OPERA: Aligning Open-Ended Reasoning via Objective Perplexity-based Reinforcement Learning
Pith reviewed 2026-06-25 20:58 UTC · model grok-4.3
The pith
OPERA replaces biased LLM judges with intrinsic perplexity reduction rewards for aligning models on open-ended reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
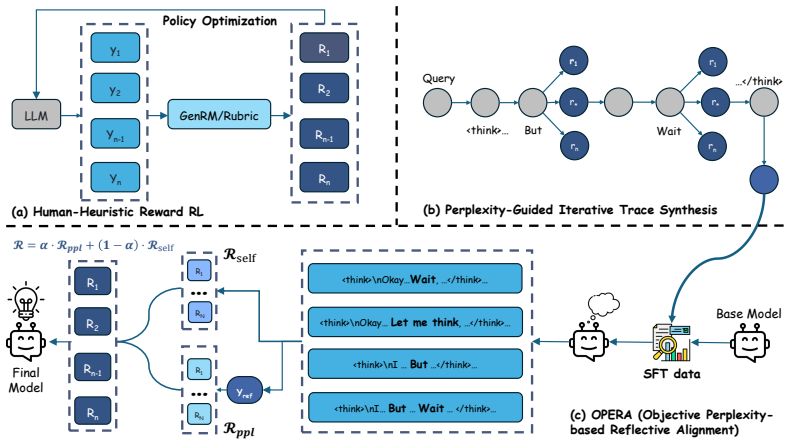
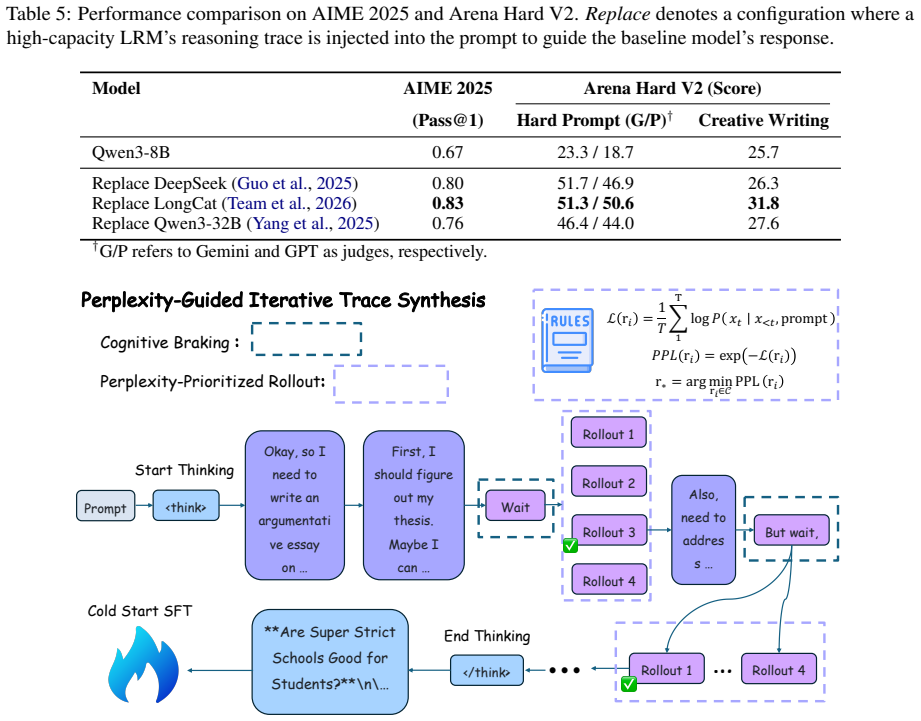
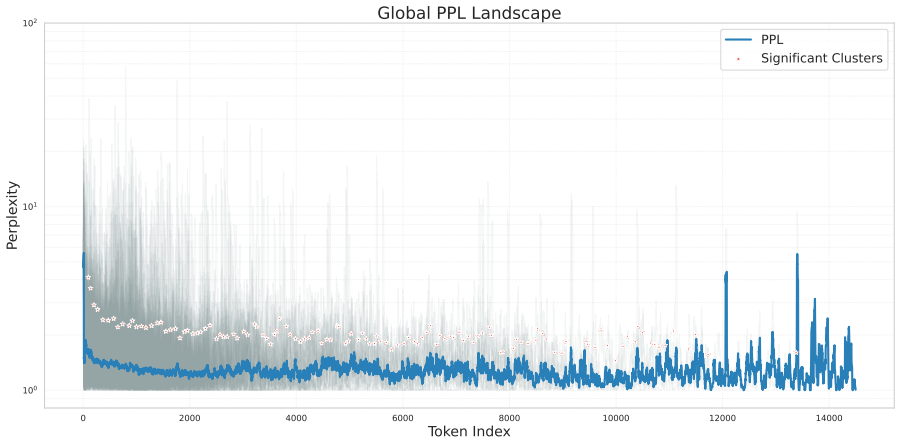
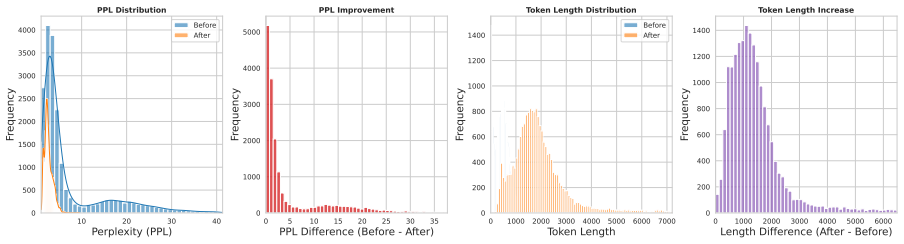
OPERA derives an intrinsic reward signal from perplexity dynamics, quantifying uncertainty reduction at critical reflective states. During the cold-start phase, it introduces a data synthesis method that leverages carefully designed guiding words to generate diverse reasoning traces, along with perplexity-prioritized rollouts that utilize internal log-probabilities to identify logically consistent reasoning branches. This pipeline yields a large-scale dataset comprising 20,000 high-quality reasoning trajectories. Implementing OPERA on Qwen3-8B establishes a new state-of-the-art among open-source models, achieving parity with or surpassing proprietary models like Gemini2.5 and MiniMax-M2.5 in
What carries the argument
The perplexity dynamics reward that quantifies uncertainty reduction at reflective states in reasoning traces.
Load-bearing premise
Reductions in perplexity at reflective states provide a reliable, unbiased reward signal for open-ended reasoning quality.
What would settle it
Human raters consistently preferring outputs from judge-based RL over OPERA-trained models on the same set of open-ended tasks.
Figures




read the original abstract
Reinforcement Learning (RL) has enabled LLMs to excel in objective reasoning tasks such as mathematics and code generation. However, applying RL to open-ended tasks, such as creative writing, remains challenging because LLM-as-a-judge reward models often exhibit stylistic biases and positional inconsistencies, leading to unstable supervision. To address this, we propose OPERA (Objective Perplexity-based Reflective Alignment), which replaces unreliable external judges with intrinsic rewards derived from perplexity dynamics. Specifically, we derive an intrinsic reward signal from perplexity dynamics, quantifying uncertainty reduction at critical reflective states. During the cold-start phase, we introduce a data synthesis method that leverages carefully designed guiding words to generate diverse reasoning traces, along with perplexity-prioritized rollouts that utilize internal log-probabilities to identify logically consistent reasoning branches. This pipeline yields a large-scale dataset comprising 20,000 high-quality reasoning trajectories. Empirical evaluations consistently demonstrate the scalability and efficacy of our approach in alignment for open-ended tasks. Implementing OPERA on Qwen3-8B establishes a new state-of-the-art among open-source models, achieving parity with or surpassing proprietary models like Gemini2.5 and MiniMax-M2.5 in some open-ended tasks. The code is available at https://github.com/pangpang-xuan/OPERA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OPERA, an RL method for open-ended LLM alignment that derives intrinsic rewards from perplexity dynamics (uncertainty reduction) at reflective states rather than using LLM judges. It describes a cold-start data synthesis pipeline using guiding words and perplexity-prioritized rollouts to produce 20k reasoning trajectories, then reports that applying the method to Qwen3-8B yields new SOTA results among open-source models with parity or superiority to proprietary models (Gemini2.5, MiniMax-M2.5) on some open-ended tasks.
Significance. If the perplexity-based reward proves non-circular and correlates with external quality metrics, the approach could scale alignment for creative tasks without judge biases and reduce reliance on human preference data. The public code release supports reproducibility.
major comments (3)
- [Abstract] Abstract: the intrinsic reward is defined directly from the model's own log-probabilities and perplexity at reflective states, but no derivation, formal definition, or proof of non-circularity is supplied; this leaves the central claim that the signal is 'objective' and independent of the base model's biases unverified.
- [Abstract] Abstract: no ablation on reflective-state detection, no error bars, and no baseline comparisons or human-preference correlations are reported, so the SOTA claim on Qwen3-8B cannot be assessed for robustness or external validity.
- [Abstract] Abstract: the data synthesis and rollout prioritization both rely on internal log-probabilities, creating a closed loop; without shown correlation to task-specific quality metrics or human judgments, reductions in perplexity may simply favor shorter or higher-probability (more predictable) outputs rather than higher-quality open-ended reasoning.
minor comments (1)
- [Abstract] Abstract: the GitHub link is provided, but the manuscript should explicitly state which components (reward computation, rollout selection, dataset) are released to enable replication.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below. Revisions will be made to strengthen the abstract, add missing analyses, and clarify the method where the comments identify gaps.
read point-by-point responses
-
Referee: [Abstract] Abstract: the intrinsic reward is defined directly from the model's own log-probabilities and perplexity at reflective states, but no derivation, formal definition, or proof of non-circularity is supplied; this leaves the central claim that the signal is 'objective' and independent of the base model's biases unverified.
Authors: The abstract is concise by design, but Section 3.2 of the full manuscript formally defines the reward as r_t = PPL(s_t) - PPL(s_{t+1}) at reflective states, where reflective states are detected via the guiding-word mechanism. The claim of objectivity refers to independence from external LLM judges rather than complete freedom from the base model. A rigorous proof of non-circularity is not supplied, as it would require additional theoretical analysis; we will revise the abstract to reference the derivation and add a limitations paragraph discussing this point. revision: partial
-
Referee: [Abstract] Abstract: no ablation on reflective-state detection, no error bars, and no baseline comparisons or human-preference correlations are reported, so the SOTA claim on Qwen3-8B cannot be assessed for robustness or external validity.
Authors: The abstract omits these elements due to length limits. The full paper reports baseline comparisons to PPO and DPO in Table 3 and human evaluations in Section 6. We agree that ablations on reflective-state detection and error bars are absent. We will add both an ablation study and error bars (standard deviations over 3 seeds) to the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the data synthesis and rollout prioritization both rely on internal log-probabilities, creating a closed loop; without shown correlation to task-specific quality metrics or human judgments, reductions in perplexity may simply favor shorter or higher-probability (more predictable) outputs rather than higher-quality open-ended reasoning.
Authors: The synthesis uses guiding words for diversity (Section 4.1) and perplexity to select consistent branches. Performance gains on external benchmarks provide indirect support. We will add a new correlation analysis between perplexity reduction and human quality ratings on 500 held-out trajectories in the revision to directly address the closed-loop concern. revision: yes
Circularity Check
Intrinsic reward defined directly from model's own perplexity and log-probabilities creates self-referential alignment
specific steps
-
self definitional
[abstract]
"we derive an intrinsic reward signal from perplexity dynamics, quantifying uncertainty reduction at critical reflective states. [...] along with perplexity-prioritized rollouts that utilize internal log-probabilities to identify logically consistent reasoning branches. This pipeline yields a large-scale dataset comprising 20,000 high-quality reasoning trajectories."
The reward is explicitly constructed as a function of the model's own perplexity (uncertainty reduction), and the training data is filtered/prioritized using the same internal log-probabilities. Therefore the RL objective and the resulting 'aligned' trajectories are defined in terms of the base model's current probability assignments, rendering the output equivalent to the input distribution by construction rather than an independent quality signal.
full rationale
The paper's central mechanism defines the reward signal and data selection pipeline exclusively in terms of the base model's internal perplexity and log-probabilities. This makes the RL objective equivalent to optimizing the model to produce outputs that the model itself already assigns higher probability to at selected states, without an independent external anchor. While the method is self-contained as an internal optimization procedure, the claim that this constitutes an 'objective' replacement for external judges reduces to reinforcing the input model's existing distribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Psychological methods, 21(3):273
Comparing the pearson and spearman corre- lation coefficients across distributions and sample sizes: A tutorial using simulations and empirical data. Psychological methods, 21(3):273. Daniel Fein, Sebastian Russo, Violet Xiang, Kabir Jolly, Rafael Rafailov, and Nick Haber. 2026. Litbench: A benchmark and dataset for reliable evaluation of creative writing...
arXiv 2026
-
[2]
Rubrics as rewards: Reinforcement learn- ing beyond verifiable domains.arXiv preprint arXiv:2507.17746. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948...
Pith/arXiv arXiv 2025
-
[3]
Adrian Kuhn, Stéphane Ducasse, and Tudor Gîrba
Writing-zero: Bridge the gap between non- verifiable tasks and verifiable rewards.arXiv preprint arXiv:2506.00103. Adrian Kuhn, Stéphane Ducasse, and Tudor Gîrba
-
[4]
Semantic clustering: Identifying topics in source code.Information and software technology, 49(3):230–243. Xuanyu Lei, Chenliang Li, Yuning Wu, Kaiming Liu, Weizhou Shen, Peng Li, Ming Yan, Ji Zhang, Fei Huang, and Yang Liu. 2025. Writing-rl: Advancing long-form writing via adaptive curriculum reinforce- ment learning.arXiv preprint arXiv:2506.05760. Zhao...
Pith/arXiv arXiv 2025
-
[5]
5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599
Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599. Meituan LongCat Team, Anchun Gui, Bei Li, Bingyang Tao, Bole Zhou, Borun Chen, Chao Zhang, Chen Gao, Chen Zhang, Chengcheng Han, and 1 others
-
[6]
arXiv preprint arXiv:2601.16725
Longcat-flash-thinking-2601 technical report. arXiv preprint arXiv:2601.16725. Haozhe Wang, Haoran Que, Qixin Xu, Minghao Liu, Wangchunshu Zhou, Jiazhan Feng, Wanjun Zhong, Wei Ye, Tong Yang, Wenhao Huang, and 1 others
-
[7]
Reverse-engineered reasoning for open-ended generation.arXiv preprint arXiv:2509.06160. Xiaohua Wang, Muzhao Tian, Yuqi Zeng, Zisu Huang, Jiakang Yuan, Bowen Chen, Jingwen Xu, Mingbo Zhou, Wenhao Liu, Muling Wu, and 1 others. 2026. Reward hacking in the era of large models: Mech- anisms, emergent misalignment, challenges.arXiv preprint arXiv:2604.13602. J...
arXiv 2026
-
[8]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan
-
[9]
Tree of thoughts: Deliberate problem solving 10 with large language models.Advances in neural information processing systems, 36:11809–11822. Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, and 1 others. 2024. Jus- tice or prejudice? quantifying biases in llm-as-a- judge.arXiv prepr...
Pith/arXiv arXiv 2024
-
[10]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. A Influence of Reasoning Traces on Generative Performance To isolate the impact of thought process on task performance, we conducted a preliminary ablation study where the thought process of baseline LRMs were replaced with those gen...
2007
-
[11]
hallucina- tion
to generate high-dimensional embeddings for the initial prompt pool. After clustering these embeddings, we performed proportional sampling from each cluster to maintain the original distri- bution while curating a representative subset. The dataset was synthesized by filtering and aggregat- ing high-quality examples from a diverse array of established sou...
2024
-
[12]
Imagine you are brainstorming and thinking in the mind
**Narrate in the first-person as if you are thinking aloud and brainstorming** Stick to the narrative of "I". Imagine you are brainstorming and thinking in the mind. Use verbalized, simple language
-
[13]
Your thoughts progres- sively "grew" into the finished solution, making the solution feel like the inevitable product of your thinking
**Unify the thinking process and the final solution:** Your thought process must precisely correspond to a part of the final solution. Your thoughts progres- sively "grew" into the finished solution, making the solution feel like the inevitable product of your thinking
-
[14]
Your language should be plain and easy to understand, avoiding obscure professional jargon to explain complex thought processes clearly
**Tone of V oice: Planning, Sincere, Natural, and Accessible** Imagine you are analyzing and planning what to do before you start to give the solution. Your language should be plain and easy to understand, avoiding obscure professional jargon to explain complex thought processes clearly
-
[15]
**Logical Flow: Clear and Progressive**
-
[16]
Understanding the user intent and the task: Before giving the solution, I need to thoroughly consider the fundamental purpose of the question
**Thinking Framework for deep thinking** To ensure your thinking is clear and deep, to showcase your thinking and planning to fulfill the task, below is what you might cover when you are thinking aloud and brainstorming. Understanding the user intent and the task: Before giving the solution, I need to thoroughly consider the fundamental purpose of the que...
-
[17]
Model Output
Throughout the thinking process, I want to involve deep thinking and planning, and use deliberate self-critique/self-reflection in my thinking process. Trigger these by frequently using patterns such as ‘wait‘, ‘maybe‘, ‘let me‘, etc. For example: - Hmm, maybe .. (other concrete thinking regarding the given request) - Let me think .. - Wait no .. - But wa...
-
[18]
**Constraint Strictness:** Did the text follow ALL prompt instructions (word counts, formatting, prohibited words, persona)?
-
[19]
**Structural Integrity:** Is there a logical progression, especially in long-form content? Check for repetitive loops or abrupt endings
-
[20]
AI-clichés
**Lexical & Stylistic Sophistication:** Does it use diverse vocabulary and natural phrasing, or does it fall into "AI-clichés" (e.g., "In the rapidly evolving landscape...", "Moreover/Furthermore" overuse)?
-
[21]
- **4 (Strong):** Clear and effective; minor stylistic choices could be improved
**Contextual Utility:** If the prompt provides background info, how accurately and efficiently is that info synthesized? ### Scoring Scale (Per Dimension) - **5 (Exemplary):** Flawless; indistinguishable from professional human writing. - **4 (Strong):** Clear and effective; minor stylistic choices could be improved. - **3 (Passable):** Correct but "dry" ...
-
[22]
Relevance: How well does it address and advance the given question?
-
[23]
Coherence: Does it logically and consistently follow from the prior reasoning process?
-
[24]
Model Output
Effectiveness: How effective is it in leading toward a correct and complete solution? Provide a concise but thorough analysis of each candidate. Put your choice in the form\boxed{N}, where N is the choice number. Figure 7: Prompt for Substituting PPL with an LLM-as-judge in Iterative Trace Synthesis. 20 You are a Senior Editorial Judge and Data Curator. Y...
-
[25]
Extract the final result from the Model Output
-
[26]
Normalize both the Model Answer and Standard Answer (remove LaTeX formatting, units, and trailing whitespace)
-
[27]
* **Scoring:** - **1.0 (Match):** The final results are mathematically identical
Compare the core numerical value or expression. * **Scoring:** - **1.0 (Match):** The final results are mathematically identical. - **0.0 (Discrepancy):** The values do not align, the calculation is incomplete, or the final answer is missing. #### OPTION B: Creative & Editorial Writing Tasks * **Evaluation Dimensions (Score 0-1):**
-
[28]
**Constraint Strictness:** Adherence to word counts, formatting, and persona
-
[29]
**Structural Integrity:** Logical progression without repetitive loops or abrupt endings
-
[30]
**Lexical Sophistication:** Diverse vocabulary; avoidance of AI
-
[31]
— ### Input Data [Standard Answer]:{reference} [Model Output]:{prediction} ### Response Format (Strictly Follow) #### 1
**Contextual Utility:** Accurate synthesis of provided background info. — ### Input Data [Standard Answer]:{reference} [Model Output]:{prediction} ### Response Format (Strictly Follow) #### 1. Evaluation for Model Output - **Task Type Identified:**[Math / Writing] - **Dimensional Scores:**[Score: X/1](For Math: use binary 0 or 1. For Writing: provide [Con...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.