PhyEditBench: A Real-World Multi-Stage Benchmark for Physics-Aware Image Editing
Pith reviewed 2026-06-26 05:26 UTC · model grok-4.3
The pith
Existing image editing models show major gaps in physics reasoning, as revealed by a new benchmark of real-world video instances, while a training-free baseline that treats video generation as reasoning outperforms them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
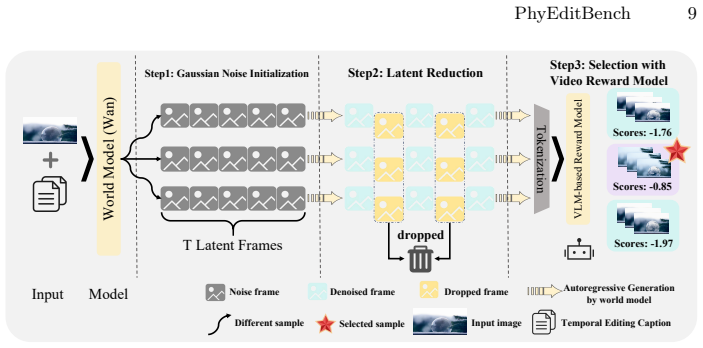
PhyEditBench shows that state-of-the-art instruction-based image editing methods have substantial limitations in physics-based reasoning when applied to authentic real-world dynamics. The benchmark supplies video-derived instances that capture genuine physical processes, and the training-free PhyWorld baseline demonstrates that the video generation process itself can function as an effective reasoning mechanism for producing more physically consistent edits.
What carries the argument
PhyEditBench benchmark with its hierarchical taxonomy of physics phenomena and video-extracted instances, together with the PhyWorld method that uses test-time scaling and latent reduction to treat video generation as a reasoning step for image editing.
If this is right
- Current state-of-the-art editing methods exhibit substantial limitations in physics-based reasoning on real-world cases.
- PhyWorld outperforms comparable models on the benchmark without requiring additional training.
- The video generation process can serve as a reasoning mechanism that improves physical fidelity in image edits.
- Benchmarks focused on physics phenomena are needed to expose and address these limitations in editing models.
Where Pith is reading between the lines
- Editing systems that draw on video priors may reduce unphysical artifacts in tasks involving motion or causality.
- The benchmark could be used to measure how well models handle edits that require predicting physical outcomes over multiple steps.
- Integrating temporal consistency checks from video generation might become a standard component of future editing pipelines.
Load-bearing premise
The 238 video-derived instances are assumed to capture authentic physical dynamics and the taxonomy of four classes and twelve subclasses is assumed to cover the physics aspects that matter for real-world editing.
What would settle it
A controlled test in which the same input image and instruction are edited by multiple models and the outputs are compared against the actual next frames of the source videos for measurable physical consistency, such as correct object trajectories after a collision.
Figures

read the original abstract
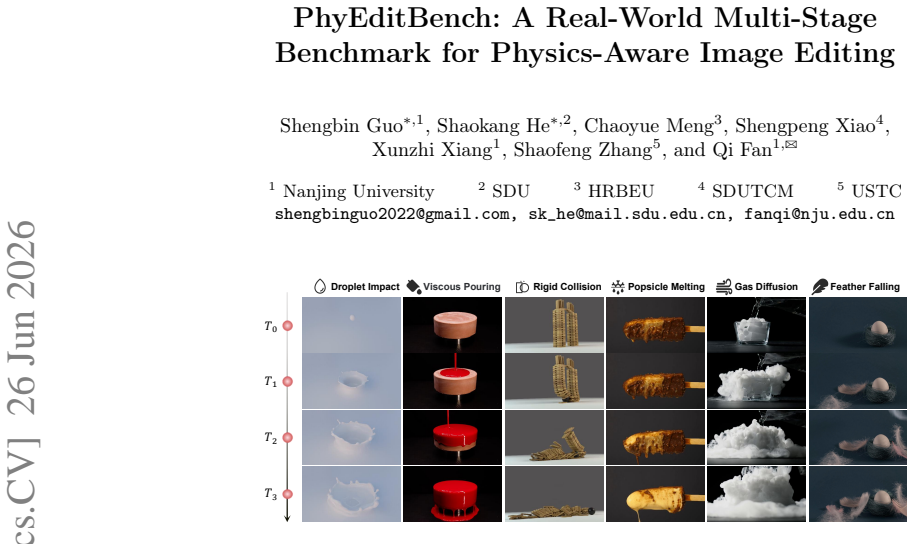
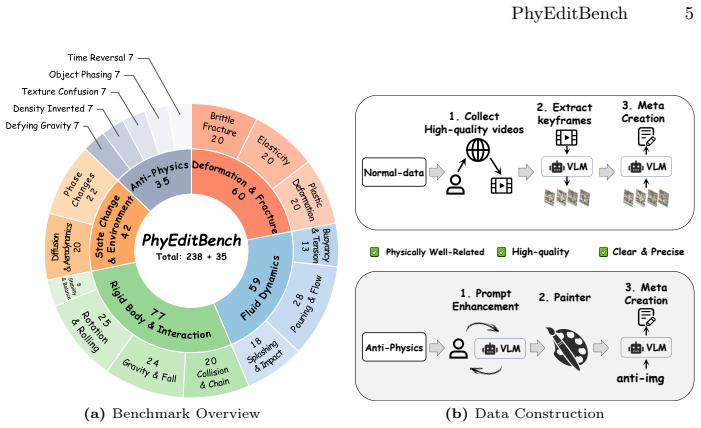
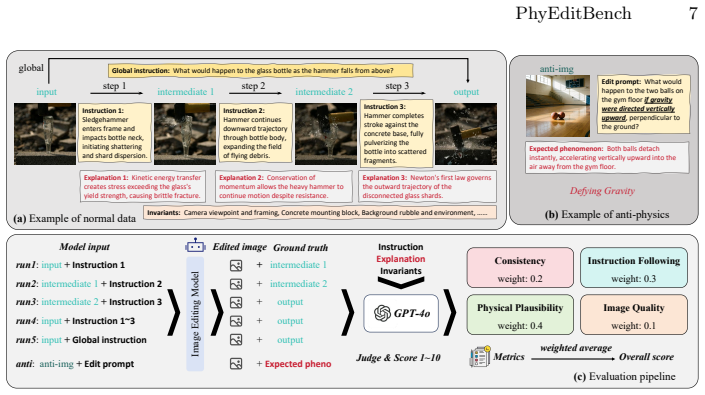
While instruction-based image editing, enabled by multi-modal generative models, has advanced significantly, existing benchmarks lack a comprehensive evaluation of physics-based reasoning, a critical capability for handling real-world scenarios. To address this, we introduce PhyEditBench, a benchmark designed to assess the physical understanding of editing models. Guided by a hierarchical taxonomy, we establish 4 primary classes and 12 subclasses. It comprises 238 high-quality, high-resolution, real-world instances meticulously extracted from videos to capture authentic physical dynamics, alongside 35 synthetic Anti-Physics instances. Our empirical analysis of current SOTA editing methods exposes substantial limitations in their physics-based reasoning. We further propose a training-free baseline named PhyWorld that uses test-time scaling and a latent reduction strategy. PhyWorld outperforms comparable models and suggests that the video generation process can effectively serve as a reasoning mechanism for image editing. The project page is available at https://github.com/Previsior/PhyEditBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PhyEditBench, a benchmark for assessing physics-based reasoning in instruction-based image editing. Guided by a 4-primary/12-subclass hierarchical taxonomy, it comprises 238 high-resolution real-world instances extracted from videos plus 35 synthetic Anti-Physics cases. Empirical analysis of SOTA methods is said to reveal substantial limitations in physics reasoning; the authors also propose PhyWorld, a training-free baseline using test-time scaling and latent reduction, which outperforms comparables and suggests video generation can serve as an image-editing reasoning mechanism.
Significance. A rigorously validated benchmark of this kind would be significant for exposing gaps in current generative models' handling of real-world physics (momentum, gravity, etc.) and for motivating new reasoning strategies such as PhyWorld's video-generation approach. The work supplies a new dataset and baseline rather than a parameter-free derivation or machine-checked proof, so its value hinges entirely on the fidelity of the 238 instances and the reported performance gaps.
major comments (3)
- [Abstract] Abstract: the claim that the 238 instances were 'meticulously extracted from videos to capture authentic physical dynamics' supplies no selection criteria, exclusion rules for non-physics confounders, inter-rater reliability statistics, or validation that the prompts isolate dynamics (e.g., momentum, gravity) from mere appearance change. This is load-bearing for the assertion that observed performance gaps reflect physics deficits rather than benchmark artifacts.
- [Abstract] Abstract: the statements that analysis 'exposes substantial limitations' and that 'PhyWorld outperforms comparable models' are unsupported by any metrics, statistical tests, instance-selection details, or error analysis, preventing verification that the central empirical claims hold.
- [Abstract] Abstract: the 4-primary/12-subclass taxonomy is presented without coverage analysis or justification that it comprehensively addresses the physics aspects relevant to real-world image editing, undermining the claim that the benchmark is a faithful diagnostic.
minor comments (1)
- [Abstract] Abstract: the GitHub link is given but no statement appears on data release, licensing, or reproducibility of the 238 instances and evaluation protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and will revise the abstract to improve clarity and self-containment while preserving its concise nature.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the 238 instances were 'meticulously extracted from videos to capture authentic physical dynamics' supplies no selection criteria, exclusion rules for non-physics confounders, inter-rater reliability statistics, or validation that the prompts isolate dynamics (e.g., momentum, gravity) from mere appearance change. This is load-bearing for the assertion that observed performance gaps reflect physics deficits rather than benchmark artifacts.
Authors: The full manuscript (Section 3.2) details the video extraction protocol, including explicit selection criteria focused on verifiable physical events, rules excluding appearance-only or camera-induced changes, and inter-rater validation. We agree the abstract should reference these elements briefly and will revise it to do so. revision: yes
-
Referee: [Abstract] Abstract: the statements that analysis 'exposes substantial limitations' and that 'PhyWorld outperforms comparable models' are unsupported by any metrics, statistical tests, instance-selection details, or error analysis, preventing verification that the central empirical claims hold.
Authors: Section 4 of the manuscript reports the full quantitative results, including per-class metrics, statistical comparisons, and error breakdowns. We will revise the abstract to include one or two key performance figures and a reference to the analysis to make the summary claims verifiable at a glance. revision: yes
-
Referee: [Abstract] Abstract: the 4-primary/12-subclass taxonomy is presented without coverage analysis or justification that it comprehensively addresses the physics aspects relevant to real-world image editing, undermining the claim that the benchmark is a faithful diagnostic.
Authors: Section 3.1 motivates the taxonomy from a survey of physics phenomena in editing tasks and provides coverage rationale with examples. We will add a concise justification sentence to the abstract to address this point directly. revision: yes
Circularity Check
No circularity: benchmark construction and empirical comparison are self-contained
full rationale
The paper describes construction of PhyEditBench via video extraction and taxonomy, plus a training-free baseline PhyWorld, with empirical comparisons to SOTA methods. No equations, parameter fitting, derivations, or self-citations appear in the provided text. The central claims rest on the benchmark instances and observed performance gaps rather than any reduction to inputs by construction. This matches the default expectation of an honest non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Image editing models must demonstrate understanding of physical laws to produce realistic outputs in real-world scenarios.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2303.08774 (2023) 3
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 3
Pith/arXiv arXiv 2023
-
[2]
In: European conference on computer vi- sion
Bar-Tal, O., Ofri-Amar, D., Fridman, R., Kasten, Y., Dekel, T.: Text2live: Text- driven layered image and video editing. In: European conference on computer vi- sion. pp. 707–723. Springer (2022) 2
2022
-
[3]
arXiv preprint arXiv:2106.08261 (2021) 4, 6
Bear, D.M., Wang, E., Mrowca, D., Binder, F.J., Tung, H.Y.F., Pramod, R., Hold- away, C., Tao, S., Smith, K., Sun, F.Y., et al.: Physion: Evaluating physical predic- tion from vision in humans and machines. arXiv preprint arXiv:2106.08261 (2021) 4, 6
arXiv 2021
-
[4]
arXiv preprint arXiv:2311.15127 (2023) 2, 4, 6
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023) 2, 4, 6
Pith/arXiv arXiv 2023
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18392–18402 (2023) 2, 3, 11
2023
-
[6]
OpenAI Technical Report (2024),https://openai.com/research/ video-generation-models-as-world-simulators2, 4, 6
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Ramesh, A., Klar, M., Sohl-Dickstein, J., et al.: Video generation models as world simulators. OpenAI Technical Report (2024),https://openai.com/research/ video-generation-models-as-world-simulators2, 4, 6
2024
-
[7]
arXiv preprint arXiv:2512.24551 (2025) 4
Cai, Y., Li, K., Jia, M., Wang, J., Sun, J., Liang, F., Chen, W., Juefei-Xu, F., Wang, C., Thabet, A., et al.: Phygdpo: Physics-aware groupwise direct prefer- ence optimization for physically consistent text-to-video generation. arXiv preprint arXiv:2512.24551 (2025) 4
Pith/arXiv arXiv 2025
-
[8]
arXiv preprint arXiv:2601.10592 (2026) 4
Chen, D., Kasarla, T., Bang, Y., Shukor, M., Chung, W., Yu, J., Bolourchi, A., Moutakanni, T., Fung, P.: Action100m: A large-scale video action dataset. arXiv preprint arXiv:2601.10592 (2026) 4
arXiv 2026
-
[9]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Chen, Z., Zhou, Q., Shen, Y., Hong, Y., Sun, Z., Gutfreund, D., Gan, C.: Visual chain-of-thought prompting for knowledge-based visual reasoning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 1254–1262 (2024) 6
2024
-
[10]
arXiv preprint arXiv:2507.06261 (2025) 2, 11
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025) 2, 11
Pith/arXiv arXiv 2025
-
[11]
arXiv preprint arXiv:2505.14683 (2025) 2, 11
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerging properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025) 2, 11
Pith/arXiv arXiv 2025
-
[12]
In: Proceedings of the IEEE/CVF international conference on computer vision
Esser, P., Chiu, J., Atighehchian, P., Granskog, J., Germanidis, A.: Structure and content-guided video synthesis with diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7346–7356 (2023) 2
2023
-
[13]
Nature Machine In- telligence2(11), 665–673 (2020) 7
Geirhos, R., Jacobsen, J.H., Michaelis, C., Zemel, R., Brendel, W., Bethge, M., Wichmann, F.A.: Shortcut learning in deep neural networks. Nature Machine In- telligence2(11), 665–673 (2020) 7
2020
-
[14]
Advances in Neural Information Processing Systems36, 52132–52152 (2023) 2 16 S
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems36, 52132–52152 (2023) 2 16 S. Guo et al
2023
-
[15]
something something
Goyal, R., Ebrahimi Kahou, S., Michalski, V., Materzynska, J., Westphal, S., Kim, H., Haenel, V., Fruend, I., Yianilos, P., Mueller-Freitag, M., et al.: The" something something" video database for learning and evaluating visual common sense. In: Proceedings of the IEEE international conference on computer vision. pp. 5842– 5850 (2017) 4
2017
-
[16]
arXiv preprint arXiv:2506.03596 (2025) 3
Han, F., Jiao, Y., Chen, S., Xu, J., Chen, J., Jiang, Y.G.: Controlthinker: Unveiling latent semantics for controllable image generation through visual reasoning. arXiv preprint arXiv:2506.03596 (2025) 3
arXiv 2025
-
[17]
arXiv preprint arXiv:2511.01295 (2025) 2, 3, 4, 8
Han, F., Wang, Y., Li, C., Liang, Z., Wang, D., Jiao, Y., Wei, Z., Gong, C., Jin, C., Chen, J., et al.: Unireditbench: A unified reasoning-based image editing benchmark. arXiv preprint arXiv:2511.01295 (2025) 2, 3, 4, 8
arXiv 2025
-
[18]
arXiv preprint arXiv:2505.17618 (2025) 3, 9, 10
He, H., Liang, J., Wang, X., Wan, P., Zhang, D., Gai, K., Pan, L.: Scaling image and video generation via test-time evolutionary search. arXiv preprint arXiv:2505.17618 (2025) 3, 9, 10
arXiv 2025
-
[19]
arXiv preprint arXiv:2512.24165 (2025) 2
He, Z., Qu, X., Li, Y., Zhu, T., Huang, S., Cheng, Y.: Diffthinker: Towards genera- tive multimodal reasoning with diffusion models. arXiv preprint arXiv:2512.24165 (2025) 2
arXiv 2025
-
[20]
arXiv preprint arXiv:2208.01626 (2022) 2
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022) 2
Pith/arXiv arXiv 2022
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Y., Xie, L., Wang, X., Yuan, Z., Cun, X., Ge, Y., Zhou, J., Dong, C., Huang,R.,Zhang,R.,etal.:Smartedit:Exploringcomplexinstruction-basedimage editing with multimodal large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8362–8371 (2024) 3
2024
-
[22]
arXiv preprint arXiv:2410.21276 (2024) 2, 11
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024) 2, 11
Pith/arXiv arXiv 2024
-
[23]
arXiv preprint arXiv:2512.23568 (2025) 2
Jiao, S., Lin, Y., Zhong, Y., She, Q., Zhou, W., Lan, X., Huang, Z., Yu, F., Yu, Y., Zhao, Y., et al.: Thinkgen: Generalized thinking for visual generation. arXiv preprint arXiv:2512.23568 (2025) 2
arXiv 2025
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kawar, B., Zada, S., Lang, O., Tov, O., Chang, H., Dekel, T., Mosseri, I., Irani, M.: Imagic: Text-based real image editing with diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6007–6017 (2023) 2
2023
-
[25]
Biometrika33(3), 239– 251 (1945) 13
Kendall, M.G.: The treatment of ties in ranking problems. Biometrika33(3), 239– 251 (1945) 13
1945
-
[26]
arXiv preprint arXiv:2312.14125 (2023) 2, 4
Kondratyuk, D., Yu, L., Gu, X., Lezama, J., Huang, J., Schindler, G., Hornung, R., Birodkar, V., Yan, J., Chiu, M.C., et al.: Videopoet: A large language model for zero-shot video generation. arXiv preprint arXiv:2312.14125 (2023) 2, 4
Pith/arXiv arXiv 2023
-
[27]
1 kontext: Flow match- ing for in-context image generation and editing in latent space
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dock- horn, T., English, J., English, Z., Esser, P., et al.: Flux. 1 kontext: Flow match- ing for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025) 2, 11
Pith/arXiv arXiv 2025
-
[28]
arXiv preprint arXiv:2601.03467 (2026) 2
Li, H., Jiang, L., Yan, Q., Song, Y., Kang, H., Liu, Z., Lu, X., Wu, B., Cai, D.: Thinkrl-edit: Thinking in reinforcement learning for reasoning-centric image editing. arXiv preprint arXiv:2601.03467 (2026) 2
arXiv 2026
-
[29]
arXiv preprint arXiv:2512.05965 (2025) 2, 3 PhyEditBench 17
Li, H., Zhang, M., Zheng, D., Guo, Z., Jia, Y., Feng, K., Yu, H., Liu, Y., Feng, Y., Pei, P., et al.: Editthinker: Unlocking iterative reasoning for any image editor. arXiv preprint arXiv:2512.05965 (2025) 2, 3 PhyEditBench 17
arXiv 2025
-
[30]
arXiv preprint arXiv:2512.13276 (2025) 2
Li, Y., Liu, L., Zhang, X., Xue, W., Luo, W., Guo, Y., Tian, Q.: Cogniedit: Dense gradient flow optimization for fine-grained image editing. arXiv preprint arXiv:2512.13276 (2025) 2
arXiv 2025
-
[31]
arXiv preprint arXiv:2510.16888 (2025) 2, 11
Li, Z., Liu, Z., Zhang, Q., Lin, B., Wu, F., Yuan, S., Yan, Z., Ye, Y., Yu, W., Niu, Y., et al.: Uniworld-v2: Reinforce image editing with diffusion negative-aware finetuning and mllm implicit feedback. arXiv preprint arXiv:2510.16888 (2025) 2, 11
Pith/arXiv arXiv 2025
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024) 3
2024
-
[33]
arXiv preprint arXiv:2501.13918 (2025) 3, 9, 10
Liu, J., Liu, G., Liang, J., Yuan, Z., Liu, X., Zheng, M., Wu, X., Wang, Q., Qin, W., Xia, M., et al.: Improving video generation with human feedback. arXiv preprint arXiv:2501.13918 (2025) 3, 9, 10
Pith/arXiv arXiv 2025
-
[34]
arXiv preprint arXiv:2504.17761 (2025) 2, 11
Liu, S., Han, Y., Xing, P., Yin, F., Wang, R., Cheng, W., Liao, J., Wang, Y., Fu, H., Han, C., et al.: Step1x-edit: A practical framework for general image editing. arXiv preprint arXiv:2504.17761 (2025) 2, 11
Pith/arXiv arXiv 2025
-
[35]
Marcus, G.: The next decade in ai: Four steps towards robust artificial intelligence. arxiv. arXiv preprint arXiv:2002.06177 (2020) 7
arXiv 2002
-
[36]
arXiv preprint arXiv:2108.01073 (2021) 2
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073 (2021) 2
Pith/arXiv arXiv 2021
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Mokady, R., Hertz, A., Aberman, K., Pritch, Y., Cohen-Or, D.: Null-text inver- sion for editing real images using guided diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6038–6047 (2023) 2
2023
-
[38]
arXiv preprint arXiv:2512.00387 (2025) 2, 3, 4, 8
Pan, K., Chen, W., Qiu, H., Yu, Q., Bu, W., Wang, Z., Zhu, Y., Li, J., Tang, S.: Wiseedit: Benchmarking cognition-and creativity-informed image editing. arXiv preprint arXiv:2512.00387 (2025) 2, 3, 4, 8
arXiv 2025
-
[39]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023) 3
2023
-
[40]
arXiv preprint arXiv:2508.05606 (2025) 2
Qin, L., Gong, J., Sun, Y., Li, T., Yang, M., Yang, X., Qu, C., Tan, Z., Li, H.: Uni-cot: Towards unified chain-of-thought reasoning across text and vision. arXiv preprint arXiv:2508.05606 (2025) 2
arXiv 2025
-
[41]
arXiv preprint arXiv:2204.06125 1(2), 3 (2022) 2, 4
Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text- conditional image generation with clip latents. arXiv preprint arXiv:2204.06125 1(2), 3 (2022) 2, 4
Pith/arXiv arXiv 2022
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 2, 3
2022
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rotstein, N., Yona, G., Silver, D., Velich, R., Bensaïd, D., Kimmel, R.: Pathways on the image manifold: Image editing via video generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7857– 7866 (2025) 2, 5, 9, 11
2025
-
[44]
arXiv preprint arXiv:2509.20427 (2025) 2, 11
Seedream, T., Chen, Y., Gao, Y., Gong, L., Guo, M., Guo, Q., Guo, Z., Hou, X., Huang, W., Huang, Y., et al.: Seedream 4.0: Toward next-generation multimodal image generation. arXiv preprint arXiv:2509.20427 (2025) 2, 11
Pith/arXiv arXiv 2025
-
[45]
Cognitive science14(1), 29–56 (1990) 6 18 S
Spelke, E.S.: Principles of object perception. Cognitive science14(1), 29–56 (1990) 6 18 S. Guo et al
1990
-
[46]
arXiv preprint arXiv:2312.11805 (2023) 3
Team, G., Anil, R., Borgeaud, S., Alayrac, J.B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A.M., Hauth, A., Millican, K., et al.: Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023) 3
Pith/arXiv arXiv 2023
-
[47]
Team, Q.: Qwen3.5: Accelerating productivity with native multimodal agents (February 2026),https://qwen.ai/blog?id=qwen3.59
2026
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition
Thrush, T., Jiang, R., Bartolo, M., Singh, A., Williams, A., Kiela, D., Ross, C.: Winoground: Probing vision and language models for visio-linguistic composition- ality. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition. pp. 5238–5248 (2022) 7
2022
-
[49]
arXiv preprint arXiv:2511.09611 (2025) 2
Tian, Y., Yang, L., Yang, J., Wang, A., Tian, Y., Zheng, J., Wang, H., Teng, Z., Wang, Z., Wang, Y., et al.: Mmada-parallel: Multimodal large diffusion language models for thinking-aware editing and generation. arXiv preprint arXiv:2511.09611 (2025) 2
arXiv 2025
-
[50]
arXiv preprint arXiv:2601.10061 (2026) 5
Tong, C., Chang, M., Zhang, S., Wang, Y., Liang, C., Zhao, Z., An, R., Zeng, B., Shi, Y., Dai, Y., et al.: Cof-t2i: Video models as pure visual reasoners for text-to- image generation. arXiv preprint arXiv:2601.10061 (2026) 5
arXiv 2026
-
[51]
arXiv preprint arXiv:2503.20314 (2025) 2, 4, 10
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
Pith/arXiv arXiv 2025
-
[52]
arXiv preprint arXiv:2511.11483 (2025) 2
Wang, K., Chen, R., Zheng, T., Huang, H.: Imagent: A unified multi- modal agent framework for test-time scalable image generation. arXiv preprint arXiv:2511.11483 (2025) 2
arXiv 2025
-
[53]
Advances in neural information processing systems35, 24824–24837 (2022) 6
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022) 6
2022
-
[54]
arXiv preprint arXiv:2508.02324 (2025) 2, 11
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025) 2, 11
Pith/arXiv arXiv 2025
-
[55]
arXiv preprint arXiv:2506.18871 (2025) 2, 11
Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y., Li, W., Jiang, X., Liu, Y., Zhou, J., et al.: Omnigen2: Exploration to advanced multimodal generation. arXiv preprint arXiv:2506.18871 (2025) 2, 11
Pith/arXiv arXiv 2025
-
[56]
arXiv preprint arXiv:2510.04290 (2025) 2, 5, 9, 10, 11
Wu, J.Z., Ren, X., Shen, T., Cao, T., He, K., Lu, Y., Gao, R., Xie, E., Lan, S., Alvarez, J.M., et al.: Chronoedit: Towards temporal reasoning for image editing and world simulation. arXiv preprint arXiv:2510.04290 (2025) 2, 5, 9, 10, 11
arXiv 2025
-
[57]
arXiv preprint arXiv:2505.16707 (2025) 2, 3, 4, 8
Wu, Y., Li, Z., Hu, X., Ye, X., Zeng, X., Yu, G., Zhu, W., Schiele, B., Yang, M.H., Yang, X.: Kris-bench: Benchmarking next-level intelligent image editing models. arXiv preprint arXiv:2505.16707 (2025) 2, 3, 4, 8
arXiv 2025
-
[58]
arXiv preprint arXiv:2505.20275 (2025) 2
Ye, Y., He, X., Li, Z., Lin, B., Yuan, S., Yan, Z., Hou, B., Yuan, L.: Imgedit: A unified image editing dataset and benchmark. arXiv preprint arXiv:2505.20275 (2025) 2
Pith/arXiv arXiv 2025
-
[59]
arXiv preprint arXiv:1910.01442 (2019) 4, 6, 7 PhyEditBench 19
Yi, K., Gan, C., Li, Y., Kohli, P., Wu, J., Torralba, A., Tenenbaum, J.B.: Clevrer: Collision events for video representation and reasoning. arXiv preprint arXiv:1910.01442 (2019) 4, 6, 7 PhyEditBench 19
Pith/arXiv arXiv 1910
-
[60]
arXiv preprint arXiv:2511.22625 (2025) 2
Yin, F., Liu, S., Han, Y., Wang, Z., Xing, P., Wang, R., Cheng, W., Wang, Y., Li, A., Yin, Z., et al.: Reasonedit: Towards reasoning-enhanced image editing models. arXiv preprint arXiv:2511.22625 (2025) 2
arXiv 2025
-
[61]
arXiv preprint arXiv:2509.21309 (2025) 4
Yuan, Y., Wang, X., Wickremasinghe, T., Nadir, Z., Ma, B., Chan, S.H.: Newton- gen: Physics-consistent and controllable text-to-video generation via neural new- tonian dynamics. arXiv preprint arXiv:2509.21309 (2025) 4
arXiv 2025
-
[62]
arXiv preprint arXiv:2512.04532 (2025) 4
Zhan, Y.W., Wang, X., Chen, H., Feng, T., Feng, W., Wang, R., Li, G., Li, Q., Zhu, W.: Phyvllm: Physics-guided video language model with motion-appearance disentanglement. arXiv preprint arXiv:2512.04532 (2025) 4
arXiv 2025
-
[63]
Advances in Neural Information Pro- cessing Systems36, 31428–31449 (2023) 2, 3
Zhang, K., Mo, L., Chen, W., Sun, H., Su, Y.: Magicbrush: A manually annotated dataset for instruction-guided image editing. Advances in Neural Information Pro- cessing Systems36, 31428–31449 (2023) 2, 3
2023
-
[64]
In: European Conference on Computer Vision
Zhang, T., Yu, H.X., Wu, R., Feng, B.Y., Zheng, C., Snavely, N., Wu, J., Freeman, W.T.: Physdreamer: Physics-based interaction with 3d objects via video genera- tion. In: European Conference on Computer Vision. pp. 388–406. Springer (2024) 4
2024
-
[65]
Zhang, Z., Chen, Z., Yang, Z., Yang, Y.: Are image-to-video models good zero-shot image editors? arXiv preprint arXiv:2511.19435 (2025) 2
arXiv 2025
-
[66]
arXiv preprint arXiv:2504.02826 (2025) 2, 3, 4, 8
Zhao, X., Zhang, P., Tang, K., Zhu, X., Li, H., Chai, W., Zhang, Z., Xia, R., Zhai, G., Yan, J., et al.: Envisioning beyond the pixels: Benchmarking reasoning- informed visual editing. arXiv preprint arXiv:2504.02826 (2025) 2, 3, 4, 8
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.