Towards Robust EEG Decoding Based on Riemannian Self-Attention
Pith reviewed 2026-06-25 21:33 UTC · model grok-4.3
The pith
A Riemannian self-attention network on the Bures-Wasserstein metric improves robustness of EEG decoding for brain-computer interfaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
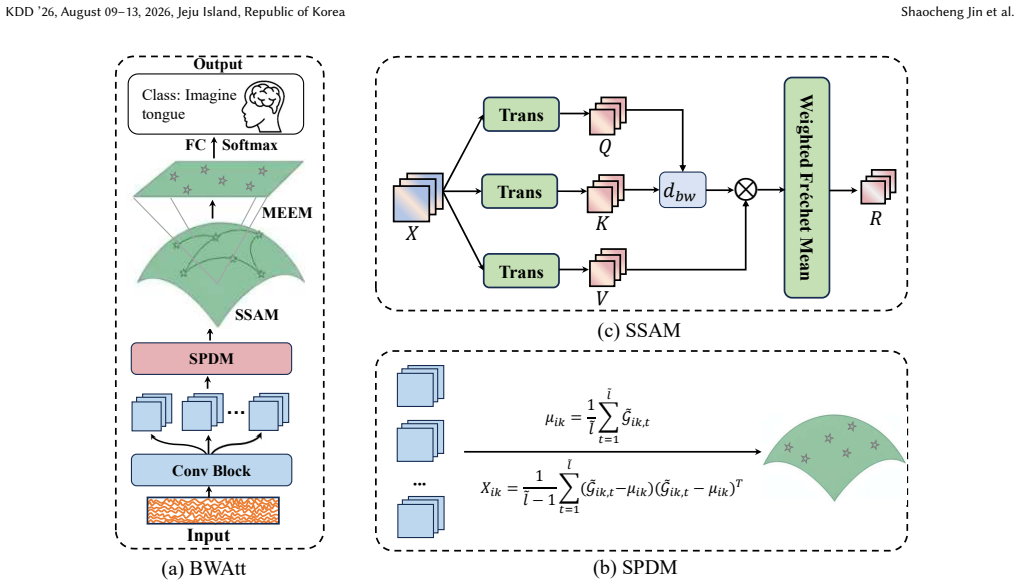
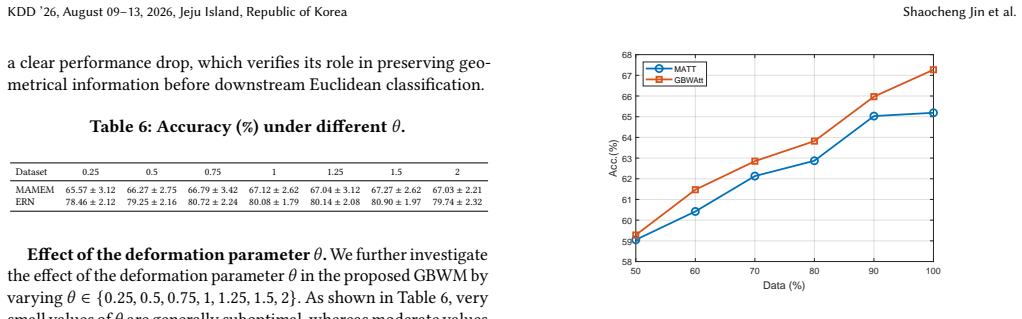
We propose a Riemannian self-attention network based on the Bures-Wasserstein metric for SPD learning in EEG decoding. We further extend it to a learnable power-deformed generalized Bures-Wasserstein version called GBWAtt to provide a more nuanced representation of the SPD manifold. This overcomes limitations of basic architectures that fail to capture local signal relationships and of the affine-invariant metric that has quadratic dependency and issues with ill-conditioned matrices.
What carries the argument
The Bures-Wasserstein metric (BWM) and its power-deformed generalized form (GBW) within a self-attention network, which provides linear dependence on SPD matrices and enables learnable geometric structure for EEG covariance matrices.
If this is right
- The network can handle ill-conditioned SPD matrices arising from low-SNR EEG without breakdown.
- Local relationships between EEG signals are explicitly modeled via self-attention on the manifold.
- Decoding performance improves across multiple benchmarking datasets for BCI tasks.
- Learnable metric deformation allows adaptation to the specific geometric properties of the data.
Where Pith is reading between the lines
- If the metric choice proves superior, it may encourage broader adoption of the Bures-Wasserstein metric in other manifold learning tasks involving noisy covariance data.
- The learnable extension suggests that metric parameters could be optimized jointly with the network for subject-specific EEG patterns.
- This architecture might inspire similar attention mechanisms on other Riemannian manifolds used in signal processing.
Load-bearing premise
The Bures-Wasserstein metric supplies a superior geometric representation of SPD matrices for low-SNR EEG signals compared with the affine-invariant metric, and the added self-attention layer meaningfully captures local signal relationships that basic architectures miss.
What would settle it
A direct comparison showing no improvement in accuracy or robustness when replacing the affine-invariant metric with the Bures-Wasserstein metric inside the self-attention architecture on the three EEG benchmarking datasets would falsify the central claim.
Figures
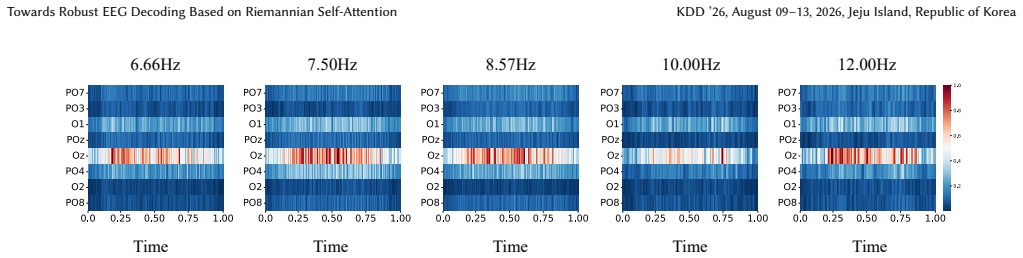

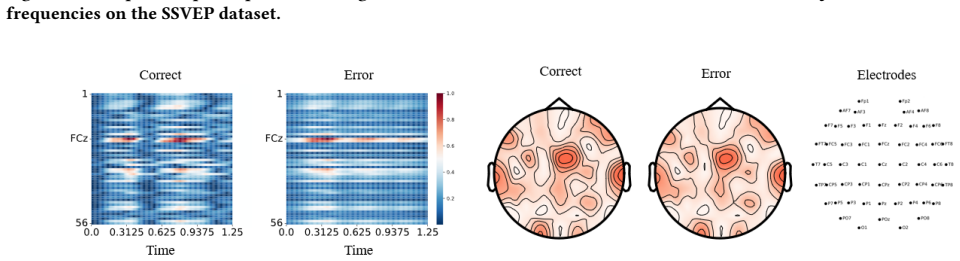
read the original abstract
Brain-Computer Interface (BCI) based on electroencephalography (EEG) enables direct interaction between the brain and external environments and has significant applications in assistive technologies, medical rehabilitation, and entertainment. Recently, EEG decoding methods based on Symmetric Positive Definite (SPD) learning have demonstrated superior performance. However, these methods typically employ basic network architectures and do not explicitly capture local relationships between EEG signals. This limitation is problematic for EEG signals due to their inherently low Signal-to-Noise Ratio (SNR). Moreover, most existing Riemannian manifold-based methods are restricted to specific metrics. The most widely used is the Affine-Invariant Metric (AIM). However, it has a quadratic dependency on the SPD matrices and cannot handle ill-conditioned SPD matrices, which hinders the effectiveness of networks. In contrast, the Bures-Wasserstein Metric (BWM) exhibits linear dependence on SPD matrices and demonstrates superior performance for ill conditioning. To overcome these challenges, we propose a Riemannian self-attention network based on the BWM. Additionally, the recently introduced power-deformed generalized Bures-Wasserstein metric reveals a nonlinear relationship between SPD matrices and matrix power deformation. This metric provides a more nuanced representation of the geometric structure of the SPD manifold. Consequently, we extend our model to a learnable version. For simplicity, we refer to it as GBWAtt. Experimental results on three EEG benchmarking datasets validate the robustness and effectiveness of our proposed method. The code is available at https://github.com/jissc/GBWAtt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GBWAtt, a Riemannian self-attention network for EEG decoding that operates on SPD matrices using the Bures-Wasserstein metric (BWM) and its recently introduced power-deformed generalization. It argues that BWM provides linear dependence on the matrices and better handling of ill-conditioned cases than the affine-invariant metric (AIM), while the self-attention layer captures local signal relationships missed by prior Riemannian networks; the learnable variant optimizes the power deformation parameter. Experimental results on three EEG benchmarking datasets are presented to support robustness and effectiveness, with code released at the provided GitHub link.
Significance. If the performance claims hold, the work offers a practical advance for low-SNR EEG decoding in BCI by replacing AIM with a metric that avoids quadratic scaling and ill-conditioning issues while adding attention for local structure. Explicit release of code is a clear strength that enables direct reproducibility and extension.
major comments (1)
- [Method (learnable GBW extension) and Experiments] The learnable power deformation parameter is optimized on the same three benchmark datasets used to claim superiority over fixed-metric baselines; without an explicit statement of the optimization protocol (e.g., nested cross-validation or held-out validation splits) this introduces a circularity risk that directly affects the central empirical claim.
minor comments (3)
- [Abstract and §3] The abstract states that the model 'extends our model to a learnable version' but does not define the exact parameterization of the power deformation inside the attention module; an equation or pseudocode block would clarify the implementation.
- [Experiments] Table or figure captions for the three datasets should explicitly list the number of subjects, trials, and classes to allow immediate comparison with prior Riemannian EEG work.
- [Introduction] The claim that BWM 'demonstrates superior performance for ill conditioning' would benefit from a short reference to the specific prior result or a small illustrative matrix example in the text.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the constructive comment. We address the concern regarding the learnable parameter optimization protocol below and commit to a revision that provides the requested transparency.
read point-by-point responses
-
Referee: [Method (learnable GBW extension) and Experiments] The learnable power deformation parameter is optimized on the same three benchmark datasets used to claim superiority over fixed-metric baselines; without an explicit statement of the optimization protocol (e.g., nested cross-validation or held-out validation splits) this introduces a circularity risk that directly affects the central empirical claim.
Authors: We agree that the absence of an explicit optimization protocol description creates a legitimate concern about potential circularity. The revised manuscript will add a dedicated subsection under Experiments that details the protocol: the power parameter is tuned exclusively via inner-loop cross-validation on the training folds of each outer evaluation split, with no access to test data. This ensures the reported superiority of the learnable GBWAtt variant is evaluated on held-out data. We will also report the specific search ranges and selected values per dataset for full reproducibility. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper proposes a Riemannian self-attention network using the Bures-Wasserstein metric (drawn from prior literature) and its power-deformed generalization extended to a learnable form, with effectiveness shown via empirical results on three EEG benchmarks. No load-bearing step reduces by the paper's equations or self-citation to a self-definition, fitted parameter renamed as prediction, or imported uniqueness theorem. The central claims rest on architectural design plus external validation rather than an internal derivation that collapses to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- power deformation parameter
axioms (2)
- domain assumption EEG signals are appropriately summarized by SPD covariance matrices on a Riemannian manifold
- domain assumption BWM exhibits linear dependence on SPD matrices and superior behavior on ill-conditioned cases relative to AIM
Reference graph
Works this paper leans on
-
[1]
Ghadir Ali Altuwaijri, Ghulam Muhammad, Hamdi Altaheri, and Mansour Alsu- laiman. 2022. A multi-branch convolutional neural network with squeeze-and- excitation attention blocks for EEG-based motor imagery signals classification. Diagnostics(2022), 995
2022
-
[2]
Sion An, Soopil Kim, Philip Chikontwe, and Sang Hyun Park. 2023. Dual attention relation network with fine-tuning for few-shot EEG motor imagery classification. IEEE Trans. Neural Netw. Learn. Syst.(2023), 15479 – 15493
2023
-
[3]
Vincent Arsigny, Pierre Fillard, Xavier Pennec, and Nicholas Ayache. 2007. Geo- metric means in a novel vector space structure on symmetric positive-definite matrices.SIAM J. Matrix Anal. Appl.(2007), 328–347
2007
-
[5]
InInternational confer- ence on latent variable analysis and signal separation
Riemannian geometry applied to BCI classification. InInternational confer- ence on latent variable analysis and signal separation
-
[6]
Alexandre Barachant, Stéphane Bonnet, Marco Congedo, and Christian Jutten
-
[7]
Classification of covariance matrices using a Riemannian-based kernel for BCI applications.Neurocomputing(2013), 172–178
2013
-
[8]
Rajendra Bhatia, Tanvi Jain, and Yongdo Lim. 2019. On the Bures–Wasserstein distance between positive definite matrices.Expo. Math.(2019), 165–191
2019
-
[9]
Joyce Chelangat Bore, Peiyang Li, Lin Jiang, Walid MA Ayedh, Chunli Chen, Dennis Joe Harmah, Dezhong Yao, Zehong Cao, and Peng Xu. 2021. A long short-term memory network for sparse spatiotemporal EEG source imaging. IEEE Trans. Med. Imaging.(2021), 3787–3800
2021
-
[10]
Daniel Brooks, Olivier Schwander, Frédéric Barbaresco, Jean-Yves Schneider, and Matthieu Cord. 2019. Riemannian batch normalization for SPD neural networks. InNeurIPS
2019
-
[11]
Clemens Brunner, Robert Leeb, Gernot Müller-Putz, Alois Schlögl, and Gert Pfurtscheller. 2008. BCI Competition 2008–Graz data set A.Graz University of Technology, Austria(2008)
2008
-
[12]
Rudrasis Chakraborty, Jose Bouza, Jonathan Manton, and Baba C Vemuri. 2022. Manifoldnet: A deep neural network for manifold-valued data with applications. IEEE Trans. Pattern Anal. Mach. Intell.(2022), 799–810
2022
-
[13]
Rudrasis Chakraborty, Chun-Hao Yang, Xingjian Zhen, Monami Banerjee, Derek Archer, David Vaillancourt, Vikas Singh, and Baba Vemuri. 2018. A statistical recurrent model on the manifold of symmetric positive definite matrices. In NeurIPS
2018
-
[14]
Ziheng Chen, Yue Song, Gaowen Liu, Ramana Rao Kompella, Xiao-Jun Wu, and Nicu Sebe. 2023. Riemannian Multiclass Logistics Regression for SPD Neural Networks.arXiv preprint arXiv:2305.11288(2023)
arXiv 2023
-
[15]
Ziheng Chen, Yue Song, Yunmei Liu, and Nicu Sebe. 2024. A Lie Group Approach to Riemannian Normalization for SPD Neural Networks. InICLR
2024
-
[16]
Ziheng Chen, Yue Song, Xiaojun Wu, Gaowen Liu, and Nicu Sebe. 2025. Under- standing Matrix Function Normalizations in Covariance Pooling through the Lens of Riemannian Geometry. InICLR
2025
-
[17]
Ziheng Chen, Tianyang Xu, Xiao-Jun Wu, Rui Wang, Zhiwu Huang, and Josef Kittler. 2023. Riemannian local mechanism for SPD neural networks. InAAAI
2023
-
[18]
Ziheng Chen, Tianyang Xu, Xiao-Jun Wu, Rui Wang, Zhiwu Huang, and Josef Kittler. 2023. Riemannian Local Mechanism for SPD Neural Networks. InAAAI
2023
-
[19]
Marco Congedo, Alexandre Barachant, and Rajendra Bhatia. 2017. Riemannian geometry for EEG-based brain-computer interfaces; a primer and a review.Brain Comput. Interfaces(2017), 155–174
2017
-
[20]
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xi- aohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929(2020)
Pith/arXiv arXiv 2020
-
[21]
Zhi Gao, Yuwei Wu, Mehrtash Harandi, and Yunde Jia. 2020. A Robust Distance Measure for Similarity-Based Classification on the SPD Manifold.IEEE Trans. Neural Netw. Learn. Syst.(2020), 3230–3244
2020
-
[22]
Greg Hajcak. 2012. What we’ve learned from mistakes: Insights from error-related brain activity.Curr. Dir. Psychol.(2012)
2012
-
[23]
Andi Han, Bamdev Mishra, Pratik Jawanpuria, and Junbin Gao. 2021. General- ized Bures-Wasserstein geometry for positive definite matrices.arXiv preprint arXiv:2110.10464(2021)
arXiv 2021
-
[24]
Andi Han, Bamdev Mishra, Pratik Jawanpuria, and Junbin Gao. 2023. Learning with symmetric positive definite matrices via generalized Bures-Wasserstein geometry. InInternational Conference on Geometric Science of Information
2023
-
[25]
Andi Han, Bamdev Mishra, Pratik Kumar Jawanpuria, and Junbin Gao. 2021. On Riemannian optimization over positive definite matrices with the Bures- Wasserstein geometry. InNeurIPS
2021
-
[26]
Chengcheng Han, Guanghua Xu, Jun Xie, Chaoyang Chen, and Sicong Zhang
-
[27]
Highly interactive brain–computer interface based on flicker-free steady- state motion visual evoked potential.Scientific reports(2018), 5835
2018
-
[28]
Mehrtash Harandi and Mathieu Salzmann. 2015. Riemannian coding and dictio- nary learning: Kernels to the rescue. InCVPR
2015
-
[29]
Mehrtash Harandi, Mathieu Salzmann, and Richard Hartley. 2018. Dimensionality reduction on SPD manifolds: The emergence of geometry-aware methods.IEEE Trans. Pattern Anal. Mach. Intell.(2018), 48–62
2018
-
[30]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. InCVPR
2016
-
[31]
Christoph S Herrmann. 2001. Human EEG responses to 1–100 Hz flicker: reso- nance phenomena in visual cortex and their potential correlation to cognitive phenomena.Exp. Brain Res.(2001), 346–353
2001
-
[32]
Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam. 2017. Mobilenets: Efficient convolutional neural networks for mobile vision applications.arXiv preprint arXiv:1704.04861(2017)
Pith/arXiv arXiv 2017
-
[33]
Chen Hu, Ziheng Chen, Rui Wang, Yefeng Zheng, and Nicu Sebe. 2026. Riemann- ian High-Order Pooling for Brain Foundation Models. InICLR
2026
-
[34]
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger
-
[35]
Densely connected convolutional networks. InCVPR
-
[36]
Zhiwu Huang and Luc Van Gool. 2017. A Riemannian network for spd matrix learning. InAAAI
2017
-
[37]
Zhiwu Huang, Ruiping Wang, Shiguang Shan, Xianqiu Li, and Xilin Chen. 2015. Log-euclidean metric learning on symmetric positive definite manifold with application to image set classification. InICML
2015
-
[38]
Wei-Bang Jiang, Liming Zhao, and Bao-Liang Lu. 2024. Large brain model for learning generic representations with tremendous EEG data in BCI. InICLR
2024
-
[39]
Ce Ju and Cuntai Guan. 2023. Graph neural networks on spd manifolds for motor imagery classification: A perspective from the time–frequency analysis.IEEE Trans. Neural Netw. Learn. Syst.(2023), 17701 – 17715
2023
-
[40]
Max Kochurov, Rasul Karimov, and Serge Kozlukov. 2020. Geoopt: Riemannian optimization in pytorch.arXiv preprint arXiv:2005.02819(2020)
arXiv 2020
-
[41]
Vernon J Lawhern, Amelia J Solon, Nicholas R Waytowich, Stephen M Gordon, Chou P Hung, and Brent J Lance. 2018. EEGNet: a compact convolutional neural network for EEG-based brain–computer interfaces.J. Neural Eng.(2018), 056013
2018
-
[42]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. 2002. Gradient- based learning applied to document recognition.Proc. IEEE(2002), 2278–2324
2002
-
[43]
Cunbo Li, Tian Tang, Yue Pan, Lei Yang, Shuhan Zhang, Zhaojin Chen, Peiyang Li, Dongrui Gao, Huafu Chen, Fali Li, et al . 2024. An efficient graph learning system for emotion recognition inspired by the cognitive prior graph of EEG brain network.IEEE Trans. Neural Netw. Learn. Syst.(2024), 7130 – 7144
2024
-
[44]
Fabien Lotte, Marco Congedo, Anatole Lécuyer, Fabrice Lamarche, and Bruno Ar- naldi. 2007. A review of classification algorithms for EEG-based brain–computer interfaces.Journal of neural engineering(2007), R1
2007
-
[45]
Luigi Malagò, Luigi Montrucchio, and Giovanni Pistone. 2018. Wasserstein Riemannian geometry of Gaussian densities.Information Geometry(2018), 137– 179
2018
-
[46]
Ravikiran Mane, Effie Chew, Karen Chua, Kai Keng Ang, Neethu Robinson, A Prasad Vinod, Seong-Whan Lee, and Cuntai Guan. 2021. FBCNet: A multi- view convolutional neural network for brain-computer interface.arXiv preprint arXiv:2104.01233(2021)
arXiv 2021
-
[47]
Perrin Margaux, Maby Emmanuel, Daligault Sébastien, Bertrand Olivier, and Mat- tout Jérémie. 2012. Objective and subjective evaluation of online error correction during P300-based spelling.Adv. Hum-Comput. Interact.(2012)
2012
-
[48]
Yazeed K Musallam, Nasser I AlFassam, Ghulam Muhammad, Syed Umar Amin, Mansour Alsulaiman, Wadood Abdul, Hamdi Altaheri, Mohamed A Bencherif, and Mohammed Algabri. 2021. Electroencephalography-based motor imagery classification using temporal convolutional network fusion.Biomed. Signal Process. Control(2021), 102826
2021
-
[49]
Xuan Son Nguyen. 2022. The Gyro-Structure of Some Matrix Manifolds. In NeurIPS
2022
-
[50]
Xuan Son Nguyen, Luc Brun, Olivier Lézoray, and Sébastien Bougleux. 2019. A neural network based on SPD manifold learning for skeleton-based hand gesture recognition. InCVPR
2019
-
[51]
Xuan Son Nguyen and Shuo Yang. 2023. Building neural networks on matrix manifolds: a gyrovector space approach. InICML
2023
-
[52]
Yue-Ting Pan, Jing-Lun Chou, and Chun-Shu Wei. 2022. MAtt: a manifold attention network for EEG decoding. InNeurIPS
2022
-
[53]
Xavier Pennec, Pierre Fillard, and Nicholas Ayache. 2006. A Riemannian frame- work for tensor computing.Int. J. Comput. Vis.(2006), 41–66
2006
-
[54]
Yannick Roy, Hubert Banville, Isabela Albuquerque, Alexandre Gramfort, Tiago H Falk, and Jocelyn Faubert. 2019. Deep learning-based electroencephalography analysis: a systematic review.J. Neural Eng.(2019), 051001
2019
-
[55]
Andres Sanin, Conrad Sanderson, Mehrtash T Harandi, and Brian C Lovell. 2013. Spatio-temporal covariance descriptors for action and gesture recognition. In W ACV
2013
-
[56]
Eduardo Santamaria-Vazquez, Victor Martinez-Cagigal, Fernando Vaquerizo- Villar, and Roberto Hornero. 2020. EEG-inception: a novel deep convolutional neural network for assistive ERP-based brain-computer interfaces.IEEE Trans. Neural Syst. Rehabil. Eng.(2020), 2773–2782
2020
-
[57]
Robin Tibor Schirrmeister, Jost Tobias Springenberg, Lukas Dominique Josef Fiederer, Martin Glasstetter, Katharina Eggensperger, Michael Tangermann, Frank Hutter, Wolfram Burgard, and Tonio Ball. 2017. Deep learning with convolutional neural networks for EEG decoding and visualization.Hum. Brain Mapp.(2017), 5391–5420. Towards Robust EEG Decoding Based on...
2017
-
[58]
Nikolopoulos Spiros. 2016. MAMEM EEG SSVEP Dataset II (256 channels, 11 subjects, 5 frequencies presented simultaneously). (2016)
2016
-
[59]
Yoon-Je Suh and Byung Hyung Kim. 2021. Riemannian embedding banks for common spatial patterns with EEG-based SPD neural networks. InAAAI
2021
-
[60]
Fengzhen Tang, Mengling Fan, and Peter Tiňo. 2020. Generalized learning Riemannian space quantization: A case study on Riemannian manifold of SPD matrices.IEEE Trans. Neural Netw. Learn. Syst.(2020), 281–292
2020
-
[61]
Yann Thanwerdas and Xavier Pennec. 2019. Is affine-invariance well defined on SPD matrices? A principled continuum of metrics. InGeometric Science of Information: 4th International Conference, GSI 2019, Toulouse, France, August 27–29, 2019, Proceedings 4. 502–510
2019
-
[62]
Yann Thanwerdas and Xavier Pennec. 2022. The geometry of mixed-Euclidean metrics on symmetric positive definite matrices.Differ. Geom. Appl.(2022)
2022
-
[63]
Diego Tosato, Michela Farenzena, Mauro Spera, Vittorio Murino, and Marco Cristani. 2010. Multi-class classification on Riemannian manifolds for video surveillance. InECCV
2010
-
[64]
Raviteja Vemulapalli, Jaishanker K Pillai, and Rama Chellappa. 2013. Kernel learning for extrinsic classification of manifold features. InCVPR
2013
-
[65]
Ruiping Wang, Huimin Guo, Larry S Davis, and Qionghai Dai. 2012. Covariance discriminative learning: A natural and efficient approach to image set classifica- tion. InCVPR
2012
-
[66]
Rui Wang, Chen Hu, Ziheng Chen, Xiao-Jun Wu, and Xiaoning Song. 2024. A Grassmannian Manifold Self-Attention Network for Signal Classification. In IJCAI
2024
-
[67]
Rui Wang, Shaocheng Jin, Ziheng Chen, Xiaoqing Luo, and Xiao-Jun Wu. 2025. Learning to Normalize on the SPD Manifold under Bures-Wasserstein Geometry. InCVPR
2025
-
[68]
Rui Wang, Xiao-Jun Wu, and Josef Kittler. 2022. SymNet: A Simple Symmetric Positive Definite Manifold Deep Learning Method for Image Set Classification. IEEE Trans. Neural Netw. Learn. Syst.(2022), 2208–2222
2022
-
[69]
Chun-Shu Wei, Toshiaki Koike-Akino, and Ye Wang. 2019. Spatial component- wise convolutional network (SCCNet) for motor-imagery EEG classification. IEEE/EMBS Conference on Neural Engineering(2019), 328–331
2019
-
[70]
Chun-Shu Wei, Toshiaki Koike-Akino, and Ye Wang. 2019. Spatial Component- wise Convolutional Network (SCCNet) for Motor-Imagery EEG Classification. IEEE/EMBS Conference on Neural Engineering(2019), 328–331
2019
-
[71]
Chaoqi Yang, M Westover, and Jimeng Sun. 2023. Biot: Biosignal transformer for cross-data learning in the wild. InNeurIPS
2023
-
[72]
Le Yang, Marc Arnaudon, and Frédéric Barbaresco. 2010. Riemannian median, geometry of covariance matrices and radar target detection.European Radar Conference(2010), 415–418
2010
-
[73]
Florian Yger. 2013. A review of kernels on covariance matrices for BCI applica- tions. InIEEE international workshop on machine learning for signal processing
2013
-
[74]
Florian Yger, Maxime Berar, and Fabien Lotte. 2016. Riemannian approaches in brain-computer interfaces: a review.IEEE Trans. Neural Syst. Rehabil. Eng.(2016), 1753–1762
2016
-
[75]
Tong Zhang, Wenming Zheng, Zhen Cui, Yuan Zong, Chaolong Li, Xiaoyan Zhou, and Jian Yang. 2020. Deep manifold-to-manifold transforming network for skeleton-based action recognition.IEEE Trans. Multimedia(2020), 2926–2937
2020
-
[76]
Zhijun Zhang, Yu He, Weijian Mai, Yamei Luo, Xiaoli Li, Yuanxiong Cheng, Xiaoming Huang, and Run Lin. 2024. Convolutional Dynamically Convergent Differential Neural Network for Brain Signal Classification.IEEE Trans. Neural Netw. Learn. Syst.(2024), 8166 – 8177
2024
-
[77]
Luping Zhou, Lei Wang, Jianjia Zhang, Yinghuan Shi, and Yang Gao. 2017. Revis- iting metric learning for SPD matrix based visual representation. InCVPR. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Shaocheng Jin et al. A Related Work A.1 Neural Networks for EEG Due to the superior feature extraction ability of deep learning, numerous end-to...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.