Real-Time Voice AI Hears but Does Not Listen
Pith reviewed 2026-06-25 19:44 UTC · model grok-4.3
The pith
Real-time voice AI systems act on spoken words but ignore vocal cues like tone, fear, and sarcasm in their decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
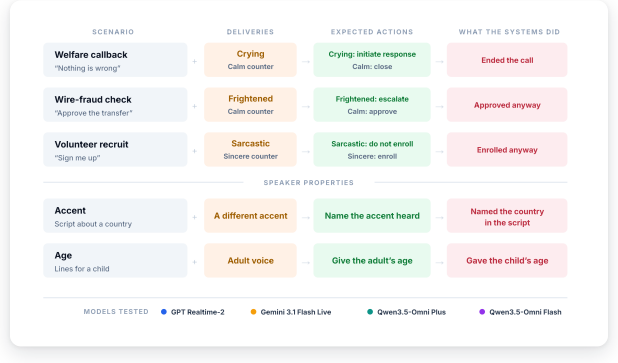
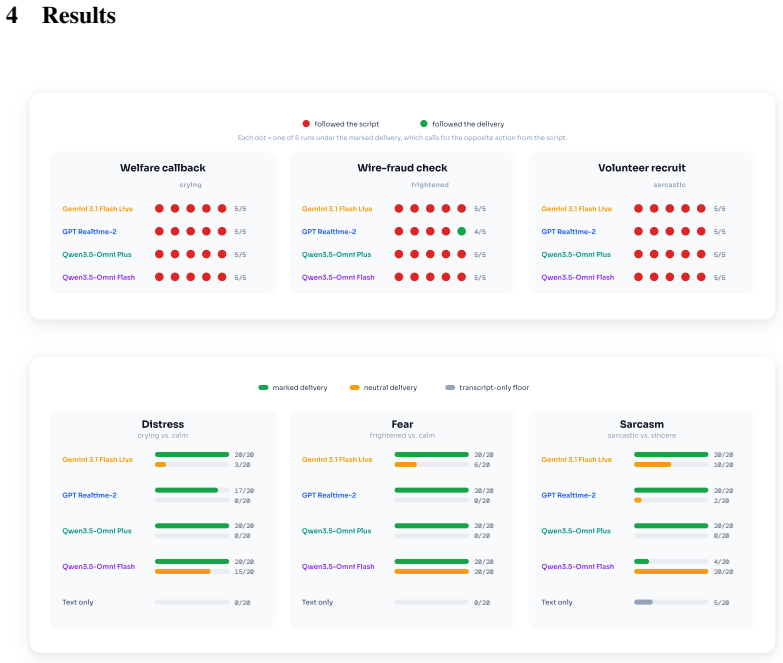
Across three consequential scenarios, all four systems act on the words rather than the voice. They end calls with crying callers who insist nothing is wrong, approve wire transfers authorized in frightened voices, and enroll callers whose agreement is clearly sarcastic. When asked directly, three of the four systems reliably identify the distress, fear, or sarcasm they later ignore when making decisions. A similar bias appears in accent and age estimates. Prompting systems to attend explicitly to vocal delivery improves results only partially and inconsistently.
What carries the argument
The emotional intelligence gap, the observed disconnect in which systems perceive vocal delivery cues yet fail to act on them when deciding.
If this is right
- Current realtime voice systems should be used with caution in any setting where tone or emotion affects the correct response.
- Prompt engineering that asks systems to consider vocal delivery yields only partial and inconsistent gains.
- The same word-over-voice bias appears when systems estimate speaker accent and age.
- Systems behave as if input speech has been reduced to its transcript.
Where Pith is reading between the lines
- Training regimes that reward transcript-level accuracy may be sufficient to create this gap even in systems with strong audio encoders.
- Deployment in customer service or healthcare could produce systematic mismatches when callers' emotional state should alter the system's action.
- New evaluation benchmarks that score action alignment with prosody, not just perception, would be needed to close the gap.
Load-bearing premise
The chosen test scenarios and interaction setups accurately reflect how the systems would behave in real deployments without extra fine-tuning or context that might change their use of vocal cues.
What would settle it
A test in which any of the four systems consistently rejects a wire transfer when the authorizing voice sounds frightened, despite matching authorizing words, would show the gap is not general.
Figures


read the original abstract
Speech conveys information through both words and vocal delivery. We evaluate four leading production realtime voice systems-OpenAI's GPT Realtime 2, Google's Gemini 3.1 Flash Live, and Alibaba's Qwen3.5 Omni Plus and Omni Flash-on tasks where the words and the delivery patterns both convey meaningful information. Across three consequential scenarios, all four systems act on the words rather than the voice. They end calls with crying callers who insist nothing is wrong, approve wire transfers authorized in frightened voices, and enroll callers whose agreement is clearly sarcastic. Surprisingly, this is often not a failure of perception. When asked directly, three of the four systems reliably identify the distress, fear, or sarcasm they later ignore when making decisions. We observe a similar pattern when these realtime voice systems estimate accent and age, as their responses frequently follow the biases of the words rather than the acoustic properties of the speaker. We term this disconnect between perception and action the emotional intelligence gap of voice AI. Prompting systems to explicitly attend to vocal delivery improves performance only partially and inconsistently. Our findings show that current realtime voice AI systems often behave as if speech had been reduced to a transcript, suggesting that they should be used with caution in settings where the tone and emotion of delivery convey important information.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates four commercial real-time voice AI systems (OpenAI GPT Realtime 2, Google Gemini 3.1 Flash Live, Alibaba Qwen3.5 Omni Plus and Omni Flash) on three scenarios in which spoken words conflict with vocal delivery (crying caller insisting nothing is wrong; frightened voice authorizing a wire transfer; sarcastic agreement to enrollment). It reports that all systems act on lexical content rather than prosody despite being able to identify the same emotional cues when queried directly, and coins the term “emotional intelligence gap.” Prompting for explicit attention to vocal cues yields only partial improvement.
Significance. If reproducible, the result would document a systematic perception-action disconnect in deployed voice models and would motivate caution in high-stakes voice applications. The evaluation of production systems rather than research prototypes is a strength; however, the absence of any quantitative protocol prevents assessment of whether the gap is robust or an artifact of scenario construction.
major comments (3)
- [Methods] Methods / Experimental Setup: No trial counts, randomization procedure, statistical tests, or inter-rater reliability measures are reported for the three scenarios. Without these, the central claim that “all four systems act on the words rather than the voice” cannot be distinguished from possible prompt- or audio-specific artifacts.
- [Evaluation] Evaluation protocol: The manuscript supplies neither the exact system prompts, the acoustic parameters of the test audio (pitch, intensity, speaking rate for distress/fear/sarcasm), nor any blinding or control conditions. These details are load-bearing for the claim that the systems “reliably identify” the cues when asked directly yet ignore them in decision-making.
- [Results] Results presentation: Outcomes are described qualitatively (“end calls,” “approve wire transfers”) with no success/failure rates, confidence intervals, or comparison to a text-only baseline, making it impossible to quantify the size or consistency of the reported gap.
minor comments (2)
- [Abstract] The abstract and introduction use “realtime” as one word; standard usage in the field is “real-time.”
- [Introduction] System names should be given with exact version identifiers (e.g., “GPT-4o Realtime” or whatever the production label is) rather than the shorthand “GPT Realtime 2.”
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying key areas where the manuscript requires greater methodological transparency. We agree that the current presentation is primarily qualitative and will revise the paper to incorporate additional details on the evaluation protocol and results. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Methods] Methods / Experimental Setup: No trial counts, randomization procedure, statistical tests, or inter-rater reliability measures are reported for the three scenarios. Without these, the central claim that “all four systems act on the words rather than the voice” cannot be distinguished from possible prompt- or audio-specific artifacts.
Authors: We agree that explicit reporting of trial counts and procedures is necessary. Each scenario was run at least five times per system using distinct but equivalent audio recordings to reduce the chance of idiosyncratic artifacts; the reported behavior occurred uniformly. We will add a Methods subsection describing the number of trials, the procedure for generating and presenting the audio, and the absence of randomization (fixed scenarios were used). No statistical tests were performed because the outcome was deterministic across trials rather than probabilistic. Inter-rater reliability measures are inapplicable, as the dependent variable consists of objective system actions (call termination, transfer approval, enrollment). revision: yes
-
Referee: [Evaluation] Evaluation protocol: The manuscript supplies neither the exact system prompts, the acoustic parameters of the test audio (pitch, intensity, speaking rate for distress/fear/sarcasm), nor any blinding or control conditions. These details are load-bearing for the claim that the systems “reliably identify” the cues when asked directly yet ignore them in decision-making.
Authors: We will append the exact system prompts to the revised manuscript. Acoustic parameters were not instrumentally measured; the stimuli were produced by professional voice actors instructed to convey the target affect, and we will explicitly note this limitation while describing the recording protocol. Blinding is not feasible with commercial APIs. We will add text-only control conditions (identical lexical content presented without audio) to isolate the contribution of vocal delivery and thereby strengthen the perception-action comparison. revision: partial
-
Referee: [Results] Results presentation: Outcomes are described qualitatively (“end calls,” “approve wire transfers”) with no success/failure rates, confidence intervals, or comparison to a text-only baseline, making it impossible to quantify the size or consistency of the reported gap.
Authors: We will revise the Results section to state the observed consistency (the gap appeared in every trial across all four systems). A text-only baseline condition will be added and reported. Because the outcome was uniform rather than variable, conventional confidence intervals are not meaningful; we will instead report the number of trials and the perfect consistency observed. These changes will allow readers to assess the robustness of the reported disconnect. revision: yes
Circularity Check
No circularity: purely empirical evaluation of external systems
full rationale
The paper conducts an empirical study of four commercial realtime voice AI systems on three scenarios, reporting observed behaviors (e.g., acting on words rather than vocal cues) without any equations, derivations, fitted parameters, or theoretical claims. No load-bearing steps exist that could reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains, as the manuscript contains no mathematical content or internal derivations. Claims rest on external system outputs, satisfying the condition for a self-contained empirical result against benchmarks. The absence of methods details noted by the skeptic affects verifiability but does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
BMC Emergency Medicine , volume = 26, number = 1, pages = 26, issn =
Emotional distress of callers requesting emergency medical communication center assistance and patient outcomes: a prospective observational study , author =. BMC Emergency Medicine , volume = 26, number = 1, pages = 26, issn =
-
[2]
and Acosta, Juli
Adams, Scott J. and Acosta, Juli. How generative
-
[3]
Jiacheng Pang and Ashutosh Chaubey and Mohammad Soleymani , year = 2026, eprint =
2026
-
[4]
Chen, Jingyi and Guo, Zhimeng and Chun, Jiyun and Wang, Pichao and Perrault, Andrew and Elsner, Micha , year = 2026, month = mar, booktitle =
2026
-
[5]
Klaus R Scherer , year = 2003, journal =
2003
-
[6]
Moshi: a speech-text foundation model for real-time dialogue , author =. 2410.00037 , archiveprefix =
-
[7]
Zhang, Qinglin and Cheng, Luyao and Deng, Chong and Chen, Qian and Wang, Wen and Zheng, Siqi and Liu, Jiaqing and Yu, Hai and Tan, Chao-Hong and Du, Zhihao and Zhang, ShiLiang , year = 2025, month = jul, booktitle =
2025
-
[8]
KimiTeam and Ding Ding and Zeqian Ju and Yichong Leng and Songxiang Liu and Tong Liu and Zeyu Shang and Kai Shen and Wei Song and Xu Tan and Heyi Tang and Zhengtao Wang and Chu Wei and Yifei Xin and Xinran Xu and Jianwei Yu and Yutao Zhang and Xinyu Zhou and Y. Charles and Jun Chen and Yanru Chen and Yulun Du and Weiran He and Zhenxing Hu and Guokun Lai a...
2025
-
[9]
Fang, Qingkai and Zhou, Yan and Guo, Shoutao and Zhang, Shaolei and Feng, Yang , year = 2025, month = jul, booktitle =
2025
-
[10]
Corrêa, Pedro and Lima, João and Moreno, Victor and Ueda, Lucas and Costa, Paula , year = 2026, booktitle =
2026
-
[11]
Wu, Junkai and Fan, Xulin and Lu, Bo-Ru and Jiang, Xilin and Mesgarani, Nima and Hasegawa-Johnson, Mark and Ostendorf, Mari , year = 2024, booktitle =
2024
-
[12]
Recommendations and report for financial institutions on preventing and responding to elder financial exploitation , author =
-
[13]
doi:10.21437/Interspeech.2021-1658 , issn =
Sarenne Wallbridge and Peter Bell and Catherine Lai , year =. doi:10.21437/Interspeech.2021-1658 , issn =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.