FUTO Swipe: Layout-Agnostic Neural Swipe Decoding
Pith reviewed 2026-06-25 20:48 UTC · model grok-4.3
The pith
A neural swipe decoder can decode gestures on any contiguous keyboard layout without retraining by predicting character locations instead of fixed keys.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
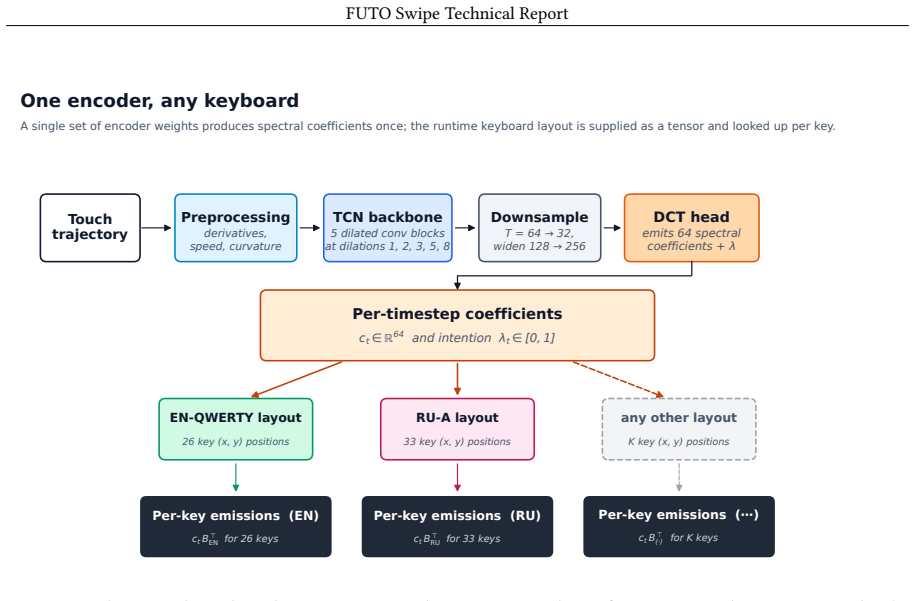
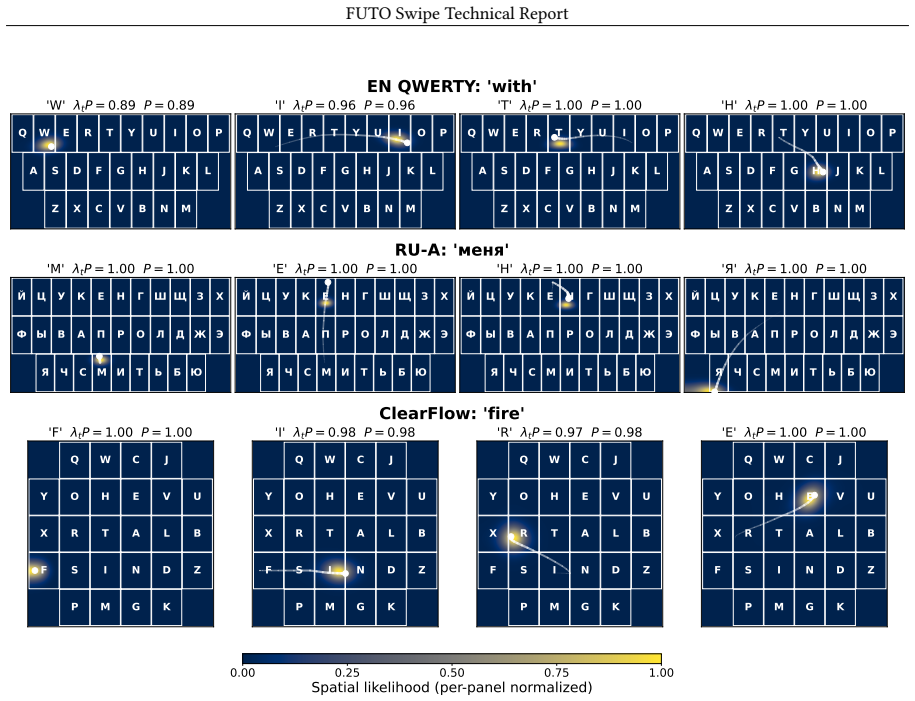
The central claim is that an encoder trained with geometric augmentations on swipe trajectories and keyboard layouts can predict per-point character indications and locations independently of any particular geometry; at inference the supplied layout is used only to map those predictions to logits, allowing the same model to decode swipes accurately on layouts absent from training and in some cases more accurately than on the training layout itself.
What carries the argument
The per-point spatial prediction head that outputs character-presence and location probabilities from the swipe trajectory, which are later aligned to an arbitrary layout supplied at inference.
If this is right
- Any new contiguous keyboard layout can be supported at inference time without collecting swipe data or running another training job.
- The same trained model can be paired with multiple layouts, including ones that differ in key size, spacing, or overall shape.
- Accuracy on unseen layouts can exceed accuracy on the layout used during training when the augmentations succeed in removing layout-specific biases.
- The released corpus of over one million swipes provides a public resource for training or evaluating further layout-agnostic decoders.
Where Pith is reading between the lines
- The same location-prediction approach could be tested on non-English scripts or right-to-left layouts to check whether the learned gesture features remain layout-independent.
- If the per-point predictions prove robust, the method might reduce the data requirements for adapting neural decoders to entirely new input surfaces such as tablets or foldables.
- Extreme layouts whose geometry lies far outside the augmentation distribution would provide a direct test of how far the independence claim extends.
Load-bearing premise
Geometric augmentations applied to both swipe trajectories and keyboard layouts during training are sufficient to make the encoder's per-point character-location predictions independent of the specific training layout.
What would settle it
Decoding accuracy measured on a contiguous layout whose key positions and relative sizes cannot be produced from the training layout by the geometric transformations used in augmentation.
Figures

read the original abstract
Neural swipe decoders are typically tied to the keyboard they were trained on, requiring a new corpus and training run for each layout. In this report, we document our approach toward training models that can function on any contiguous mobile keyboard layout. At each point along the swipe, our encoder predicts whether the user is indicating a character and where on the keyboard that character lies. The keyboard layout is supplied at inference time and used to map the spatial and temporal prediction to a logit at each key, rather than being learned during training. Training neural models requires substantial data, but public swipe data is limited, particularly for non-QWERTY layouts. We release swipe.futo.org, the largest MIT-licensed swipe corpus we are aware of, containing over 1M donated swipes from more than 12k donor sessions. To generalize beyond the English QWERTY layout, we apply geometric augmentations to both the swipe trajectory and the keyboard layout at every training step, forcing the model to make predictions based on characteristics of the swipe gesture rather than the training layout. The model generalizes to layouts absent from training, in some cases more accurately than the layout it was trained on. This combines the layout-flexibility of an algorithmic decoder with the accuracy of a neural model. Trained models are publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a neural swipe decoder designed to operate on arbitrary contiguous mobile keyboard layouts without retraining. At each point in a swipe trajectory, an encoder predicts whether a character is being indicated and its spatial location; the supplied layout at inference time then maps these predictions to per-key logits. Geometric augmentations are applied to both trajectories and layouts during training to promote layout independence, and the authors release swipe.futo.org, a large MIT-licensed corpus of over 1M swipes, to support further work. The central empirical claim is that the resulting model generalizes to layouts absent from training and in some cases outperforms the layout on which it was trained.
Significance. If the generalization result is substantiated with detailed experimental evidence, the work would meaningfully advance neural input methods by removing the need for per-layout retraining while retaining neural accuracy. The public release of the swipe.futo.org dataset constitutes a concrete, reusable contribution that directly addresses the scarcity of non-QWERTY swipe data and improves reproducibility in the field.
major comments (2)
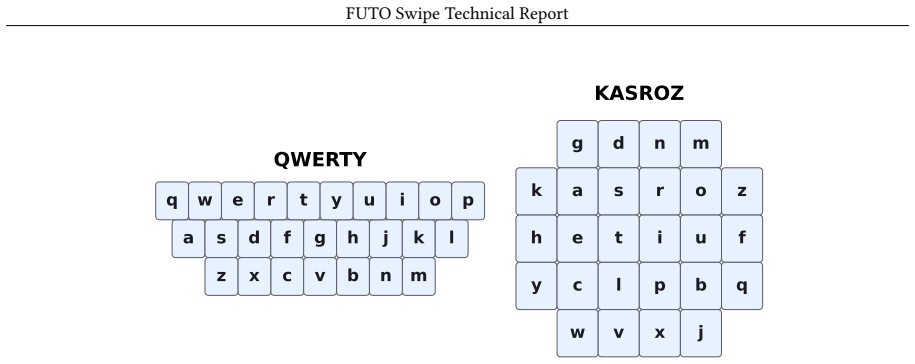
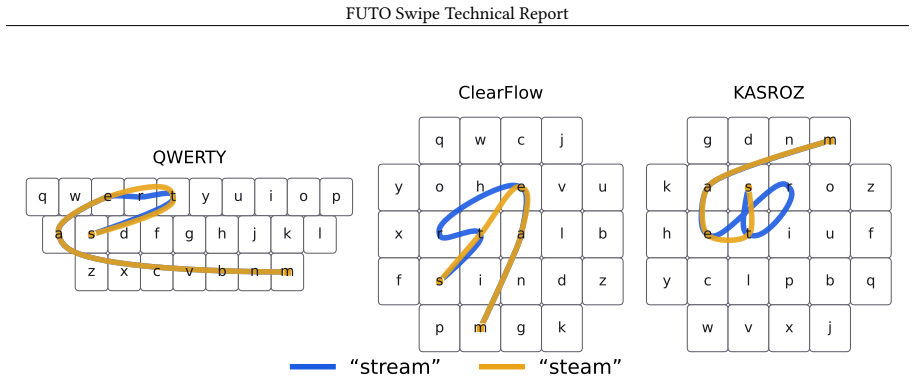
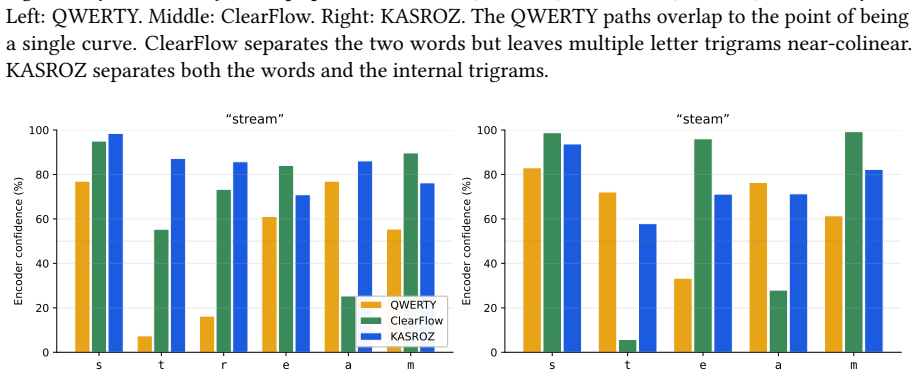
- [Abstract] Abstract: the claim that the model 'generalizes to layouts absent from training, in some cases more accurately than the layout it was trained on' is the central empirical result, yet the abstract supplies no description of the test layouts, their structural differences from the training layout, baseline comparisons, error bars, or statistical tests. This absence prevents evaluation of whether the reported gains reflect true layout-agnostic behavior.
- [Training procedure] Training procedure (geometric augmentations): the description states that augmentations are applied to both swipe trajectories and keyboard layouts at every step, but does not specify the transformation family (e.g., whether it includes changes to key count, row count, or adjacency graph topology). Without this detail the claim that the encoder's per-point predictions become independent of any specific training layout cannot be assessed for genuinely novel layouts.
minor comments (1)
- [Abstract] The term 'contiguous mobile keyboard layout' is used without an explicit definition or illustration of what constitutes contiguity versus non-contiguous arrangements.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The two major comments identify areas where additional specificity will strengthen the manuscript; we address each below and will incorporate revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the model 'generalizes to layouts absent from training, in some cases more accurately than the layout it was trained on' is the central empirical result, yet the abstract supplies no description of the test layouts, their structural differences from the training layout, baseline comparisons, error bars, or statistical tests. This absence prevents evaluation of whether the reported gains reflect true layout-agnostic behavior.
Authors: We agree the abstract is too terse on the central empirical claim. In revision we will add a concise clause describing the unseen test layouts (alternative English layouts with different key counts and row structures plus one non-Latin layout), note that results include baseline comparisons with error bars, and direct readers to the experiments section for statistical details. Abstract length constraints preclude full statistical reporting there. revision: yes
-
Referee: [Training procedure] Training procedure (geometric augmentations): the description states that augmentations are applied to both swipe trajectories and keyboard layouts at every step, but does not specify the transformation family (e.g., whether it includes changes to key count, row count, or adjacency graph topology). Without this detail the claim that the encoder's per-point predictions become independent of any specific training layout cannot be assessed for genuinely novel layouts.
Authors: The referee correctly notes that the current text is high-level. The augmentation family does encompass changes to key count, row count, and adjacency: at each step we apply random affine transforms to trajectories and, for layouts, we perturb grid positions, insert or delete keys within rows, and alter relative adjacencies while preserving contiguity. We will expand the training-procedure section with an explicit enumeration of the transformation parameters and ranges so that readers can evaluate the degree of layout novelty. revision: yes
Circularity Check
No circularity; empirical augmentation and testing on held-out layouts
full rationale
The paper presents an empirical training procedure that applies geometric augmentations to swipe trajectories and keyboard layouts during training, then evaluates the resulting encoder on layouts absent from the training distribution. No equations, fitted parameters, or self-citations are invoked to derive the central generalization claim; the layout-agnostic behavior is asserted as an observed outcome of the augmentation regime rather than a mathematical identity or renamed input. The approach is self-contained against external benchmarks (the released corpus and public model weights) and does not reduce any prediction to a quantity defined by the target result itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Swipe gestures contain layout-independent spatial-temporal features that can be isolated by geometric augmentation of both trajectory and keyboard.
Reference graph
Works this paper leans on
-
[1]
swipe.futo.org: An open english swipe-typing corpus, 2026
FUTO. swipe.futo.org: An open english swipe-typing corpus, 2026. https://huggingface. co/datasets/futo-org/swipe.futo.org
2026
-
[2]
SHARK 2: a large vocabulary shorthand writing system for pen-based computers
Per Ola Kristensson and Shumin Zhai. SHARK 2: a large vocabulary shorthand writing system for pen-based computers. In Steven Feiner and James A. Landay, editors,Proceedings of the 17th Annual ACM Symposium on User Interface Software and Technology, Santa Fe, NM, USA, October 24-27, 2004, pages 43–52. ACM, 2004. doi: 10.1145/1029632.1029640. URL https://do...
-
[3]
Alex Graves, Santiago Fernández, Faustino J. Gomez, and Jürgen Schmidhuber. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In William W. Cohen and Andrew W. Moore, editors,Machine Learning, Proceedings of the Twenty- Third International Conference (ICML 2006), Pittsburgh, Pennsylvania, USA, June ...
-
[4]
Ouais Alsharif, Tom Ouyang, Françoise Beaufays, Shumin Zhai, Thomas M. Breuel, and Johan Schalkwyk. Long short term memory neural network for keyboard gesture decoding. In2015 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2015, South Brisbane, Queensland, Australia, April 19-24, 2015, pages 2076–2080. IEEE, 2015. doi: 10...
-
[5]
Emil Biju, Anirudh Sriram, Mitesh M. Khapra, and Pratyush Kumar. Joint transformer/RNN architecture for gesture typing in indic languages. In Donia Scott, Nuria Bel, and Chengqing Zong, editors,Proceedings of the 28th International Conference on Computational Linguistics, pages 999–1010, Barcelona, Spain (Online), December 2020. International Committee on...
-
[6]
Leiva, Sunjun Kim, Wenzhe Cui, Xiaojun Bi, and Antti Oulasvirta
Luis A. Leiva, Sunjun Kim, Wenzhe Cui, Xiaojun Bi, and Antti Oulasvirta. How we swipe: A large- scale shape-writing dataset and empirical findings. In Jessica R. Cauchard and Marcos Serrano, editors,MobileHCI ’21: 23rd International Conference on Mobile Human-Computer Interaction, Toulouse & Virtual Event, France, 27 September 2021 - 1 October 2021, pages...
-
[7]
Neu- ral search space in gboard decoder
Yanxiang Zhang, Yuanbo Zhang, Haicheng Sun, Yun Wang, Gary Sivek, and Shumin Zhai. Neu- ral search space in gboard decoder. In Franck Dernoncourt, Daniel Preoţiuc-Pietro, and Anas- tasia Shimorina, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1245–1254, Miami, Florida, US, November 2...
-
[8]
Bellegarda, Ojas Bapat, Partha Lal, and Xin Wang
Akash Mehra, Jerome R. Bellegarda, Ojas Bapat, Partha Lal, and Xin Wang. Leveraging gans to improve continuous path keyboard input models. In2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, May 4-8, 2020, pages 8174–
2020
-
[9]
IEEE, 2020. doi: 10.1109/ICASSP40776.2020.9052978. URL https://doi.org/10.1109/ ICASSP40776.2020.9052978. 15 FUTO Swipe Technical Report
-
[10]
How we use deep learning for swipe typing on the Grammarly iOS Keyboard, 2024
Grammarly Engineering. How we use deep learning for swipe typing on the Grammarly iOS Keyboard, 2024. Grammarly Engineering blog, https://www.grammarly.com/blog/ engineering/deep-learning-swipe-typing/
2024
-
[11]
Xiaojun Bi and Shumin Zhai. IJQwerty: What difference does one key change make? gesture typing keyboard optimization bounded by one key position change from qwerty. In Jofish Kaye, Allison Druin, Cliff Lampe, Dan Morris, and Juan Pablo Hourcade, editors,Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, May 7-...
-
[12]
Smith, Xiaojun Bi, and Shumin Zhai
Brian A. Smith, Xiaojun Bi, and Shumin Zhai. Optimizing touchscreen keyboards for gesture typing. In Bo Begole, Jinwoo Kim, Kori Inkpen, and Woontack Woo, editors,Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, CHI 2015, Seoul, Republic of Korea, April 18-23, 2015, pages 3365–3374. ACM, 2015. doi: 10.1145/2702123.27023...
-
[13]
ClearFlow: Typing with clarity and flow
ClearFlow Keyboard. ClearFlow: Typing with clarity and flow. https://clearflowkeyboard. github.io/, 2026
2026
-
[14]
Junxiao Shen, Khadija Khaldi, Enmin Zhou, Hemant Bhaskar Surale, and Amy Karlson. Ges- ture2text: A generalizable decoder for word-gesture keyboards in XR through trajectory coarse discretization and pre-training.IEEE Trans. Vis. Comput. Graph., 30(11):7118–7128, 2024. doi: 10.1109/TVCG.2024.3456198. URLhttps://doi.org/10.1109/TVCG.2024.3456198
-
[15]
Mobile keyboard input decoding with finite-state transducers, 2017
Tom Ouyang, David Rybach, Françoise Beaufays, and Michael Riley. Mobile keyboard input decoding with finite-state transducers, 2017. URLhttps://arxiv.org/abs/1704.03987
Pith/arXiv arXiv 2017
-
[16]
Transliterated mobile keyboard input via weighted finite-state transducers
Lars Hellsten, Brian Roark, Prasoon Goyal, Cyril Allauzen, Françoise Beaufays, Tom Ouyang, Michael Riley, and David Rybach. Transliterated mobile keyboard input via weighted finite-state transducers. In Frank Drewes, editor,Proceedings of the 13th International Conference on Finite State Methods and Natural Language Processing (FSMNLP 2017), pages 10–19, ...
-
[17]
Dirty Data in the Newsroom: Comparing Data Preparation in Journalism and Data Science,
Jeremy Chu, Dongsheng An, Yan Ma, Wenzhe Cui, Shumin Zhai, Xianfeng David Gu, and Xiaojun Bi. WordGesture-GAN: Modeling word-gesture movement with generative adversarial network. In Albrecht Schmidt, Kaisa Väänänen, Tesh Goyal, Per Ola Kristensson, Anicia Peters, Stefanie Mueller, Julie R. Williamson, and Max L. Wilson, editors,Proceedings of the 2023 CHI...
-
[18]
Mykola Maslych, Eugene Matthew Taranta, Mostafa Aldilati, and Joseph J. LaViola. Effective 2d stroke-based gesture augmentation for rnns. In Albrecht Schmidt, Kaisa Väänänen, Tesh Goyal, Per Ola Kristensson, Anicia Peters, Stefanie Mueller, Julie R. Williamson, and Max L. Wilson, editors,Proceedings of the 2023 CHI Conference on Human Factors in Computing...
-
[19]
Yahia Hamdi, Houcine Boubaker, and Adel M. Alimi. Data augmentation using geometric, fre- quency, and beta modeling approaches for improving multi-lingual online handwriting recognition. Int. J. Document Anal. Recognit., 24(3):283–298, 2021. doi: 10.1007/S10032-021-00376-2. URL https://doi.org/10.1007/s10032-021-00376-2. 16 FUTO Swipe Technical Report
-
[20]
Curtis Wigington, Seth Stewart, Brian L. Davis, Bill Barrett, Brian L. Price, and Scott Cohen. Data augmentation for recognition of handwritten words and lines using a CNN-LSTM network. In 14th IAPR International Conference on Document Analysis and Recognition, ICDAR 2017, Kyoto, Japan, November 9-15, 2017, pages 639–645. IEEE, 2017. doi: 10.1109/ICDAR.20...
-
[21]
Iglovikov, Eugene Khvedchenya, Alex Parinov, Mikhail Druzhinin, and Alexandr A
Alexander Buslaev, Vladimir I. Iglovikov, Eugene Khvedchenya, Alex Parinov, Mikhail Druzhinin, and Alexandr A. Kalinin. Albumentations: Fast and flexible image augmentations.Inf., 11(2):125,
-
[22]
doi: 10.3390/INFO11020125. URLhttps://doi.org/10.3390/info11020125
-
[23]
Sanghyun Woo, Shoubhik Debnath, Ronghang Hu, Xinlei Chen, Zhuang Liu, In So Kweon, and Saining Xie. Convnext V2: co-designing and scaling convnets with masked autoencoders. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 16133–16142. IEEE, 2023. doi: 10.1109/CVPR52729.2023.01548....
-
[24]
Squeeze-and-excitation networks
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 7132–7141. Computer Vision Foundation / IEEE Computer Society, 2018. doi: 10.1109/ CVPR.2018.00745. URL http://openaccess.thecvf.com/content_cvpr_2018/html/Hu_ Squeez...
arXiv 2018
-
[25]
A ConvNet for the 2020s , booktitle =
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 11966–11976. IEEE, 2022. doi: 10.1109/ CVPR52688.2022.01167. URLhttps://doi.org/10.1109/CVPR52688.2022.01167
-
[26]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenRe- view.net, 2019. URLhttps://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[27]
Deep-fsmn for large vocabulary continuous speech recognition
Shiliang Zhang, Ming Lei, Zhijie Yan, and Lirong Dai. Deep-fsmn for large vocabulary continuous speech recognition. In2018 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, AB, Canada, April 15-20, 2018, pages 5869–5873. IEEE, 2018. doi: 10.1109/ ICASSP.2018.8461404. URLhttps://doi.org/10.1109/ICASSP.2018.8461404
-
[28]
The lambdaloss framework for ranking metric optimization
Xuanhui Wang, Cheng Li, Nadav Golbandi, Michael Bendersky, and Marc Najork. The lambdaloss framework for ranking metric optimization. In Alfredo Cuzzocrea, James Allan, Norman W. Paton, Divesh Srivastava, Rakesh Agrawal, Andrei Z. Broder, Mohammed J. Zaki, K. Selçuk Candan, Alexandros Labrinidis, Assaf Schuster, and Haixun Wang, editors,Proceedings of the...
-
[29]
Chris J.C. Burges. From RankNet to LambdaRank to LambdaMART: An overview. Technical Report MSR-TR-2010-82, Microsoft Research, June
2010
-
[30]
URL https://www.microsoft.com/en-us/research/publication/ from-ranknet-to-lambdarank-to-lambdamart-an-overview/
-
[31]
Swipealot: Multimodal swipe keyboard transformer, 2025
David Lee Miller. Swipealot: Multimodal swipe keyboard transformer, 2025. URL https:// huggingface.co/dleemiller/SwipeALot-base
2025
-
[32]
swipe-negatives: Hard negatives for english swipe decoding, 2026
FUTO. swipe-negatives: Hard negatives for english swipe decoding, 2026. https:// huggingface.co/datasets/futo-org/swipe-negatives. 17 FUTO Swipe Technical Report
2026
-
[33]
CR-CTC: consistency regularization on CTC for improved speech recognition
Zengwei Yao, Wei Kang, Xiaoyu Yang, Fangjun Kuang, Liyong Guo, Han Zhu, Zengrui Jin, Zhaoqing Li, Long Lin, and Daniel Povey. CR-CTC: consistency regularization on CTC for improved speech recognition. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview...
2025
-
[34]
S im CSE : Simple Contrastive Learning of Sentence Embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple contrastive learning of sen- tence embeddings. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen- tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894–6910, Online and Punta Cana, Dominican Republic, November 2021. As...
-
[35]
Xiangning Chen, Chen Liang, Da Huang, Esteban Real, Kaiyuan Wang, Hieu Pham, Xuanyi Dong, Thang Luong, Cho-Jui Hsieh, Yifeng Lu, and Quoc V. Le. Symbolic discovery of optimization algorithms. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conf...
2023
-
[36]
Tyers, and Gregor Weber
Rosana Ardila, Megan Branson, Kelly Davis, Michael Kohler, Josh Meyer, Michael Henretty, Reuben Morais, Lindsay Saunders, Francis M. Tyers, and Gregor Weber. Common voice: A massively- multilingual speech corpus. In Nicoletta Calzolari, Frédéric Béchet, Philippe Blache, Khalid Choukri, Christopher Cieri, Thierry Declerck, Sara Goggi, Hitoshi Isahara, Bent...
2020
-
[37]
FUTO Keyboard for Android, 2026
FUTO. FUTO Keyboard for Android, 2026. https://github.com/futo-org/ android-keyboard
2026
-
[38]
Shumin Zhai, Michael A. Hunter, and Barton A. Smith. Performance optimization of virtual keyboards.Hum. Comput. Interact., 17(2-3):229–269, 2002. doi: 10.1080/07370024.2002.9667315. URLhttps://doi.org/10.1080/07370024.2002.9667315
-
[39]
T Flash and N Hogan. The coordination of arm movements: an experimentally confirmed math- ematical model.Journal of Neuroscience, 5(7):1688–1703, 1985. ISSN 0270-6474. doi: 10.1523/ JNEUROSCI.05-07-01688.1985. URLhttps://www.jneurosci.org/content/5/7/1688
arXiv 1985
-
[40]
Modeling human performance of pen stroke gestures
Xiang Cao and Shumin Zhai. Modeling human performance of pen stroke gestures. In Mary Beth Rosson and David J. Gilmore, editors,Proceedings of the 2007 Conference on Human Factors in Computing Systems, CHI 2007, San Jose, California, USA, April 28 - May 3, 2007, pages 1495–
2007
-
[41]
ACM, 2007. doi: 10.1145/1240624.1240850. URL https://doi.org/10.1145/1240624. 1240850
-
[42]
Word clarity as a metric in sampling keyboard test sets
Xin Yi, Chun Yu, Weinan Shi, Xiaojun Bi, and Yuanchun Shi. Word clarity as a metric in sampling keyboard test sets. In Gloria Mark, Susan R. Fussell, Cliff Lampe, m. c. schraefel, Juan Pablo Hourcade, Caroline Appert, and Daniel Wigdor, editors,Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, May 06-11, 2017, ...
2017
-
[43]
URLhttps://doi.org/10.1145/3025453.3025701
doi: 10.1145/3025453.3025701. URLhttps://doi.org/10.1145/3025453.3025701
-
[44]
Variational connectionist temporal classification
Linlin Chao, Jingdong Chen, and Wei Chu. Variational connectionist temporal classification. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors,Computer Vision - 18 FUTO Swipe Technical Report ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XXVIII, Lecture Notes in Computer Science, pages ...
-
[45]
URLhttps://doi.org/10.1007/978-3-030-58604-1_28
-
[46]
Ehsan Variani, David Rybach, Cyril Allauzen, and Michael Riley. Hybrid autoregressive transducer (HAT). In2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, May 4-8, 2020, pages 6139–6143. IEEE, 2020. doi: 10.1109/ICASSP40776. 2020.9053600. URLhttps://doi.org/10.1109/ICASSP40776.2020.9053600. A Ef...
-
[47]
Skipped per-sample for layouts with more than three rows (Indic scripts) to avoid violating row geometry
Y-scale.A per-sample scale sy ∼ U(0.75,1.0) contracts the y axis around y=0.5. Skipped per-sample for layouts with more than three rows (Indic scripts) to avoid violating row geometry
-
[48]
Simulates layouts whose keys-per-row count differs from the training layout, producing narrower or wider key cells
X-scale.An independent per-sample scale sx ∼ U(0.85,1.0) contracts the x axis around x=0.5. Simulates layouts whose keys-per-row count differs from the training layout, producing narrower or wider key cells. 20 FUTO Swipe Technical Report
-
[49]
Breaks the prior that keys lie on a strictly orthogonal grid
Shear.Two independent per-sample shear factors sxy, syx ∼ U(−0.05,0.05) apply a small affine skew: x′ =x+s xy(y−0.5) then y′ =y+s yx(x′ −0.5) . Breaks the prior that keys lie on a strictly orthogonal grid. 4.Flips.Independent Bernoulli(0.5)flips along each axis
-
[50]
If the rotated content would overflow the unit square the rotation is rejected for that sample (the pre-rotation state is kept)
Rotation.A per-sample angle θ∼ U[0,2π) rotates trajectory and keys around the trajectory’s centroid. If the rotated content would overflow the unit square the rotation is rejected for that sample (the pre-rotation state is kept)
-
[51]
Translation.A bounded shift moves the combined bounding box of the trajectory and the masked key positions to a random valid origin inside[0,1] 2
-
[52]
Time reversal.With probability 0.1 the temporal axis of the trajectory is reversed, and the target word is also reversed so the CTC label sequence stays aligned. Geometric stages 1–6 are applied identically to the trajectory tensor [B,2, T] and to the training- time layout-key tensor [B, K,4] , where the two extra columns are the key half-radii (rx, ry) u...
arXiv 2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.