From Sounds to Scenes: A Benchmark for Evaluating Context-Aware Auditory Scene Understanding in Large Audio Language Models
Pith reviewed 2026-06-25 20:34 UTC · model grok-4.3
The pith
Large audio language models require integrating speech, sound events, and backgrounds to understand real auditory scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that effective auditory scene understanding requires integration over all auditory layers, rather than reliance on speech or sound alone, and introduces the CASU benchmark with semi-synthetic data construction and specific tasks to demonstrate this requirement in large audio language models.
What carries the argument
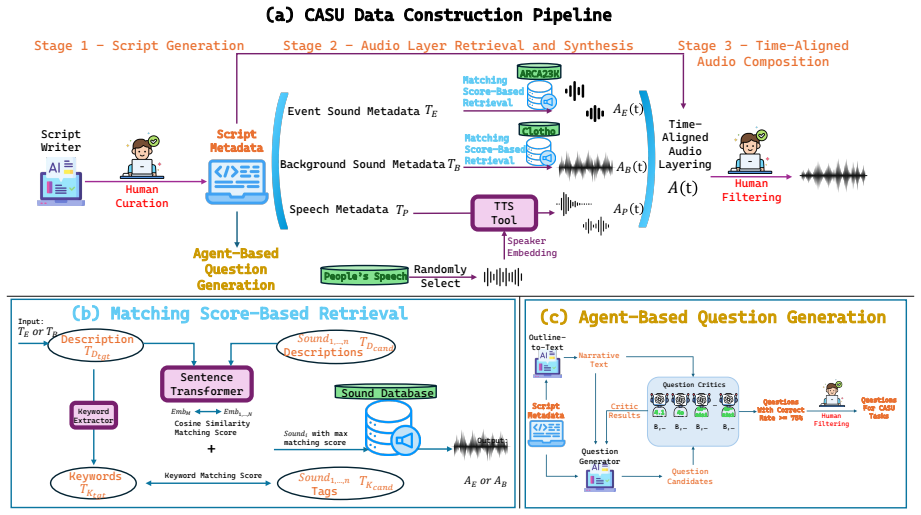
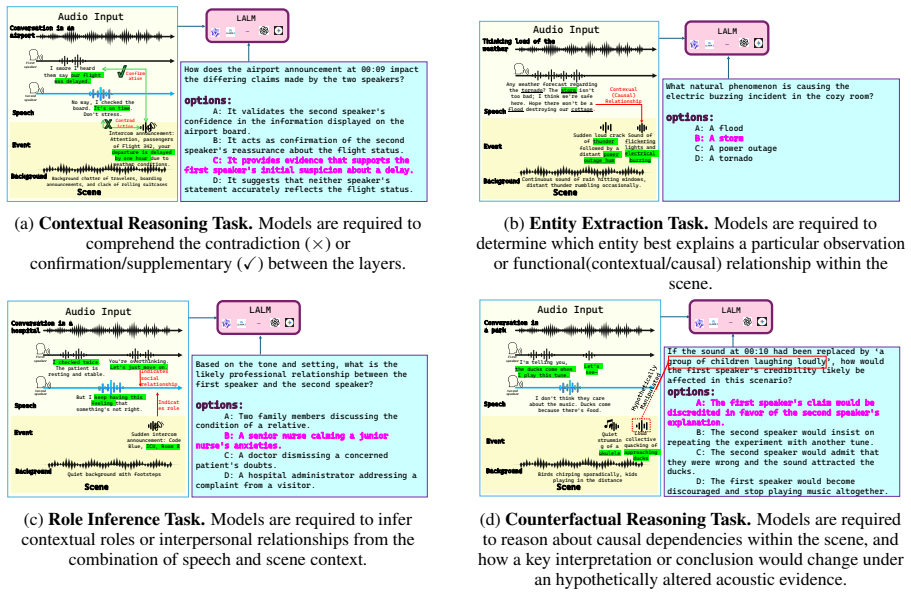
The CASU benchmark consisting of a scalable pipeline for time-accurate semi-synthetic audio streams and four probing tasks: contextual question answering, entity extraction from the scene, speaker role inference, and counterfactual reasoning.
If this is right
- Models relying on isolated layers will fail at holistic scene interpretation.
- The benchmark can guide development of more capable audio understanding systems.
- Integration of all sound sources is necessary for advancing complex audio tasks in language models.
- Semi-synthetic construction enables controlled testing of contextual relationships.
Where Pith is reading between the lines
- This suggests potential improvements in applications like smart assistants that interpret conversations amid noise.
- The method could extend to evaluating multimodal models involving audio and visual context.
- Future work might test whether human-like scene understanding emerges only with full layer integration.
Load-bearing premise
Semi-synthetic audio streams created by composing real-world scene sounds with synthetic speech accurately capture the complex contextual relationships present in real-world auditory scenes.
What would settle it
If models show equivalent performance on tasks using only speech or only sounds compared to full scenes in real recordings, the necessity of full integration would be challenged.
Figures

read the original abstract
Recent Large Audio Language Models (LALMs) have achieved remarkable progress in audio perceptual tasks across individual acoustic layers, including speech, sound, and music. However, existing benchmarks predominantly evaluate these layers in isolation, overlooking the complex contextual relationships that arise when multiple acoustic sources co-occur in real-world auditory scenes. Real-world auditory interpretation requires Context-Aware Auditory Scene Understanding (CASU): the ability to comprehend the holistic scene by integrating sound layers. To evaluate this capability, we introduce the CASU benchmark, which assesses whether Audio LLMs can interpret auditory scenes composed of speech, acoustic events (e.g., announcements), and background environments (e.g., traffic), and reason about the logical relationships between these layers. We propose a scalable pipeline for constructing time-accurate, semi-synthetic audio streams by composing real-world scene sounds with synthetic speech. Building on this data, we design four tasks that probe scene understanding: contextual question answering, entity extraction from the scene, speaker role inference, and counterfactual reasoning where scene is manipulated. Experiments across multiple LALMs demonstrate that effective auditory scene understanding requires integration over all auditory layers, rather than reliance on speech or sound alone, underscoring the necessity of CASU for advancing complex audio understanding in LALMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the CASU benchmark to assess Large Audio Language Models (LALMs) on context-aware auditory scene understanding, which requires integrating speech, acoustic events, and background environments in holistic scenes. It describes a scalable pipeline for time-aligned semi-synthetic audio streams formed by overlaying real-world scene sounds with synthetic speech, and defines four tasks (contextual question answering, entity extraction, speaker role inference, and counterfactual reasoning) to probe logical relationships across layers. Experiments on multiple LALMs are reported to show that restricting models to speech or sound subsets degrades performance, supporting the claim that effective scene understanding necessitates cross-layer integration rather than isolated processing.
Significance. If the benchmark construction and task results hold, the work would provide a useful new evaluation framework that highlights limitations in current LALMs for complex, multi-source audio scenes and could encourage development of models with stronger contextual integration. The scalable pipeline and the four probing tasks represent concrete contributions to audio AI evaluation.
major comments (1)
- [Abstract, pipeline paragraph] Abstract, paragraph on pipeline: the semi-synthetic construction composes real-world scene sounds with independently generated synthetic speech that is time-aligned but does not describe any mechanism (e.g., metadata-driven semantic constraints or cross-layer conditioning) to ensure that speech content is logically dependent on the acoustic events or environment. Without such verification, the performance gaps on the four tasks could arise from mismatch with the artificial overlay rather than from an absence of integration capability in the models, directly affecting the central claim that the results demonstrate the necessity of CASU.
minor comments (1)
- [Abstract] The abstract provides no quantitative results, error analysis, or baseline comparisons; the full manuscript should include these to allow assessment of effect sizes and task difficulty.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract, pipeline paragraph] Abstract, paragraph on pipeline: the semi-synthetic construction composes real-world scene sounds with independently generated synthetic speech that is time-aligned but does not describe any mechanism (e.g., metadata-driven semantic constraints or cross-layer conditioning) to ensure that speech content is logically dependent on the acoustic events or environment. Without such verification, the performance gaps on the four tasks could arise from mismatch with the artificial overlay rather than from an absence of integration capability in the models, directly affecting the central claim that the results demonstrate the necessity of CASU.
Authors: We agree that the current manuscript description does not explicitly detail mechanisms ensuring logical dependence between the synthetic speech content and the overlaid acoustic events or environments. This is a valid concern that could affect interpretation of the performance gaps. In the revised manuscript we will expand the pipeline section with (1) explicit metadata-driven semantic constraints used during speech synthesis (e.g., conditioning on scene type, event labels, and temporal alignment), (2) concrete examples of generated speech-scene pairs demonstrating contextual relevance, and (3) a verification procedure (human annotation of logical consistency) applied to the benchmark. These additions will directly support the claim that observed integration effects reflect model capabilities rather than construction artifacts. revision: yes
Circularity Check
No circularity: benchmark construction paper with independent experimental evaluation
full rationale
The paper constructs a new benchmark (CASU) via a described pipeline for semi-synthetic audio and evaluates LALMs on four tasks. No equations, fitted parameters, or predictions appear that reduce to prior inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing. The central claim rests on comparative model performance across full vs. restricted audio layers, which is externally falsifiable via the released benchmark rather than self-referential. This matches the default expectation for non-circular benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Audio Flamingo 3: Advancing Audio Intelligence with Fully Open Large Audio Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[2]
International Conference on Machine Learning , pages=
Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[3]
Forty-second International Conference on Machine Learning , year=
Audio Flamingo 2: An Audio-Language Model with Long-Audio Understanding and Expert Reasoning Abilities , author=. Forty-second International Conference on Machine Learning , year=
-
[4]
2025 , url=
Qingkai Fang and Shoutao Guo and Yan Zhou and Zhengrui Ma and Shaolei Zhang and Yang Feng , booktitle=. 2025 , url=
2025
-
[5]
arXiv preprint arXiv:2509.17765 , year=
Qwen3-Omni Technical Report , author=. arXiv preprint arXiv:2509.17765 , year=
-
[6]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[7]
arXiv preprint arXiv:2503.20215 , year=
Qwen2.5-Omni Technical Report , author=. arXiv preprint arXiv:2503.20215 , year=
-
[8]
ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Urban sound & sight: Dataset and benchmark for audio-visual urban scene understanding , author=. ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2022 , organization=
2022
-
[9]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Dynamic-superb: Towards a dynamic, collaborative, and comprehensive instruction-tuning benchmark for speech , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[10]
Audiobench: A universal benchmark for audio large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[11]
arXiv preprint arXiv:2402.07729 , year=
Air-bench: Benchmarking large audio-language models via generative comprehension , author=. arXiv preprint arXiv:2402.07729 , year=
-
[12]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Mustango: Toward controllable text-to-music generation , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[13]
arXiv preprint arXiv:2310.08753 , year=
Compa: Addressing the gap in compositional reasoning in audio-language models , author=. arXiv preprint arXiv:2310.08753 , year=
-
[14]
Multimedia Systems , volume=
Context-based environmental audio event recognition for scene understanding , author=. Multimedia Systems , volume=. 2015 , publisher=
2015
-
[15]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Crab: A unified audio-visual scene understanding model with explicit cooperation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[16]
arXiv preprint arXiv:2407.10759 , year=
Qwen2-Audio Technical Report , author=. arXiv preprint arXiv:2407.10759 , year=
-
[17]
The Twelfth International Conference on Learning Representations , year=
SALMONN: Towards Generic Hearing Abilities for Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[18]
arXiv preprint arXiv:2507.13264 , year=
Voxtral , author=. arXiv preprint arXiv:2507.13264 , year=
-
[19]
2023 , booktitle=
Joint Audio and Speech Understanding , author=. 2023 , booktitle=
2023
-
[20]
arXiv preprint arXiv:2305.10790 , year=
Listen, Think, and Understand , author=. arXiv preprint arXiv:2305.10790 , year=
-
[21]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[22]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[23]
Evaluating Robustness of Large Audio Language Models to Audio Injection: An Empirical Study
Hou, Guanyu and He, Jiaming and Zhou, Yinhang and Guo, Ji and Qiao, Yitong and Zhang, Rui and Jiang, Wenbo. Evaluating Robustness of Large Audio Language Models to Audio Injection: An Empirical Study. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1303
-
[24]
arXiv preprint arXiv:2505.15957 , year=
Towards holistic evaluation of large audio-language models: A comprehensive survey , author=. arXiv preprint arXiv:2505.15957 , year=
-
[25]
arXiv preprint arXiv:2410.19168 , year=
Mmau: A massive multi-task audio understanding and reasoning benchmark , author=. arXiv preprint arXiv:2410.19168 , year=
-
[26]
arXiv preprint arXiv:2505.13032 , year=
MMAR: A Challenging Benchmark for Deep Reasoning in Speech, Audio, Music, and Their Mix , author=. arXiv preprint arXiv:2505.13032 , year=
-
[27]
arXiv preprint arXiv:2506.04779 , year=
MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark , author=. arXiv preprint arXiv:2506.04779 , year=
-
[28]
arXiv preprint arXiv:2508.13992 , year=
Mmau-pro: A challenging and comprehensive benchmark for holistic evaluation of audio general intelligence , author=. arXiv preprint arXiv:2508.13992 , year=
-
[29]
arXiv preprint arXiv:2505.13237 , year=
Sakura: On the multi-hop reasoning of large audio-language models based on speech and audio information , author=. arXiv preprint arXiv:2505.13237 , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Sd-eval: A benchmark dataset for spoken dialogue understanding beyond words , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
and Cao, Y
Iqbal, T. and Cao, Y. and Bailey, A. and Plumbley, M. D. and Wang, W. , title =. Proceedings of the Detection and Classification of Acoustic Scenes and Events 2021 Workshop (DCASE2021) , pages =. 2021 , address =
2021
-
[32]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Clotho: An audio captioning dataset , author=. ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2020 , organization=
2020
-
[34]
arXiv preprint arXiv:2111.09344 , year=
The people's speech: A large-scale diverse english speech recognition dataset for commercial usage , author=. arXiv preprint arXiv:2111.09344 , year=
-
[35]
arXiv preprint arXiv:1908.10084 , year=
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. arXiv preprint arXiv:1908.10084 , year=
Pith/arXiv arXiv 1908
-
[36]
Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
Bleu: a method for automatic evaluation of machine translation , author=. Proceedings of the 40th annual meeting of the Association for Computational Linguistics , pages=
-
[37]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[38]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Word error rate estimation for speech recognition: e-WER , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=. 2018 , organization=
2018
-
[39]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.