Adaptive Utility driven Resource Orchestration for Resilient AI (AURORA-AI)
Pith reviewed 2026-06-26 04:41 UTC · model grok-4.3
The pith
AURORA-AI recovers immediately from black-swan disruptions by reallocating compute via a closed-loop policy that jointly tracks performance, fairness, and stability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
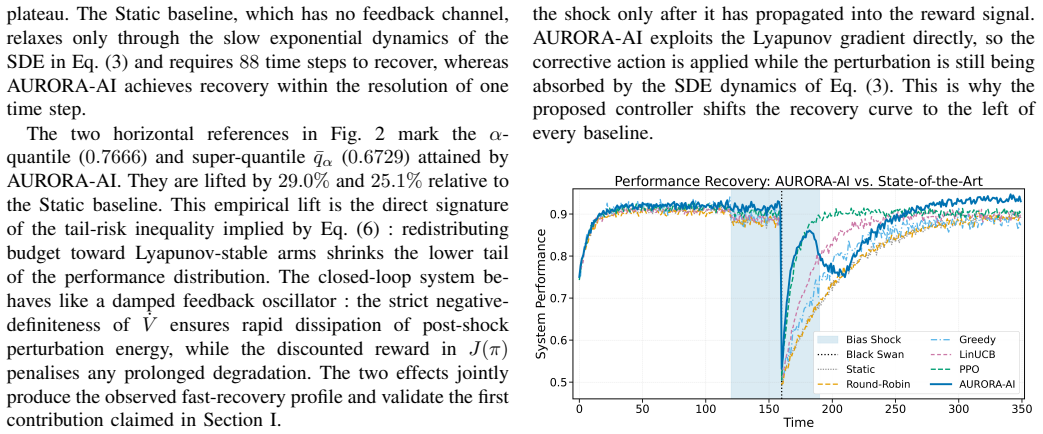
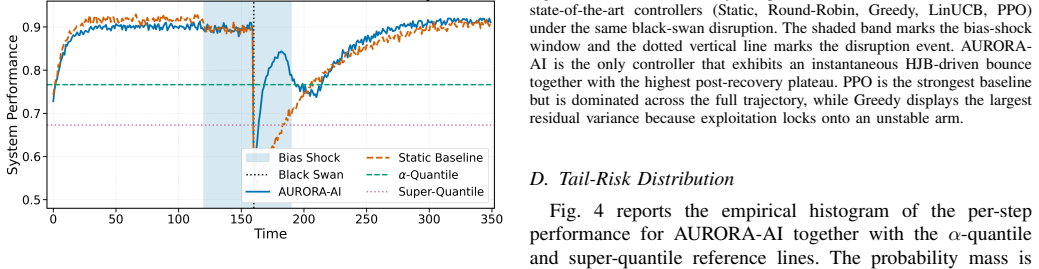
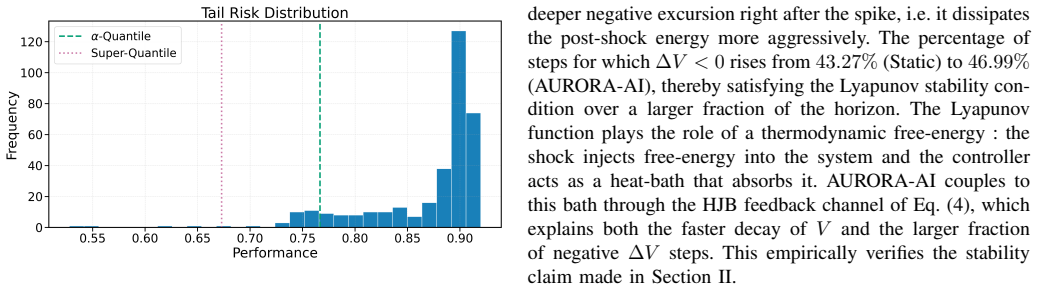
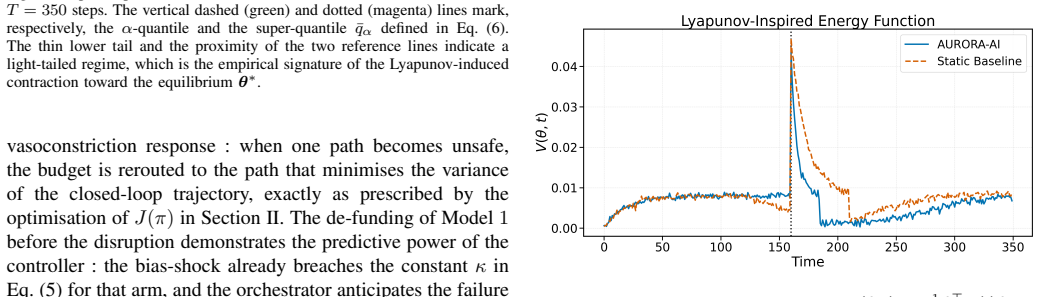
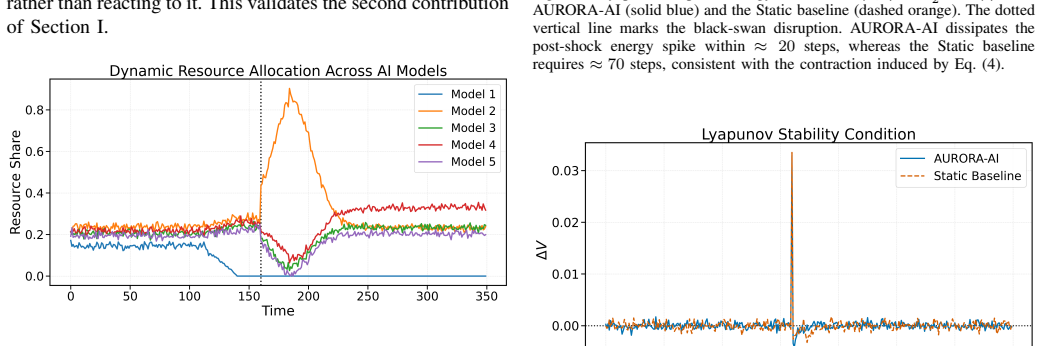
AURORA-AI unifies Hamilton-Jacobi-Bellman feedback control, Lyapunov-based stability monitoring, and a fairness-aware composite utility into a single closed-loop policy. The policy continuously redistributes computational budget across a population of heterogeneous AI models so that the global utility remains maximised under disruption. In a discrete-time simulation that injects demographic bias shocks, gradual concept drift, and abrupt black-swan disruptions, AURORA-AI achieves immediate recovery from the black-swan event, lifts the alpha-quantile and super-quantile by twenty-nine and twenty-five percent, reduces mean and maximum demographic parity gap, and increases the fraction of Lyapuno
What carries the argument
The closed-loop policy that integrates Hamilton-Jacobi-Bellman feedback control, Lyapunov stability monitoring, and a composite utility defined jointly over predictive performance, demographic parity, cost, latency, robustness, and interpretability.
If this is right
- Immediate recovery from abrupt black-swan events rather than delayed recovery seen in static and reinforcement-learning baselines.
- Higher alpha-quantile and super-quantile values of the global utility metric.
- Simultaneous reduction in both mean and maximum demographic parity gap across models.
- Larger fraction of operating steps that satisfy Lyapunov stability criteria.
Where Pith is reading between the lines
- The same control structure could be tested on continuous-time or hardware-in-the-loop platforms to check whether the discrete-time gains translate.
- The fairness term inside the composite utility might be replaced by other human-centric metrics such as explainability scores without changing the overall architecture.
- The approach suggests a route for embedding stability guarantees directly into multi-objective resource managers used by cloud AI platforms.
Load-bearing premise
The discrete-time simulation that injects demographic bias shocks, gradual concept drift, and abrupt black-swan disruptions faithfully represents the non-stationary conditions the framework would face in real deployments.
What would settle it
Running AURORA-AI on a live multi-model serving system that experiences an unannounced sudden change in data distribution or compute availability and recording whether recovery occurs in zero time steps while the baselines take many steps.
Figures

read the original abstract
Modern AI systems are increasingly deployed under non-stationary computational, demographic, and operational conditions in which static resource allocation strategies degrade both predictive performance and human-centric properties such as fairness and explainability. This paper presents AURORA-AI, an Adaptive Utility-driven Resource Orchestration framework for Resilient AI that unifies Hamilton-Jacobi-Bellman feedback control, Lyapunov-based stability monitoring, and a fairness-aware composite utility into a single closed-loop policy.The framework continuously redistributes computational budget across a population of heterogeneous AI models so that the global utility, defined jointly over predictive performance, demographic parity, cost, latency, robustness, and interpretability, remains maximised under disruption. The framework is evaluated in a stress-rich discrete-time simulation that concurrently injects demographic bias shocks, gradual concept drift, and abrupt black-swan disruptions, and is compared against five established controllers including Static, Round Robin, Greedy, LinUCB, and a deep reinforcement-learning agent based on Proximal Policy Optimisation. AURORA-AI achieves immediate recovery from the black-swan event compared to eighty-eight time steps for the Static baseline and twenty-two for Proximal Policy Optimisation, lifts the alpha-quantile and the super-quantile by twenty-nine and twenty-five percent respectively, simultaneously reduces the mean and maximum demographic parity gap, and increases the fraction of Lyapunov-stable operating steps. These results indicate that fairness-aware adaptive orchestration grounded in stability theory is a practical and theoretically motivated path toward resilient human-centric AI deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AURORA-AI, a closed-loop framework that combines Hamilton-Jacobi-Bellman feedback control, Lyapunov stability monitoring, and a fairness-aware composite utility (over predictive performance, demographic parity, cost, latency, robustness, and interpretability) to dynamically reallocate compute across heterogeneous AI models under non-stationary conditions. It is evaluated in a single discrete-time simulation that injects demographic bias shocks, concept drift, and black-swan events, and claims immediate recovery (vs. 88/22 steps for Static/PPO baselines), 29%/25% lifts in alpha- and super-quantiles, simultaneous reduction in mean/max demographic parity gap, and higher fraction of Lyapunov-stable steps compared to five baselines.
Significance. If the simulation were shown to be representative of real non-stationary deployments, the integration of optimal control, stability theory, and multi-objective fairness into a single orchestration policy would be a notable contribution to resilient human-centric AI. The explicit use of Lyapunov monitoring and the attempt at a composite utility are strengths that could be built upon, but the current evidence base does not yet support the claim of a 'practical path' to deployment.
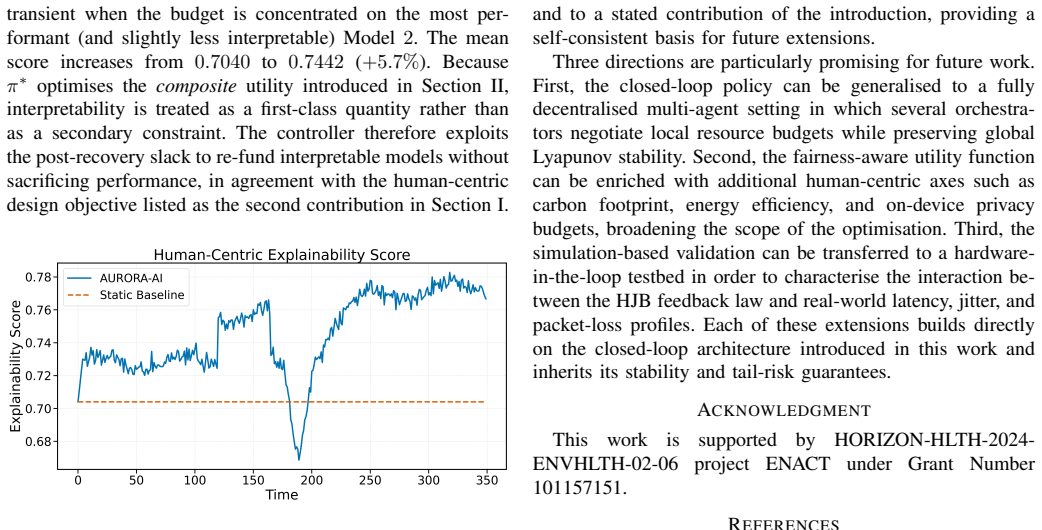
major comments (3)
- [Evaluation] Evaluation section (performance claims paragraph): all quantitative results (immediate black-swan recovery, 29%/25% quantile lifts, parity-gap reductions, Lyapunov-stable fraction) derive from one unreproduced discrete-time simulation whose exact state-transition model, shock magnitudes/timings, exclusion rules, and parameter values are not reported; no error bars, statistical tests, or sensitivity sweeps appear, so the central empirical claim cannot be assessed for robustness.
- [Framework] Framework description (utility definition): the global utility is stated to be 'defined jointly over predictive performance, demographic parity, cost, latency, robustness, and interpretability,' yet no explicit functional form, weighting procedure, or normalization is supplied; without this it is impossible to rule out that reported gains are partly tautological, as the policy directly optimizes the same quantities appearing in the utility.
- [Evaluation] Evaluation section (baseline comparison): the simulation injects concurrent demographic bias shocks, gradual drift, and abrupt disruptions, but no calibration against production traces or ablation on individual shock types is described; this makes it impossible to isolate whether the reported advantage stems from the HJB+Lyapunov design or from simulator-specific dynamics.
minor comments (2)
- [Evaluation] The abstract and evaluation paragraph cite five baselines (Static, Round Robin, Greedy, LinUCB, PPO) but do not specify the exact state/action spaces or reward formulations used for the RL baseline, which would aid reproducibility.
- [Framework] Notation for the composite utility and the Lyapunov function is introduced without an accompanying table of symbols or explicit dependence on the resource-allocation vector, making the closed-loop policy description harder to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate the revisions that will be incorporated to improve the manuscript's clarity, reproducibility, and robustness.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (performance claims paragraph): all quantitative results (immediate black-swan recovery, 29%/25% quantile lifts, parity-gap reductions, Lyapunov-stable fraction) derive from one unreproduced discrete-time simulation whose exact state-transition model, shock magnitudes/timings, exclusion rules, and parameter values are not reported; no error bars, statistical tests, or sensitivity sweeps appear, so the central empirical claim cannot be assessed for robustness.
Authors: We agree that the simulation details and statistical rigor are insufficiently documented. In the revised version we will supply the complete state-transition model, exact shock magnitudes, timings, exclusion rules, and all parameter values. We will also report results aggregated over multiple independent runs with error bars, include appropriate statistical tests, and add sensitivity sweeps over key parameters. revision: yes
-
Referee: [Framework] Framework description (utility definition): the global utility is stated to be 'defined jointly over predictive performance, demographic parity, cost, latency, robustness, and interpretability,' yet no explicit functional form, weighting procedure, or normalization is supplied; without this it is impossible to rule out that reported gains are partly tautological, as the policy directly optimizes the same quantities appearing in the utility.
Authors: The referee is correct that the explicit functional form was omitted. The revised manuscript will include the precise mathematical definition of the composite utility, the weighting procedure, and the normalization steps so that the optimization objective is fully specified and the reported gains can be independently verified. revision: yes
-
Referee: [Evaluation] Evaluation section (baseline comparison): the simulation injects concurrent demographic bias shocks, gradual drift, and abrupt disruptions, but no calibration against production traces or ablation on individual shock types is described; this makes it impossible to isolate whether the reported advantage stems from the HJB+Lyapunov design or from simulator-specific dynamics.
Authors: We will add ablations that isolate the contribution of each shock type (demographic bias shocks, concept drift, black-swan events) to clarify the source of the performance gains. Direct calibration to proprietary production traces is not possible within the scope of this work; we will instead expand the discussion of how the chosen shock parameters are motivated by documented real-world phenomena. revision: partial
Circularity Check
No circularity in derivation; framework and evaluation remain independent
full rationale
The paper defines a composite utility over performance, fairness, cost, latency, robustness and interpretability, then deploys a policy to maximise it inside a discrete-time simulator that injects the listed disruptions. No equations, functional forms or weighting procedures are supplied in the text that would make the reported metric improvements (recovery time, quantile lifts, parity-gap reduction, Lyapunov-stable fraction) equivalent to the inputs by construction. The comparative claims are obtained by running the same simulator against five external baselines; nothing in the supplied abstract or description reduces any central result to a self-definition, a fitted parameter renamed as prediction, or a self-citation chain. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- weights in the composite utility function
- simulation parameters for shock magnitude and timing
axioms (2)
- domain assumption Heterogeneous AI models can have their computational budgets redistributed at each discrete time step without additional overhead or model-specific constraints.
- domain assumption The chosen Lyapunov function certifies stability for the closed-loop system under the injected disruptions.
Reference graph
Works this paper leans on
-
[1]
AI revolutionizing industries worldwide: A comprehensive overview of its diverse applications,
A. B. Rashid and M. A. K. Kausik, “AI revolutionizing industries worldwide: A comprehensive overview of its diverse applications,” Hybrid Adv., vol. 7, p. 100277, 2024
2024
-
[2]
Imagining the thinking machine: Techno- logical myths and the rise of artificial intelligence,
S. Natale and A. Ballatore, “Imagining the thinking machine: Techno- logical myths and the rise of artificial intelligence,”Convergence: Int. J. Res. New Media Technol., vol. 26, no. 1, pp. 3–18, 2020
2020
-
[3]
Getting from generative AI to trustworthy AI: What LLMs might learn from Cyc,
D. Lenat and G. Marcus, “Getting from generative AI to trustworthy AI: What LLMs might learn from Cyc,” 2023,arXiv:2308.04445
-
[4]
Z. B. Akhtar, “Unveiling the evolution of generative AI (GAI): A comprehensive and investigative analysis toward LLM models (2021–
2021
-
[5]
and beyond,”J. Electr . Syst. Inf. Technol., vol. 11, no. 1, p. 22, 2024
2024
-
[6]
A survey on bias and fairness in machine learning,
N. Mehrabi, F. Morstatter, N. Saxena, K. Lerman, and A. Galstyan, “A survey on bias and fairness in machine learning,”ACM Comput. Surv., vol. 54, no. 6, pp. 1–35, Jul. 2021
2021
-
[7]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatricket al., “Overcoming catastrophic forgetting in neural networks,”Proc. Nat. Acad. Sci., vol. 114, no. 13, pp. 3521–3526, Mar. 2017
2017
-
[8]
Threat of adversarial attacks on deep learning in computer vision: A survey,
N. Akhtar and A. Mian, “Threat of adversarial attacks on deep learning in computer vision: A survey,”IEEE Access, vol. 6, pp. 14410–14430, 2018
2018
-
[9]
Federated learning: Challenges, methods, and future directions,
T. Li, A. K. Sahu, A. Talwalkar, and V . Smith, “Federated learning: Challenges, methods, and future directions,”IEEE Signal Process. Mag., vol. 37, no. 3, pp. 50–60, May 2020
2020
-
[10]
Toward safe and accelerated deep reinforcement learning for next-generation wireless networks,
A. M. Nagib, H. Abou-Zeid, and H. S. Hassanein, “Toward safe and accelerated deep reinforcement learning for next-generation wireless networks,”IEEE Netw., vol. 37, no. 2, pp. 182–189, Mar.–Apr. 2023
2023
-
[11]
R. S. Sutton and A. G. Barto,Reinforcement Learning: An Introduction, 2nd ed. Cambridge, MA, USA: MIT Press, 2018
2018
-
[12]
A contextual-bandit approach to personalized news article recommendation,
L. Li, W. Chu, J. Langford, and R. E. Schapire, “A contextual-bandit approach to personalized news article recommendation,” inProc. 19th Int. Conf. World Wide Web (WWW), 2010, pp. 661–670
2010
-
[13]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017,arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.