Optimizing CUDA like a Human: Micro-Profiling Tools as Expert Surrogates for LLM-Based GPU Kernel Optimization
Pith reviewed 2026-06-26 01:10 UTC · model grok-4.3
The pith
Micro-profiling tools convert hardware metrics into natural-language guidance that lets LLMs optimize CUDA kernels to expert levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
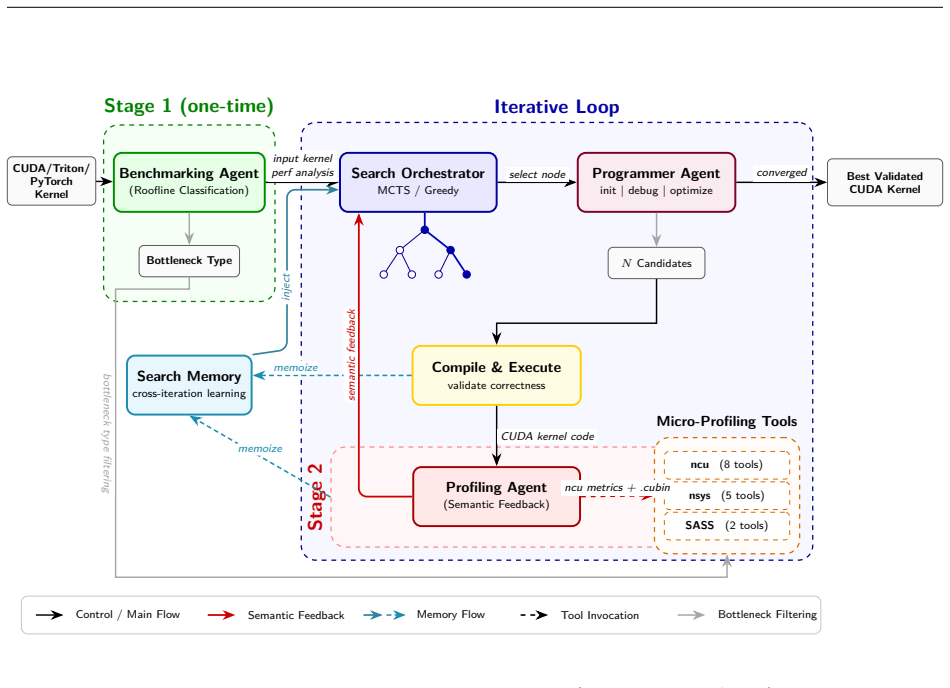
KernelPro shows that a semantic feedback operator, which maps raw hardware metrics to natural-language guidance via pluggable micro-profiling tools, combined with roofline-filtered two-stage tool invocation and a domain-adapted MCTS that includes progressive widening, dead-end pruning, and search memory, enables an LLM agent to generate optimized CUDA and CuTe kernels. These kernels achieve state-of-the-art geometric mean speedups on all three levels of KernelBench and surpass expert-optimized Triton kernels on VeOmni MoE workloads while also improving energy efficiency, with ablations confirming that each added component contributes measurable gains.
What carries the argument
The semantic feedback operator, which encodes expert heuristics as pluggable micro-profiling tools that transform raw hardware metrics into actionable natural language guidance for the LLM.
If this is right
- Micro-profiling tools produce statistically significant gains over raw metrics (p < 0.0001).
- Domain-adapted MCTS yields 26 percent higher geometric mean performance than greedy search (p = 0.004).
- Proactive tool orchestration adds 23 percent improvement (p = 0.035).
- The same system can generate raw-CUDA plus CuTe kernels that exceed hand-tuned Triton on production MoE training workloads.
- Energy efficiency can be optimized jointly with speed, producing an 11.6 percent measured reduction at matched performance.
Where Pith is reading between the lines
- The same tool-encoding pattern could be applied to other code-generation domains such as CPU vectorization or FPGA design if equivalent profiling interfaces exist.
- Search memory and cross-iteration learning may reduce the number of LLM calls needed on repeated optimization tasks for similar kernel families.
- Direct source-level generation over an existing library like CUTLASS/CuTe may generalize to other domain-specific codebases that expose composable primitives.
- Adding explicit energy or power metrics into the MCTS reward function could further tilt the search toward power-efficient solutions without separate post-processing.
Load-bearing premise
The micro-profiling tools and roofline classifier must correctly encode expert heuristics so the natural-language feedback supplied to the LLM is not systematically misleading or hardware-specific.
What would settle it
Running KernelPro on KernelBench with the micro-profiling tools disabled and measuring whether geometric mean speedups fall to the level of prior LLM-only baselines or raw-metric prompting.
Figures
read the original abstract
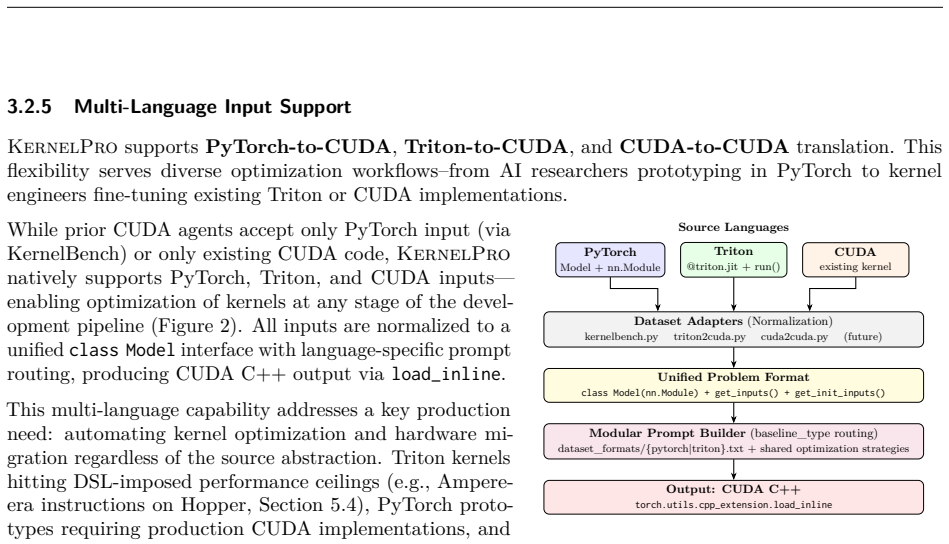
We present KernelPro, a closed-loop multi-agent system that automatically generates, profiles, and iteratively optimizes GPU kernel code by integrating large language model (LLM) code generation with hardware profiler feedback and pluggable bottleneck detection tools. KernelPro introduces four contributions: (1) a semantic feedback operator that encodes expert heuristics as pluggable micro-profiling tools, transforming raw hardware metrics into actionable natural language guidance; (2) a two-stage tool invocation architecture where roofline-based bottleneck classification filters which specialized analysis tools execute, combining kernel-level (ncu), instruction-level (SASS), and system-level (nsys) profiling; (3) a domain-adapted MCTS with progressive widening, asymmetric branching, log-reward calibration, dead-end pruning, and search memory for cross-iteration learning; and (4) direct CuTe source-level code generation via autonomous code search over the CUTLASS/CuTe codebase. On KernelBench, KernelPro achieves geometric mean speedups of 2.42x/4.69x/5.30x on Levels 1/2/3, establishing state-of-the-art performance across all difficulty levels. On VeOmni's expert-optimized MoE training kernels, KernelPro achieves 1.23x over hand-tuned Triton by generating a from-scratch raw-CUDA+CuTe Hopper WGMMA kernel. Ablation studies demonstrate that each design component independently and significantly improves optimization quality: micro-profiling tools (p < 0.0001 vs raw metrics), MCTS search (26% higher geometric mean vs greedy, p = 0.004), and proactive tool orchestration (23% improvement, p = 0.035). Finally, KernelPro is the first CUDA kernel coding agent to optimize energy efficiency beyond the speed-only focus of prior systems, demonstrating an 11.6% measured energy reduction at matched speed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents KernelPro, a closed-loop multi-agent LLM system for GPU kernel optimization that integrates semantic feedback from pluggable micro-profiling tools (roofline classification followed by ncu/SASS/nsys analysis), a domain-adapted MCTS with progressive widening and dead-end pruning, and direct CuTe source generation. It claims geometric-mean speedups of 2.42×/4.69×/5.30× on KernelBench Levels 1/2/3 (SOTA across difficulty levels), 1.23× over hand-tuned Triton on VeOmni MoE kernels via a from-scratch Hopper WGMMA kernel, an 11.6% energy reduction at matched speed, and statistically significant gains from each component (micro-profiling p<0.0001, MCTS p=0.004, orchestration p=0.035).
Significance. If the central performance claims hold after addressing experimental transparency, the work is significant for demonstrating a practical, reproducible path to LLM-driven kernel optimization that exceeds prior systems and hand-tuned baselines while extending to energy efficiency. The pluggable micro-profiling design and MCTS adaptations represent concrete engineering contributions that could be adopted in future automated performance tools.
major comments (2)
- [Abstract and results section] Abstract and results section: The geometric-mean speedups (2.42×/4.69×/5.30×) and SOTA claim rest on unreviewed experimental choices; the manuscript supplies no baseline details, error bars, or description of how KernelBench levels were constructed, preventing independent assessment of the reported gains.
- [§3.2 and ablation studies] §3.2 (two-stage tool invocation) and ablation studies: The central 'expert surrogate' premise—that the roofline classifier plus micro-profilers faithfully encode expert heuristics and avoid systematic mis-routing (e.g., on Hopper WGMMA register-pressure vs. bandwidth trade-offs)—is load-bearing but unsupported by direct validation against independent expert judgments on the same kernels; the reported p<0.0001 improvement over raw metrics does not address fidelity of the natural-language mapping.
minor comments (2)
- [Abstract] Abstract: The energy-efficiency result (11.6% reduction) is presented without corresponding baseline energy numbers or measurement methodology, which should be clarified for completeness.
- [MCTS description] The MCTS description mentions 'log-reward calibration' and 'search memory' without explicit equations or pseudocode; adding these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting issues of experimental transparency and validation of the expert-surrogate components. We address each comment below and will revise the manuscript to improve clarity and reproducibility while preserving the core claims supported by the existing ablation data.
read point-by-point responses
-
Referee: [Abstract and results section] Abstract and results section: The geometric-mean speedups (2.42×/4.69×/5.30×) and SOTA claim rest on unreviewed experimental choices; the manuscript supplies no baseline details, error bars, or description of how KernelBench levels were constructed, preventing independent assessment of the reported gains.
Authors: We agree that the current manuscript lacks sufficient detail for independent verification. In the revised version we will add: (1) explicit baseline configurations including library versions, compilation flags, and hardware setup; (2) error bars or standard deviations accompanying all geometric-mean speedups; and (3) a dedicated paragraph describing the construction of KernelBench Levels 1–3, including the criteria used for difficulty assignment. These additions will appear in a new “Experimental Setup” subsection and the results section. revision: yes
-
Referee: [§3.2 and ablation studies] §3.2 (two-stage tool invocation) and ablation studies: The central 'expert surrogate' premise—that the roofline classifier plus micro-profilers faithfully encode expert heuristics and avoid systematic mis-routing (e.g., on Hopper WGMMA register-pressure vs. bandwidth trade-offs)—is load-bearing but unsupported by direct validation against independent expert judgments on the same kernels; the reported p<0.0001 improvement over raw metrics does not address fidelity of the natural-language mapping.
Authors: The reported p<0.0001 quantifies the performance benefit of the full tool pipeline versus raw metrics, which indirectly supports the utility of the encoded heuristics. The roofline classifier and subsequent profilers follow well-established expert practices. Nevertheless, we acknowledge that direct side-by-side comparison with independent expert judgments on the same kernels would provide stronger evidence of mapping fidelity, particularly for cases such as Hopper WGMMA register-pressure versus bandwidth decisions. We will revise §3.2 to expand the description of the natural-language mapping rules, include a brief discussion of potential mis-routing scenarios, and add a limitations paragraph noting the absence of direct expert validation. We view this as a partial revision because a new expert study is outside the scope of the current experiments. revision: partial
Circularity Check
No significant circularity; empirical benchmark-driven system with independent evaluations
full rationale
The paper describes an engineering system (KernelPro) whose central claims are geometric-mean speedups on external benchmarks (KernelBench Levels 1-3 and VeOmni MoE kernels) and ablation p-values. These results are measured outcomes, not quantities derived from equations or parameters fitted inside the paper. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the architecture description or evaluation chain; the roofline classifier and micro-profilers are presented as pluggable components whose correctness is assessed by downstream speedups rather than by internal consistency alone. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Roofline model correctly classifies kernel bottlenecks for the purpose of deciding which micro-profiling tools to invoke
Reference graph
Works this paper leans on
-
[1]
GPU kernel scientist: An LLM -driven framework for iterative kernel optimization
Martin Andrews and Sam Witteveen. GPU kernel scientist: An LLM -driven framework for iterative kernel optimization. In ES-FoMo III Workshop at ICML, 2025. URL https://arxiv.org/abs/2506.20807
arXiv 2025
-
[2]
Continuous upper confidence trees with polynomial exploration -- consistency
David Auger, Adrien Couetoux, and Olivier Teytaud. Continuous upper confidence trees with polynomial exploration -- consistency. In Proceedings of the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD), pp.\ 194--209, 2013. doi:10.1007/978-3-642-40988-2_13
-
[3]
LongBench v2 : Towards deeper understanding and reasoning on realistic long-context multitasks
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench v2 : Towards deeper understanding and reasoning on realistic long-context multitasks. arXiv preprint arXiv:2412.15204, 2024. URL https://arxiv.org/abs/2412.15204
Pith/arXiv arXiv 2024
-
[4]
Arijit Bhattacharjee, Heng Ping, Son Vu Le, Paul Bogdan, Nesreen K. Ahmed, and Ali Jannesari. OptiML : An end-to-end framework for program synthesis and CUDA kernel optimization. arXiv preprint arXiv:2602.12305, 2026. URL https://arxiv.org/abs/2602.12305
arXiv 2026
-
[5]
Architecting an energy-efficient DRAM system for GPUs
Niladrish Chatterjee, Mike O'Connor, Donghyuk Lee, Daniel R Johnson, Stephen W Keckler, Minsoo Rhu, and William J Dally. Architecting an energy-efficient DRAM system for GPUs . In 2017 IEEE International Symposium on High Performance Computer Architecture (HPCA), pp.\ 73--84. IEEE, 2017
2017
-
[6]
AVO : Agentic variation operators for autonomous evolutionary search
Terry Chen, Zhifan Ye, Bing Xu, Zihao Ye, Timmy Liu, Ali Hassani, Tianqi Chen, Andrew Kerr, Haicheng Wu, Yang Xu, Yu-Jung Chen, Hanfeng Chen, Aditya Kane, Ronny Krashinsky, Ming-Yu Liu, Vinod Grover, Luis Ceze, Roger Bringmann, John Tran, Wei Liu, Fung Xie, Michael Lightstone, and Humphrey Shi. AVO : Agentic variation operators for autonomous evolutionary...
arXiv 2026
-
[7]
cuPilot : A strategy-coordinated multi-agent framework for CUDA kernel evolution
Yongchao Chen, Yueying Li, Yue Zhang, Shreyas Singh, Tian Lan, and Yongle Zhang. cuPilot : A strategy-coordinated multi-agent framework for CUDA kernel evolution. In arXiv preprint arXiv:2512.16465, 2025. URL https://arxiv.org/abs/2512.16465
arXiv 2025
-
[8]
Kris Shengjun Dong, Sahil Modi, Dima Nikiforov, Sana Damani, Edward Lin, Siva Kumar Sastry Hari, and Christos Kozyrakis. KernelBlaster : Continual cross-task CUDA optimization via memory-augmented in-context reinforcement learning. In arXiv preprint arXiv:2602.14293, 2026. URL https://arxiv.org/abs/2602.14293
arXiv 2026
-
[9]
Making LLMs optimize multi-scenario CUDA kernels like experts
Yuxuan Han, Meng-Hao Guo, Zhengning Liu, Wenguang Chen, and Shi-Min Hu. Making LLMs optimize multi-scenario CUDA kernels like experts. In arXiv preprint arXiv:2603.07169, 2026. URL https://arxiv.org/abs/2603.07169
arXiv 2026
-
[10]
Wolfe, and Eric Chicken
Myles Hollander, Douglas A. Wolfe, and Eric Chicken. Nonparametric Statistical Methods. John Wiley & Sons, 3rd edition, 2014
2014
-
[11]
An integrated GPU power and performance model
Sunpyo Hong and Hyesoon Kim. An integrated GPU power and performance model. In Proceedings of the 37th Annual International Symposium on Computer Architecture (ISCA), pp.\ 280--289, 2010
2010
-
[12]
1.1 computing's energy problem (and what we can do about it)
Mark Horowitz. 1.1 computing's energy problem (and what we can do about it). In 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), pp.\ 10--14. IEEE, 2014
2014
-
[13]
TreeRL : LLM reinforcement learning with on-policy tree search
Zhenyu Hou, Ziniu Hu, Yujiang Li, Rui Lu, Jie Tang, and Yuxiao Dong. TreeRL : LLM reinforcement learning with on-policy tree search. arXiv preprint arXiv:2506.11902, 2025. URL https://arxiv.org/abs/2506.11902
arXiv 2025
-
[14]
Electricity 2024: Analysis and forecast to 2026
International Energy Agency . Electricity 2024: Analysis and forecast to 2026. Technical report, International Energy Agency (IEA), Paris, 2024. URL https://www.iea.org/reports/electricity-2024
2024
-
[15]
Tree search for LLM agent reinforcement learning
Yuxiang Ji, Ziyu Ma, Yong Wang, Guanhua Chen, Xiangxiang Chu, and Liaoni Wu. Tree search for LLM agent reinforcement learning. In arXiv preprint arXiv:2509.21240, 2025. URL https://arxiv.org/abs/2509.21240
arXiv 2025
-
[16]
Accelwattch: A power modeling framework for modern gpus
Vijay Kandiah, Scott Peverelle, Mahmoud Khairy, Junrui Pan, Amogh Manjunath, Timothy G Rogers, Tor M Aamodt, and Nikos Hardavellas. Accelwattch: A power modeling framework for modern gpus. In MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, pp.\ 738--753, 2021
2021
-
[17]
Bandit based Monte-Carlo planning
Levente Kocsis and Csaba Szepesv\' a ri. Bandit based Monte-Carlo planning. In Proceedings of the 17th European Conference on Machine Learning (ECML), pp.\ 282--293, 2006. doi:10.1007/11871842_29
-
[18]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention . In Proceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP), 2023. URL https://arxiv.org/abs/2309.06180
Pith/arXiv arXiv 2023
-
[19]
GPUWattch : Enabling energy optimizations in GPGPUs
Jingwen Leng, Tayler Hetherington, Ahmed ElTantawy, Syed Gilani, Nam Sung Kim, Tor M Aamodt, and Vijay Janapa Reddi. GPUWattch : Enabling energy optimizations in GPGPUs . In Proceedings of the 40th Annual International Symposium on Computer Architecture (ISCA), pp.\ 487--498, 2013
2013
-
[20]
Shiyang Li, Zijian Zhang, Winson Chen, Yuebo Luo, Mingyi Hong, and Caiwen Ding. StitchCUDA : An automated multi-agents end-to-end GPU programing framework with rubric-based agentic reinforcement learning. In Proceedings of the 43rd International Conference on Machine Learning (ICML), Proceedings of Machine Learning Research. PMLR, 2026. URL https://arxiv....
arXiv 2026
-
[21]
Over-synchronization in GPU programs
Ajay Nayak and Arkaprava Basu. Over-synchronization in GPU programs. In 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 2024
2024
-
[22]
Alexander Novikov, Ng\^ a n V\ u , Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. AlphaEvolve : A coding agent for scientific an...
Pith/arXiv arXiv 2025
-
[23]
CUTLASS : CUDA templates for linear algebra subroutines
NVIDIA . CUTLASS : CUDA templates for linear algebra subroutines. https://github.com/NVIDIA/cutlass, 2023
2023
-
[24]
CUDA C++ Best Practices Guide , 2024
NVIDIA Corporation . CUDA C++ Best Practices Guide , 2024. URL https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/
2024
-
[25]
OpenAI Agents SDK
OpenAI . OpenAI Agents SDK . https://github.com/openai/openai-agents-python, 2025
2025
-
[26]
Zhang, William Hu, Christopher R\' e , and Azalia Mirhoseini
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christopher R\' e , and Azalia Mirhoseini. KernelBench : Can LLMs write efficient GPU kernels? In arXiv preprint arXiv:2502.10517, 2025. URL https://arxiv.org/abs/2502.10517
Pith/arXiv arXiv 2025
-
[27]
GrepSeek : Training search agents for direct corpus interaction
Alireza Salemi, Chang Zeng, Atharva Nijasure, Jui-Hui Chung, Razieh Rahimi, Fernando Diaz, and Hamed Zamani. GrepSeek : Training search agents for direct corpus interaction. arXiv preprint arXiv:2605.29307, 2026. URL https://arxiv.org/abs/2605.29307
Pith/arXiv arXiv 2026
-
[28]
GPUs Go Brrr , 2024
Benjamin Spector, Aaryan Singhal, Simran Arora, and Chris Re. GPUs Go Brrr , 2024. URL https://hazyresearch.stanford.edu/blog/2024-05-12-tk. Hazy Research Blog, introducing ThunderKittens
2024
-
[29]
KernelEvolve : Scaling agentic kernel coding for heterogeneous AI accelerators at meta
Ansor Team and Meta. KernelEvolve : Scaling agentic kernel coding for heterogeneous AI accelerators at meta. In arXiv preprint arXiv:2512.23236, 2025. URL https://arxiv.org/abs/2512.23236
arXiv 2025
-
[30]
Philippe Tillet, H. T. Kung, and David Cox. Triton: An intermediate language and compiler for tiled neural network computations. In Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages (MAPL), 2019
2019
-
[31]
KernelFoundry : Hardware-aware evolutionary GPU kernel optimization
Nina Wiedemann, Quentin Leboutet, Michael Paulitsch, Diana Wofk, and Benjamin Ummenhofer. KernelFoundry : Hardware-aware evolutionary GPU kernel optimization. In arXiv preprint arXiv:2603.12440, 2026. URL https://arxiv.org/abs/2603.12440
arXiv 2026
-
[32]
Fang Wu, Weihao Xuan, Heli Qi, Ximing Lu, Aaron Tu, Li Erran Li, and Yejin Choi. DeepSearch : Overcome the bottleneck of reinforcement learning with verifiable rewards via Monte Carlo tree search. In arXiv preprint arXiv:2509.25454, 2025. URL https://arxiv.org/abs/2509.25454
Pith/arXiv arXiv 2025
-
[33]
Charlene Yang, Thorsten Kurth, and Samuel Williams. Hierarchical roofline analysis for GPUs : Accelerating performance optimization for the NERSC-9 Perlmutter system. Concurrency and Computation: Practice and Experience, 32 0 (20): 0 e5547, 2020. doi:10.1002/cpe.5547
-
[34]
Part-time power measurements: nvidia-smi's lack of attention
Zeyu Yang, Karel Ad \'a mek, and Wesley Armour. Part-time power measurements: nvidia-smi's lack of attention. arXiv preprint arXiv:2312.02741, 2024
arXiv 2024
-
[35]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. ReAct : Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR), 2023. URL https://arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[36]
Di Zhang, Jianbo Wu, Jingdi Lei, Tong Che, Jiatong Li, Tong Xie, Xiaoshui Huang, Shufei Zhang, Marco Pavone, Yuqiang Li, Wanli Ouyang, and Dongzhan Zhou. Accessing GPT-4 level mathematical olympiad solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B . arXiv preprint arXiv:2406.07394, 2024. URL https://arxiv.org/abs/2406.07394
arXiv 2024
-
[37]
CudaForge : An agent framework with hardware feedback for CUDA kernel optimization
Zijian Zhang, Rong Wang, Shiyang Li, Yuebo Luo, Mingyi Hong, and Caiwen Ding. CudaForge : An agent framework with hardware feedback for CUDA kernel optimization. In arXiv preprint arXiv:2511.01884, 2025. URL https://arxiv.org/abs/2511.01884
arXiv 2025
-
[38]
CUDA Agent : Large-scale agentic RL for high-performance CUDA kernel generation
Zijian Zhang, Shiyang Li, Rong Wang, Yuebo Luo, Mingyi Hong, and Caiwen Ding. CUDA Agent : Large-scale agentic RL for high-performance CUDA kernel generation. In arXiv preprint arXiv:2602.24286, 2026. URL https://arxiv.org/abs/2602.24286
arXiv 2026
-
[39]
GPA : A GPU performance advisor based on instruction sampling
Keren Zhou, Xiaozhu Meng, Ryuichi Sai, and John Mellor-Crummey. GPA : A GPU performance advisor based on instruction sampling. In Proceedings of the 2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), pp.\ 115--125, 2021. URL https://arxiv.org/abs/2009.04061
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.