Sample-efficient Transfer Reinforcement Learning via Adaptive Reward Shaping and Policy-Ratio Reweighting Strategy
Pith reviewed 2026-06-26 05:23 UTC · model grok-4.3
The pith
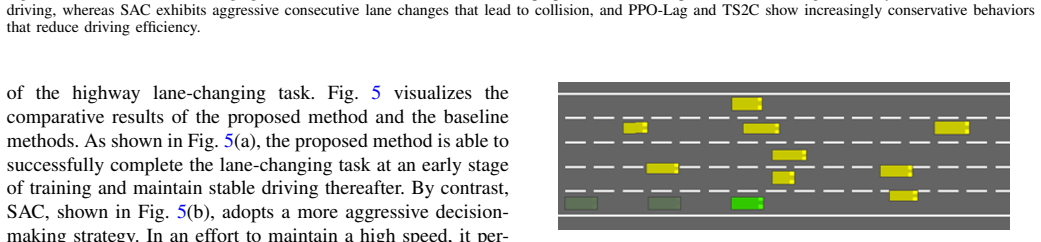
A transfer RL framework for highway lane changing uses adaptive safety-cost teacher intervention, decaying reward shaping, and likelihood-ratio sample reweighting to cut unsafe exploration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
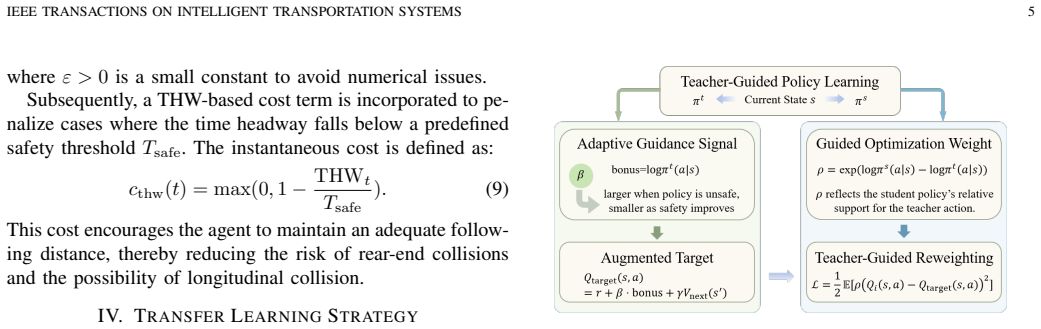
The central claim is that an adaptive teacher intervention based on instantaneous safety cost, combined with teacher-guided reward shaping that decays as policy safety rises and a likelihood-ratio reweighting in policy optimization, produces a mixed behavior policy whose return is theoretically bounded while stabilizing transfer and improving both safety and sample efficiency on lane-changing tasks under varying traffic conditions.
What carries the argument
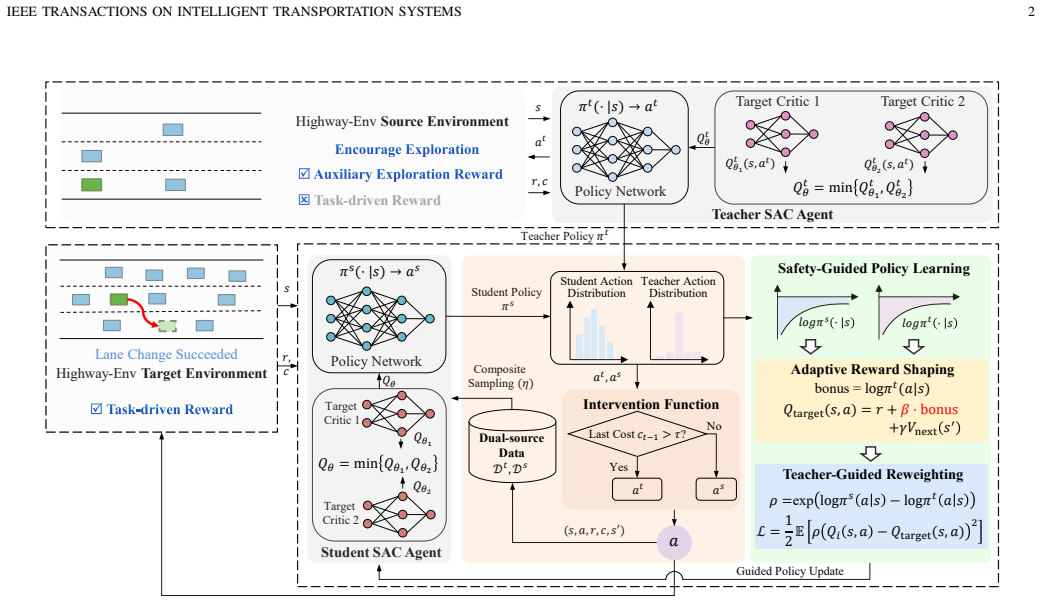
adaptive teacher intervention mechanism triggered by instantaneous safety cost that fades progressively and supplies dual-source samples for joint training
If this is right
- Risky actions during early transfer are suppressed without permanently locking the student to the teacher.
- Return under the mixed behavior policy remains bounded as intervention strength declines.
- Sample weights adjusted by the policy-ratio factor reduce oscillation from distribution shift.
- Guidance from the teacher naturally diminishes once the student policy achieves adequate safety margins.
Where Pith is reading between the lines
- The same fading-intervention pattern could be tested in other continuous-control transfer settings where an external safety oracle is cheap to evaluate.
- If the safety cost can be replaced by a learned critic, the framework might remove the need for an explicit teacher after initial transfer.
- The dual-source sample stream suggests a natural way to blend offline demonstration data with online rollouts without separate replay buffers.
Load-bearing premise
An instantaneous safety cost can be computed reliably in real time to decide when to intervene without itself creating bias or new failure modes, and a sufficiently aligned teacher policy remains continuously available.
What would settle it
Running the identical student policy on the NGSIM validation set after disabling the safety-cost trigger while keeping reward shaping and reweighting shows whether the reported safety gain falls below 52 percent.
Figures

read the original abstract
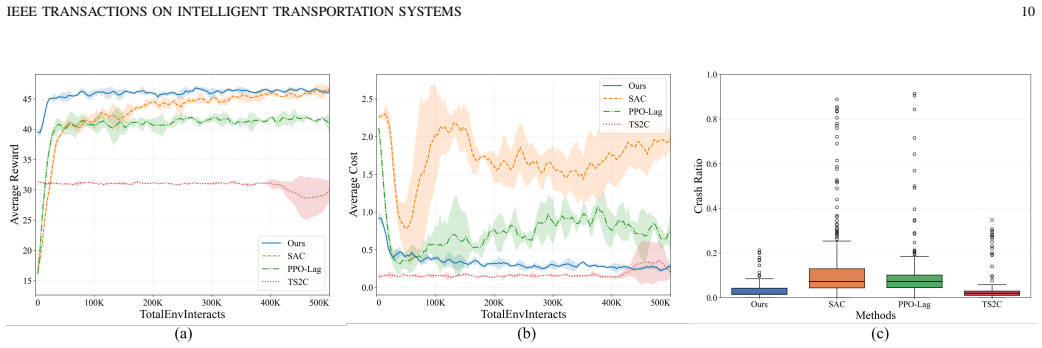
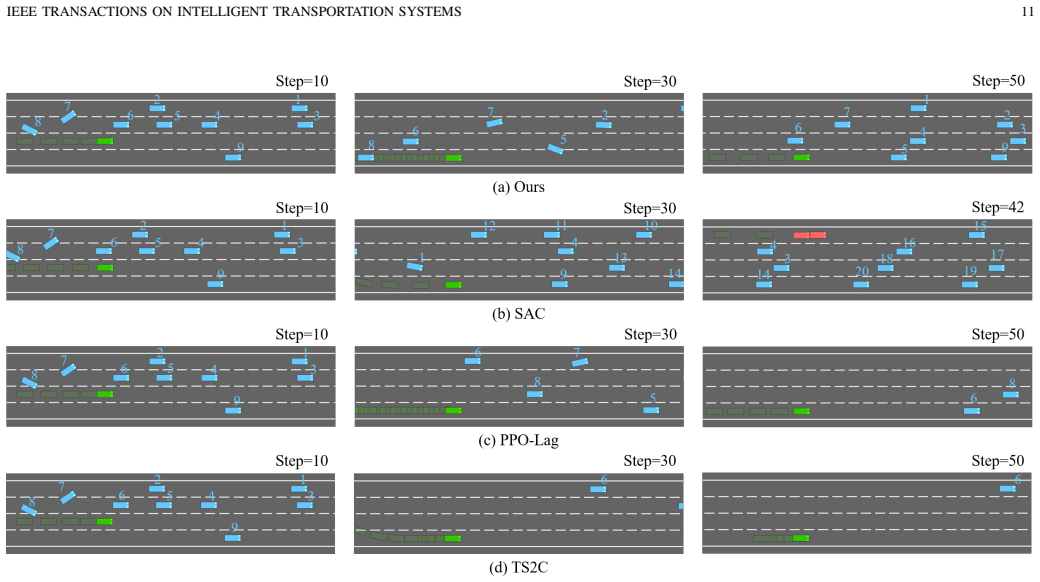
Transfer learning improves policy learning efficiency by reusing knowledge from source tasks, providing a feasible paradigm for safe and efficient autonomous highway lane changing decision-making. Existing methods frequently encounter transfer mismatch induced by distribution shifts between source and target domains, leading to training oscillation and performance decline. Besides, target domain adaptation depends on exploratory interactions, which struggles to guarantee training safety in safety-critical lane changing cases. To tackle these limitations, this paper proposes a safe transfer reinforcement learning framework for autonomous highway lane changing. First, we design an adaptive teacher intervention mechanism based on instantaneous safety cost to restrain risky exploration and fade intervention strength progressively, with theoretical analysis on return bounds for mixed behavior policy. This intervention also produces dual-source samples for joint training. Second, a teacher-guided safe transfer module embeds action evaluation information of teacher policy into student learning via reward shaping to boost training safety and efficiency, with teacher guidance decaying as policy safety rises. Third, a teacher-guided weighted optimization mechanism adjusts sample weights in policy optimization using a likelihood ratio factor to stabilize transfer performance. Experiments under varied traffic densities and validations on real-world NGSIM dataset reveal that our method surpasses baseline approaches by over 52.2% in safety and 5.0% in learning efficiency. Results verify the efficacy and robustness of our safety-aware transfer strategy for autonomous highway lane changing under various traffic conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a safe transfer reinforcement learning framework for autonomous highway lane changing. It introduces (1) an adaptive teacher intervention mechanism triggered by an instantaneous safety cost that restrains risky actions, fades over time, and generates dual-source samples, accompanied by theoretical return bounds for the mixed behavior policy; (2) a teacher-guided safe transfer module that embeds teacher action evaluations via reward shaping with decaying guidance; and (3) a teacher-guided weighted optimization that reweights samples via a likelihood ratio factor. Experiments across varied traffic densities and on the NGSIM dataset report gains of over 52.2% in safety and 5.0% in learning efficiency versus baselines.
Significance. If the empirical gains and theoretical bounds hold under scrutiny, the work would offer a concrete approach to mitigating transfer mismatch and unsafe exploration in safety-critical RL domains. The combination of intervention, shaping, and reweighting, plus real-world dataset validation, addresses practically relevant issues in autonomous driving. The theoretical component on mixed-policy returns is a positive element that could strengthen the contribution if the bounds are non-vacuous and the safety cost is well-specified.
major comments (2)
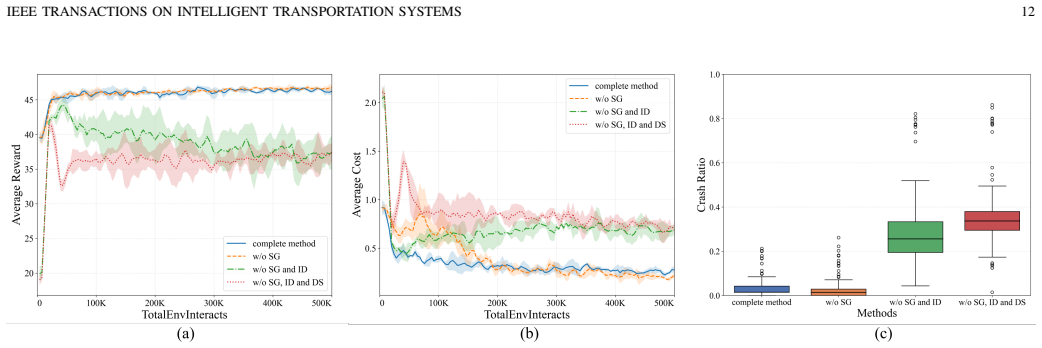
- [Abstract / adaptive teacher intervention mechanism] The instantaneous safety cost that triggers and modulates teacher intervention (central to the adaptive mechanism described in the abstract) lacks a concrete definition, formula, or real-time computation procedure. This is load-bearing for the safety and transfer claims because the intervention decay, dual-source sampling, and reported 52.2% safety improvement all depend on it; without a bias-free, domain-realizable definition, the justification for the framework and the empirical gains cannot be evaluated.
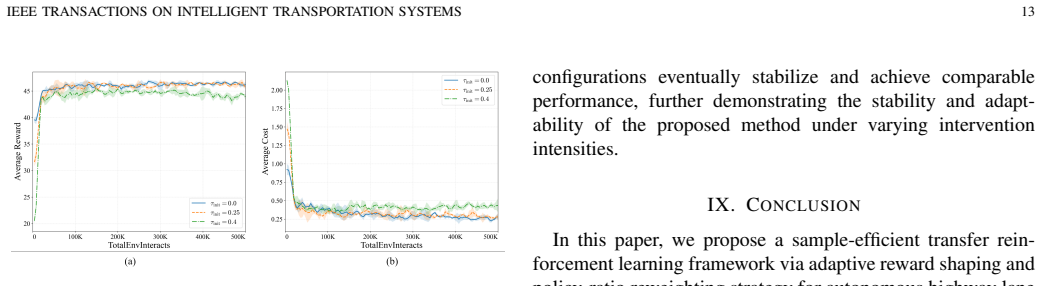
- [Experiments] The experimental claims of 52.2% safety and 5.0% efficiency improvements are presented without error bars, number of independent runs, hyperparameter sensitivity analysis, or full protocol details. This undermines assessment of whether the gains are robust across traffic densities or sensitive to the safety-cost threshold choice.
minor comments (1)
- [Abstract] The abstract refers to 'theoretical analysis on return bounds for mixed behavior policy' without indicating the section or key equations containing the derivation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key aspects of the framework and strengthen the empirical evaluation. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / adaptive teacher intervention mechanism] The instantaneous safety cost that triggers and modulates teacher intervention (central to the adaptive mechanism described in the abstract) lacks a concrete definition, formula, or real-time computation procedure. This is load-bearing for the safety and transfer claims because the intervention decay, dual-source sampling, and reported 52.2% safety improvement all depend on it; without a bias-free, domain-realizable definition, the justification for the framework and the empirical gains cannot be evaluated.
Authors: We agree that the current presentation does not sufficiently detail the instantaneous safety cost. In the revised manuscript we will add an explicit mathematical definition (based on relative velocity, distance to leading vehicle, and lane-change feasibility), the real-time computation procedure using observable states, and pseudocode showing how the cost triggers intervention strength and its decay schedule. This will be placed in Section 3.1 alongside the existing theoretical return bounds. revision: yes
-
Referee: [Experiments] The experimental claims of 52.2% safety and 5.0% efficiency improvements are presented without error bars, number of independent runs, hyperparameter sensitivity analysis, or full protocol details. This undermines assessment of whether the gains are robust across traffic densities or sensitive to the safety-cost threshold choice.
Authors: The referee is correct that additional statistical rigor is needed. We will revise the experimental section to report means and standard deviations over at least five independent random seeds, include error bars on all performance plots, add a sensitivity analysis for the safety-cost threshold, and provide the full training protocol (hyperparameters, network architectures, and evaluation metrics) in an appendix. revision: yes
Circularity Check
No derivation chain or equations presented; claims rest on empirical results only
full rationale
The manuscript text supplies only an abstract describing a transfer RL framework with adaptive teacher intervention, reward shaping, and policy-ratio reweighting, plus experimental claims of 52.2% safety gains. No equations, return-bound derivations, or self-citations appear in the provided content, so no load-bearing step can be inspected for reduction to its own inputs by construction. The mentioned theoretical analysis is not exhibited, precluding any finding of self-definitional, fitted-prediction, or self-citation circularity. The derivation is therefore self-contained against external benchmarks by absence of inspectable math.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Deep reinforcement learning for autonomous driving: A survey,
B. R. Kiran, I. Sobh, V . Talpaert, P. Mannion, A. A. A. Sallab, S. Yo- gamani, and P. P ´erez, “Deep reinforcement learning for autonomous driving: A survey,”IEEE Trans. Intell. Transp. Syst., vol. 23, no. 6, pp. 4909–4926, 2022
2022
-
[2]
Safe reinforcement learning for autonomous lane changing using set-based prediction,
H. Krasowski, X. Wang, and M. Althoff, “Safe reinforcement learning for autonomous lane changing using set-based prediction,” inIEEE Int. Conf. Intell. Transp. Syst. (ITSC), 2020, pp. 1–7
2020
-
[3]
Unsupervised reinforcement learning for multi-task autonomous driving: Expanding skills and cultivating curiosity,
Z. Ma, X. Liu, and Y . Huang, “Unsupervised reinforcement learning for multi-task autonomous driving: Expanding skills and cultivating curiosity,”IEEE Trans. Intell. Transp. Syst., vol. 25, no. 10, pp. 14 209– 14 219, 2024
2024
-
[4]
Driving tasks transfer using deep reinforcement learning for decision-making of autonomous vehicles in unsignalized intersection,
H. Shu, T. Liu, X. Mu, and D. Cao, “Driving tasks transfer using deep reinforcement learning for decision-making of autonomous vehicles in unsignalized intersection,”IEEE Trans. Veh. Technol., vol. 71, no. 1, pp. 41–52, 2022
2022
-
[5]
A perspective of q-value estimation on offline-to-online reinforcement learning,
Y . Zhang, J. Liu, C. Li, Y . Niu, Y . Yang, Y . Liu, and W. Ouyang, “A perspective of q-value estimation on offline-to-online reinforcement learning,” inProc. AAAI Conf. Artif. Intell., vol. 38, no. 15, 2024, pp. 16 908–16 916
2024
-
[6]
Sim-to-lab-to-real: Safe reinforcement learning with shielding and generalization guarantees,
K.-C. Hsu, A. Z. Ren, D. P. Nguyen, A. Majumdar, and J. F. Fisac, “Sim-to-lab-to-real: Safe reinforcement learning with shielding and generalization guarantees,”Artif. Intell., vol. 314, p. 103811, 2023
2023
-
[7]
Knowledge transfer from simple to complex: A safe and efficient reinforcement learning framework for autonomous driving decision-making,
R. Zhou, J. Huang, M. Li, H. Li, H. Cao, and X. Song, “Knowledge transfer from simple to complex: A safe and efficient reinforcement learning framework for autonomous driving decision-making,”Adv. Eng. Inform., 2025
2025
-
[8]
Zero-shot deep reinforcement learning driving policy transfer for autonomous vehicles based on robust control,
Z. Xu, C. Tang, and M. Tomizuka, “Zero-shot deep reinforcement learning driving policy transfer for autonomous vehicles based on robust control,” inProc. 21th IEEE Intell. Transp. Syst. Conf. (ITSC). IEEE, 2018, pp. 2865–2871
2018
-
[9]
Safety reinforcement learning control via transfer learning,
Q. Zhang, C. Wu, H. Tian, Y . Gao, W. Yao, and L. Wu, “Safety reinforcement learning control via transfer learning,”Automatica, vol. 166, p. 111714, 2024
2024
-
[10]
Federated trans- fer reinforcement learning for autonomous driving,
X. Liang, Y . Liu, T. Chen, M. Liu, and Q. Yang, “Federated trans- fer reinforcement learning for autonomous driving,”arXiv preprint arXiv:1910.06001, 2019. IEEE TRANSACTIONS ON INTELLIGENT TRANSPORTATION SYSTEMS 14
arXiv 1910
-
[11]
Scenario- level knowledge transfer for motion planning of autonomous driving via successor representation,
H. Lu, C. Lu, H. Wang, J. Gong, M. Zhu, and H. Yang, “Scenario- level knowledge transfer for motion planning of autonomous driving via successor representation,”Transp. Res. Pt. C-Emerg. Technol., vol. 168, p. 104899, 2024
2024
-
[12]
Self-supervised domain transfer for reinforcement learning-based autonomous driving agent,
R. Moni and B. Gyires-T ´oth, “Self-supervised domain transfer for reinforcement learning-based autonomous driving agent,”Expert Syst. Appl., vol. 284, p. 127809, 2025
2025
-
[13]
Cross-domain adaptive transfer reinforcement learning based on state-action correspondence,
H. You, R. Dong, Y . Chi, and Y . Zhu, “Cross-domain adaptive transfer reinforcement learning based on state-action correspondence,” inProc. Conf. Uncertainty Artif. Intell., vol. 180, 2022, pp. 1640–1652
2022
-
[14]
Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards,
M. Vecerik, T. Hester, J. Scholz, F. Wang, O. Pietquin, B. Piot, N. Heess, T. Roth ¨orl, T. Lampe, and M. Riedmiller, “Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards,”arXiv preprint arXiv:1707.08817, 2017
Pith/arXiv arXiv 2017
-
[15]
Policy optimization with demonstrations,
B. Kang, Z. Jie, and J. Feng, “Policy optimization with demonstrations,” inProc. 35th Int. Conf. Mach. Learn., vol. 80, 2018, pp. 2474–2483
2018
-
[16]
Actor-mimic: Deep multitask and transfer reinforcement learning,
E. Parisotto, J. L. Ba, and R. Salakhutdinov, “Actor-mimic: Deep multitask and transfer reinforcement learning,”arXiv preprint arXiv:1511.06342, 2015
Pith/arXiv arXiv 2015
-
[17]
Knowledge transfer for deep reinforcement learning with hierarchical experience replay,
H. Yin and S. Pan, “Knowledge transfer for deep reinforcement learning with hierarchical experience replay,” inProc. AAAI Conf. Artif. Intell., vol. 31, no. 1, 2017
2017
-
[18]
Improving reinforcement learning with confidence-based demonstrations,
Z. Wang and M. E. Taylor, “Improving reinforcement learning with confidence-based demonstrations,” inProc. 26th Int. Joint Conf. Artif. Intell., ser. IJCAI’17, 2017, p. 3027–3033
2017
-
[19]
An enhanced advising model in teacher-student framework using state categorization,
D. Anand, V . Gupta, P. Paruchuri, and B. Ravindran, “An enhanced advising model in teacher-student framework using state categorization,” inProc. AAAI Conf. Artif. Intell., vol. 35, no. 8, 2021, pp. 6653–6660
2021
-
[20]
Human as ai mentor: En- hanced human-in-the-loop reinforcement learning for safe and efficient autonomous driving,
Z. Huang, Z. Sheng, C. Ma, and S. Chen, “Human as ai mentor: En- hanced human-in-the-loop reinforcement learning for safe and efficient autonomous driving,”Commun. Transp. Res., p. 100127, 2024
2024
-
[21]
Adaptive action advising with different rewards,
Y . Guo, X. Zhang, S. Stepputtis, J. Campbell, and K. P. Sycara, “Adaptive action advising with different rewards,” inProc. Mach. Learn. Res., 2025, pp. 252–267
2025
-
[22]
Safe reinforcement learning via shielding,
M. Alshiekh, R. Bloem, R. Ehlers, B. K ¨onighofer, S. Niekum, and U. Topcu, “Safe reinforcement learning via shielding,” inProc. AAAI Conf. Artif. Intell., vol. 32, no. 1, 2018
2018
-
[23]
Safe reinforcement learning via shielding under partial observability,
S. Carr, N. Jansen, S. Junges, and U. Topcu, “Safe reinforcement learning via shielding under partial observability,” inProc. AAAI Conf. Artif. Intell., vol. 37, no. 12, 2023, pp. 14 748–14 756
2023
-
[24]
Robust model predictive shielding for safe reinforcement learning with stochastic dynamics,
S. Li and O. Bastani, “Robust model predictive shielding for safe reinforcement learning with stochastic dynamics,” inProc. IEEE Int. Conf. Robot. Autom. (ICRA), 2020, pp. 7166–7172
2020
-
[25]
Teaching on a budget in multi-agent deep reinforcement learning,
E. Ilhan, J. Gow, and D. Perez-Liebana, “Teaching on a budget in multi-agent deep reinforcement learning,”Proc. 2019 IEEE Conf. Games (CoG), p. 1–8, 2019
2019
-
[26]
Action advising with advice imitation in deep reinforcement learning,
E. Ilhan, J. Gow, and D. Perez Liebana, “Action advising with advice imitation in deep reinforcement learning,” inProc. 20th Int. Conf. Auton. Agents Multiagent Syst., ser. AAMAS ’21, 2021, p. 629–637
2021
-
[27]
Reinforcement learning with demonstrations from mismatched task under sparse reward,
Y . Guo, J. Gao, Z. Wu, C. Shi, and J. Chen, “Reinforcement learning with demonstrations from mismatched task under sparse reward,” in Proc. Conf. Robot Learn., 2023, pp. 1146–1156
2023
-
[28]
Psiphi- learning: Reinforcement learning with demonstrations using successor features and inverse temporal difference learning,
A. Filos, C. Lyle, Y . Gal, S. Levine, N. Jaques, and G. Farquhar, “Psiphi- learning: Reinforcement learning with demonstrations using successor features and inverse temporal difference learning,” inProc. 35th Int. Conf. Mach. Learn., 2021, pp. 3305–3317
2021
-
[29]
Hybrid reinforcement learning with expert state sequences,
X. Guo, S. Chang, M. Yu, G. Tesauro, and M. Campbell, “Hybrid reinforcement learning with expert state sequences,” inProc. AAAI Conf. Artif. Intell., vol. 33, no. 01, 2019, pp. 3739–3746
2019
-
[30]
Guided exploration with proximal policy optimization using a single demonstration,
G. Libardi, G. De Fabritiis, and S. Dittert, “Guided exploration with proximal policy optimization using a single demonstration,” inProc. 38th Int. Conf. Mach. Learn., 2021, pp. 6611–6620
2021
-
[31]
Hybrid rl: Using both offline and online data can make rl efficient,
Y . Song, Y . Zhou, A. Sekhari, J. A. Bagnell, A. Krishnamurthy, and W. Sun, “Hybrid rl: Using both offline and online data can make rl efficient,” inProc. 11th Int. Conf. Learn. Represent. (ICLR), 2023
2023
-
[32]
Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble,
S. Lee, Y . Seo, K. Lee, P. Abbeel, and J. Shin, “Offline-to-online reinforcement learning via balanced replay and pessimistic q-ensemble,” inProc. Conf. Robot Learn., 2022, pp. 1702–1712
2022
-
[33]
Dcur: Data curriculum for teaching via samples with reinforcement learning,
D. Seita, A. Gopal, Z. Mandi, and J. Canny, “Dcur: Data curriculum for teaching via samples with reinforcement learning,” inarXiv preprint arXiv:2109.07380, 2021
arXiv 2021
-
[34]
An actor-critic algorithm for constrained markov decision processes,
V . S. Borkar, “An actor-critic algorithm for constrained markov decision processes,”Syst. Control Lett., vol. 54, no. 3, pp. 207–213, 2005
2005
-
[35]
Reinforcement learning by guided safe exploration,
Q. Yang, T. D. Sim ˜ao, N. Jansen, S. H. Tindemans, and M. T. Spaan, “Reinforcement learning by guided safe exploration,” inProc. 26th Eur. Conf. Artif. Intell., 2023, pp. 2858–2865
2023
-
[36]
Guarded policy optimization with imperfect online demonstrations,
Z. Xue, Z. Peng, Q. Li, Z. Liu, and B. Zhou, “Guarded policy optimization with imperfect online demonstrations,”Proc. 11th Int. Conf. Learn. Represent. (ICLR), 2023
2023
-
[37]
Approximately optimal approximate rein- forcement learning,
S. Kakade and J. Langford, “Approximately optimal approximate rein- forcement learning,” inProc. 19th Int. Conf. Mach. Learn., 2002, pp. 267–274
2002
-
[38]
G. B. Folland,Real analysis: modern techniques and their applications. John Wiley & Sons, 1999
1999
-
[39]
T. M. Cover and J. A. Thomas,Elements of Information Theory, 2nd ed. Wiley, 2006
2006
-
[40]
An environment for autonomous driving decision-making,
E. Leurent, “An environment for autonomous driving decision-making,” GitHub repository, 2018
2018
-
[41]
The kinematic bicycle model: A consistent model for planning feasible trajectories for autonomous vehicles?
P. Polack, F. Altch ´e, B. d’Andr ´ea Novel, and A. de La Fortelle, “The kinematic bicycle model: A consistent model for planning feasible trajectories for autonomous vehicles?” inProc. IEEE Intell. Veh. Symp. (IV 2017), 2017, pp. 812–818
2017
-
[42]
Congested traffic states in empirical observations and microscopic simulations,
M. Treiber, A. Hennecke, and D. Helbing, “Congested traffic states in empirical observations and microscopic simulations,”Phys. Rev. E, vol. 62, no. 2, p. 1805, 2000
2000
-
[43]
Preferred time-headway of highway drivers,
T. Ayres, L. Li, D. Schleuning, and D. Young, “Preferred time-headway of highway drivers,” inProc. 4th IEEE Intell. Transp. Syst. Conf. (ITSC), 2001, pp. 826–829
2001
-
[44]
Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” inProc. 35th Int. Conf. Mach. Learn., 2018, pp. 1861–1870
2018
-
[45]
Responsive safety in reinforce- ment learning by pid lagrangian methods,
A. Stooke, J. Achiam, and P. Abbeel, “Responsive safety in reinforce- ment learning by pid lagrangian methods,” inProc. 37th Int. Conf. Mach. Learn., 2020, pp. 9133–9143
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.