Unison: Benchmarking Unified Multimodal Models via Synergistic Understanding and Generation
Pith reviewed 2026-06-26 05:14 UTC · model grok-4.3
The pith
Unison benchmark shows unified multimodal models lack synergy between understanding and generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
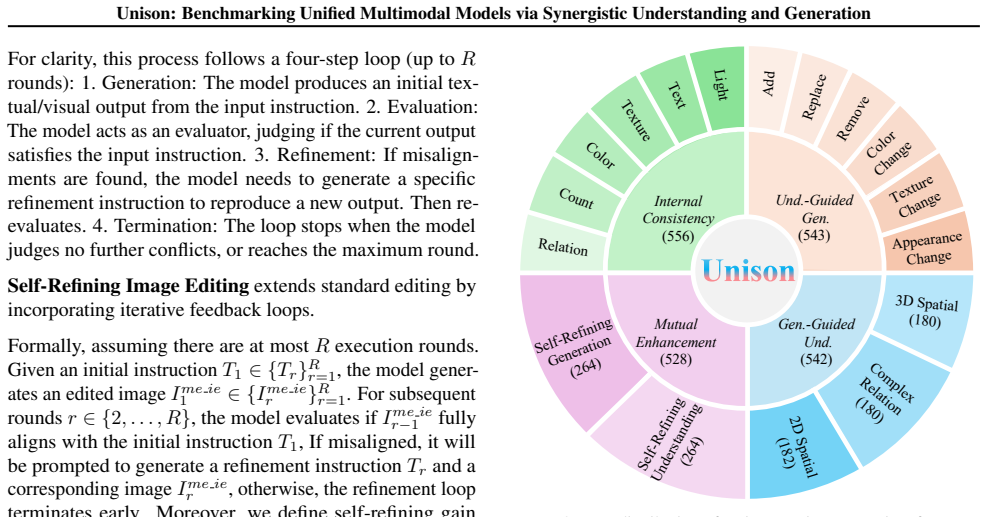
Unison is a benchmark with 2,169 high-quality unified task samples that evaluates joint understanding and generation through the dimensions of internal consistency, understanding-guided generation, generation-guided understanding, and mutual enhancement; it supplies both unified and decoupled tracks to attribute failure modes and measure gains from unified modeling, plus an Unison-Judge model aligned with human judgments, and systematic tests on current models uncover critical limitations in existing unified multimodal systems.
What carries the argument
Unison benchmark with its four synergy dimensions and unified versus decoupled evaluation tracks.
If this is right
- Failure modes can be traced to specific gaps such as missing internal consistency or weak cross-task guidance.
- Quantified gains from unified modeling can guide decisions on whether to train models jointly or separately.
- Models must improve mutual enhancement to handle tasks that require understanding to shape generation and vice versa.
- Future designs should target the uncovered limitations rather than scaling isolated capabilities.
Where Pith is reading between the lines
- Models trained to close the gaps identified by Unison could support more fluid interactive uses such as editing an image after understanding its content from a description.
- The decoupled-track approach could be adapted to measure synergy in other combined capabilities like reasoning plus planning.
- Widespread adoption might shift training objectives toward explicit optimization of understanding-generation feedback loops.
Load-bearing premise
The 2,169 samples and Unison-Judge model give a representative, human-aligned measure of synergy.
What would settle it
If human raters consistently disagree with Unison-Judge scores on the same model outputs, or if models show no measurable gain on synergistic tasks compared with separate understanding and generation tests.
Figures


read the original abstract
Unified multimodal models capable of both understanding and generation have achieved remarkable strides. However, despite their unified designs, existing evaluations typically assess understanding and generation capabilities in isolation, overlooking the synergy between comprehension and generation. To bridge this gap, we introduce Unison, a comprehensive benchmark comprising 2,169 high-quality unified task samples, designed to evaluate joint understanding and generation in unified multimodal models. Unison offers three key strengths: 1) Comprehensive Dimensions: Unison encompasses internal consistency, understanding-guided generation, generation-guided understanding, and mutual enhancement to enable holistic evaluation. 2) Diagnostic Evaluation: it provides both unified and decoupled tracks for understanding and generation, allowing fine-grained attribution of failure modes and quantitative analysis of the gains from unified modeling. 3) Human Alignment: we also introduce Unison-Judge, an evaluation model well aligned with human judgments to ensure reliable assessment. Based on systematic evaluations of state-of-the-art models on Unison, we uncover critical limitations in current unified multimodal systems and highlight promising directions for future research. Codes, Unison and Unison-Judge are publicly available at https://github.com/FudanCVL/Unison.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Unison, a benchmark of 2,169 high-quality unified task samples for evaluating synergistic understanding and generation in unified multimodal models. It defines four evaluation dimensions (internal consistency, understanding-guided generation, generation-guided understanding, mutual enhancement), supplies both unified and decoupled tracks, and releases Unison-Judge (an evaluation model claimed to align with human judgments). Systematic evaluations on SOTA models are said to reveal critical limitations and suggest future directions; code, data, and judge are released publicly.
Significance. If the sample curation and judge validation procedures prove sound, Unison would address a genuine gap: existing benchmarks evaluate understanding and generation in isolation and therefore cannot quantify synergy or attribute failure modes to unified modeling. Public release of the benchmark and judge would be a concrete contribution to the field.
major comments (3)
- [Abstract / §3] Abstract and benchmark-construction section: the manuscript asserts that the 2,169 samples are “high-quality” and representative for measuring synergy, yet supplies no selection criteria, source-dataset breakdown, difficulty stratification, exclusion rules, or inter-annotator statistics. Because these samples constitute the sole empirical basis for the claim of “critical limitations in current unified multimodal systems,” the absence of curation documentation makes the diagnostic results untestable.
- [Abstract / §4] Abstract and Unison-Judge section: the claim that Unison-Judge is “well aligned with human judgments” is load-bearing for all reported scores, but no training data, human-correlation metrics (e.g., Pearson/Spearman), inter-rater agreement, or calibration-set size are provided. Without these, it is impossible to distinguish model weaknesses from judge miscalibration.
- [§5] Evaluation section: the paper reports that unified modeling yields gains on the mutual-enhancement track, yet the decoupled-track baselines and the exact quantitative attribution of those gains are not shown with sufficient controls (e.g., matched model capacity, identical training data). This weakens the central claim that the benchmark isolates synergy effects.
minor comments (2)
- [Abstract] The GitHub repository link is given but the manuscript does not state the exact commit or data-split files that correspond to the 2,169 samples used in the reported experiments.
- [§2] Notation for the four synergy dimensions is introduced without a compact table summarizing the input/output modalities and scoring protocol for each dimension.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important areas for improving transparency and rigor. We address each major comment below and commit to revisions that strengthen the manuscript without misrepresenting our current work.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and benchmark-construction section: the manuscript asserts that the 2,169 samples are “high-quality” and representative for measuring synergy, yet supplies no selection criteria, source-dataset breakdown, difficulty stratification, exclusion rules, or inter-annotator statistics. Because these samples constitute the sole empirical basis for the claim of “critical limitations in current unified multimodal systems,” the absence of curation documentation makes the diagnostic results untestable.
Authors: We acknowledge that the current manuscript provides insufficient documentation on the curation process. In the revised version, we will expand §3 with a dedicated subsection detailing the sample selection criteria, source-dataset breakdown, difficulty stratification, exclusion rules, and inter-annotator statistics to enhance reproducibility and testability of the results. revision: yes
-
Referee: [Abstract / §4] Abstract and Unison-Judge section: the claim that Unison-Judge is “well aligned with human judgments” is load-bearing for all reported scores, but no training data, human-correlation metrics (e.g., Pearson/Spearman), inter-rater agreement, or calibration-set size are provided. Without these, it is impossible to distinguish model weaknesses from judge miscalibration.
Authors: We agree that the validation details for Unison-Judge must be provided to support the alignment claim. The revised manuscript will include the training data description, human-correlation metrics (Pearson and Spearman), inter-rater agreement, and calibration-set size in the Unison-Judge section. revision: yes
-
Referee: [§5] Evaluation section: the paper reports that unified modeling yields gains on the mutual-enhancement track, yet the decoupled-track baselines and the exact quantitative attribution of those gains are not shown with sufficient controls (e.g., matched model capacity, identical training data). This weakens the central claim that the benchmark isolates synergy effects.
Authors: We will revise §5 to include more explicit controls in the decoupled-track baselines, such as matched model capacity and training data where feasible, along with clearer quantitative attribution of gains from unified modeling to better isolate synergy effects. revision: yes
Circularity Check
No significant circularity in benchmark construction
full rationale
The paper constructs a benchmark (2,169 samples, Unison-Judge) and defines evaluation dimensions without any equations, parameter fitting, or derivation chain. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear. Claims of human alignment and sample quality are assertions about new artifacts rather than reductions to prior inputs; the work is self-contained as benchmark design with no internal circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 2,169 samples adequately cover the space of synergistic understanding-generation interactions.
- domain assumption Unison-Judge provides reliable scores aligned with human judgment.
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y ., Tan...
-
[2]
V ., Khedr, H., Huang, A., et al
Carion, N., Gustafson, L., Hu, Y .-T., Debnath, S., Hu, R., Suris, D., Ryali, C., Alwala, K. V ., Khedr, H., Huang, A., et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719,
-
[3]
Chen, J., Xu, Z., Pan, X., Hu, Y ., Qin, C., Goldstein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025a. Chen, X., Fang, H., Lin, T.-Y ., Vedantam, R., Gupta, S., Doll´ar, P., and Zitnick, C. L. Microsoft coco captions...
-
[4]
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., and Ruan, C. Janus-pro: Unified multimodal understand- ing and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025b. Cho, J., Hu, Y ., Garg, R., Anderson, P., Krishna, R., Baldridge, J., Bansal, M., Pont-Tuset, J., and Wang, S. Davidsonian scene graph: Improving reliabi...
-
[5]
Emerg- ing properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., Shi, G., and Fan, H. Emerg- ing properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683,
-
[6]
Seed-x: Multimodal models with unified multi-granularity comprehension and generation
Ge, Y ., Zhao, S., Zhu, J., Ge, Y ., Yi, K., Song, L., Li, C., Ding, X., and Shan, Y . Seed-x: Multimodal models with unified multi-granularity comprehension and generation. arXiv preprint arXiv:2404.14396,
-
[7]
Geng, Z., Wang, Y ., Ma, Y ., Li, C., Rao, Y ., Gu, S., Zhong, Z., Lu, Q., Hu, H., Zhang, X., et al. X-omni: Reinforcement learning makes discrete autoregressive image generative models great again.arXiv preprint arXiv:2507.22058,
-
[8]
Hu, X., Wang, R., Fang, Y ., Fu, B., Cheng, P., and Yu, G. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135,
-
[9]
Huang, R., Wang, C., Yang, J., Lu, G., Yuan, Y ., Han, J., Hou, L., Zhang, W., Hong, L., Zhao, H., et al. Illume+: Il- luminating unified mllm with dual visual tokenization and diffusion refinement.arXiv preprint arXiv:2504.01934,
-
[10]
Li, Y ., Qian, R., Pan, B., Zhang, H., Huang, H., Zhang, B., Tong, J., You, H., Du, X., Gan, Z., Kim, H., Jia, C., Wang, Z., Yang, Y ., Gao, M., Dou, Z.-Y ., Hu, W., Gao, C., Li, D., Dufter, P., Wang, Z., Yin, G., Zhang, Z., Chen, C., Zhao, Y ., Pang, R., and Chen, Z. Manzano: A simple and scalable unified multimodal model with a hybrid vision tokenizer.a...
-
[11]
M., Hauth, A., Millican, K., et al
Team, G., Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Sori- cut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
-
[12]
Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.-m., Bai, S., Xu, X., Chen, Y ., et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025a. Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y ., Li, W., Jiang, X., Liu, Y ., Zhou, J., et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.188...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.