ATGBuilder: Feature-Assisted Graph Learning for Activity Transition Graph Construction with Seed Supervision
Pith reviewed 2026-06-26 03:32 UTC · model grok-4.3
The pith
ATGBuilder improves activity transition graph construction for Android apps by combining LLM summaries with widget feature reconstruction in graph learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ATGBuilder constructs higher-quality activity transition graphs by using an LLM to produce compact textual functionality summaries from activity layouts, encoding widget-trigger information as edge attributes, and adding an auxiliary widget-attribute reconstruction objective during training of a seed-supervised graph learning model.
What carries the argument
ATGBuilder, a feature-assisted graph learning model that integrates LLM-generated activity summaries and an auxiliary widget-attribute reconstruction loss to support seed-supervised link prediction for ATGs.
If this is right
- Higher-quality ATGs reduce both missed acceptable transitions and extracted infeasible ones compared with pure static or dynamic baselines.
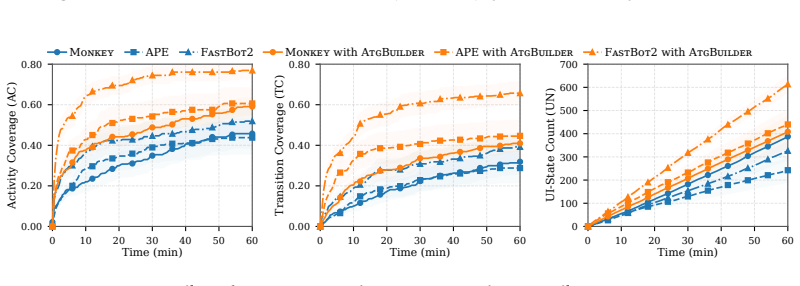
- The improved graphs provide better navigation guidance that increases coverage in automated GUI exploration tools.
- Ablation results indicate that both the LLM summaries and the widget reconstruction objective contribute to the observed gains.
- The seed-supervised framing allows the approach to leverage limited verified transitions without requiring full ground truth during training.
Where Pith is reading between the lines
- The same LLM-plus-reconstruction pattern could be tested on iOS or web app navigation graphs where layout metadata is similarly available.
- If widget triggers prove central, other static features such as permission declarations or intent filters might be added as additional edge attributes.
- The method's reliance on LLM summarization quality suggests that performance may vary with the choice of LLM and prompt design on new app corpora.
Load-bearing premise
The manually-checked ground-truth ATGs used for evaluation are assumed to be complete and unbiased.
What would settle it
Re-labeling the benchmark apps with an independent team of human reviewers and measuring whether the performance advantage over baselines disappears or reverses.
Figures

read the original abstract
Android applications are organized around activities that provide visual Graphical User Interface (GUI) containers that host the UI and handle user interaction events. Activity Transition Graphs (ATGs) have been widely used to model apps' GUI navigation. However, the construction of high-quality ATGs is challenging: ATGs based on static analysis may miss acceptable transitions and may extract infeasible ones; while dynamically explored ATGs can yield incomplete transitions. Recent learning-based approaches can treat ATG construction as a seed-supervised link-prediction task. However, the use of activity-layout and widget-trigger information for ATG construction remains limited. We propose ATGBuilder, a feature-assisted graph-learning approach for seed-supervised ATG construction. ATGBuilder uses a Large Language Model (LLM) to summarize UI activity metadata from layouts into compact textual functionality summaries. ATGBuilder explicitly models widget-trigger information into the edge attribute: It then uses an auxiliary widget-attribute reconstruction objective on this information during model training. ATGBuilder's performance was evaluated across a series of ablations on the frontmatter corpus, and an experiment on benchmark using manually-checked ground-truth ATGs. Experiments on multiple benchmarks show that ATGBuilder significantly outperforms state-of-the-art methods. We further demonstrate its effectiveness by improving automated GUI exploration tools through better navigation guidance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ATGBuilder, a feature-assisted graph learning method for seed-supervised construction of Activity Transition Graphs (ATGs) in Android apps. It employs an LLM to generate compact textual summaries of activity layouts, incorporates widget-trigger information as edge attributes, and trains with an auxiliary widget-attribute reconstruction objective. The authors evaluate via ablations on a frontmatter corpus and benchmark experiments against manually-checked ground-truth ATGs, claiming significant outperformance over SOTA methods and improved guidance for automated GUI exploration tools.
Significance. If the results hold under rigorous GT validation, the work could meaningfully advance automated Android app analysis and testing by producing more complete and accurate navigation models than pure static or dynamic approaches. The combination of LLM-derived functionality summaries with explicit modeling of widget triggers and an auxiliary reconstruction loss represents a targeted technical contribution to link-prediction formulations of ATG construction. Reproducibility of the headline empirical gains, however, hinges on details of the ground-truth process that are currently absent.
major comments (2)
- [Evaluation / benchmark experiments] Evaluation / benchmark section: The central claim that ATGBuilder 'significantly outperforms state-of-the-art methods' on multiple benchmarks rests entirely on comparisons against manually-checked ground-truth ATGs. The manuscript describes these GTs only as 'manually-checked' and supplies no labeling protocol, number of raters, inter-rater agreement statistics, app-selection criteria, or coverage/completeness guarantees. This is load-bearing for the outperformance result; without these details the reported gains cannot be reproduced or distinguished from possible systematic biases in the reference ATGs.
- [Ablation study] Ablation study (frontmatter corpus): The paper states that performance was evaluated 'across a series of ablations' yet provides neither quantitative metrics for each ablation variant, nor tables of results, nor any statistical significance testing. This prevents assessment of whether the LLM summaries or auxiliary reconstruction objective actually drive the claimed improvements.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., F1 or accuracy delta versus the strongest baseline) to substantiate the 'significantly outperforms' statement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to improve the reproducibility of the evaluation and ablation results.
read point-by-point responses
-
Referee: [Evaluation / benchmark experiments] Evaluation / benchmark section: The central claim that ATGBuilder 'significantly outperforms state-of-the-art methods' on multiple benchmarks rests entirely on comparisons against manually-checked ground-truth ATGs. The manuscript describes these GTs only as 'manually-checked' and supplies no labeling protocol, number of raters, inter-rater agreement statistics, app-selection criteria, or coverage/completeness guarantees. This is load-bearing for the outperformance result; without these details the reported gains cannot be reproduced or distinguished from possible systematic biases in the reference ATGs.
Authors: We agree that the manuscript currently lacks sufficient detail on the ground-truth construction process. In the revised version we will add a dedicated subsection describing the labeling protocol, number of raters, inter-rater agreement statistics (e.g., Cohen's kappa), app-selection criteria, and any coverage or completeness guarantees used when creating the manually-checked ATGs. revision: yes
-
Referee: [Ablation study] Ablation study (frontmatter corpus): The paper states that performance was evaluated 'across a series of ablations' yet provides neither quantitative metrics for each ablation variant, nor tables of results, nor any statistical significance testing. This prevents assessment of whether the LLM summaries or auxiliary reconstruction objective actually drive the claimed improvements.
Authors: We acknowledge that the current ablation section does not report the requested quantitative details. We will expand the ablation study in the revision to include complete result tables for every variant, all performance metrics, and statistical significance tests (e.g., paired t-tests or Wilcoxon tests) so that the contribution of the LLM summaries and auxiliary reconstruction objective can be directly assessed. revision: yes
Circularity Check
No circularity: empirical ML model with external benchmarks and auxiliary loss; no self-referential reduction visible.
full rationale
The paper describes an empirical graph-learning approach for seed-supervised link prediction on ATGs, incorporating LLM-derived summaries and an auxiliary widget-attribute reconstruction objective. No equations, parameter-fitting procedures, or derivation steps are presented that reduce a claimed prediction back to its own inputs by construction. Evaluation relies on manually-checked ground-truth ATGs from external benchmarks rather than self-generated data. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central claim of outperformance is therefore an independent empirical result against external references and does not collapse into a definitional or fitted tautology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Android Developers. 2024. UI/Application Exerciser Monkey. https://developer.android.com/studio/test/other-testing- tools/monkey. Accessed: 2025
2024
-
[2]
Gilles Baechler, Srinivas Sunkara, Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor Carbune, Jason Lin, Jindong Chen, and Abhanshu Sharma. 2024. ScreenAI: A Vision-Language Model for UI and Infographics Understanding. InProceedings of the 33rd International Joint Conference on Artificial Intelligence (IJCAI’24). 3058–3068
2024
-
[3]
Sen Chen, Lingling Fan, Chunyang Chen, Ting Su, Wenhe Li, Yang Liu, and Lihua Xu. 2019. StoryDroid: Automated Generation of Storyboard for Android Apps. InProceedings of the 41st International Conference on Software Engineering (ICSE’19). 596–607
2019
-
[4]
Yige Chen, Sinan Wang, Yida Tao, and Yepang Liu. 2024. Model-based GUI Testing for HarmonyOS Apps. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering (ASE’24). 2411–2414
2024
-
[5]
Zhen Dong, Marcel Böhme, Lucia Cojocaru, and Abhik Roychoudhury. 2020. Time-Travel Testing of Android Apps. In Proceedings of the 42nd International Conference on Software Engineering (ICSE’20). 481–492
2020
-
[6]
Yue Fan, Lei Ding, Ching-Chen Kuo, Shan Jiang, Yang Zhao, Xinze Guan, Jie Yang, Yi Zhang, and Xin Wang. 2024. Read Anywhere Pointed: Layout-aware GUI Screen Reading with Tree-of-Lens Grounding. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP’24). 9503–9522
2024
-
[7]
Mattia Fazzini, Martin Prammer, Marcelo d’Amorim, and Alessandro Orso. 2018. Automatically Translating Bug Reports into Test Cases for Mobile Apps. InProceedings of the 27th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA’18). 141–152
2018
-
[8]
2016.Deep Learning
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. 2016.Deep Learning. MIT Press. http://www.deeplearningbook .org
2016
-
[9]
Google. 2018. BERT Base Model (cased). https://huggingface.co/google-bert/bert-base-cased. Accessed: 2026
2018
-
[10]
Google. 2026. Android Apps on Google Play. https://play.google.com/store/apps. Accessed: 2026
2026
-
[11]
Tianxiao Gu, Chengnian Sun, Xiaoxing Ma, Chun Cao, Chang Xu, Yuan Yao, Qirun Zhang, Jian Lu, and Zhendong Su
-
[12]
InProceedings of the 41st International Conference on Software Engineering (ICSE’19)
Practical GUI Testing of Android Applications via Model Abstraction and Refinement. InProceedings of the 41st International Conference on Software Engineering (ICSE’19). 269–280
-
[13]
Wunan Guo, Zhen Dong, Liwei Shen, Daihong Zhou, Bin Hu, Chen Zhang, and Hai Xue. 2025. Effectively Modeling UI Transition Graphs for Android Apps Via Reinforcement Learning. InProceedings of the 33rd IEEE/ACM International J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018. AtgBuilder: Feature-Assisted Graph Learning for Activity Transitio...
2025
-
[14]
Yiling He, Hongyu She, Xingzhi Qian, Xinran Zheng, Zhuo Chen, Zhan Qin, and Lorenzo Cavallaro. 2025. On Benchmarking Code LLMs for Android Malware Analysis. InProceedings of the 34th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA Companion’25). 153–160
2025
-
[15]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations (ICLR’17)
2017
-
[16]
Pingfan Kong, Li Li, Jun Gao, Kui Liu, Tegawendé F Bissyandé, and Jacques Klein. 2018. Automated Testing of Android Apps: A Systematic Literature Review.IEEE Transactions on Reliability68, 1 (2018), 45–66
2018
-
[17]
Konstantin Kuznetsov, Vitalii Avdiienko, Alessandra Gorla, and Andreas Zeller. 2018. Analyzing the user interface of Android apps. InProceedings of the 5th International Conference on Mobile Software Engineering and Systems (MOBILESoft@ICSE’18). 84–87
2018
-
[18]
Jansen, Lijun Zhang, and Andreas Zeller
Konstantin Kuznetsov, Chen Fu, Song Gao, David N. Jansen, Lijun Zhang, and Andreas Zeller. 2021. Frontmatter: Mining Android User Interfaces at Scale. InProceedings of the 29th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering (ESEC/FSE’21). 1580–1584
2021
-
[19]
Duling Lai and Julia Rubin. 2019. Goal-Driven Exploration for Android Applications. InProceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering (ASE’19). 115–127
2019
-
[20]
Samuli Laine and Timo Aila. 2017. Temporal Ensembling for Semi-Supervised Learning. InProceedings of the 5th International Conference on Learning Representations (ICLR’17)
2017
-
[21]
Qimai Li, Zhichao Han, and Xiao-Ming Wu. 2018. Deeper Insights Into Graph Convolutional Networks for Semi- Supervised Learning. InProceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI’18). 3538–3545
2018
-
[22]
Yuanchun Li, Ziyue Yang, Yao Guo, and Xiangqun Chen. 2019. Humanoid: A Deep Learning-Based Approach to Automated Black-Box Android App Testing. InProceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering (ASE’19). 1070–1073
2019
-
[23]
LibreTube contributors. 2021. LibreTube. https://github.com/libre-tube/LibreTube. Accessed: 2026
2021
-
[24]
Jiakun Liu, Peixin Zhang, Han Hu, Yonghui Liu, Wei Minn, Ferdian Thung, Shahar Maoz, Eran Toch, Debin Gao, and David Lo. 2025. Activity Transition Graph Generation: How Far Are We?ACM Transactions on Software Engineering and Methodology(2025). https://doi.org/10.1145/3776553 Just Accepted
-
[25]
Zhe Liu, Chunyang Chen, Junjie Wang, Xing Che, Yuekai Huang, Jun Hu, and Qing Wang. 2023. Fill in the Blank: Context-aware Automated Text Input Generation for Mobile GUI Testing. InProceedings of the 45th International Conference on Software Engineering. 1355–1367
2023
-
[26]
Zhe Liu, Chunyang Chen, Junjie Wang, Yuhui Su, Yuekai Huang, Jun Hu, and Qing Wang. 2023. Ex pede Herculem: Augmenting Activity Transition Graph for Apps via Graph Convolution Network. InProceedings of the 45th IEEE/ACM International Conference on Software Engineering (ICSE’23). 1983–1995
2023
-
[27]
Yanchen Lu, Hongyu Lin, Zehua He, Haitao Xu, Zhao Li, Shuai Hao, Liu Wang, Haoyu Wang, and Kui Ren. 2025. TacDroid: Detection of Illicit Apps Through Hybrid Analysis of UI-Based Transition Graphs. InProceedings of the 47th IEEE/ACM International Conference on Software Engineering (ICSE’25). 2790–2802
2025
-
[28]
Zhengwei Lv, Chao Peng, Zhao Zhang, Ting Su, Kai Liu, and Ping Yang. 2022. Fastbot2: Reusable Automated Model- based GUI Testing for Android Enhanced by Reinforcement Learning. InProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering (ASE’22). 135:1–135:5
2022
-
[29]
Nguyen, Bryan Robbins, Ishan Banerjee, and Atif M
Bao N. Nguyen, Bryan Robbins, Ishan Banerjee, and Atif M. Memon. 2014. GUITAR: An Innovative Tool for Automated Testing of GUI-driven Software.Automated Software Engineering21, 1 (2014), 65–105
2014
-
[30]
Kenta Oono and Taiji Suzuki. 2020. Graph Neural Networks Exponentially Lose Expressive Power for Node Classifica- tion. InProceedings of the 8th International Conference on Learning Representations (ICLR’20)
2020
-
[31]
OpenAI. 2024. GPT-4o. https://openai.com/index/hello-gpt-4o. Accessed: 2025
2024
-
[32]
Minxue Pan, An Huang, Guoxin Wang, Tian Zhang, and Xuandong Li. 2020. Reinforcement Learning Based Curiosity- Driven Testing of Android Applications. InProceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA’20). 153–164
2020
-
[33]
Reed, Honglak Lee, Dragomir Anguelov, Christian Szegedy, Dumitru Erhan, and Andrew Rabinovich
Scott E. Reed, Honglak Lee, Dragomir Anguelov, Christian Szegedy, Dumitru Erhan, and Andrew Rabinovich. 2015. Training Deep Neural Networks on Noisy Labels with Bootstrapping. InProceedings of the 3rd International Conference on Learning Representations (ICLR’15)
2015
-
[34]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP’19). 3980–3990
2019
-
[35]
Ernst, Tegawendé F
Jordan Samhi, René Just, Michael D. Ernst, Tegawendé F. Bissyandé, and Jacques Klein. 2026. Resolving Conditional Implicit Calls to Improve Static and Dynamic Analysis in Android Apps.ACM Transactions on Software Engineering and Methodology35, 2 (2026). J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018. 111:24 Chenhui Cui, Zixiang Xian, D...
2026
-
[36]
Sentence-BERT. 2020. all-MiniLM-L12-v2. https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2. Accessed: 2026
2020
-
[37]
Statista. 2025. Market Share of Mobile Operating Systems Worldwide from 2009 to 2025, by Quarter. https://www.stat ista.com/statistics/272698/global-market-share-held-by-mobile-operating-systems-since-2009/. Accessed: 2026
2025
-
[38]
Ting Su, Guozhu Meng, Yuting Chen, Ke Wu, Weiming Yang, Yao Yao, Geguang Pu, Yang Liu, and Zhendong Su
-
[39]
InProceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering (ESEC/FSE’17)
Guided, Stochastic Model-based GUI Testing of Android Apps. InProceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering (ESEC/FSE’17). 245–256
2017
-
[40]
Team NewPipe. 2015. NewPipe. https://github.com/TeamNewPipe/NewPipe. Accessed: 2026
2015
-
[41]
Wenyu Wang, Wing Lam, and Tao Xie. 2021. An Infrastructure Approach to Improving Effectiveness of Android UI Testing Tools. InProceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA’21). ACM, 165–176
2021
-
[42]
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S. Yu. 2021. A Comprehensive Survey on Graph Neural Networks.IEEE Transactions on Neural Networks and Learning Systems32, 1 (2021), 4–24
2021
-
[43]
Xusheng Xiao, Xiaoyin Wang, Zhihao Cao, Hanlin Wang, and Peng Gao. 2019. IconIntent: Automatic Identification of Sensitive UI Widgets based on Icon Classification for Android Apps. InProceedings of the 41st International Conference on Software Engineering (ICSE’19). 257–268
2019
-
[44]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. 2019. How Powerful are Graph Neural Networks?. In Proceedings of the 7th International Conference on Learning Representations (ICLR’19)
2019
-
[45]
Shengqian Yang, Haowei Wu, Hailong Zhang, Yan Wang, Chandrasekar Swaminathan, Dacong Yan, and Atanas Rountev. 2018. Static window transition graphs for Android.Automated Software Engineering25, 4 (2018), 833–873
2018
-
[46]
Shuaihao Yang, Zigang Zeng, and Wei Song. 2022. PermDroid: Automatically Testing Permission-Related Behaviour of Android Applications. InProceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis (ISSTA’22). 593–604
2022
-
[47]
Zenodo. 2021. Frontmatter Dataset. https://zenodo.org/records/5084655. Accessed: 2026
arXiv 2021
-
[48]
Muhan Zhang and Yixin Chen. 2018. Link Prediction Based on Graph Neural Networks. InProceedings of the 31st Annual Conference on Neural Information Processing Systems (NeurIPS’18). 5171–5181
2018
-
[49]
Xiangyu Zhang, Lingling Fan, Sen Chen, Yucheng Su, and Boyuan Li. 2023. Scene-Driven Exploration and GUI Modeling for Android Apps. InProceedings of the 38th IEEE/ACM International Conference on Automated Software Engineering (ASE’23). 1251–1262
2023
-
[50]
Yixue Zhao, Marcelo Schmitt Laser, Yingjun Lyu, and Nenad Medvidovic. 2018. Leveraging Program Analysis to Reduce User-Perceived Latency in Mobile Applications. InProceedings of the 40th International Conference on Software Engineering (ICSE’18). 176–186. J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018. AtgBuilder: Feature-Assisted Grap...
2018
-
[54]
activity_id
Return as a pure JSON object wrapped in triple backticks (code block markers): 13```{ 14"activity_id": "[MASK_ID]", 15"activity_name": "[MASK_NAME]", 16"purpose": "YOUR_ANSWER" 17}``` 18 19retry_prompt_template: | 20The previous response did not meet the requirements. Please try again to summarize the core purpose of the Activity in one sentence, followin...
-
[58]
activity_id
Return as a pure JSON object wrapped in triple backticks (code block markers): 31```{ 32"activity_id": "[MASK_ID]", 33"activity_name": "[MASK_NAME]", 34"purpose": "YOUR_ANSWER" 35}``` 36 37widget_prompt_template: | 38As an Android app tester, given a Widget's info: 39- Widget id: [MASK_ID] 40- Widget type: [MASK_TYPE] 41- Widget structure: [MASK_CONTENT] ...
-
[62]
widget_id
Return as a pure JSON object wrapped in triple backticks (code block markers): 49```{ 50"widget_id": "[MASK_ID]", J. ACM, Vol. 37, No. 4, Article 111. Publication date: August 2018. 111:2 Chenhui Cui, Zixiang Xian, Danyu Li, Tao Li, Rubing Huang, Dave Towey, Shikai Guo, and Jiakun Liu 51"widget_type": "[MASK_TYPE]", 52"purpose": "YOUR_ANSWER" 53}``` 54 55...
2018
-
[63]
In English and in one concise sentence (<= 30 English words)
-
[64]
Accurately reflects the main function/purpose
-
[65]
No extra info/explanations
-
[66]
widget_id
Return as a pure JSON object wrapped in triple backticks (code block markers): 67```{ 68"widget_id": "[MASK_ID]", 69"widget_type": "[MASK_TYPE]", 70"purpose": "YOUR_ANSWER" 71}``` These prompts are used consistently across apps to encourage concise, consistent summaries for subsequent embedding and feature fusion. B Summary Length Selection AtgBuilderuses...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.