TraMP-LLaMA: Generative Interpretability with Decoupled Instruction Tuning for Facial Expression Quality Assessment
Pith reviewed 2026-06-26 05:07 UTC · model grok-4.3
The pith
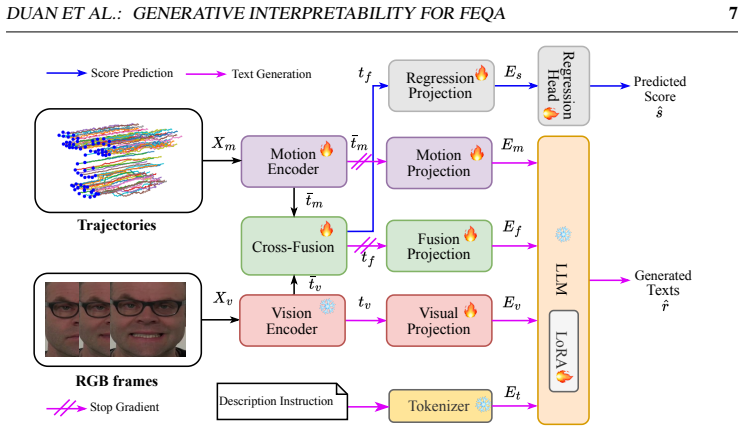
TraMP-LLaMA jointly predicts facial expression severity scores and generates structured textual reports from motion cues using decoupled instruction tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TraMP-LLaMA is a unified multimodal framework that integrates RGB appearance and landmark trajectory cues, adopts a decoupled instruction-tuning strategy to reduce task interference between severity prediction and language generation, and, when trained jointly on multiple expressions, achieves the best severity prediction performance among compared methods while also outperforming competitive video-language baselines in report generation.
What carries the argument
Decoupled instruction-tuning strategy that separates severity scoring from language generation to limit task interference while preserving performance on both.
If this is right
- Severity predictions in Parkinson's assessment become inspectable through explicit textual descriptions of the facial motion evidence.
- Joint training across multiple expressions yields higher rank correlation than single-expression or non-decoupled baselines.
- The same framework structure can accept additional motion-description annotations without degrading numeric prediction accuracy.
- Report generation quality exceeds that of standard video-language models when the tuning stages are kept separate.
Where Pith is reading between the lines
- Similar decoupling may help other medical video tasks that require both a numeric output and a human-readable justification.
- The added text annotations could serve as training data for purely language-based explanation models even if the visual backbone changes.
- If the performance lift holds on larger clinical datasets, the approach could reduce the need for separate post-hoc explanation modules.
Load-bearing premise
The decoupled tuning strategy reduces interference between scoring and report generation without introducing dataset-specific artifacts or overfitting to the added text annotations.
What would settle it
Re-training the model with a single shared instruction-tuning stage instead of the decoupled stage and finding that the reported gains in both Spearman's correlation and report quality disappear or reverse.
Figures


read the original abstract
Existing facial expression quality assessment (FEQA) methods typically produce only a severity score, without explicitly communicating the observable facial motion evidence that supports the prediction. This limits interpretability and makes it difficult to inspect the basis of model outputs in Parkinson's disease assessment. To address this gap, we propose TraMP-LLaMA, a unified multimodal framework that jointly predicts severity scores and generates structured textual reports from facial motion cues. The framework integrates RGB appearance and landmark trajectory cues, and adopts a decoupled instruction-tuning strategy to reduce task interference between severity prediction and language generation. To support this task, we further extend the PFED5 dataset with expert-guided textual motion descriptions and construct PFED5-plus. Experiments on PFED5-plus show that TraMP-LLaMA outperforms competitive video-language baselines in report generation and achieves the best severity prediction performance among the compared methods under joint multi-expression training, improving Spearman's rank correlation by at least 4.39 percent over all competing methods. The text annotations and code are available at https://github.com/shuchaoduan/TraMP-LLaMA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TraMP-LLaMA, a multimodal framework integrating RGB appearance and landmark trajectory cues for joint severity score prediction and structured textual report generation in facial expression quality assessment. It introduces a decoupled instruction-tuning strategy to mitigate task interference and extends the PFED5 dataset to PFED5-plus with expert-guided motion descriptions. Experiments claim that the model outperforms video-language baselines in report generation and achieves the highest severity prediction performance under joint multi-expression training, with at least a 4.39% improvement in Spearman's rank correlation over competing methods. Code and annotations are released.
Significance. If the empirical gains are robust, the work could advance interpretability in clinical FEQA applications such as Parkinson's assessment by supplying both quantitative scores and human-readable motion evidence. The open release of data and code is a positive contribution to reproducibility in the area.
major comments (1)
- [Abstract] Abstract: The central performance claims (outperformance in report generation and 4.39% Spearman improvement) are stated without reference to the specific baselines, number of expressions, cross-validation protocol, or statistical significance tests. These details are load-bearing for evaluating whether the decoupled tuning strategy drives the gains or whether they arise from dataset extension or training choices.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We agree that the abstract would benefit from greater specificity on experimental details to allow readers to better assess the source of the reported gains. We will revise the abstract to incorporate these elements while preserving conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (outperformance in report generation and 4.39% Spearman improvement) are stated without reference to the specific baselines, number of expressions, cross-validation protocol, or statistical significance tests. These details are load-bearing for evaluating whether the decoupled tuning strategy drives the gains or whether they arise from dataset extension or training choices.
Authors: We acknowledge the referee's point. The current abstract refers to 'competitive video-language baselines' and 'joint multi-expression training' but does not name the baselines or specify the protocol. In the revised version we will explicitly list the main baselines (Video-LLaMA, LLaVA-Video, and the non-decoupled ablation), note that experiments cover the five expressions in PFED5-plus under 5-fold cross-validation, and clarify that the 4.39% figure is the minimum improvement observed across all compared methods. Full protocols, ablation results isolating the decoupled tuning contribution, and any statistical tests appear in Sections 4 and 5; we will add a brief pointer in the abstract. We do not claim statistical significance tests were performed beyond the reported rank correlations, so the revision will not introduce unsupported claims. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical ML contribution: it introduces TraMP-LLaMA, a multimodal model with decoupled instruction tuning, extends the PFED5 dataset to PFED5-plus with textual annotations, and reports experimental results on report generation and severity prediction (Spearman correlation gains). No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All central claims rest on external benchmarks and code release rather than reducing to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A framework to assess clinical safety and hallucination rates of llms for medical text summarisation
Elham Asgari, Nina Montaña Brown, Magda Dubois, Saleh Khalil, Jasmine Balloch, Joshua Au Yeung, and Dominic Pimenta. A framework to assess clinical safety and hallucination rates of llms for medical text summarisation. NPJ Digital Medicine, 8, 2025
2025
-
[2]
Vanni, Gaetano Zaccara, and Claudia Manfredi
Andrea Bandini, Silvia Orlandi, Hugo Jair Escalante, Fabio Giovannelli, Massimo Cin- cotta, Carlos Alberto Reyes-García, P. Vanni, Gaetano Zaccara, and Claudia Manfredi. Analysis of facial expressions in Parkinson’s disease through video-based automatic methods. Journal of Neuroscience Methods, 281:7–20, 2017
2017
-
[3]
A new dataset for facial motion analysis in individuals with neurological disorders.IEEE Journal of Biomedical and Health Informatics, 25(4):1111–1119, 2020
Andrea Bandini, Sia Rezaei, Diego L Guarín, Madhura Kulkarni, Derrick Lim, Mark I Boulos, Lorne Zinman, Yana Yunusova, and Babak Taati. A new dataset for facial motion analysis in individuals with neurological disorders.IEEE Journal of Biomedical and Health Informatics, 25(4):1111–1119, 2020
2020
-
[4]
Face-llava: Facial ex- pression and attribute understanding through instruction tuning
Ashutosh Chaubey, Xulang Guan, and Mohammad Soleymani. Face-llava: Facial ex- pression and attribute understanding through instruction tuning. In IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV), 2026
2026
-
[5]
Finecliper: Multi-modal fine-grained clip for dynamic facial expression recognition with adapters
Haodong Chen, Haojian Huang, Junhao Dong, Mingzhe Zheng, and Dian Shao. Finecliper: Multi-modal fine-grained clip for dynamic facial expression recognition with adapters. In ACM International Conference on Multimedia (MM), 2024
2024
-
[6]
From static to dynamic: Adapting landmark-aware image models for facial expression recognition in videos
Yin Chen, Jia Li, Shiguang Shan, Meng Wang, and Richang Hong. From static to dynamic: Adapting landmark-aware image models for facial expression recognition in videos. IEEE Transactions on Affective Computing, 2024
2024
-
[7]
A deep multi- scale spatiotemporal network for assessing depression from facial dynamics
Wheidima Carneiro De Melo, Eric Granger, and Abdenour Hadid. A deep multi- scale spatiotemporal network for assessing depression from facial dynamics. IEEE transactions on affective computing, 13(3):1581–1592, 2020
2020
-
[8]
Facial expres- sion analysis using decomposed multiscale spatiotemporal networks
Wheidima Carneiro De Melo, Eric Granger, and Miguel Bordallo Lopez. Facial expres- sion analysis using decomposed multiscale spatiotemporal networks. Expert Systems with Applications, 236:121276, 2024
2024
-
[9]
Alab- dulmohsin, Avital Oliver, Piotr Padlewski, Alexey A
Mostafa Dehghani, Basil Mustafa, Josip Djolonga, Jonathan Heek, Matthias Minderer, Mathilde Caron, Andreas Steiner, Joan Puigcerver, Robert Geirhos, Ibrahim M. Alab- dulmohsin, Avital Oliver, Piotr Padlewski, Alexey A. Gritsenko, Mario Luvci’c, and Neil Houlsby. Patch n’ pack: Navit, a vision transformer for any aspect ratio and resolution. Neural Informa...
2023
-
[10]
Skateformer: Skeletal-temporal transformer for human action recognition
Jeonghyeok Do and Munchurl Kim. Skateformer: Skeletal-temporal transformer for human action recognition. In European Conference on Computer Vision (ECCV), 2025
2025
-
[11]
QAFE- Net: Quality assessment of facial expressions with landmark heatmaps
Shuchao Duan, Amirhossein Dadashzadeh, Alan Whone, and Majid Mirmehdi. QAFE- Net: Quality assessment of facial expressions with landmark heatmaps. In ELFA Workshop at W ACV2024, volume abs/2312.00856, 2024
arXiv 2024
-
[12]
Trajectory-guided motion perception for facial expression quality assessment in neu- rological disorders
Shuchao Duan, Amirhossein Dadashzadeh, Alan Whone, and Majid Mirmehdi. Trajectory-guided motion perception for facial expression quality assessment in neu- rological disorders. In IEEE international conference on automatic face and gesture recognition (FG), 2025
2025
-
[13]
EmoCLIP: A Vision-Language Method for Zero-Shot Video Facial Expression Recognition
Niki Maria Foteinopoulou and Ioannis Patras. EmoCLIP: A Vision-Language Method for Zero-Shot Video Facial Expression Recognition. In IEEE 18th International Conference on Automatic Face and Gesture Recognition (FG), 2024
2024
-
[14]
Goetz, Barbara C Tilley, Stephanie R
Christopher G. Goetz, Barbara C Tilley, Stephanie R. Shaftman, Glenn T. Stebbins, Stanley Fahn, Pablo Martínez-Martín, Werner Poewe, Cristina Sampaio, Matthew B. Stern, Richard Dodel, Bruno Dubois, Robert G. Holloway, Joseph Jankovic, Jaime Kulisevsky, Anthony E. Lang, Andrew John Lees, Sue E. Leurgans, Peter LeWitt, David Nyenhuis, C. Warren Olanow, Oliv...
2008
-
[15]
Detecting hypomimia symptoms by selfie photo analysis: for early Parkin- son disease detection
Athina Grammatikopoulou, Nikolaos Grammalidis, Sevasti Bostantjopoulou, and Zoe Katsarou. Detecting hypomimia symptoms by selfie photo analysis: for early Parkin- son disease detection. In ACM International Conference on PErvasive Technologies Related to Assistive Environments (PETRA), 2019
2019
-
[16]
Sample and computation redistribution for efficient face detection
Jia Guo, Jiankang Deng, Alexandros Lattas, and Stefanos Zafeiriou. Sample and computation redistribution for efficient face detection. In International Conference on Learning Representations (ICLR), 2022
2022
-
[17]
Motionbench: Benchmarking and improv- ing fine-grained video motion understanding for vision language models
Wenyi Hong, Yean Cheng, Zhuoyi Yang, Weihan Wang, Lefan Wang, Xiaotao Gu, Shiyu Huang, Yuxiao Dong, and Jie Tang. Motionbench: Benchmarking and improv- ing fine-grained video motion understanding for vision language models. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[18]
Detecting depression based on facial cues elicited by emotional stimuli in video
Bin Hu, Yongfeng Tao, and Minqiang Yang. Detecting depression based on facial cues elicited by emotional stimuli in video. Computers in Biology and Medicine, 165: 107457, 2023
2023
-
[19]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. International Conference on Learning Representations (ICLR), 2021
2021
-
[20]
Kiut: Knowledge-injected u-transformer for radiology report generation
Zhongzhen Huang, Xiaofan Zhang, and Shaoting Zhang. Kiut: Knowledge-injected u-transformer for radiology report generation. In IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2023. DUAN ET AL.: GENERA TIVE INTERPRETABILITY FOR FEQA17
2023
-
[21]
Clinical score estimation for determining oro-facial dysfunction severity
Trassandra Jewelle Ipapo, Charlize Del Rosario, Patricia Angela Abu, and Raphael Alampay. Clinical score estimation for determining oro-facial dysfunction severity. In International Conference on Robotics, Control and Vision Engineering (RCVE), 2023
2023
-
[22]
DFEW: A large-scale database for recognizing dynamic facial expressions in the wild
Xingxun Jiang, Yuan Zong, Wenming Zheng, Chuangao Tang, Wanchuang Xia, Cheng Lu, and Jiateng Liu. DFEW: A large-scale database for recognizing dynamic facial expressions in the wild. In ACM International Conference on Multimedia (MM), 2020
2020
-
[23]
Diagnosing Parkinson disease through facial expression recognition: Video analysis
Bo Jin, Yue Qu, Liang Zhang, and Zhan Gao. Diagnosing Parkinson disease through facial expression recognition: Video analysis. Journal of Medical Internet Research, 22, 2020
2020
-
[24]
Chat-univi: Unified visual representation empowers large language models with image and video understanding
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[25]
Mvbench: A comprehensive multi-modal video un- derstanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video un- derstanding benchmark. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[26]
Tsffm: Depression detection based on latent association of facial and body expressions
Xingyun Li, Xinyu Yi, Lin Lu, Hao Wang, Yunshao Zheng, Mengmeng Han, and Qingxiang Wang. Tsffm: Depression detection based on latent association of facial and body expressions. Computers in Biology and Medicine, 168:107805, 2024
2024
-
[27]
Facial affective behavior analysis with instruction tuning
Yifan Li, Anh Dao, Wentao Bao, Zhen Tan, Tianlong Chen, Huan Liu, and Yu Kong. Facial affective behavior analysis with instruction tuning. ArXiv, abs/2404.05052, 2024
arXiv 2024
-
[28]
Sequence-level affective level estimation based on pyramidal facial expression features
Jiacheng Liao, Yan Hao, Zhuoyi Zhou, Jiahui Pan, and Yan Liang. Sequence-level affective level estimation based on pyramidal facial expression features. Pattern Recognition, 145:109958, 2024
2024
-
[29]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Annual Meeting of the Association for Computational Linguistics (ACL), 2004
2004
-
[30]
Hierarchical global and local transformer for pain estimation with facial expression videos
Hongrui Liu, Haochen Xu, Jinheng Qiu, Shizhe Wu, and Manhua Liu. Hierarchical global and local transformer for pain estimation with facial expression videos. Pattern Analysis and Applications, 27(3):85, 2024
2024
-
[31]
Mafw: A large-scale, multi-modal, compound affective database for dynamic facial expression recognition in the wild
Yuanyuan Liu, Wei Dai, Chuanxu Feng, Wenbin Wang, Guanghao Yin, Jiabei Zeng, and Shiguang Shan. Mafw: A large-scale, multi-modal, compound affective database for dynamic facial expression recognition in the wild. In ACM International Conference on Multimedia (MM), 2022
2022
-
[32]
Pra- net: Part-and-relation attention network for depression recognition from facial expres- sion
Zhenyu Liu, Xiaoyan Yuan, Yutong Li, Zixuan Shangguan, Li Zhou, and Bin Hu. Pra- net: Part-and-relation attention network for depression recognition from facial expres- sion. Computers in biology and medicine, 157:106589, 2023. 18DUAN ET AL.: GENERA TIVE INTERPRETABILITY FOR FEQA
2023
-
[33]
Cohn, Kenneth M
Patrick Lucey, Jeffrey F. Cohn, Kenneth M. Prkachin, Patricia E. Solomon, and I. Matthews. Painful data: The UNBC-McMaster shoulder pain expression archive database. In IEEE International Conference on Automatic Face & Gesture Recognition (FG), 2011
2011
-
[34]
Khan, and Fahad Shahbaz Khan
Muhammad Maaz, Hanoona Abdul Rasheed, Salman H. Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and lan- guage models. In Annual Meeting of the Association for Computational Linguistics (ACL), 2023
2023
-
[35]
Explainable depression detection based on facial expression using lstm on atten- tional intermediate feature fusion with label smoothing
Yanisa Mahayossanunt, Natawut Nupairoj, Solaphat Hemrungrojn, and Peerapon Va- teekul. Explainable depression detection based on facial expression using lstm on atten- tional intermediate feature fusion with label smoothing. Sensors, 23(23):9402, 2023
2023
-
[36]
Ershova, and Ekaterina Yu
Anastasia Moshkova, Andrey Samorodov, Ekaterina Ivanova, Margarita V . Ershova, and Ekaterina Yu. Fedotova. Assessment of Parkinson’s disease severity based on au- tomatic analysis of facial expressions and motor activity of the hands. In International Conference on Biomedical Electronics and Devices (BIODEVICES), 2022
2022
-
[37]
Rajendra Acharya, and Kwok-Leung Tsui
Elham Nasarian, Roohallah Alizadehsani, U. Rajendra Acharya, and Kwok-Leung Tsui. Designing interpretable ml system to enhance trust in healthcare: A system- atic review to proposed responsible clinician-ai-collaboration framework. Information Fusion, 108:102412, 2023
2023
-
[38]
Image captioning using facial expression and attention
Omid Mohamad Nezami, Mark Dras, Stephen Wan, and Cécile Paris. Image captioning using facial expression and attention. Journal of Artificial Intelligence Research, 68: 661–689, 2019
2019
-
[39]
Video assessment to detect amyotrophic lateral sclerosis
Guilherme Camargo Oliveira, Quoc Cuong Ngo, Leandro Aparecido Passos, Leonardo Silva Oliveira, Stella Stylianou, João Paulo Papa, and Dinesh Kumar. Video assessment to detect amyotrophic lateral sclerosis. Digital Biomarkers, 8(1):171–180, 2024
2024
-
[40]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Annual Meeting of the Association for Computational Linguistics (ACL), 2002
2002
-
[41]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. International Conference for High Performance Computing, Networking, Storage and Analysis (SC), 2020
2020
-
[42]
Towards identification of hypomimia in Parkinson’s disease based on face recognition methods
Martin Rajnoha, Jirí Mekyska, Radim Burget, Ilona Eliasova, Milena Kostalova, and Irena Rektorová. Towards identification of hypomimia in Parkinson’s disease based on face recognition methods. In International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), 2018
2018
-
[43]
Early-stage parkinson’s disease detection based on opti- cal flow and video vision transformer
Anas Filali Razzouki, Laetitia Jeancolas, Graziella Mangone, Sara Sambin, Alizé Cha- lançon, Manon Gomes, Stéphane Lehéricy, Jean-Christophe Corvol, Marie Vidail- het, Isabelle Arnulf, et al. Early-stage parkinson’s disease detection based on opti- cal flow and video vision transformer. In International Conference on Human System Interaction (HSI), 2024. ...
2024
-
[44]
why should i trust you?
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “why should i trust you?”: Explaining the predictions of any classifier. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), 2016
2016
-
[45]
Selvaraju, Abhishek Das, Ramakrishna Vedantam, Michael Cogswell, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju, Abhishek Das, Ramakrishna Vedantam, Michael Cogswell, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. International Journal of Computer Vision, 128:336 – 359, 2016
2016
-
[46]
Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra
Xiaoqian Shen, Yunyang Xiong, Changsheng Zhao, Lemeng Wu, Jun Chen, Chenchen Zhu, Zechun Liu, Fanyi Xiao, Bala Varadarajan, Florian Bordes, Zhuang Liu, Hu Xu, Hyunwoo J. Kim, Bilge Soran, Raghuraman Krishnamoorthi, Mohamed Elhoseiny, and Vikas Chandra. Longvu: Spatiotemporal adaptive compression for long video- language understanding. International Confer...
2025
-
[47]
Automated radiology report generation: A review of recent advances.IEEE Reviews in Biomedical Engineering, 18:368–387, 2024
Phillip Sloan, Philip Clatworthy, Edwin Simpson, and Majid Mirmehdi. Automated radiology report generation: A review of recent advances.IEEE Reviews in Biomedical Engineering, 18:368–387, 2024
2024
-
[48]
Bimbo, and Zakia Hammal
Benjamin Szczapa, Mohamed Daoudi, Stefano Berretti, Pietro Pala, A. Bimbo, and Zakia Hammal. Automatic estimation of self-reported pain by trajectory analysis in the manifold of fixed rank positive semi-definite matrices.IEEE Transactions on Affective Computing, 13:1813–1826, 2022
2022
-
[49]
Uncertainty-aware score distribution learning for action quality assessment
Yansong Tang, Zanlin Ni, Jiahuan Zhou, Danyang Zhang, Jiwen Lu, Ying Wu, and Jie Zhou. Uncertainty-aware score distribution learning for action quality assessment. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[50]
Two-stream attention net- work for pain recognition from video sequences
Patrick Thiam, Hans A Kestler, and Friedhelm Schwenker. Two-stream attention net- work for pain recognition from video sequences. Sensors, 20(3):839, 2020
2020
-
[51]
Distance Ordering: A deep supervised metric learning for pain intensity estimation
Jie Ting, Yi-Cheng Yang, Li-Chen Fu, Chu-Lin Tsai, and Chien-Hua Huang. Distance Ordering: A deep supervised metric learning for pain intensity estimation. In IEEE International Conference on Machine Learning and Applications (ICMLA), 2021
2021
-
[52]
Lawrence Zitnick, and Devi Parikh
Ramakrishna Vedantam, C. Lawrence Zitnick, and Devi Parikh. Cider: Consensus- based image description evaluation. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015
2015
-
[53]
Diagnostic captioning by coop- erative task interactions and sample-graph consistency
Zhanyu Wang, Lei Wang, Xiu Li, and Luping Zhou. Diagnostic captioning by coop- erative task interactions and sample-graph consistency. IEEE Transactions on Pattern Analysis and Machine Intelligence, 47:6585–6598, 2025
2025
-
[54]
Global-local combined features to detect pain intensity from facial expression images with attention mechanism1.Journal of Electronic Science and Technology, page 100260, 2024
Jiang Wu, Yi Shi, Shun Yan, and Hong-mei Yan. Global-local combined features to detect pain intensity from facial expression images with attention mechanism1.Journal of Electronic Science and Technology, page 100260, 2024
2024
-
[55]
Emovit: Revolutionizing emotion insights with visual instruction tuning
Hongxia Xie, Chu-Jun Peng, Yu-Wen Tseng, Hung-Jen Chen, Chan-Feng Hsu, Hong- Han Shuai, and Wen-Huang Cheng. Emovit: Revolutionizing emotion insights with visual instruction tuning. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 20DUAN ET AL.: GENERA TIVE INTERPRETABILITY FOR FEQA
2024
-
[56]
Xiaojing Xu and Virginia R. de Sa. Exploring multidimensional measurements for pain evaluation using facial action units. In IEEE International Conference on Automatic Face and Gesture Recognition (FG), 2020
2020
-
[57]
Qwen An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxin Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin,...
Pith/arXiv arXiv 2024
-
[58]
Describe your facial expressions by link- ing image encoders and large language models
Yujian Yuan, Jiabei Zeng, and Shiguang Shan. Describe your facial expressions by link- ing image encoders and large language models. In British Machine Vision Conference (BMVC), 2023
2023
-
[59]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[60]
Videollama 3: Frontier multi- modal foundation models for image and video understanding
Boqiang Zhang, Kehan Li, Zesen Cheng, Zhiqiang Hu, Yuqian Yuan, Guanzheng Chen, Sicong Leng, Yuming Jiang, Hang Zhang, Xin Li, et al. Videollama 3: Frontier multi- modal foundation models for image and video understanding. arXiv, abs/2501.13106, 2025
Pith/arXiv arXiv 2025
-
[61]
Video-llama: An instruction-tuned audio- visual language model for video understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio- visual language model for video understanding. In Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[62]
A generalist vision–language foun- dation model for diverse biomedical tasks
Kai Zhang, Rong Zhou, Eashan Adhikarla, Zhiling Yan, Yixin Liu, Jun Yu, Zhengliang Liu, Xun Chen, Brian D Davison, Hui Ren, et al. A generalist vision–language foun- dation model for diverse biomedical tasks. Nature Medicine, 30(11):3129–3141, 2024
2024
-
[63]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. International Conference on Learning Representations (ICLR), 2020
2020
-
[64]
LLaV A-video: Video instruction tuning with synthetic data
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun MA, Ziwei Liu, and Chunyuan Li. LLaV A-video: Video instruction tuning with synthetic data. Transactions on Machine Learning Research, 2025. ISSN 2835-8856
2025
-
[65]
Former-DFER: Dynamic facial expression recogni- tion transformer
Zengqun Zhao and Qingshan Liu. Former-DFER: Dynamic facial expression recogni- tion transformer. In ACM International Conference on Multimedia (MM), 2021
2021
-
[66]
Enhancing zero-shot facial expression recognition by llm knowledge transfer.IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV), 2025
Zengqun Zhao, Yu Cao, Shaogang Gong, and Ioannis Patras. Enhancing zero-shot facial expression recognition by llm knowledge transfer.IEEE/CVF Winter Conference on Applications of Computer Vision (W ACV), 2025
2025
-
[67]
Cofinal: Enhancing action quality assessment with coarse-to-fine instruction alignment
Kanglei Zhou, Junlin Li, Ruizhi Cai, Liyuan Wang, Xingxing Zhang, and Xiaohui Liang. Cofinal: Enhancing action quality assessment with coarse-to-fine instruction alignment. In International Joint Conference on Artificial Intelligence (IJCAI), 2024. DUAN ET AL.: GENERA TIVE INTERPRETABILITY FOR FEQA21
2024
-
[68]
Visually inter- pretable representation learning for depression recognition from facial images
Xiuzhuang Zhou, Kai Jin, Yuanyuan Shang, and Guodong Guo. Visually inter- pretable representation learning for depression recognition from facial images. IEEE transactions on affective computing, 11(3):542–552, 2018. Supplementary Materials This supplementary materials provides additional details on the text annotations in the PFED5+ dataset, including th...
2018
-
[69]
Do not add any new observations or infer any hidden states (e.g., intent, affect, diagnosis)
-
[70]
Do not remove any information about facial details (eyebrows, eyelids, cheeks, mouth corners, mouth)
-
[71]
During this time,
Keep the same template structure. - For ‘sit at rest’, keep the format: “During this time, ...” - For action clips (‘smile’, ‘frown’, ‘squeeze eyes’, ‘clench teeth’), keep the format: “Prior to the onset of the action, ... During the action, ... Following the completion of the action, ...”
-
[72]
You may rephrase only for fluency and redundancy reduction
Preserve all evidence statements in meaning. You may rephrase only for fluency and redundancy reduction
-
[73]
Output a single fluent paragraph. 24DUAN ET AL.: GENERA TIVE INTERPRETABILITY FOR FEQA C Description Instructions C.1 Instruction Diversification and Usage To reduce prompt sensitivity and improve robustness to instruction phrasing, we use an in- struction diversification strategy during training. We prepare two instruction pools corre- sponding to the tw...
-
[74]
(Base Instruction)
Provide a brief, objective summary of the person’s facial state and minor visible move- ments, focusing on the eyebrows, eyelids, cheeks, mouth corner, and mouth, and not- ing any additional details such as blinking, chin states, gaze shifts, or wrinkle changes. (Base Instruction)
-
[75]
Describe the person’s facial appearance in a concise and neutral way, emphasizing the state of the eyebrows, eyelids, cheeks, mouth corners, and mouth, and include any subtle motions such as blinking, gaze direction, or wrinkle changes
-
[76]
Give a short, factual account of the person’s facial expression and any slight move- ments, mentioning the eyebrows, eyelids, cheeks, corners of the mouth, and mouth, as well as other minor cues like blinking or shifts in gaze
-
[77]
Summarize briefly and objectively how the person’s face appears, focusing on the position and tension of the eyebrows, eyelids, cheeks, and mouth region, and note if there are tiny movements such as blinks or eye direction changes
-
[78]
Provide an objective and succinct description of the person’s facial condition, pay- ing attention to the eyebrows, eyelids, cheeks, mouth corners, and mouth, and add observations on any minute actions like blinking or wrinkle variations
-
[79]
DUAN ET AL.: GENERA TIVE INTERPRETABILITY FOR FEQA25
Write a concise summary of the face’s current state, concentrating on the eyebrows, eyelids, cheeks, and mouth area, and point out any subtle visible movements such as a blink or a change in gaze. DUAN ET AL.: GENERA TIVE INTERPRETABILITY FOR FEQA25
-
[80]
Offer a neutral, compact description of how the person’s facial features appear, fo- cusing on key areas-the eyebrows, eyelids, cheeks, and mouth-and mention minor activities like blinking or muscle twitches if visible
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.