Evaluating Japanese Dialect Robustness Across Speech and Text-based Large Language Models
Pith reviewed 2026-06-25 20:06 UTC · model grok-4.3
The pith
Speech language models' dialect robustness correlates with their text LLM counterparts and improves with dialect training and encoder fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
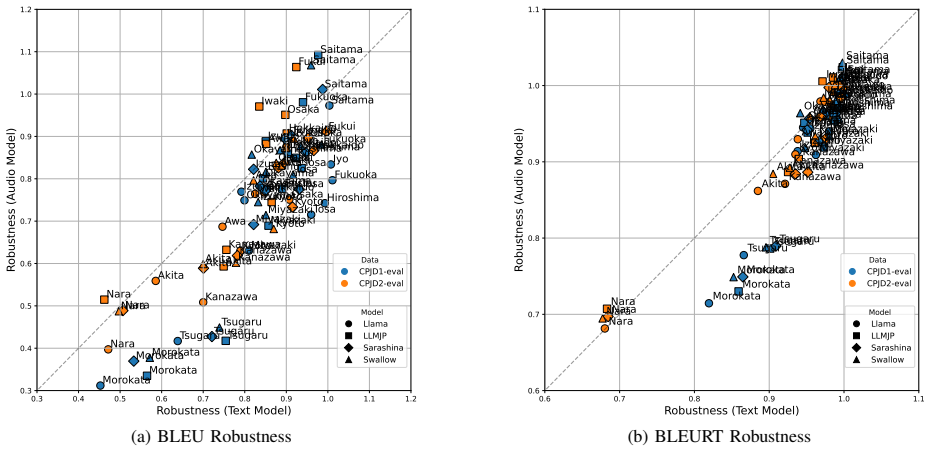
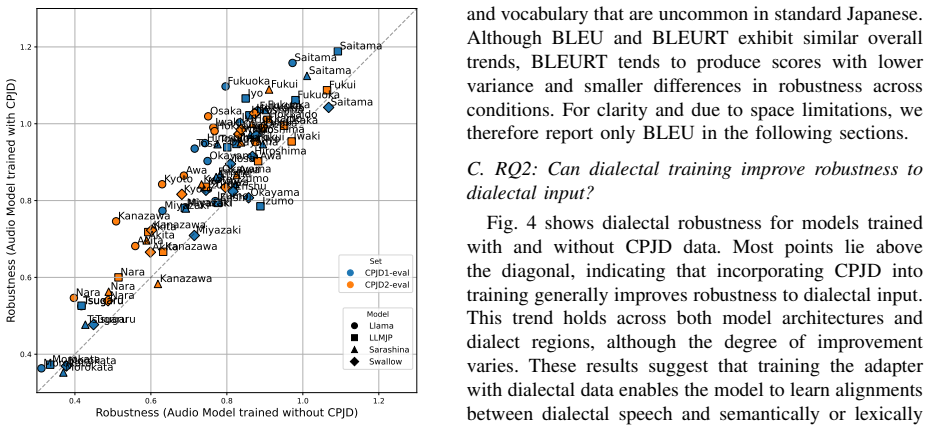
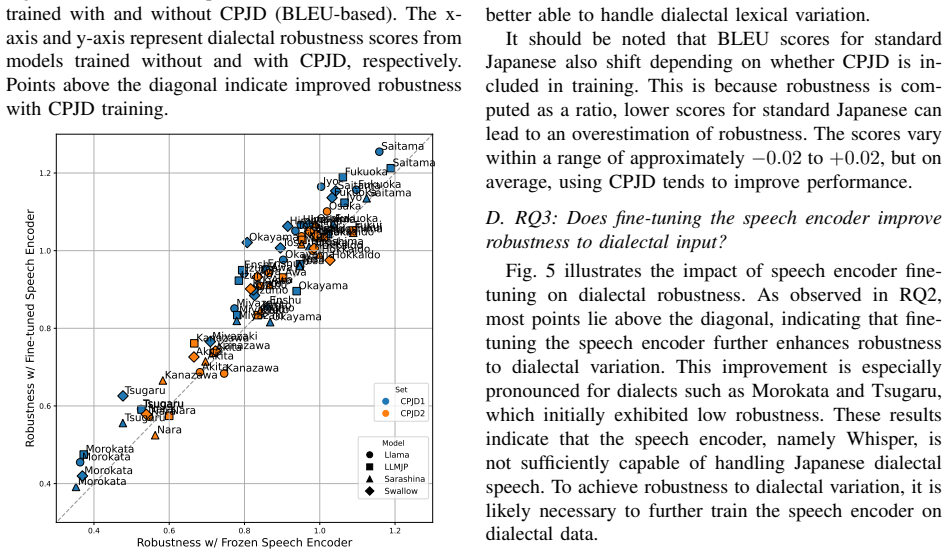
Our experiments show that SLM robustness correlates with that of their text-based counterparts. Furthermore, training with dialectal data and fine-tuning the speech encoder each improves robustness in SLMs, where robustness is defined as the ratio of performance on dialectal versus standard inputs using Japanese dialects as the test case.
What carries the argument
The ratio of performance on dialectal versus standard inputs, used as the definition of robustness for comparing LLMs and SLMs on Japanese dialect tasks.
If this is right
- SLM robustness can be inferred from the base text LLM's robustness without separate speech testing.
- Adding dialectal data during training raises SLM performance on dialect inputs relative to standard ones.
- Fine-tuning only the speech encoder component yields measurable robustness gains for spoken dialect inputs.
- The performance-ratio metric enables direct comparison of dialect handling across text and speech models.
Where Pith is reading between the lines
- Selecting a base LLM already strong on text dialects would likely produce a more robust SLM without additional speech-specific work.
- The observed correlation implies that most dialect difficulties reside in the language model core rather than the speech front-end.
- If the correlation pattern appears in other languages, the same training and fine-tuning steps could transfer.
- System builders could screen candidate base models on text dialect benchmarks before building the speech version.
Load-bearing premise
The ratio of performance on dialectal versus standard inputs constitutes a fair and sufficient definition of robustness, and the selected Japanese dialects, tasks, and models are representative enough for the correlation and improvement claims to generalize.
What would settle it
Finding an SLM whose dialect robustness does not track its text LLM counterpart, or showing that dialectal training and speech-encoder fine-tuning produce no gain on held-out dialect test sets.
Figures

read the original abstract
Dialogue systems based on large language models (LLMs) have advanced significantly in recent years. However, dialectal variation remains a major challenge, particularly for systems that process spoken input. LLM-based speech language models (SLMs), which integrate LLMs with speech processing components, show promise for spoken language tasks, yet their ability to comprehend dialects has not been sufficiently studied. Moreover, it remains unclear how the dialectal understanding of the base LLM affects SLM performance. This study investigates the dialectal robustness of both LLMs and SLMs using Japanese dialects as a test case. We define robustness as the ratio of performance on dialectal versus standard inputs, enabling fair comparisons. Our experiments show that SLM robustness correlates with that of their text-based counterparts. Furthermore, training with dialectal data and fine-tuning the speech encoder each improves robustness in SLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates dialectal robustness in Japanese LLMs and SLMs, defining robustness as the ratio of model performance on dialectal versus standard (standard Japanese) inputs. Experiments demonstrate a correlation between the robustness of SLMs and their text-based LLM counterparts. Additional results indicate that training on dialectal data and fine-tuning the speech encoder each improve robustness metrics in SLMs.
Significance. If the empirical patterns hold under a more robust metric and with representative sampling, the work would provide useful evidence on modality transfer of dialectal understanding and practical levers (dialectal training, encoder fine-tuning) for improving spoken dialogue systems. The ratio-based framing allows cross-model comparison but requires validation that it isolates generalization rather than baseline effects.
major comments (1)
- [Abstract and Results] The central claims (correlation between SLM and LLM robustness; gains from dialectal training and encoder fine-tuning) rest on defining robustness exclusively as the performance ratio (dialectal/standard). This ratio is only interpretable for generalization if standard-input performance is stable, high, and non-interacting with dialect effects across models. The manuscript should report absolute accuracies on standard inputs (with error bars) and test whether the ratio masks absolute performance drops or baseline variation; without these, the correlation and improvement claims risk being metric artifacts. (See abstract and results sections describing the ratio definition and reported correlations.)
minor comments (1)
- [Abstract] The abstract states the central findings but omits dataset sizes, number of dialects/tasks, model families, statistical tests, and controls; these details should be summarized early for readers.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestion regarding the robustness metric. We address the major comment point-by-point below.
read point-by-point responses
-
Referee: [Abstract and Results] The central claims (correlation between SLM and LLM robustness; gains from dialectal training and encoder fine-tuning) rest on defining robustness exclusively as the performance ratio (dialectal/standard). This ratio is only interpretable for generalization if standard-input performance is stable, high, and non-interacting with dialect effects across models. The manuscript should report absolute accuracies on standard inputs (with error bars) and test whether the ratio masks absolute performance drops or baseline variation; without these, the correlation and improvement claims risk being metric artifacts. (See abstract and results sections describing the ratio definition and reported correlations.)
Authors: We agree that absolute accuracies on standard inputs provide valuable context. In the revised manuscript we will add a table (or supplementary figure) reporting absolute performance on standard Japanese inputs for every model, with error bars from repeated runs where available. We will also include a brief analysis checking for interactions between baseline performance and dialect effects. The ratio definition was selected to normalize for inherent differences in model capability on standard inputs and thereby enable fair cross-model comparisons of relative robustness; the observed correlation between SLM and LLM robustness, as well as the gains from dialectal training and encoder fine-tuning, remain consistent under this normalization. We will make these additions without altering the core claims. revision: yes
Circularity Check
No circularity: empirical ratios and measured effects are reported directly from data
full rationale
The paper is an empirical evaluation study. It explicitly defines robustness as the performance ratio (dialectal/standard) and reports measured correlations plus training effects without any derivation chain, equations, or self-citations that reduce the central claims to fitted parameters or prior results by construction. The claims rest on experimental outcomes rather than self-referential logic, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Performance ratio between dialectal and standard inputs is a sufficient and fair measure of dialectal robustness.
Reference graph
Works this paper leans on
-
[1]
Qwen, :, A. Yang, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Li, D. Liu, F. Huang, H. Weiet al., “Qwen2.5 Technical Report,”arXiv:2412.15115, 2025
Pith/arXiv arXiv 2025
-
[2]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadianet al., “The Llama 3 Herd of Models,”arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[3]
DeepSeek-AI, A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhanget al., “DeepSeek-V3 Technical Report,”arXiv:2412.19437, 2024
Pith/arXiv arXiv 2024
-
[4]
OpenAI, J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidtet al., “GPT-4 Technical Report,”arXiv:2303.08774, 2024
Pith/arXiv arXiv 2024
-
[5]
R. Anil, A. M. Dai, O. Firat, M. Johnson, D. Lepikhin, A. Passos, S. Shakeri, E. Taropa, P. Bailey, Z. Chenet al., “PaLM 2 Technical Report,”arXiv:2305.10403, 2023
Pith/arXiv arXiv 2023
-
[6]
F. Lin, S. Mao, E. L. Malfa, V . Hofmann, A. de Wynter, X. Wang, S.-Q. Chen, M. Wooldridge, J. B. Pierrehumbert, and F. Wei, “One Language, Many Gaps: Evaluating Dialect Fairness and Robustness of Large Language Models in Reasoning Tasks,” arXiv:2410.11005, 2025
arXiv 2025
-
[7]
Assessing Thai Di- alect Performance in LLMs with Automatic Benchmarks and Human Evaluation,
P. Limkonchotiwat, K. Masuk, S. Nonesung, C. Mai-On, S. Nu- tanong, W. Ponwitayarat, and P. Manakul, “Assessing Thai Di- alect Performance in LLMs with Automatic Benchmarks and Human Evaluation,”arXiv:2504.05898, 2025
arXiv 2025
-
[8]
Can LLMs Handle Low-Resource Dialects? A Case Study on Translation and Common Sense Reasoning in ˇSariˇs,
V . Ondrejov´a and M. ˇSuppa, “Can LLMs Handle Low-Resource Dialects? A Case Study on Translation and Common Sense Reasoning in ˇSariˇs,” inProceedings of the Eleventh Workshop on NLP for Similar Languages, Varieties, and Dialects (VarDial 2024), 2024, pp. 130–139
2024
-
[9]
AudioPaLM: A Large Language Model That Can Speak and Listen,
P. K. Rubenstein, C. Asawaroengchai, D. D. Nguyen, A. Bapna, Z. Borsoset al., “AudioPaLM: A Large Language Model That Can Speak and Listen,”arXiv:2306.12925, 2023
Pith/arXiv arXiv 2023
-
[10]
Qwen-Audio: Advancing Universal Audio Un- derstanding via Unified Large-Scale Audio-Language Models,
Y . Chu, J. Xu, X. Zhou, Q. Yang, S. Zhang, Z. Yan, C. Zhou, and J. Zhou, “Qwen-Audio: Advancing Universal Audio Un- derstanding via Unified Large-Scale Audio-Language Models,” arXiv:2311.07919, 2023
Pith/arXiv arXiv 2023
-
[11]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-Audio Technical Report,”arXiv:2407.10759, 2024
Pith/arXiv arXiv 2024
-
[12]
Dialect-to-Standard Normalization: A Large-Scale Multilingual Evaluation,
O. Kuparinen, A. Mileti ´c, and Y . Scherrer, “Dialect-to-Standard Normalization: A Large-Scale Multilingual Evaluation,” inFind- ings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 13 814–13 828
2023
-
[13]
Multi-dialect Neural Machine Translation and Dialectometry,
K. Abe, Y . Matsubayashi, N. Okazaki, and K. Inui, “Multi-dialect Neural Machine Translation and Dialectometry,” inProceedings of the 32nd Pacific Asia Conference on Language, Information and Computation, 2018
2018
-
[14]
Building Parallel Monolingual Gan Chinese Dialects Corpus,
F. Xu, M. Wang, and M. Li, “Building Parallel Monolingual Gan Chinese Dialects Corpus,” inProceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), 2018
2018
-
[15]
Dialect Speech Recognition Modeling using Corpus of Japanese Dialects and Self-Supervised Learning- based Model XLSR,
S. Miwa and A. Kai, “Dialect Speech Recognition Modeling using Corpus of Japanese Dialects and Self-Supervised Learning- based Model XLSR,” inProceedings of Interspeech 2023, 2023, pp. 4928–4932
2023
-
[16]
Dialect Transfer for Swiss German Speech Translation,
C. Paonessa, Y . Schraner, J. Deriu, M. H ¨urlimann, M. V ogel, and M. Cieliebak, “Dialect Transfer for Swiss German Speech Translation,” inFindings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 15 240–15 254
2023
-
[17]
BanglaDialecto: An End-to-End AI-Powered Regional Speech Standardization ,
M. N. Sadat Samin, J. Ibn Ahad, T. A. Medha, F. Rahman, M. R. Amin, N. Mohammed, and S. Rahman, “ BanglaDialecto: An End-to-End AI-Powered Regional Speech Standardization ,” in2024 IEEE International Conference on Big Data (BigData), 2024, pp. 1635–1644
2024
-
[18]
BLEU: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “BLEU: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 2002, p. 311–318
2002
-
[19]
BLEURT: Learning Robust Metrics for Text Generation,
T. Sellam, D. Das, and A. Parikh, “BLEURT: Learning Robust Metrics for Text Generation,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020, pp. 7881–7892
2020
-
[20]
LoRA: Low-Rank Adaptation of Large Language Models,
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “LoRA: Low-Rank Adaptation of Large Language Models,” inProceedings of the International Confer- ence on Learning Representations, 2022
2022
-
[21]
Integrating Pre-Trained Speech and Language Mod- els for End-to-End Speech Recognition,
Y . Hono, K. Mitsuda, T. Zhao, K. Mitsui, T. Wakatsuki, and K. Sawada, “Integrating Pre-Trained Speech and Language Mod- els for End-to-End Speech Recognition,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024, pp. 13 289–13 305
2024
-
[22]
Prompting Large Language Models with Speech Recognition Abilities,
Y . Fathullah, C. Wu, E. Lakomkin, J. Jia, Y . Shangguan, K. Li, J. Guo, W. Xiong, J. Mahadeokar, O. Kalinli, C. Fuegen, and M. Seltzer, “Prompting Large Language Models with Speech Recognition Abilities,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2024, pp. 13 351–13 355
2024
-
[23]
End-to-End Speech Recognition Contextualization with Large Language Models,
E. Lakomkin, C. Wu, Y . Fathullah, O. Kalinli, M. L. Seltzer, and C. Fuegen, “End-to-End Speech Recognition Contextualization with Large Language Models,” inProceedings of the IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 12 406–12 410
2024
-
[24]
ReazonSpeech: A free and massive corpus for Japanese ASR,
Y . Yin, D. Mori, and S. Fujimoto, “ReazonSpeech: A free and massive corpus for Japanese ASR,” inProceedings of the 29th Annual Meeting of the Association for Natural Language Processing (Domestic Conference), 2023, pp. 1134–1139
2023
-
[25]
Towards Speech Dialogue Translation Mediating Speakers of Different Lan- guages,
S. Shimizu, C. Chu, S. Li, and S. Kurohashi, “Towards Speech Dialogue Translation Mediating Speakers of Different Lan- guages,” inFindings of the Association for Computational Lin- guistics: ACL 2023, 2023, pp. 1122–1134
2023
-
[26]
CoV oST 2: A Massively Mul- tilingual Speech-to-Text Translation Corpus,
C. Wang, A. Wu, and J. Pino, “CoV oST 2: A Massively Mul- tilingual Speech-to-Text Translation Corpus,”arXiv:2007.10310, 2020
arXiv 2007
-
[27]
CPJD Corpus: Crowdsourced Parallel Speech Corpus of Japanese Dialects,
S. Takamichi and H. Saruwatari, “CPJD Corpus: Crowdsourced Parallel Speech Corpus of Japanese Dialects,” inProceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), 2018
2018
-
[28]
Building a Large Japanese Web Corpus for Large Language Models,
N. Okazaki, K. Hattori, H. Shota, H. Iida, M. Ohi, K. Fujii, T. Nakamura, M. Loem, R. Yokota, and S. Mizuki, “Building a Large Japanese Web Corpus for Large Language Models,” inProceedings of the First Conference on Language Modeling, 2024
2024
-
[29]
Continual pre-training for cross-lingual llm adaptation: Enhancing japanese language capabilities,
K. Fujii, T. Nakamura, M. Loem, H. Iida, M. Ohi, K. Hattori, H. Shota, S. Mizuki, R. Yokota, and N. Okazaki, “Continual pre-training for cross-lingual llm adaptation: Enhancing japanese language capabilities,” inProceedings of the First Conference on Language Modeling, 2024
2024
-
[30]
Robust Speech Recognition via Large-Scale Weak Supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust Speech Recognition via Large-Scale Weak Supervision,”arXiv:2212.04356, 2022
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.