Life After Benchmark Saturation: A Case Study of CORE-Bench
Pith reviewed 2026-06-26 01:16 UTC · model grok-4.3
The pith
After accuracy saturates, benchmarks retain value by tracking efficiency, reliability, and human collaboration effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Even after agents reach high accuracy on CORE-Bench, the six dimensions of construct validity, out-of-distribution generalizability, efficiency, reliability, model-versus-scaffold importance, and human-agent uplift continue to produce distinguishable and actionable differences in performance.
What carries the argument
The six post-saturation performance dimensions applied to the CORE-Bench reproducibility task suite.
If this is right
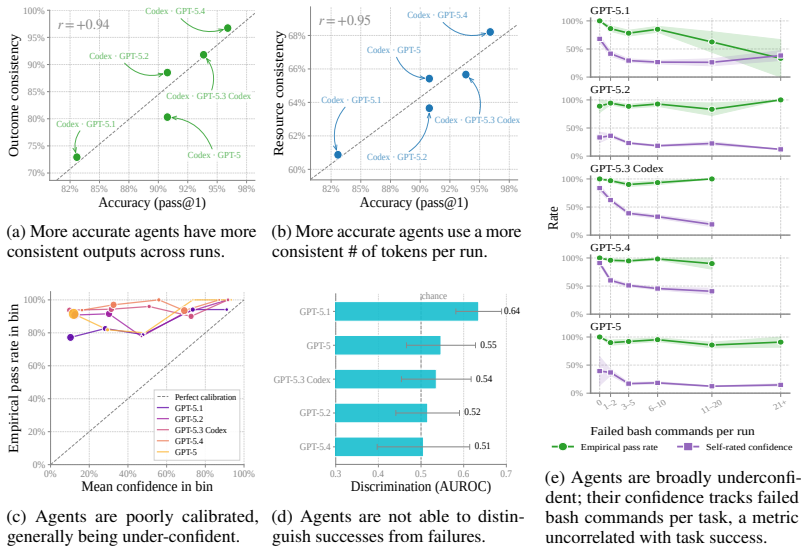
- Efficiency and reliability differences remain detectable on CORE-Bench v1.1 even when accuracy has plateaued.
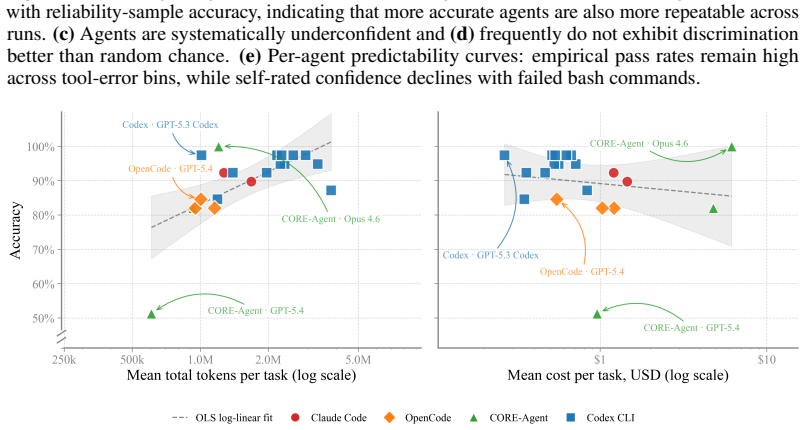
- Model and scaffold contributions can be separated and compared independently.
- Human-agent teams achieve a measurable reduction in task completion time on real reproducibility work.
- Improved benchmark versions can reveal construct validity issues that weaker agents did not expose.
Where Pith is reading between the lines
- The same multi-dimension approach could extend the useful life of other saturated agent benchmarks beyond CORE-Bench.
- Focusing on human uplift may encourage design of scaffolds that complement rather than replace human effort.
Load-bearing premise
That the six listed dimensions are the main ones worth tracking after saturation and that the small randomized experiment on reproducibility tasks supplies representative evidence of collaboration benefits.
What would settle it
A larger set of saturated benchmarks where these six dimensions show no new distinctions between agents, or a follow-up human-agent experiment that finds no reliable speedup.
Figures

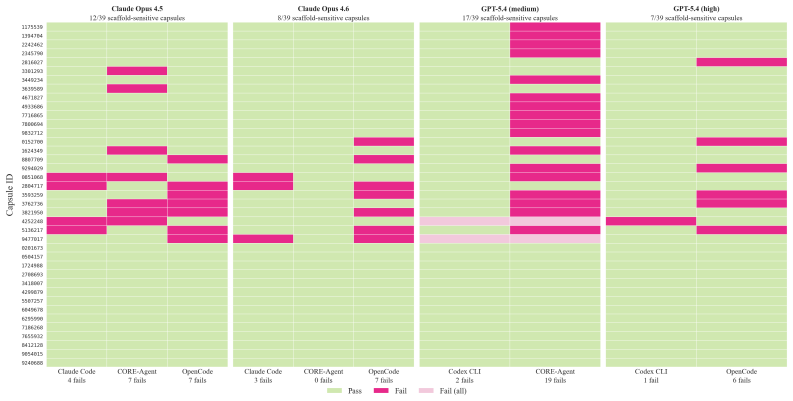
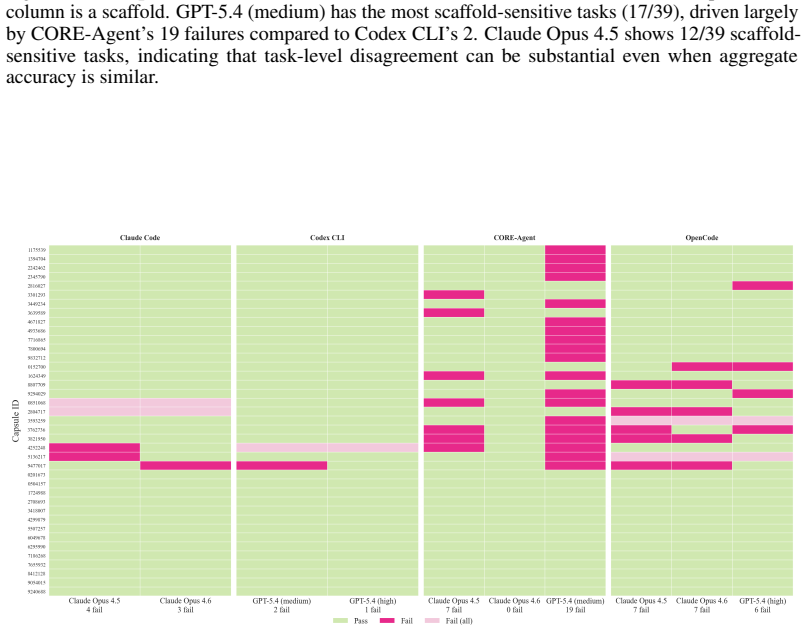
read the original abstract
When a benchmark's accuracy saturates, it is often retired and replaced with a more challenging version. We show that this approach privileges accuracy and misses the opportunity to study six other key dimensions of agent performance: construct validity issues such as shortcuts, out-of-distribution generalizability, efficiency, reliability, the relative importance of the model versus the scaffold, and uplift from human-agent collaboration. We use CORE-Bench Hard, a benchmark for computational reproducibility of scientific code, as a case study to demonstrate that measuring agents along these dimensions yields meaningful insights into agent performance even after accuracy saturates. First, we surface threats to construct validity in CORE-Bench Hard that are difficult to anticipate with less capable agents. We introduce an improved benchmark, CORE-Bench v1.1, and an out-of-distribution task suite, CORE-Bench OOD. Second, we find that despite accuracy saturation, CORE-Bench v1.1 remains useful for measuring efficiency, reliability, model performance, and scaffold performance. Finally, we conduct a small-scale randomized experiment to measure uplift from human-agent collaboration on real-world computational reproducibility tasks. We find a statistically significant speedup by about a factor of two -- likely underestimated due to one-fifth of human-only reproductions reaching the time limit before completing -- and describe various other findings. Together, our contributions present a more rigorous alternative to the dominant accuracy-centric evaluation paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that accuracy saturation on benchmarks like CORE-Bench Hard should prompt multi-dimensional evaluation rather than retirement. Using CORE-Bench as a case study, it identifies six additional dimensions (construct validity/shortcuts, OOD generalizability, efficiency, reliability, model vs. scaffold, and human-agent uplift), releases CORE-Bench v1.1 and an OOD task suite to surface validity threats, demonstrates continued utility of the benchmark for the non-accuracy dimensions, and reports a small-scale randomized experiment finding a statistically significant ~2x speedup from human-agent collaboration on real-world reproducibility tasks (likely underestimated due to time limits).
Significance. If the experimental evidence holds, the work provides a concrete, extensible alternative to accuracy-centric benchmark retirement that could prolong the scientific value of saturated benchmarks in agent evaluation. The release of v1.1 and OOD suites, together with the empirical collaboration result, supplies falsifiable, multi-dimensional data that directly addresses a practical problem in the field.
major comments (2)
- [Abstract] Abstract (final paragraph on the randomized experiment): The claim of a statistically significant ~2x speedup from human-agent collaboration is load-bearing for the human-agent uplift dimension, yet the manuscript provides no sample size (n), task selection criteria, randomization details, power analysis, or statistical test. Without these, it is impossible to assess whether the result supports generalization beyond the specific tasks or is robust to the noted time-limit censoring.
- [Abstract] Abstract and methods description: The paper states that threats to construct validity in CORE-Bench Hard 'are difficult to anticipate with less capable agents' and that v1.1 addresses them, but supplies no concrete examples of the shortcuts discovered, no quantitative before/after comparison of validity metrics, and no table enumerating the changes between Hard and v1.1. This information is required to evaluate whether the new benchmark actually improves construct validity.
minor comments (2)
- [Abstract] The abstract refers to 'one-fifth of human-only reproductions reaching the time limit' but does not indicate where the supporting breakdown (counts, per-task times) appears in the main text or supplementary material.
- The six dimensions are introduced as 'key' without an explicit operationalization table or reference to prior literature justifying the selection over other candidate dimensions (e.g., safety or calibration).
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight areas where additional methodological details would strengthen the manuscript. We address each point below and plan revisions accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph on the randomized experiment): The claim of a statistically significant ~2x speedup from human-agent collaboration is load-bearing for the human-agent uplift dimension, yet the manuscript provides no sample size (n), task selection criteria, randomization details, power analysis, or statistical test. Without these, it is impossible to assess whether the result supports generalization beyond the specific tasks or is robust to the noted time-limit censoring.
Authors: We acknowledge that the abstract and current methods description lack these critical details. Upon revision, we will expand the relevant sections to report the sample size, task selection criteria, randomization details, power analysis, and the statistical test employed. This will allow readers to better evaluate the robustness of the ~2x speedup finding, including considerations for time-limit censoring. revision: yes
-
Referee: [Abstract] Abstract and methods description: The paper states that threats to construct validity in CORE-Bench Hard 'are difficult to anticipate with less capable agents' and that v1.1 addresses them, but supplies no concrete examples of the shortcuts discovered, no quantitative before/after comparison of validity metrics, and no table enumerating the changes between Hard and v1.1. This information is required to evaluate whether the new benchmark actually improves construct validity.
Authors: We agree that concrete examples, quantitative comparisons, and a change table are necessary to substantiate the improvements in construct validity. In the revised manuscript, we will provide specific examples of shortcuts identified, before/after validity metrics where available, and a table detailing the modifications from CORE-Bench Hard to v1.1. revision: yes
Circularity Check
No circularity: empirical case study with no derivations or self-referential reductions
full rationale
The paper is an empirical case study involving benchmark modification (CORE-Bench v1.1 and OOD suite), measurement of six performance dimensions, and a small-scale randomized experiment on human-agent collaboration. No mathematical derivations, fitted parameters called predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text or abstract. Claims rest on direct experimental observations and benchmark construction rather than any reduction of outputs to inputs by construction. This is the expected outcome for a non-derivational empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmarks should be evaluated on multiple performance dimensions beyond accuracy even after saturation occurs
Reference graph
Works this paper leans on
-
[1]
James Adams, David Bracken, Noam Gidron, Will Horne, Diana Z. O’Brien, and Kaitlin Senk. Can’t we all just get along? how women MPs can ameliorate affective polarization in western publics.American Political Science Review, 2023. doi: 10.1017/S0003055422000491. URL https://doi.org/10.1017/S0003055422000491
-
[2]
Mubashara Akhtar, Anka Reuel, Prajna Soni, Sanchit Ahuja, Pawan Sasanka Ammanamanchi, Ruchit Rawal, Vilém Zouhar, Srishti Yadav, Chenxi Whitehouse, Dayeon Ki, Jennifer Mickel, Leshem Choshen, Marek Šuppa, Jan Batzner, Jenny Chim, Jeba Sania, Yanan Long, Hos- sein A. Rahmani, Christina Knight, Yiyang Nan, Jyoutir Raj, Yu Fan, Shubham Singh, Sub- ramanyam S...
Pith/arXiv arXiv 2026
-
[3]
Claude Code, 2025
Anthropic. Claude Code, 2025. URLhttps://www.claude.com/product/claude-code. 11
2025
-
[4]
Sabrina B. Arias and Christopher W. Blair. Changing tides: Public attitudes on climate migration. Journal of Politics, 2022. doi: 10.1086/715163. URLhttps://doi.org/10.1086/715163
-
[5]
Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples
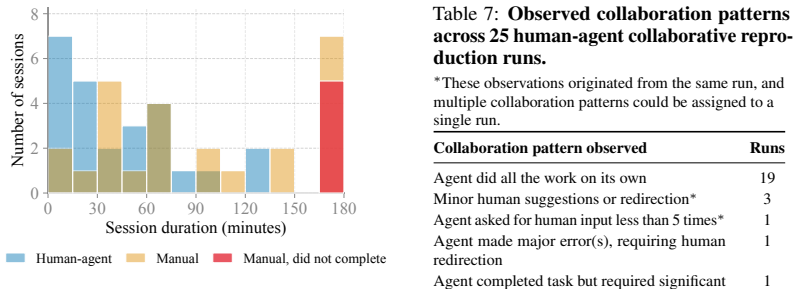
Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 274–283. PMLR, 10–15 Jul 2018. U...
2018
-
[6]
Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity, July 2025
Joel Becker, Nate Rush, Elizabeth Barnes, and David Rein. Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity, July 2025. URL http://arxiv. org/abs/2507.09089. arXiv:2507.09089 [cs]
arXiv 2025
-
[7]
AgentX AgentBeats Competition, 2026
Berkeley RDI. AgentX AgentBeats Competition, 2026. URL https://rdi.berkeley.edu/ agentx-agentbeats
2026
-
[8]
Le, Christopher Ré, and Azalia Mirhoseini
Bradley Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V . Le, Christopher Ré, and Azalia Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling. arXiv preprint arXiv:2407.21787, 2024. URLhttps://arxiv.org/abs/2407.21787
Pith/arXiv arXiv 2024
-
[9]
MultiWOZ: A large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling
Paweł Budzianowski, Tsung-Hsien Wen, Bo-Hsiang Tseng, Iñigo Casanueva, Stefan Ultes, Osman Ramadan, and Milica Gaši´c. MultiWOZ - a large-scale multi-domain Wizard-of-Oz dataset for task-oriented dialogue modelling. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Nat...
-
[10]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[11]
ARC-AGI-1, 2019
Francois Chollet. ARC-AGI-1, 2019. URLhttps://arcprize.org/arc-agi/1
2019
-
[12]
ARC- AGI-2: A New Challenge for Frontier AI Reasoning Systems, January 2026
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. ARC- AGI-2: A New Challenge for Frontier AI Reasoning Systems, January 2026. URL http: //arxiv.org/abs/2505.11831. arXiv:2505.11831 [cs.AI]
Pith/arXiv arXiv 2026
-
[13]
Jimenez, John Yang, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Alijubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Kevin Liu, and Aleksander Madry. Introducing SWE-bench Verified, August 2024. URL https://openai.com/index/introducing-swe-bench-verified/
2024
-
[14]
Davenport, Annie Franco, and Shanto Iyengar
Lauren D. Davenport, Annie Franco, and Shanto Iyengar. Multiracial identity and political preferences.Journal of Politics, 2022. doi: 10.1086/714760. URL https://doi.org/10. 1086/714760
-
[15]
SWE-Bench Pro: Can AI Agents Solve Long- Horizon Software Engineering Tasks?, 2025
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. SWE-Bench Pro: Can AI Agents Solve Long- H...
Pith/arXiv arXiv 2025
-
[16]
Yellow vests, pessimistic beliefs, and carbon tax aversion
Thomas Douenne and Adrien Fabre. Yellow vests, pessimistic beliefs, and carbon tax aversion. American Economic Journal: Economic Policy, 2022. doi: 10.1257/pol.20200092. URL https://doi.org/10.1257/pol.20200092
-
[17]
AI Built For Excel, 2026
Endex. AI Built For Excel, 2026. URLhttps://endex.ai
2026
-
[18]
AI best papers: Top research papers in AI, ML, CV, and NLP
Eppner, Clemens. AI best papers: Top research papers in AI, ML, CV, and NLP. https: //aibestpape.rs/?sub=AI,ML,CV,NLP, 2026
2026
-
[19]
Latxa: An open language model and evaluation suite for Basque
Julen Etxaniz, Oscar Sainz, Naiara Perez, Itziar Aldabe, German Rigau, Eneko Agirre, Aitor Ormazabal, Mikel Artetxe, and Aitor Soroa. Latxa: An open language model and evaluation suite for Basque. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Lon...
-
[20]
DropMes- sage: Unifying random dropping for graph neural networks
Taoran Fang, Zhiqing Xiao, Chunping Wang, Jiarong Xu, Xuan Yang, and Yang Yang. DropMes- sage: Unifying random dropping for graph neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, 2023. URL https://doi.org/10.1609/aaai.v37i4. 25545
-
[21]
ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence, March 2026
ARC Prize Foundation. ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence, March 2026. URLhttp://arxiv.org/abs/2603.24621. arXiv:2603.24621 [cs]
Pith/arXiv arXiv 2026
-
[22]
Improving evaluation of machine translation quality estimation
Yvette Graham. Improving evaluation of machine translation quality estimation. InProceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (ACL), 2015. URL https://www.aclweb.org/anthology/P15-1174/
2015
-
[23]
Nature645(8081), 633–638 (Sep 2025)
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, et al. Deepseek-r1 incentivizes reasoning in LLMs through reinforcement learning.Nature, 645(8081):633–638, 2025. doi: 10.1038/s41586-025-09422-z. URLhttps://www.nature.com/articles/s41586-025-09422-z
-
[24]
Cheating On AI Agent Evaluations, November 2025
Maia Hamin and Benjamin Edelman. Cheating On AI Agent Evaluations, November 2025. URL https://www.nist.gov/caisi/cheating-ai-agent-evaluations . Last Modi- fied: 2025-12-02T12:20-05:00
2025
-
[25]
Building the Business Case for Legal AI | In-House Guide from Harvey, 2022
Harvey. Building the Business Case for Legal AI | In-House Guide from Harvey, 2022. URL https://www.harvey.ai/
2022
-
[26]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum? id=d7KBjmI3GmQ
2021
-
[27]
Antinormative messaging, group cues, and the nuclear ban treaty.Journal of Politics, 2022
Stephen Herzog, Jonathon Baron, and Rebecca Davis Gibbons. Antinormative messaging, group cues, and the nuclear ban treaty.Journal of Politics, 2022. doi: 10.1086/714924. URL https://doi.org/10.1086/714924
-
[28]
Measuring mid-2025 llm-assistance on novice performance in biology, 2026
Shen Zhou Hong, Alex Kleinman, Alyssa Mathiowetz, Adam Howes, Julian Cohen, Suveer Ganta, Alex Letizia, Dora Liao, Deepika Pahari, Xavier Roberts-Gaal, Luca Righetti, and Joe Torres. Measuring mid-2025 llm-assistance on novice performance in biology, 2026. URL https://arxiv.org/abs/2602.16703
arXiv 2025
-
[29]
Meta database, version 1.https://i4replication.org/reports/ ?cpt=metadata, 2024
Institute for Replication. Meta database, version 1.https://i4replication.org/reports/ ?cpt=metadata, 2024
2024
-
[30]
SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=VTF8yNQM66. 13
2024
-
[31]
Siegel, Nitya Nadgir, and Arvind Narayanan
Sayash Kapoor, Benedikt Stroebl, Zachary S. Siegel, Nitya Nadgir, and Arvind Narayanan. AI Agents That Matter.Transactions on Machine Learning Research, February 2025. ISSN 2835-8856. URLhttps://openreview.net/forum?id=Zy4uFzMviZ
2025
-
[32]
Holistic agent leaderboard: The missing infrastructure for AI agent evaluation
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, Franck Ndzomga, Dheeraj Oruganty, Sophie Luskin, Kangheng Liu, Botao Yu, Amit Arora, Dongyoon Hahm, Harsh Trivedi, Huan Sun, Juyong Lee, Tengjun Jin, Yifan Mai, Yifei Zhou, Yuxuan Zhu, Rishi Bommasani, Daniel Kang, Da...
2026
-
[33]
Entertaining beliefs in economic mobility.American Journal of Political Science,
Eunji Kim. Entertaining beliefs in economic mobility.American Journal of Political Science,
-
[34]
URLhttps://doi.org/10.1111/ajps.12702
doi: 10.1111/ajps.12702. URLhttps://doi.org/10.1111/ajps.12702
-
[35]
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D Manning, Christopher Re, Diana Acosta-Navas, Drew A. Hudson, Eric Zelikman, Esin Durmus, Faisal Ladhak, Frieda Rong, Hongyu ...
2023
-
[36]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 21558–21572. Curran Associate...
2023
-
[37]
Gabriel López-Moctezuma, Leonard Wantchekon, Daniel Rubenson, Thomas Fujiwara, and Cecilia Pe Lero. Policy deliberation and voter persuasion: Experimental evidence from an election in the Philippines.American Journal of Political Science, 2022. doi: 10.1111/ajps. 12566. URLhttps://doi.org/10.1111/ajps.12566
-
[38]
Towards end-to-end automation of AI research
Chris Lu, Cong Lu, Robert Tjarko Lange, Yutaro Yamada, Shengran Hu, Jakob Foerster, David Ha, and Jeff Clune. Towards end-to-end automation of AI research.Nature, 651(8107):914– 919, March 2026. ISSN 0028-0836, 1476-4687. doi: 10.1038/s41586-026-10265-5. URL https://www.nature.com/articles/s41586-026-10265-5
-
[39]
Semisupervised neural proto-language recon- struction
Liang Lu, Peirong Xie, and David Mortensen. Semisupervised neural proto-language recon- struction. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 14715–14759, Bangkok, Thailand, August 2024. Association for Computational Ling...
-
[40]
Fantastically ordered prompts an d where to find them: Overcoming few-shot prompt order sensitivity
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts an d where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL),
-
[41]
URLhttps://aclanthology.org/2022.acl-long.556/
2022
-
[42]
Introducing docent, March 2025
Kevin Meng, Vincent Huang, Jacob Steinhardt, and Sarah Schwettmann. Introducing docent, March 2025. URLhttps://transluce.org/introducing-docent
2025
-
[43]
Adriana Molina-Garzón, Tara Grillos, Alan Zarychta, and Krister P. Andersson. Decentralization can increase cooperation among public officials.American Journal of Political Science, 2022. doi: 10.1111/ajps.12606. URLhttps://doi.org/10.1111/ajps.12606. 14
-
[44]
How much does ai impact development speed? an enterprise-based randomized controlled trial
Elise Paradis, Kate Grey, Quinn Madison, Daye Nam, Andrew Macvean, Vahid Meimand, Nan Zhang, Ben Ferrari-Church, and Satish Chandra. How much does ai impact development speed? an enterprise-based randomized controlled trial. In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), pages 618–629, ...
-
[45]
MALT: A Dataset of Natural and Prompted Be- haviors That Threaten Eval Integrity, October 2025
Neev Parikh and Hjalmar Wijk. MALT: A Dataset of Natural and Prompted Be- haviors That Threaten Eval Integrity, October 2025. URL https://metr.org/blog/ 2025-10-14-malt-dataset-of-natural-and-prompted-behaviors/
2025
-
[46]
Patricia Paskov, Kevin Wei, Shen Zhou Hong, Dan Bateyko, Xavier Roberts-Gaal, Carson Ezell, Gailius Praninskas, Valerie Chen, Umang Bhatt, and Ella Guest. Rcts & human uplift studies: Methodological challenges and practical solutions for frontier ai evaluation, 2026. URL https://arxiv.org/abs/2603.11001
Pith/arXiv arXiv 2026
-
[47]
Pustejovsky.clubSandwich: Cluster-Robust (Sandwich) Variance Estimators with Small-Sample Corrections, 2026
James E. Pustejovsky.clubSandwich: Cluster-Robust (Sandwich) Variance Estimators with Small-Sample Corrections, 2026. URL https://CRAN.R-project.org/package= clubSandwich. R package version 0.7.0
2026
-
[48]
Pustejovsky and Elizabeth Tipton
James E. Pustejovsky and Elizabeth Tipton. Small-sample methods for cluster-robust variance estimation and hypothesis testing in fixed effects models.Journal of Business & Economic Statistics, 36(4):672–683, 2018. doi: 10.1080/07350015.2016.1247004. URL https://doi. org/10.1080/07350015.2016.1247004
-
[49]
Towards a Science of AI Agent Reliability, February 2026
Stephan Rabanser, Sayash Kapoor, Peter Kirgis, Kangheng Liu, Saiteja Utpala, and Arvind Narayanan. Towards a Science of AI Agent Reliability, February 2026. URL http://arxiv. org/abs/2602.16666. arXiv:2602.16666 [cs]
Pith/arXiv arXiv 2026
-
[50]
Beyond Accuracy: Behavioral Testing of
Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behavioral testing of NLP models with CheckList. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4902–4912, Online, 2020. Association for Computati...
-
[51]
CORE-bench: Fostering the credibility of published research through a computational re- producibility agent benchmark.Transactions on Machine Learning Research, 2024
Zachary S Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan. CORE-bench: Fostering the credibility of published research through a computational re- producibility agent benchmark.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URLhttps://openreview.net/forum?id=BsMMc4MEGS
2024
-
[52]
David Szakonyi. Indecent disclosures: Anticorruption reforms and political selection.American Journal of Political Science, 2023. doi: 10.1111/ajps.12646. URL https://doi.org/10. 1111/ajps.12646
-
[53]
A pipeline for transcript analysis using Inspect Scout, February 2026
UK AISI. A pipeline for transcript analysis using Inspect Scout, February 2026. URL https://www.aisi.gov.uk/blog/ a-pipeline-for-transcript-analysis-using-inspect-scout
2026
-
[54]
Wandb Weave, 2024
Wandb.ai. Wandb Weave, 2024. URLhttps://wandb.ai/site/weave
2024
-
[55]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J...
-
[56]
doi: 10.52202/079017-3018. URL https://proceedings.neurips.cc/paper_ files/paper/2024/file/ad236edc564f3e3156e1b2feafb99a24-Paper-Datasets_ and_Benchmarks_Track.pdf
-
[57]
Position: Humans are Missing from AI Coding Agent Research, 2025
Zora Zhiruo Wang, John Yang, Kilian Lieret, Alexa Tartaglini, Valerie Chen, Yuxiang Wei, Zijian Wang, Lingming Zhang, Karthik Narasimhan, Ludwig Schmidt, Graham Neubig, Daniel Fried, and Diyi Yang. Position: Humans are Missing from AI Coding Agent Research, 2025. URLhttps://zorazrw.github.io/files/position-haicode.pdf. 15
2025
-
[58]
Reliable conflictive multi- view learning
Cai Xu, Jiajun Si, Ziyu Guan, Wei Zhao, Yue Wu, and Xiyue Gao. Reliable conflictive multi- view learning. InProceedings of the AAAI Conference on Artificial Intelligence, 2024. URL https://doi.org/10.1609/aaai.v38i14.29546
-
[59]
{$\tau$}-bench: A benchmark for Tool-Agent-User interaction in real-world domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R Narasimhan. {$\tau$}-bench: A benchmark for Tool-Agent-User interaction in real-world domains. InThe Thirteenth Inter- national Conference on Learning Representations, 2025. URLhttps://openreview.net/ forum?id=roNSXZpUDN
2025
-
[60]
Adam Zelizer. Talking shops: The effects of caucus discussion on policy coalitions.American Journal of Political Science, 2021. doi: 10.1111/ajps.12636. URL https://doi.org/10. 1111/ajps.12636
-
[61]
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, 2021. URLhttps://doi.org/ 10.1609/aaai.v35i12.17325
-
[62]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=oKn9c6ytLx
2024
-
[63]
Establishing Best Practices for Building Rigorous Agentic Benchmarks
Yuxuan Zhu, Tengjun Jin, Yada Pruksachatkun, Andy Zhang, Shu Liu, Sasha Cui, Sayash Kapoor, Shayne Longpre, Kevin Meng, Rebecca Weiss, Fazl Barez, Rahul Gupta, Jwala Dhamala, Jacob Merizian, Mario Giulianelli, Harry Coppock, Cozmin Ududec, Jasjeet Sekhon, Jacob Steinhardt, Antony Kellermann, Sarah Schwettmann, Matei Zaharia, Ion Stoica, Percy Liang, and D...
2025
-
[64]
URL https://proceedings.neurips.cc/paper_files/paper/2025/file/ f316275b44ee2de533102913828a8107-Paper-Datasets_and_Benchmarks_Track. pdf. 16 A Technical appendices and supplementary material A.1 Benchmark update details We made the following changes to CORE-Bench Hard’s grading script when grading agent responses in CORE-Bench v1.1 and CORE-Bench OOD:
2025
-
[65]
Expanded CORE-Bench Hard’s original 95% prediction interval to accept answers that lie within the default tolerances ofnp.isclose at the upper and lower bounds of the prediction interval
-
[66]
Expanded CORE-Bench Hard’s original 95% prediction interval to accept answers where agents reported unrounded results directly from computation when the ground truth was a rounded value
-
[67]
True" or
Checked if the ground truth answer was "True" or "False" as astring, and if the agent’s answer was instead reported as a boolean. Converted the agent’s answer to a string before grading (this only affected taskcapsule-2242462)
-
[68]
evaluable
Accepted multiple answers for the tasks in Table 11. A.2 Accuracy saturation of CORE-Bench v1.1 and CORE-Bench OOD We adopt metrics from Akhtar et al. [2] that use the standard error of the difference in accuracy between the scores of top and kth agent to determine the similarity of accuracies on CORE-Bench v1.1 and CORE-Bench OOD. The standard error of t...
2011
-
[69]
More specifically:Reproduction of targets we selected from the paper (see below) looks likely to run in our setup (A40 48GB VRAM, disk space: 40GB+40GB - see evaluator instructions for details) 5.Data available (link). (where applicable) a. “Available” meaning for direct download without registration or such b. For ML papers, this might include pre-existi...
-
[70]
Compute time
Compute time limit: running the code / inference necessary for the reproduction is antici- pated to take less than 45 minutes on our hardware. Notes: a. “Compute time” refers to the cumulative duration of the agent and/or human evaluator having to wait for VM to complete compute tasks. b. This represents the compute reproduction time for all replication t...
2011
-
[71]
Agent did all the work on its own
-
[72]
Agent asked for human input less than 5 times
-
[73]
Human had to provide a minor suggestion or two to redirect agent on the right path
-
[74]
Agent made major error(s), requiring human redirection
-
[75]
Agent stopped before completing full answer(s), requiring human prodding to continue
-
[76]
Agent asked for human input/assistance for several steps
-
[77]
Agent and human worked back-and-forth as near-equal partners
-
[78]
Agent completed task but required significant scope clarification upfront
-
[79]
Agent failed completely
-
[80]
Other: 98 Where Agent added value
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.