TACO: Towards Task-Consistent Open-Vocabulary Adaptation in Video Recognition
Pith reviewed 2026-06-30 09:35 UTC · model grok-4.3
The pith
TACO reduces the mismatch between fine-tuning and evaluation objectives in open-vocabulary video recognition by regularizing relative geometry in representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
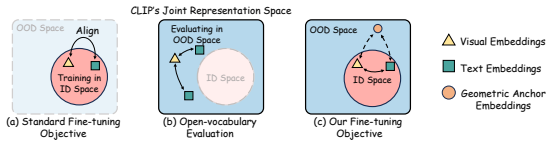
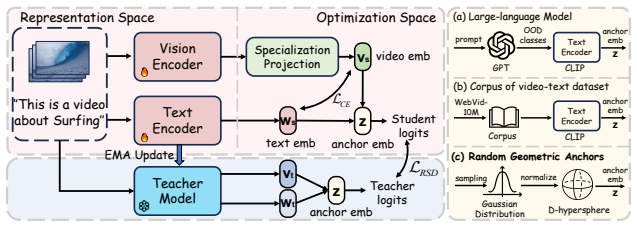
TACO mitigates the potential negative effects induced by the inconsistency between the fine-tuning and evaluation objectives, where model optimization is restricted to the known training distribution but evaluated on unseen ones. It does so by proposing Relative Structure Distillation, which regularizes the relative geometry of the representation space and suppresses harmful alignment shift during training, and by decoupling the representation space from the optimization space with a lightweight specialization projection, allowing task-specific adaptation without directly overspecializing the representations used at test time, establishing state-of-the-art performance on diverse benchmarks u
What carries the argument
Relative Structure Distillation, which regularizes the relative geometry of the representation space, combined with a lightweight specialization projection that decouples the representation space from the optimization space.
If this is right
- Adaptation preserves OOD-relevant alignment beyond the training distribution.
- Harmful alignment shift is suppressed during training without overspecializing test representations.
- Task-specific adaptation proceeds while the representations used at evaluation remain closer to the pretrained geometry.
- State-of-the-art results follow on cross-dataset and base-to-novel video recognition benchmarks.
Where Pith is reading between the lines
- The same relative-geometry constraint might reduce objective mismatch in image or audio open-vocabulary adaptation settings.
- Combining the specialization projection with other forms of knowledge distillation could further separate optimization from evaluation spaces.
- Measuring the change in pairwise distances among features on unseen videos before and after applying the distillation term would directly test the claimed preservation effect.
Load-bearing premise
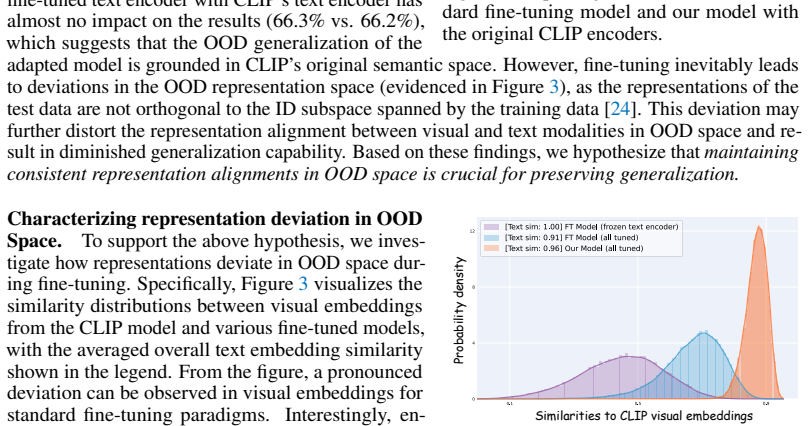
The observed deviation of representations beyond the fine-tuning data distribution is primarily inherited from the inconsistency between fine-tuning and evaluation objectives, and preserving relative geometry alignment will suppress harmful shift without introducing new trade-offs.
What would settle it
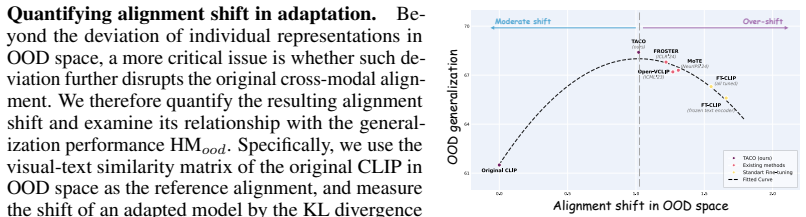
A controlled experiment in which models trained with Relative Structure Distillation still exhibit large representation deviations on held-out video distributions, with no corresponding gain in base-to-novel or cross-dataset accuracy, would falsify the central mechanism.
Figures


read the original abstract
Adapting CLIP for open-vocabulary video recognition necessitates a delicate balance between newly acquired video knowledge and the pretrained generalization. While existing studies pursue this generalization-specialization trade-off with additional regularizations or constraints, we argue that they overlook the deviation of representations beyond the fine-tuning data distribution, resulting in suboptimal adaptation effects. We believe such deviation is inherited from the inconsistency between the fine-tuning and evaluation objectives, where model optimization is restricted to the known training distribution but evaluated on unseen ones. In this paper, we introduce \emph{TACO}, a simple yet effective framework to mitigate the potential negative effects induced by this inconsistency. Our key insight is that adaptation should preserve OOD-relevant alignment beyond the training distribution. To this end, we propose \emph{Relative Structure Distillation}, which regularizes the relative geometry of the representation space and suppresses harmful alignment shift during training. We further decouple the representation space from the optimization space with a lightweight specialization projection, allowing task-specific adaptation without directly overspecializing the representations used at test time. \emph{TACO} establishes state-of-the-art performance on diverse benchmarks under cross-dataset and base-to-novel settings. Code will be released at https://github.com/ZMHH-H/TACO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TACO for adapting CLIP to open-vocabulary video recognition. It identifies an inconsistency between fine-tuning (restricted to training distribution) and evaluation (on unseen distributions) as the source of harmful representation deviation, and introduces Relative Structure Distillation to regularize relative geometry in the representation space plus a lightweight specialization projection to decouple representation from optimization space. The framework is claimed to achieve state-of-the-art results on diverse benchmarks under cross-dataset and base-to-novel settings.
Significance. If the empirical claims are substantiated, the work offers a lightweight, conceptually clean approach to preserving OOD-relevant alignment without heavy additional constraints, which could meaningfully advance practical open-vocabulary video adaptation.
major comments (1)
- The provided abstract (and the high-level description in the reader's summary) supplies no equations, implementation details, baselines, ablation studies, or error analysis. The central SOTA claim therefore cannot be evaluated from the given material; the full manuscript must include these in the methods (§3) and experiments (§4) sections for the contribution to be assessable.
Simulated Author's Rebuttal
We thank the referee for the review. The comment appears to focus on the abstract, but the full manuscript contains the requested details in the methods and experiments sections. We address the point below.
read point-by-point responses
-
Referee: The provided abstract (and the high-level description in the reader's summary) supplies no equations, implementation details, baselines, ablation studies, or error analysis. The central SOTA claim therefore cannot be evaluated from the given material; the full manuscript must include these in the methods (§3) and experiments (§4) sections for the contribution to be assessable.
Authors: The full manuscript includes equations for Relative Structure Distillation and the specialization projection in §3 (Methods). Section 4 (Experiments) reports implementation details, multiple baselines, ablation studies on each component, cross-dataset and base-to-novel results, and error analysis. The abstract is intentionally high-level per standard practice; the SOTA claims are substantiated by the quantitative results and ablations in the full text. revision: no
Circularity Check
No circularity: method proposal is declarative and empirically grounded
full rationale
The paper introduces TACO as a framework with Relative Structure Distillation and a specialization projection to address objective inconsistency in CLIP adaptation for video recognition. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on the stated insight about OOD deviation and are validated through benchmark experiments rather than reducing to inputs by construction. This is a standard empirical method paper with self-contained logical structure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Leveraging vision-language models for improving domain generalization in image classification
Sravanti Addepalli, Ashish Ramayee Asokan, Lakshay Sharma, and R Venkatesh Babu. Leveraging vision-language models for improving domain generalization in image classification. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 23922–23932, 2024
2024
-
[2]
Frozen in time: A joint video and image encoder for end-to-end retrieval
Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[3]
A Short Note about Kinetics-600
Joao Carreira, Eric Noland, Andras Banki-Horvath, Chloe Hillier, and Andrew Zisserman. A short note about kinetics-600.arXiv preprint arXiv:1808.01340, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Elaborative rehearsal for zero-shot action recognition
Shizhe Chen and Dong Huang. Elaborative rehearsal for zero-shot action recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
2021
-
[5]
Ost: Refining text knowledge with optimal spatio-temporal descriptor for general video recognition
Tongjia Chen, Hongshan Yu, Zhengeng Yang, Zechuan Li, Wei Sun, and Chen Chen. Ost: Refining text knowledge with optimal spatio-temporal descriptor for general video recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[6]
Cat-seg: Cost aggregation for open-vocabulary semantic segmentation
Seokju Cho, Heeseong Shin, Sunghwan Hong, Anurag Arnab, Paul Hongsuck Seo, and Seungryong Kim. Cat-seg: Cost aggregation for open-vocabulary semantic segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4113–4123, 2024
2024
-
[7]
Wenliang Dai, Lu Hou, Lifeng Shang, Xin Jiang, Qun Liu, and Pascale Fung. Enabling multimodal generation on clip via vision-language knowledge distillation.arXiv preprint arXiv:2203.06386, 2022
-
[8]
Estimating the intrinsic dimension of datasets by a minimal neighborhood information.Scientific reports, 2017
Elena Facco, Maria d’Errico, Alex Rodriguez, and Alessandro Laio. Estimating the intrinsic dimension of datasets by a minimal neighborhood information.Scientific reports, 2017
2017
-
[9]
Groundvts: Visual token sampling in multimodal large language models for video temporal grounding
Rong Fan, Kaiyan Xiao, Minghao Zhu, Liuyi Wang, Kai Dai, and Zhao Yang. Groundvts: Visual token sampling in multimodal large language models for video temporal grounding. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[10]
something something
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2017
2017
-
[11]
Open-vocabulary object detection via vision and language knowledge distillation
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[12]
Mmrl: Multi-modal representation learning for vision-language models
Yuncheng Guo and Xiaodong Gu. Mmrl: Multi-modal representation learning for vision-language models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[13]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[14]
Efficient text-driven motion generation via latent consistency training.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2026
Mengxian Hu, Minghao Zhu, Xun Zhou, Qingqing Yan, Shu Li, Chengju Liu, and Qijun Chen. Efficient text-driven motion generation via latent consistency training.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2026
2026
-
[15]
Froster: Frozen clip is a strong teacher for open- vocabulary action recognition
Xiaohu Huang, Hao Zhou, Kun Yao, and Kai Han. Froster: Frozen clip is a strong teacher for open- vocabulary action recognition. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[16]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. InInternational Conference on Machine Learning (ICML), pages 4904–4916, 2021
2021
-
[18]
Prompting visual-language models for efficient video understanding
Chen Ju, Tengda Han, Kunhao Zheng, Ya Zhang, and Weidi Xie. Prompting visual-language models for efficient video understanding. InProceedings of the European Conference on Computer Vision (ECCV), pages 105–124, 2022. 10
2022
-
[19]
Prompting visual-language models for efficient video understanding
Chen Ju, Tengda Han, Kunhao Zheng, Ya Zhang, and Weidi Xie. Prompting visual-language models for efficient video understanding. InProceedings of the European Conference on Computer Vision (ECCV), 2022
2022
-
[20]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Maple: Multi-modal prompt learning
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. Maple: Multi-modal prompt learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[22]
Self-regulating prompts: Foundational model adaptation without forgetting
Muhammad Uzair Khattak, Syed Talal Wasim, Muzammal Naseer, Salman Khan, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Self-regulating prompts: Foundational model adaptation without forgetting. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[23]
Kuehne, H
H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre. Hmdb: A large video database for human motion recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2556–2563, 2011
2011
-
[24]
Fine-tuning can distort pretrained features and underperform out-of-distribution
Ananya Kumar, Aditi Raghunathan, Robbie Matthew Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[25]
Promptkd: Unsupervised prompt distillation for vision-language models
Zheng Li, Xiang Li, Xinyi Fu, Xin Zhang, Weiqiang Wang, Shuo Chen, and Jian Yang. Promptkd: Unsupervised prompt distillation for vision-language models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[26]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[27]
Match, expand and improve: Unsupervised finetuning for zero-shot action recognition with language knowledge
Wei Lin, Leonid Karlinsky, Nina Shvetsova, Horst Possegger, Mateusz Kozinski, Rameswar Panda, Rogerio Feris, Hilde Kuehne, and Horst Bischof. Match, expand and improve: Unsupervised finetuning for zero-shot action recognition with language knowledge. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[28]
Clipose: Category-level object pose estimation with pre-trained vision-language knowledge
Xiao Lin, Minghao Zhu, Ronghao Dang, Guangliang Zhou, Shaolong Shu, Feng Lin, Chengju Liu, and Qijun Chen. Clipose: Category-level object pose estimation with pre-trained vision-language knowledge. IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[29]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[30]
Visualizing data using t-sne.Journal of machine learning research, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 2008
2008
-
[31]
Some methods of classification and analysis of multivariate observations
James B McQueen. Some methods of classification and analysis of multivariate observations. InProc. of 5th Berkeley Symposium on Math. Stat. and Prob., pages 281–297, 1967
1967
-
[32]
Improving zero-shot gen- eralization of learned prompts via unsupervised knowledge distillation
Marco Mistretta, Alberto Baldrati, Marco Bertini, and Andrew D Bagdanov. Improving zero-shot gen- eralization of learned prompts via unsupervised knowledge distillation. InProceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[33]
Expanding language-image pretrained models for general video recognition
Bolin Ni, Houwen Peng, Minghao Chen, Songyang Zhang, Gaofeng Meng, Jianlong Fu, Shiming Xi- ang, and Haibin Ling. Expanding language-image pretrained models for general video recognition. In Proceedings of the European Conference on Computer Vision (ECCV), pages 1–18, 2022
2022
-
[34]
St-adapter: Parameter-efficient image- to-video transfer learning
Junting Pan, Ziyi Lin, Xiatian Zhu, Jing Shao, and Hongsheng Li. St-adapter: Parameter-efficient image- to-video transfer learning. InAdvances in Neural Information Processing Systems (NeurIPS), pages 26462–26477, 2022
2022
-
[35]
Clipping: Distilling clip-based models with a student base for video-language retrieval
Renjing Pei, Jianzhuang Liu, Weimian Li, Bin Shao, Songcen Xu, Peng Dai, Juwei Lu, and Youliang Yan. Clipping: Distilling clip-based models with a student base for video-language retrieval. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[36]
Disentangling spatial and temporal learning for efficient image-to-video transfer learning
Zhiwu Qing, Shiwei Zhang, Ziyuan Huang, Yingya Zhang, Changxin Gao, Deli Zhao, and Nong Sang. Disentangling spatial and temporal learning for efficient image-to-video transfer learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 11
2023
-
[37]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML), pages 8748–8763, 2021
2021
-
[38]
Fine-tuned clip models are efficient video learners
Hanoona Rasheed, Muhammad Uzair Khattak, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. Fine-tuned clip models are efficient video learners. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6545–6554, 2023
2023
-
[39]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[40]
Actionclip: A new paradigm for video action recognition
Mengmeng Wang, Jiazheng Xing, and Yong Liu. Actionclip: A new paradigm for video action recognition. arXiv preprint arXiv:2109.08472, 2021
-
[41]
Vita-clip: Video and text adaptive clip via multimodal prompting
Syed Talal Wasim, Muzammal Naseer, Salman Khan, Fahad Shahbaz Khan, and Mubarak Shah. Vita-clip: Video and text adaptive clip via multimodal prompting. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 23034–23044, 2023
2023
-
[42]
Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization
Zejia Weng, Xitong Yang, Ang Li, Zuxuan Wu, and Yu-Gang Jiang. Open-vclip: Transforming clip to an open-vocabulary video model via interpolated weight optimization. InInternational Conference on Machine Learning (ICML), pages 36978–36989, 2023
2023
-
[43]
Robust fine-tuning of zero-shot models
Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Kornblith, Rebecca Roelofs, Raphael Gontijo Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, et al. Robust fine-tuning of zero-shot models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[44]
Revisiting classifier: Transferring vision-language models for video recognition
Wenhao Wu, Zhun Sun, and Wanli Ouyang. Revisiting classifier: Transferring vision-language models for video recognition. InProceedings of the AAAI Conference on Artificial Intelligence, pages 2847–2855, 2023
2023
-
[45]
Bidirectional cross-modal knowledge exploration for video recognition with pre-trained vision-language models
Wenhao Wu, Xiaohan Wang, Haipeng Luo, Jingdong Wang, Yi Yang, and Wanli Ouyang. Bidirectional cross-modal knowledge exploration for video recognition with pre-trained vision-language models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6620– 6630, 2023
2023
-
[46]
Clip-kd: An empirical study of clip model distillation
Chuanguang Yang, Zhulin An, Libo Huang, Junyu Bi, Xinqiang Yu, Han Yang, Boyu Diao, and Yongjun Xu. Clip-kd: An empirical study of clip model distillation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 15952–15962, 2024
2024
-
[47]
Mma: Multi-modal adapter for vision- language models
Lingxiao Yang, Ru-Yuan Zhang, Yanchen Wang, and Xiaohua Xie. Mma: Multi-modal adapter for vision- language models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[48]
Aim: Adapting image models for efficient video action recognition
Taojiannan Yang, Yi Zhu, Yusheng Xie, Aston Zhang, Chen Chen, and Mu Li. Aim: Adapting image models for efficient video action recognition. InInternational Conference on Learning Representations (ICLR), 2022
2022
-
[49]
Yating Yu, Congqi Cao, Yifan Zhang, and Yanning Zhang. Learning to generalize without bias for open-vocabulary action recognition.arXiv preprint arXiv:2502.20158, 2025
-
[50]
Florence: A New Foundation Model for Computer Vision
Lu Yuan, Dongdong Chen, Yi-Ling Chen, Noel Codella, Xiyang Dai, Jianfeng Gao, Houdong Hu, Xuedong Huang, Boxin Li, Chunyuan Li, et al. Florence: A new foundation model for computer vision.arXiv preprint arXiv:2111.11432, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[51]
Learning to prompt for vision-language models.International Journal of Computer Vision (IJCV), 130(9):2337–2348, 2022
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International Journal of Computer Vision (IJCV), 130(9):2337–2348, 2022
2022
-
[52]
Conditional prompt learning for vision- language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision- language models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[53]
Complementary relation contrastive distillation
Jinguo Zhu, Shixiang Tang, Dapeng Chen, Shijie Yu, Yakun Liu, Mingzhe Rong, Aijun Yang, and Xiaohua Wang. Complementary relation contrastive distillation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 12
2021
-
[54]
Fine-grained spatiotemporal motion alignment for contrastive video representation learning
Minghao Zhu, Xiao Lin, Ronghao Dang, Chengju Liu, and Qijun Chen. Fine-grained spatiotemporal motion alignment for contrastive video representation learning. InProceedings of the 31st ACM International Conference on Multimedia, pages 4725–4736, 2023
2023
-
[55]
Mote: Reconciling generalization with specialization for visual-language to video knowledge transfer
Minghao Zhu, Zhengpu Wang, Mengxian Hu, Ronghao Dang, Xiao Lin, Xun Zhou, Chengju Liu, and Qijun Chen. Mote: Reconciling generalization with specialization for visual-language to video knowledge transfer. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[56]
Orthogonal temporal interpolation for zero-shot video recognition
Yan Zhu, Junbao Zhuo, Bin Ma, Jiajia Geng, Xiaoming Wei, Xiaolin Wei, and Shuhui Wang. Orthogonal temporal interpolation for zero-shot video recognition. InProceedings of the 31st ACM International Conference on Multimedia, pages 7491–7501, 2023. 13 Appendix Overview This appendix is organized as follows: •Section A: Limitations and Broader Impact. •Secti...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.