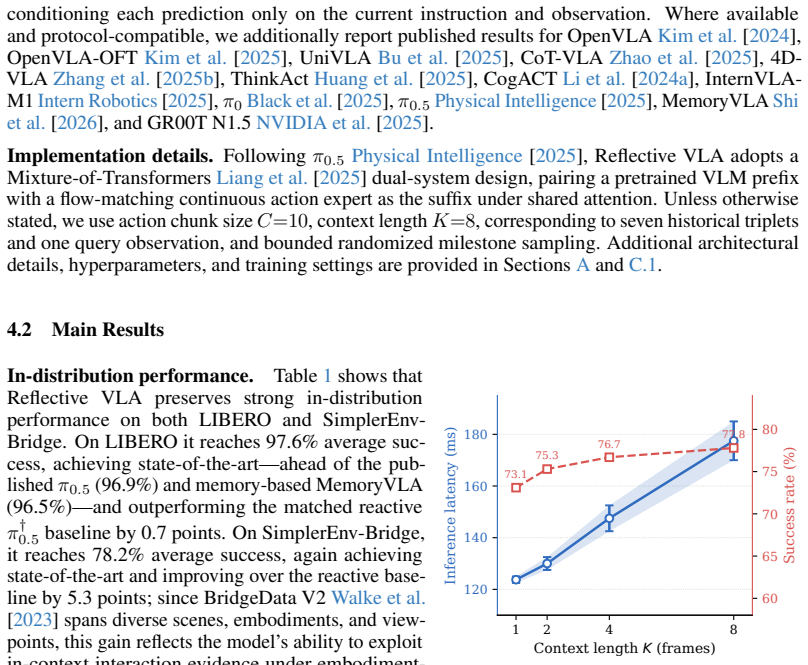
Reflective VLA conditions each decision on a context of observation-action-consequence triplets. Each triplet records not only what the robot observed and executed, but also how the scene changed afterward, exposing the deployment-specific mapping from actions to observed effects. Architecturally, Reflective VLA routes all observation modalities through the VLM under shared attention, so the action expert reasons directly over past triplets and the current observation. A block-causal mask enables parallel multi-frame training without leakage and supports KV-cached real-time inference.
What carries the argument
Observation-action-consequence triplet context that exposes the deployment-specific mapping from actions to observed effects.
If this is right
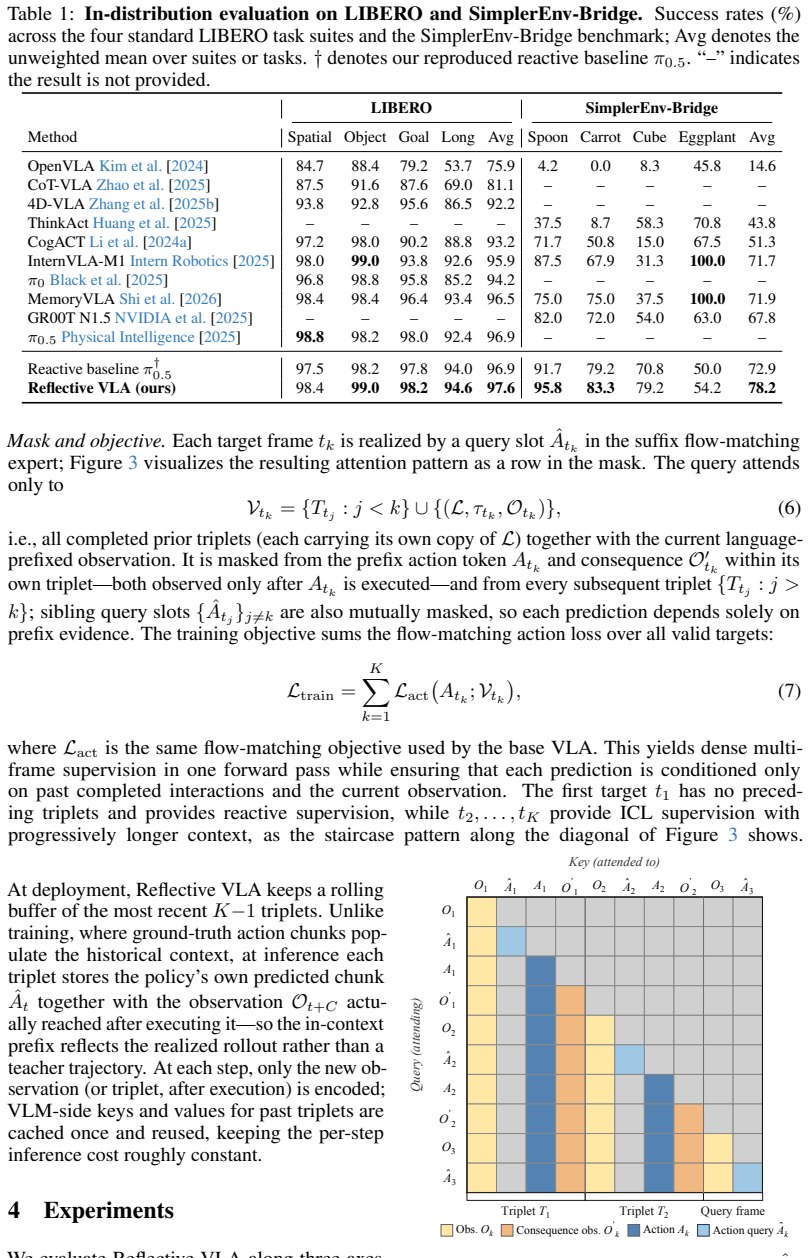
- In-distribution performance on LIBERO and SimplerEnv-Bridge remains comparable to reactive baselines.
- Average success rate rises 5.4 percentage points on LIBERO-Plus under distribution shift.
- Average success rate rises 4.2 percentage points on the harder LIBERO-Plus-Hard benchmark.
- Action consequences, rather than context length alone, produce the measured cross-environment gains.
Where Pith is reading between the lines
- The same triplet conditioning could be tested on real-robot platforms where calibration drifts between sessions.
- If consequence images become noisy in practice, the model might still benefit from learning an internal forward model of scene change.
- The block-causal masking pattern could be reused in other partially observable sequential decision tasks outside robotics.
- Shorter histories might suffice if the first consequence already reveals the dominant hidden factor such as camera offset.
Load-bearing premise
The visual change after an action is observable and sufficient to disambiguate embodiment-specific factors that a single frame cannot reveal.
What would settle it
Running the same architecture on LIBERO-Plus with consequence images replaced by random frames and measuring whether the reported 5.4-point gain disappears.
Figures

read the original abstract
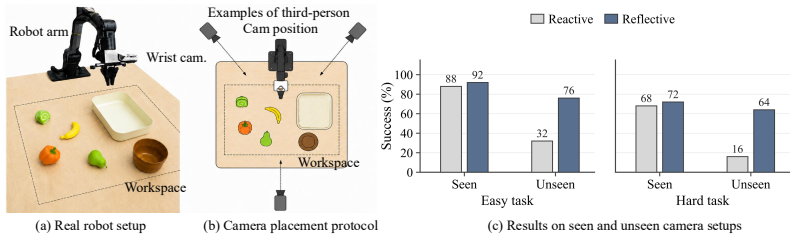
Most vision-language-action (VLA) models are reactive: they predict the next action from the current instruction and observation, implicitly assuming that the current observation fully specifies the action-relevant state. In embodied control, however, embodiment-specific factors such as camera-to-robot geometry, robot calibration, or systematic actuation bias are often hard to identify from a single observation. As a result, reactive policies cannot reliably disambiguate these factors in general, overfitting to training environments and generalizing poorly at deployment. We propose Reflective VLA, which conditions each decision on a context of observation-action-consequence triplets. Each triplet records not only what the robot observed and executed, but also how the scene changed afterward, exposing the deployment-specific mapping from actions to observed effects. Architecturally, Reflective VLA routes all observation modalities through the VLM under shared attention, so the action expert reasons directly over past triplets and the current observation. A block-causal mask enables parallel multi-frame training without leakage and supports KV-cached real-time inference. On standard LIBERO and SimplerEnv-Bridge, Reflective VLA preserves strong in-distribution performance. Under distribution shift on LIBERO-Plus and the harder LIBERO-Plus-Hard, it improves average success rate by 5.4 and 4.2 percentage points over a matched reactive baseline. Ablations with a matched history-only baseline further show that action consequences -- rather than additional context length alone -- are the key to cross-environment generalization. Project page: https://lianqing11.github.io/reflective-vla-page/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Reflective VLA, a VLA architecture that conditions each action prediction on a context of observation-action-consequence triplets (rather than current observation alone) to expose embodiment-specific factors such as camera-to-robot geometry and actuation bias. It reports that this yields 5.4 and 4.2 percentage-point gains in average success rate under distribution shift on LIBERO-Plus and LIBERO-Plus-Hard while preserving in-distribution performance on standard LIBERO and SimplerEnv-Bridge; a matched history-only ablation is used to argue that consequences, not extra context length, drive the improvement. The model routes modalities through a shared VLM with block-causal masking for parallel training and KV-cached inference.
Significance. If the reported gains hold and the ablation isolates the claimed mechanism, the result would be a concrete, empirically grounded advance in VLA generalization for embodied control. The direct comparison to a history-only baseline provides a falsifiable test of the central hypothesis that consequence signals disambiguate factors invisible in single frames. The block-causal masking design is a technical strength that supports both training efficiency and real-time deployment.
major comments (2)
- [Experiments and Ablations] The ablation against the history-only baseline is load-bearing for the claim that 'action consequences -- rather than additional context length alone -- are the key to cross-environment generalization.' However, the manuscript does not provide explicit construction details for the consequence triplets (e.g., exact triplet length, what visual signal replaces the consequence frame in the baseline, or how the triplets are assembled from rollout data). Without these, it is not possible to confirm that the baseline is matched in all respects except the consequence signal.
- [§3 (Method) and §4 (Experiments)] The central assumption that visual consequences are both perceptible to the VLM and sufficient to resolve embodiment-specific ambiguities (camera calibration, actuation bias) is not verified with targeted diagnostics. The paper should report whether the observed scene changes in LIBERO-Plus are large enough to disambiguate the shifts, or include an analysis of cases where the consequence signal is subtle or histories are short.
minor comments (2)
- [§3] Notation for the triplet components (observation, action, consequence) should be defined once in a dedicated subsection and used consistently; current usage mixes descriptive text with inline symbols.
- [Table 2] Table captions for the LIBERO-Plus results should explicitly state the number of evaluation episodes per environment and whether success is measured over the full task horizon or a fixed number of steps.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of Reflective VLA's potential contribution and for the detailed, constructive comments. We address each major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments and Ablations] The ablation against the history-only baseline is load-bearing for the claim that 'action consequences -- rather than additional context length alone -- are the key to cross-environment generalization.' However, the manuscript does not provide explicit construction details for the consequence triplets (e.g., exact triplet length, what visual signal replaces the consequence frame in the baseline, or how the triplets are assembled from rollout data). Without these, it is not possible to confirm that the baseline is matched in all respects except the consequence signal.
Authors: We agree that the current manuscript lacks sufficient explicit details on triplet construction and baseline matching, which limits the ability to fully verify the ablation. In the revised version we will add a dedicated paragraph in §4 (Experiments) specifying: triplet length (fixed at 4 frames per context window), assembly procedure (each triplet is formed as (o_t, a_t, o_{t+1}) drawn directly from the same rollout trajectories used for training), and baseline construction (consequence frames o_{t+1} are replaced by a duplicate of the current observation o_t while preserving identical sequence length, token count, and block-causal masking). These additions will make the matched nature of the ablation explicit. revision: yes
-
Referee: [§3 (Method) and §4 (Experiments)] The central assumption that visual consequences are both perceptible to the VLM and sufficient to resolve embodiment-specific ambiguities (camera calibration, actuation bias) is not verified with targeted diagnostics. The paper should report whether the observed scene changes in LIBERO-Plus are large enough to disambiguate the shifts, or include an analysis of cases where the consequence signal is subtle or histories are short.
Authors: We concur that direct diagnostics would better substantiate the mechanism. While the existing ablations and distribution-shift results provide indirect support, the manuscript does not contain quantitative analysis of scene-change magnitude or performance stratified by history length. In the revision we will add to §4: (i) average L2 feature distance (using the VLM encoder) between pre- and post-action frames on LIBERO-Plus to quantify perceptible change, and (ii) a breakdown of success rates on short-history subsets (<3 frames) versus longer contexts. This will clarify when consequence signals are most informative. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The paper advances an architectural proposal (conditioning on observation-action-consequence triplets) and supports its generalization claims solely through measured success rates on held-out LIBERO-Plus and SimplerEnv environments plus matched ablations. No mathematical derivation, fitted parameter, or self-referential equation is present; the central performance deltas are obtained from independent test distributions and do not reduce to the method definition by construction. No load-bearing self-citations or imported uniqueness results appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AgiBot-World-Contributors, Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, et al. AgiBot World Colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669,
-
[2]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025a
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
-
[3]
doi: 10.15607/RSS.2025.XXI.010. Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alexander Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale. InRSS,
-
[4]
doi: 10.15607/RSS.2023.XIX.025. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, ...
-
[5]
doi: 10.15607/RSS.2025. XXI.014. Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. In NeurIPS,
-
[6]
RL$^2$: Fast Reinforcement Learning via Slow Reinforcement Learning
doi: 10.15607/RSS.2023.XIX.026. Yan Duan, John Schulman, Xi Chen, Peter L. Bartlett, Ilya Sutskever, and Pieter Abbeel. Rl2: Fast reinforcement learning via slow reinforcement learning.arXiv preprint arXiv:1611.02779,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.15607/rss.2023.xix.026 2023
-
[7]
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. LIBERO-Plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626,
-
[8]
Intern Robotics. InternVLA-M1: A spatially guided vision-language-action framework for generalist robot policy.arXiv preprint arXiv:2510.13778,
-
[9]
doi: 10.15607/RSS.2025.XXI.017. Michael Laskin, Luyu Wang, Junhyuk Oh, Emilio Parisotto, Stephen Spencer, Richie Steigerwald, DJ Strouse, Steven Hansen, Angelos Filos, Ethan Brooks, Maxime Gazeau, Himanshu Sahni, Satinder Singh, and V olodymyr Mnih. In-context reinforcement learning with algorithm distillation. InICLR,
-
[10]
Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, Xiaofan Wang, Bei Liu, Jianlong Fu, Jianmin Bao, Dong Chen, Yuanchun Shi, Jiaolong Yang, and Baining Guo. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:24...
-
[11]
GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
NVIDIA, Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
-
[12]
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747,
-
[13]
π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054,
Physical Intelligence. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054,
-
[14]
doi: 10.15607/RSS.2024.XX.090. Homer Rich Walke, Kevin Black, Tony Z. Zhao, Quan Vuong, Chongyi Zheng, Philippe Hansen-Estruch, Andre Wang He, Vivek Myers, Moo Jin Kim, Max Du, Abraham Lee, Kuan Fang, Chelsea Finn, and Sergey Levine. BridgeData V2: A dataset for robot learning at scale. InConference on Robot Learning, volume 229, pages 1723–1736,
-
[15]
A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692,
Wei Wu, Fan Lu, Yunnan Wang, Shuai Yang, Shi Liu, Fangjing Wang, Qian Zhu, He Sun, Yong Wang, Shuailei Ma, et al. A pragmatic vla foundation model.arXiv preprint arXiv:2601.18692,
-
[16]
Hongyin Zhang, Shuo Zhang, Junxi Jin, Qixin Zeng, Runze Li, and Donglin Wang. Robustvla: Robustness-aware reinforcement post-training for vision-language-action models.arXiv preprint arXiv:2511.01331, 2025a. Jiahui Zhang, Yurui Chen, Yueming Xu, Ze Huang, Yanpeng Zhou, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, Xingyue Quan, Hang Xu, and Li Zhang. 4d-vla: Spa...
-
[17]
doi: 10.15607/RSS.2023.XIX.016. Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Ya-Qin Zhang, Jiangmiao Pang, Jingjing Liu, Tai Wang, and Xianyuan Zhan. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model. InICLR,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.