The Capability Frontier: Benchmarks Miss 82% of Model Performance
Pith reviewed 2026-06-26 05:15 UTC · model grok-4.3
The pith
Benchmarks that test single models on single runs miss 82% of LLM performance by ignoring optimal selection across models and generations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
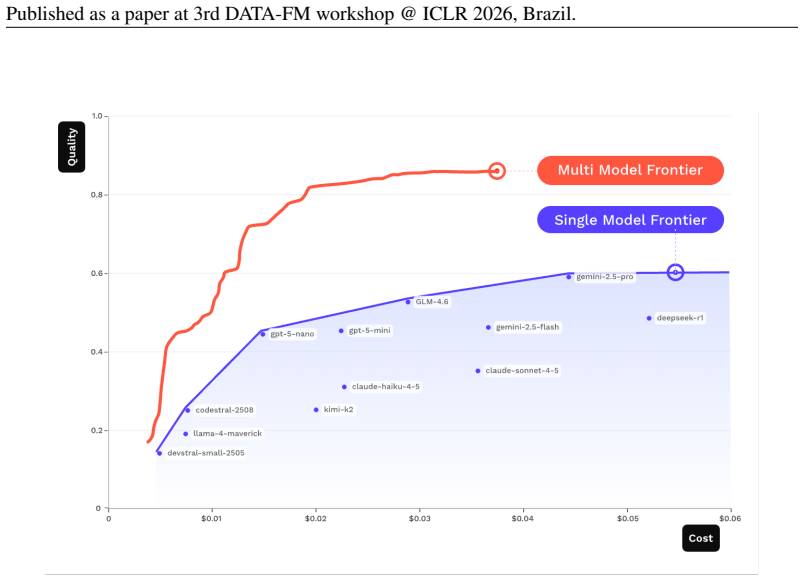
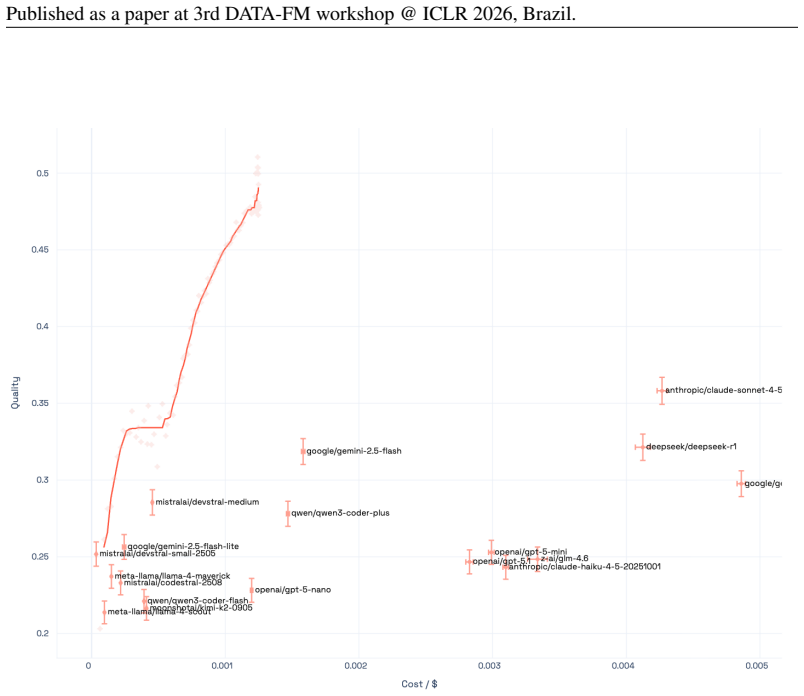
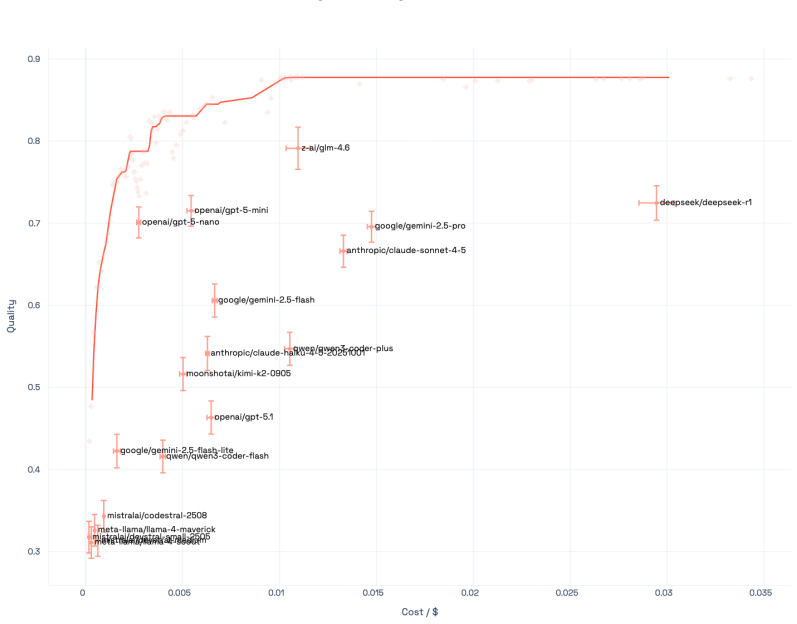
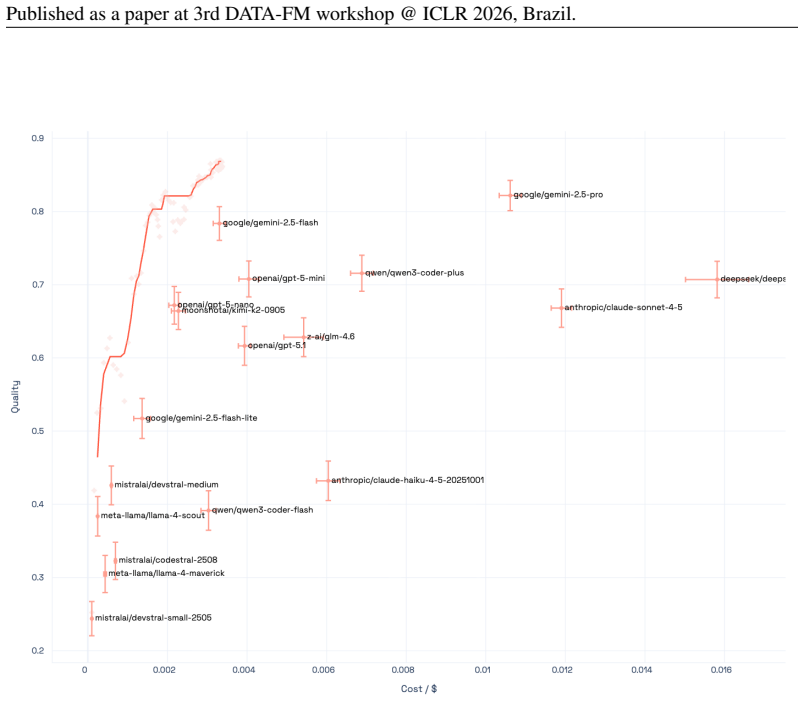
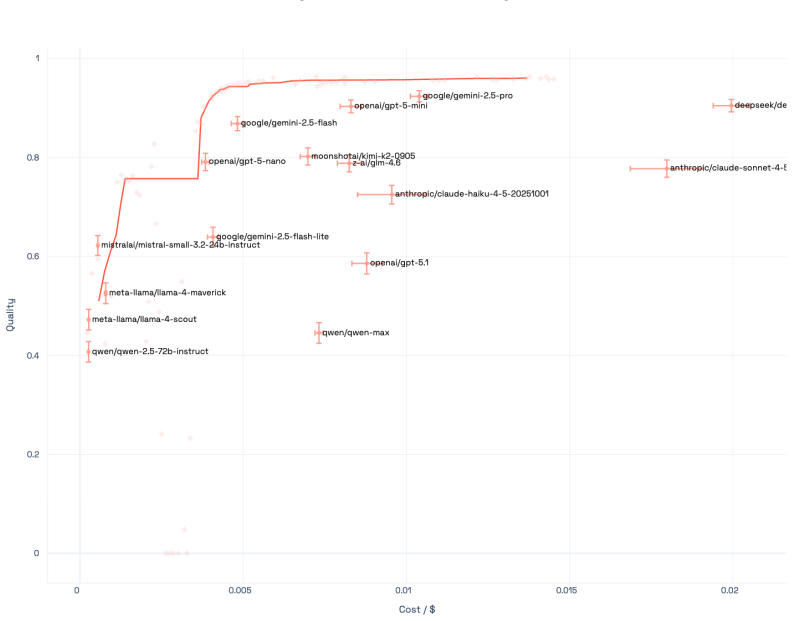
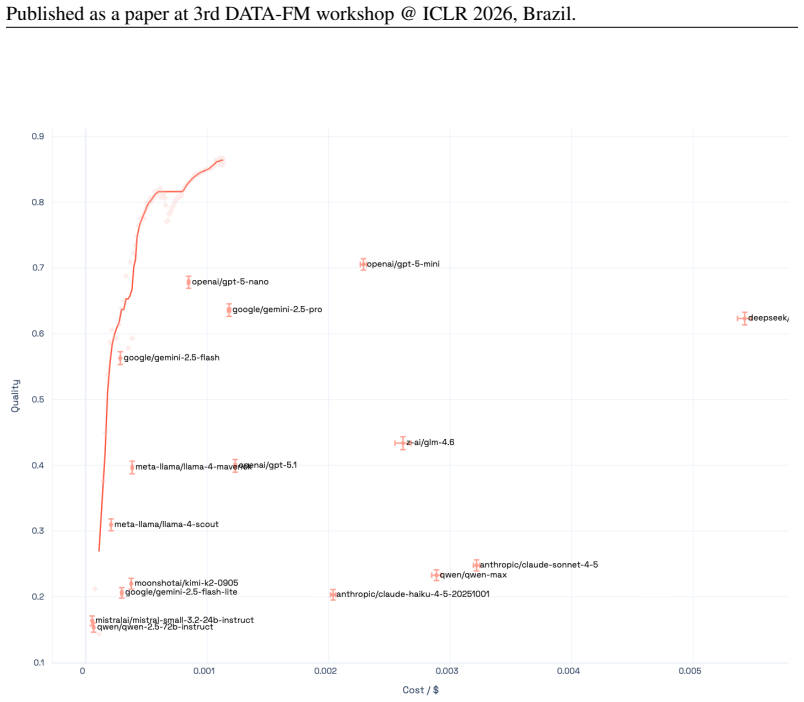
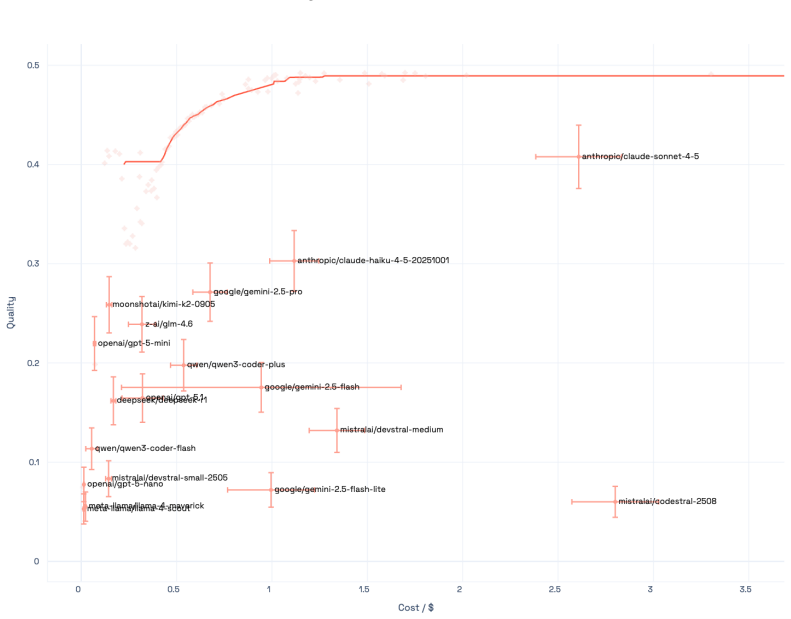
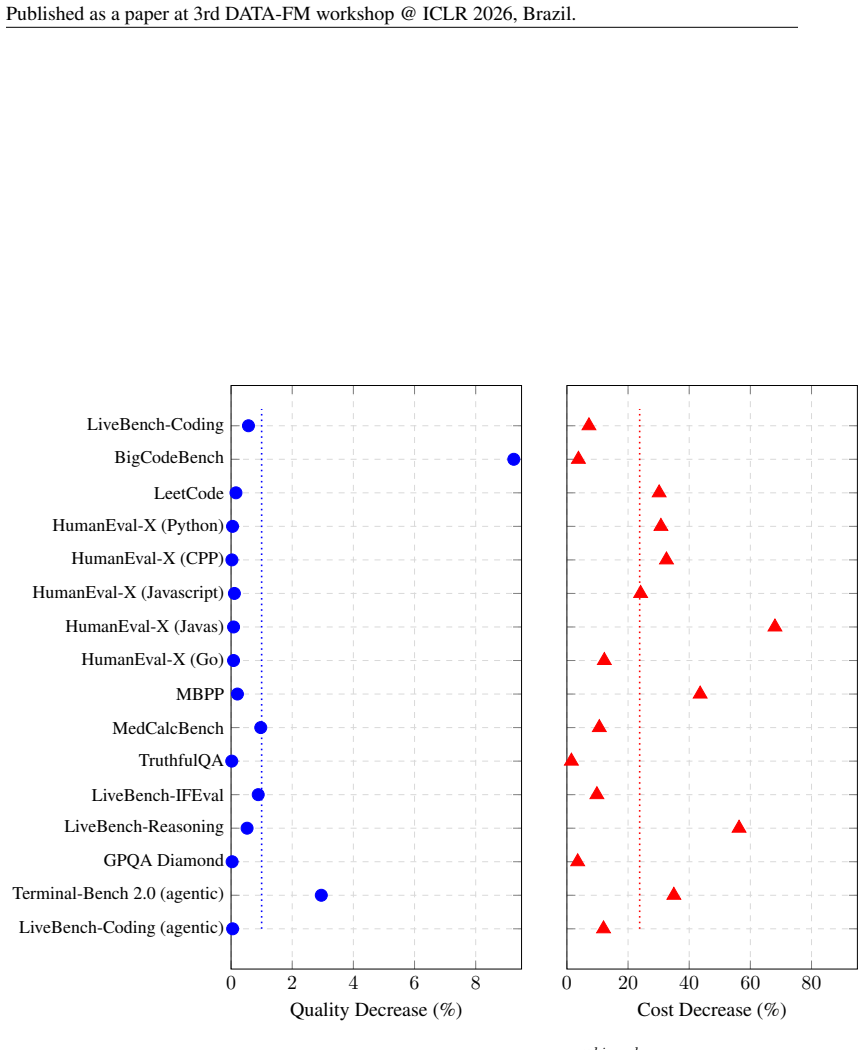
The Capability Frontier is a Pareto frontier over a set of models that characterizes the best achievable performance at each cost level under optimal selection across models and generations via an oracle. This corrects for underestimation from single-model evaluation and overestimation from taking maxima over noisy samples. On 21 LLMs across 16 benchmarks spanning coding, reasoning, medicine and other domains, correcting for single-model evaluation yields a 54% error rate reduction; additionally correcting for single runs yields an 82% improvement, with SOTA accuracy matched at 85% cost reduction. Controlled simulations show higher query topic entropy produces a near-monotonic increase in th
What carries the argument
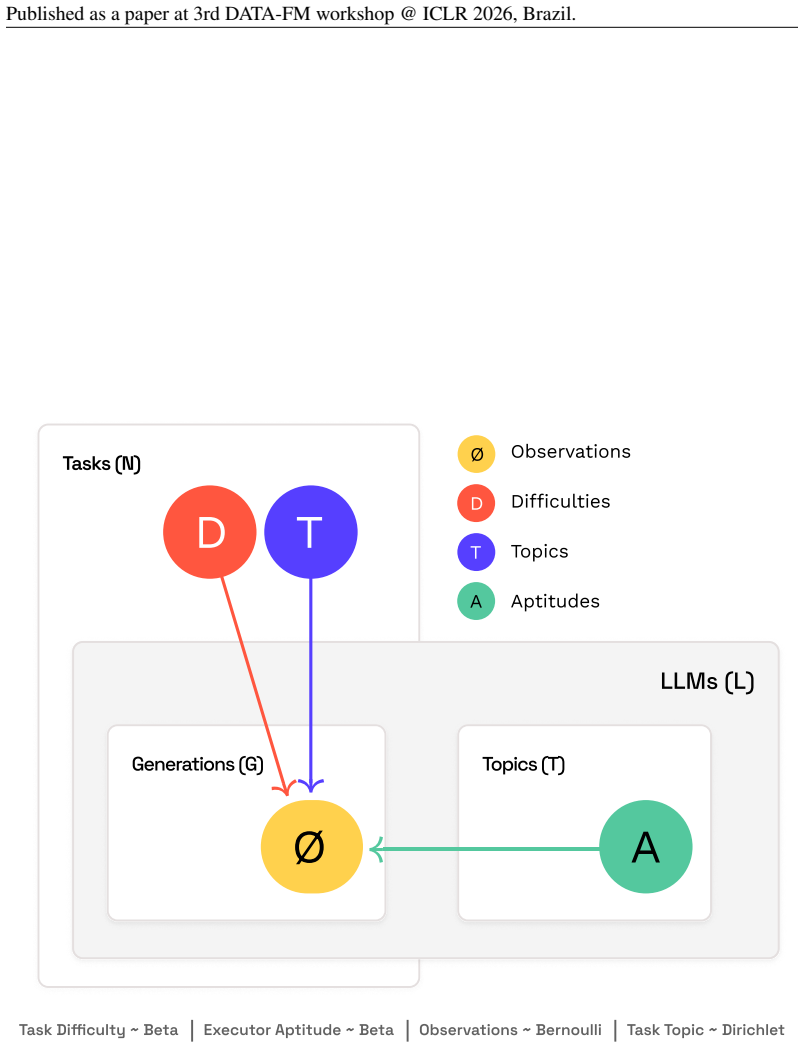
The Capability Frontier, a Pareto frontier over models that characterizes the best achievable performance at each cost level under optimal selection across models and generations via an oracle.
If this is right
- Correcting for single-model evaluation reduces error rates by 54 percent across the studied benchmarks.
- Further correcting for single runs produces an 82 percent performance improvement.
- State-of-the-art accuracy is reachable at 85 percent lower cost using the frontier.
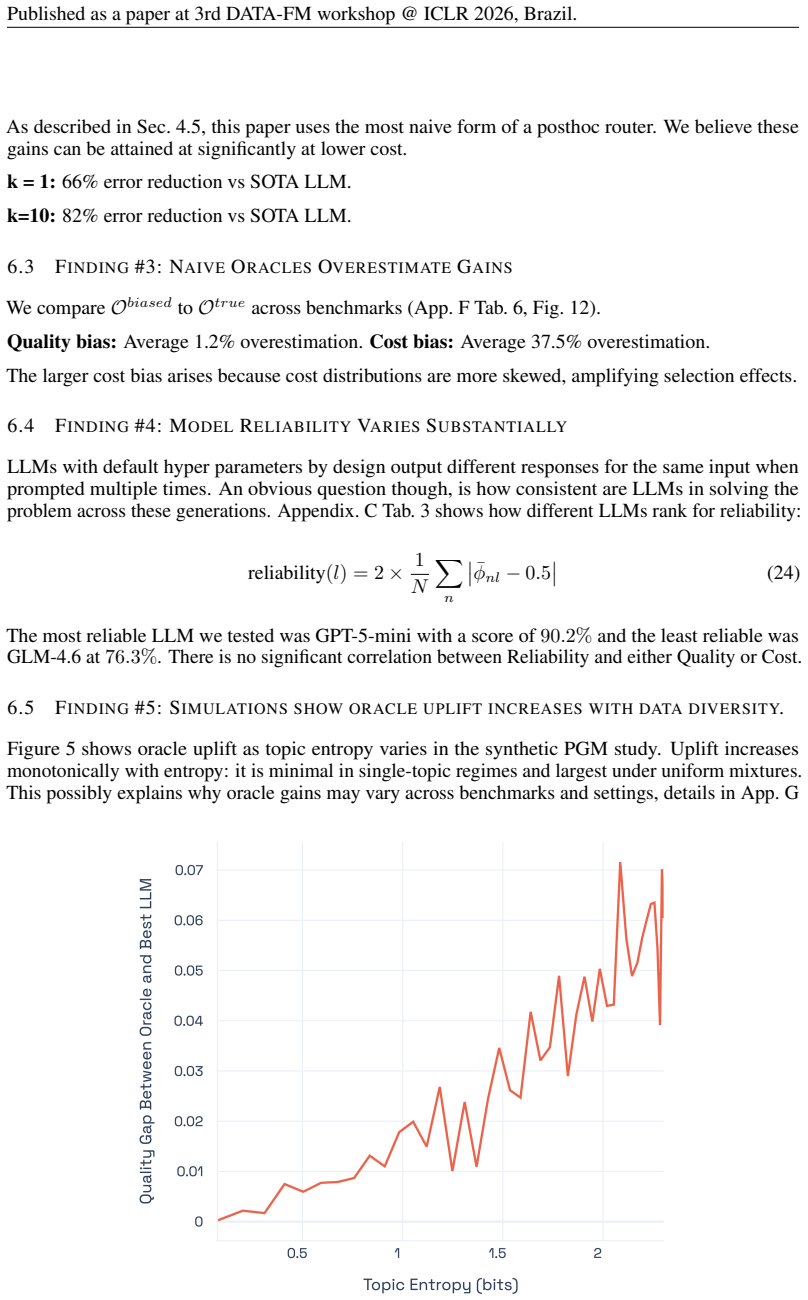
- The gap between the frontier and the best single model grows with higher query topic entropy.
Where Pith is reading between the lines
- Leaderboards may systematically favor generalist models over specialists when domains are mixed.
- Learned routers could approximate much of the oracle gain in deployed systems.
- Evaluation protocols might shift toward reporting frontier performance rather than isolated model scores.
- Real-world multi-domain applications are likely to show even larger underestimation than the benchmarks.
Load-bearing premise
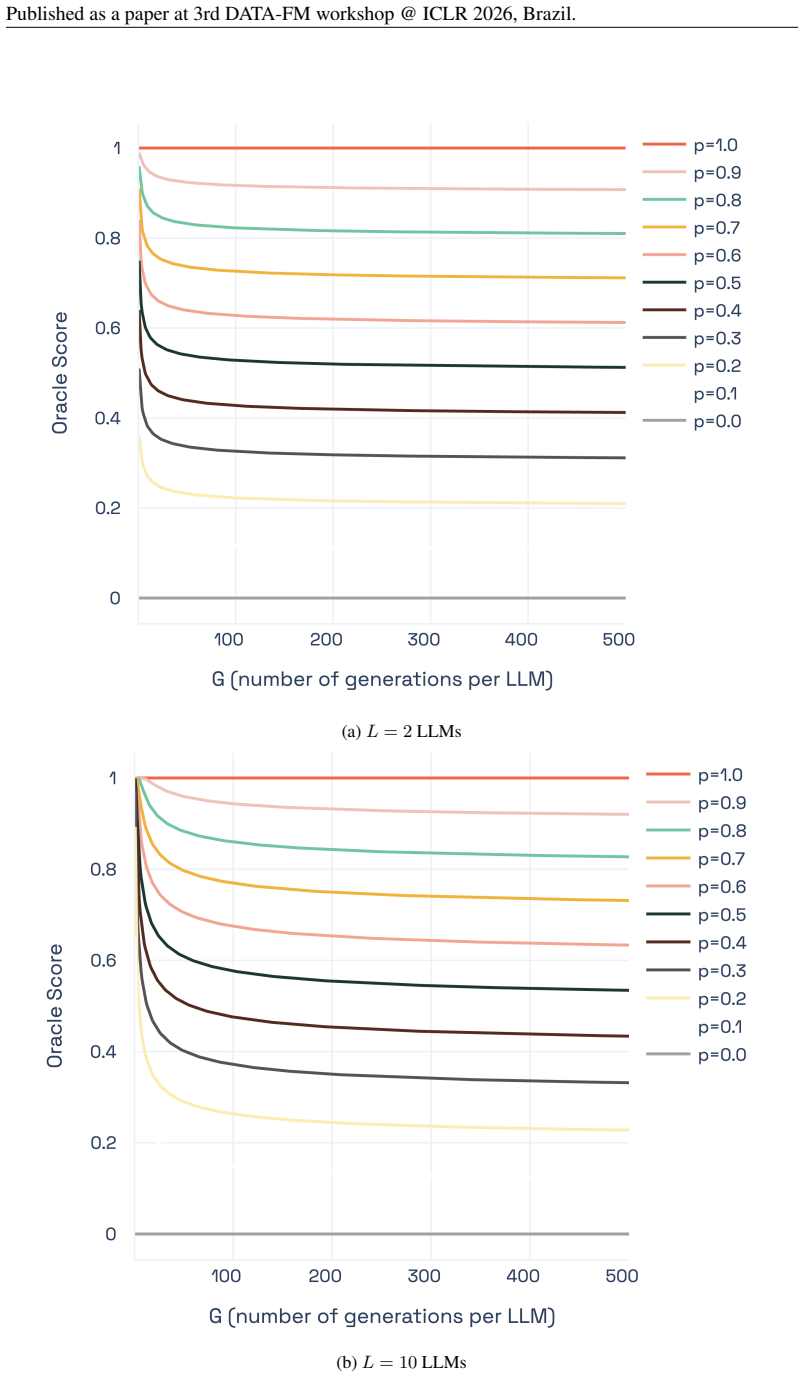
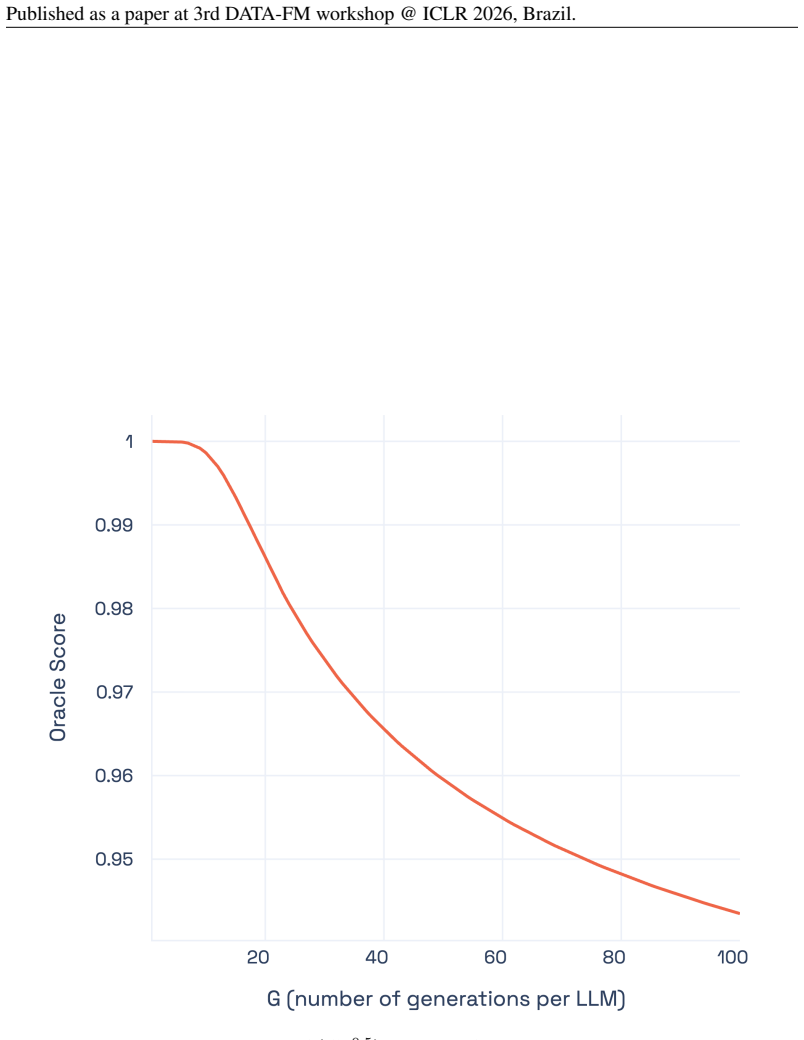
The Capability Frontier construction assumes an oracle exists that can perfectly select the optimal model and generation for every query at the stated cost levels without additional overhead or prior knowledge of correctness.
What would settle it
Implementing a real selector or router that achieves accuracy and cost close to the reported frontier on a held-out benchmark set would test whether the stated gains are realizable.
Figures
read the original abstract
Existing benchmarks typically report accuracy for a single model on a single run. This systematically understates real-world LLM capabilities, particularly under heterogeneous data distributions: (i) different models get different questions correct according to their specializations, and (ii) given a budget, multiple generations can be sampled and selectively retained. To quantify this gap, we introduce the Capability Frontier: a Pareto frontier over a set of models that characterizes the best achievable performance at each cost level under optimal selection across models and generations (i.e., via an oracle). Our construction corrects for two opposing biases: underestimation from single-model evaluation and overestimation from taking maxima over noisy samples. We study 21 LLMs across 16 widely used benchmarks spanning coding, reasoning, medicine, factuality, instruction following, and agentic tasks, comparing Capability Frontier performance at matched cost to each benchmark's top-performing model. Correcting for single-model evaluation yields a 54% error rate reduction; additionally correcting for single runs yields an 82% improvement, with SOTA accuracy matched at 85% cost reduction. Complementing these empirical results, we use controlled probabilistic simulations to show that higher query topic entropy produces a near-monotonic increase in the performance gap between oracle routing and the best single model. Our findings suggest collective LLM capabilities are substantially underestimated, with implications for evaluation and deployment in data-heterogeneous, multi-domain settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard single-model, single-run LLM benchmarks systematically understate capabilities due to model specialization and sampling variance. It introduces the Capability Frontier, a Pareto curve of best achievable accuracy at each cost level obtained by oracle selection of the lowest-cost correct output across 21 LLMs and multiple generations on 16 benchmarks. This yields a 54% error-rate reduction from single-model correction alone, an 82% improvement after also correcting for single runs, and SOTA accuracy at 85% lower cost. Controlled simulations are used to show that higher query-topic entropy monotonically widens the gap between the oracle frontier and the best single model.
Significance. If a practical (non-oracle) selector can be substituted while preserving most of the reported gains, the work would materially change evaluation practice and deployment strategy for heterogeneous workloads. The breadth of the 21-model, 16-benchmark empirical study and the entropy-based simulation provide a concrete, falsifiable basis for the underestimation claim.
major comments (2)
- [Abstract] Abstract: The 54% error-rate reduction, 82% improvement, and 85% cost reduction are obtained by constructing the Capability Frontier as the per-query minimum-cost correct output across all models and generations. The manuscript provides no non-oracle selector, no cost model for selection, and no overhead subtraction, so these quantities are oracle upper bounds whose distance to any realizable procedure remains unmeasured.
- [Abstract and simulation section] Abstract and simulation section: The claim that 'higher query topic entropy produces a near-monotonic increase in the performance gap' is shown only under the same oracle construction; without an accompanying analysis of how a learned router or verifier would degrade under the same entropy regimes, the simulation does not establish that the empirical gaps are attainable.
minor comments (2)
- [Methods] The precise definition of 'cost' (token count, latency, or monetary) and the data-exclusion rules for the 16 benchmarks are not stated in the abstract and should be added to the methods section for reproducibility.
- [Figures] Figure captions should explicitly note that all frontier points assume oracle knowledge of correctness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We agree that the reported gains are oracle upper bounds and will revise the manuscript to make this framing explicit while preserving the core empirical contribution.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 54% error-rate reduction, 82% improvement, and 85% cost reduction are obtained by constructing the Capability Frontier as the per-query minimum-cost correct output across all models and generations. The manuscript provides no non-oracle selector, no cost model for selection, and no overhead subtraction, so these quantities are oracle upper bounds whose distance to any realizable procedure remains unmeasured.
Authors: We agree these quantities are oracle upper bounds. The abstract already states the construction uses 'optimal selection across models and generations (i.e., via an oracle),' but we will revise the abstract to explicitly label the 54%, 82%, and 85% figures as 'oracle upper bounds' and add a short paragraph in the discussion section on the unmeasured gap to practical selectors, including possible overhead. This is a clarification only; the empirical study of the 21-model, 16-benchmark oracle frontier remains unchanged. revision: yes
-
Referee: [Abstract and simulation section] Abstract and simulation section: The claim that 'higher query topic entropy produces a near-monotonic increase in the performance gap' is shown only under the same oracle construction; without an accompanying analysis of how a learned router or verifier would degrade under the same entropy regimes, the simulation does not establish that the empirical gaps are attainable.
Authors: The simulation isolates the effect of topic entropy on the size of the oracle gap to demonstrate that underestimation grows with heterogeneity; it does not claim any particular learned router attains the full gap. We will revise the simulation section to state explicitly that the results quantify oracle potential and that practical routers may realize only a fraction, while the observed monotonicity indicates the attainable benefit is likely larger in high-entropy regimes. No new router experiments are added, as that would constitute a separate study. revision: partial
Circularity Check
No circularity: empirical upper-bound construction on fixed benchmarks
full rationale
The Capability Frontier is defined explicitly as the oracle-selected Pareto front over models and generations, then its accuracy and cost metrics are computed directly from the same ground-truth labels used for single-model baselines. The 54% error reduction, 82% improvement, and 85% cost figures are therefore measured outcomes of this construction rather than quantities that reduce by definition or by fitted-parameter renaming to the paper's own inputs. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the central numbers; the derivation remains self-contained against the external benchmark data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An oracle can select the optimal model and generation for each query to achieve the Pareto frontier at stated costs
invented entities (1)
-
Capability Frontier
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
xRouter: Training Cost-Aware LLMs Orchestration System via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[2]
2025 , eprint=
A Unified Approach to Routing and Cascading for LLMs , author=. 2025 , eprint=
2025
-
[3]
2025 , eprint=
Agreement-Based Cascading for Efficient Inference , author=. 2025 , eprint=
2025
-
[4]
2025 , eprint=
C3PO: Optimized Large Language Model Cascades with Probabilistic Cost Constraints for Reasoning , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
BEST-Route: Adaptive LLM Routing with Test-Time Optimal Compute , author=. 2025 , eprint=
2025
-
[6]
Universal Model Routing for Efficient LLM Inference , author=. arXiv arXiv:2502.08773 , url=. 2025 , eprint=
arXiv 2025
-
[7]
2025 , eprint=
Efficient Training-Free Online Routing for High-Volume Multi-LLM Serving , author=. 2025 , eprint=
2025
-
[8]
Breaking Model Lock-in: Cost-Efficient Zero-Shot LLM Routing via a Universal Latent Space , author=. arXiv arXiv:2601.06220 , url=. 2026 , eprint=
arXiv 2026
-
[9]
arXiv preprint arXiv:2510.01234 , url=
LLMRank: Understanding LLM Strengths for Model Routing , author=. arXiv preprint arXiv:2510.01234 , url=. 2025 , eprint=
arXiv 2025
-
[10]
arXiv preprint arXiv:2508.12491 , url=
Cost-Aware Contrastive Routing for LLMs , author=. arXiv preprint arXiv:2508.12491 , url=. 2025 , eprint=
arXiv 2025
-
[11]
arXiv preprint arXiv:2412.04692 , url=
Smoothie: Label Free Language Model Routing , author=. arXiv preprint arXiv:2412.04692 , url=. 2024 , eprint=
arXiv 2024
-
[12]
2023 , eprint=
Large Language Model Routing with Benchmark Datasets , author=. 2023 , eprint=
2023
-
[13]
2024 , eprint=
RouterBench: A Benchmark for Multi-LLM Routing System , author=. 2024 , eprint=
2024
-
[14]
2023 , eprint=
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance , author=. 2023 , eprint=
2023
-
[15]
2025 , eprint=
RouteLLM: Learning to Route LLMs with Preference Data , author=. 2025 , eprint=
2025
-
[16]
mini-SWE-agent: The 100 line AI agent that solves GitHub issues or helps you in your command line , author =
-
[17]
2026 , note =
LeetCode , author =. 2026 , note =
2026
-
[18]
arXiv , year =
Evaluating Large Language Models Trained on Code , author =. arXiv , year =
-
[19]
2025 , eprint=
Beyond Monoliths: Expert Orchestration for More Capable, Democratic, and Safe Language Models , author=. 2025 , eprint=
2025
-
[20]
Biostatistics , year =
The projack: a resampling approach to correct for ranking bias in high-throughput studies , author =. Biostatistics , year =
-
[21]
Statistics in Medicine , year =
A flexible genome-wide bootstrap method that accounts for ranking- and threshold-selection bias in GWAS interpretation and replication study design , author =. Statistics in Medicine , year =
-
[22]
American Journal of Human Genetics , year =
Overcoming the winner's curse: estimating penetrance parameters from case-control data , author =. American Journal of Human Genetics , year =
-
[23]
Journal of the American Statistical Association , year =
Tweedie's Formula and Selection Bias , author =. Journal of the American Statistical Association , year =
-
[24]
The Annals of Applied Statistics , year =
Bayesian methods to overcome the winner's curse in genetic studies , author =. The Annals of Applied Statistics , year =
-
[25]
PLOS Genetics , year =
Review and further developments in statistical corrections for Winner's Curse in genetic association studies , author =. PLOS Genetics , year =
-
[26]
2025 , volume =
The winner's curse under dependence: repairing empirical Bayes using convolution , journal =. 2025 , volume =
2025
-
[27]
The Quarterly Journal of Economics , year =
Inference on Winners , author =. The Quarterly Journal of Economics , year =
-
[28]
Journal of Petroleum Technology , year =
Competitive Bidding in High-Risk Situations , author =. Journal of Petroleum Technology , year =
-
[29]
Management Science , year =
The Optimizer's Curse: Skepticism and Postdecision Surprise in Decision Analysis , author =. Management Science , year =
-
[30]
arXiv , year =
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author =. arXiv , year =
-
[31]
arXiv , year =
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , author =. arXiv , year =
-
[32]
2023 , note =
HumanEval-X: A New Benchmark for Multilingual Program Synthesis , author =. 2023 , note =
2023
-
[33]
arXiv , year =
Program Synthesis with Large Language Models , author =. arXiv , year =
-
[34]
arXiv , year =
LiveBench: A Challenging, Contamination-Free LLM Benchmark , author =. arXiv , year =
-
[35]
arXiv , year =
GPQA: A Graduate-Level Google-Proof Q&A Benchmark , author =. arXiv , year =
-
[36]
arXiv , year =
MedCalc-Bench: Evaluating Large Language Models for Medical Calculations , author =. arXiv , year =
-
[37]
Proceedings of ACL 2022 , year =
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author =. Proceedings of ACL 2022 , year =
2022
-
[38]
Terminal-Bench , author =
-
[39]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[40]
Introducing GPT-5 for developers , author =
-
[41]
Introducing GPT-5.1 for developers , author =
-
[42]
Introducing Claude Haiku 4.5 , author =
-
[43]
What's new in Claude 4.5 , author =
-
[44]
Gemini 2.5 model family expands , author =
-
[45]
Gemini 2.5 Updates: Flash/Pro GA, SFT, Flash-Lite on Vertex AI , author =
-
[46]
Welcome Llama 4 Maverick & Scout on Hugging Face , author =
-
[47]
Announcing Codestral 25.08 and the Complete Mistral Coding Stack for Enterprises , author =
-
[48]
Kimi K2: Open Agentic Intelligence , author =
-
[49]
arXiv , year =
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. arXiv , year =
-
[50]
GLM-4.6V: Open Source Multimodal Models with Native Tool Use , author =
-
[51]
arXiv , year =
Qwen3 Technical Report , author =. arXiv , year =
-
[52]
2009 , publisher=
Probabilistic Graphical Models: Principles and Techniques , author=. 2009 , publisher=
2009
-
[53]
Nature Medicine , volume=
Toward expert-level medical question answering with large language models , author=. Nature Medicine , volume=. 2025 , publisher=
2025
-
[54]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.