SubdivAR: Autoregressive Next-Scale Prediction for Neural Mesh Subdivision
Pith reviewed 2026-06-26 04:59 UTC · model grok-4.3
The pith
SubdivAR reformulates mesh subdivision as autoregressive next-scale prediction to recover fine details while preserving topology.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
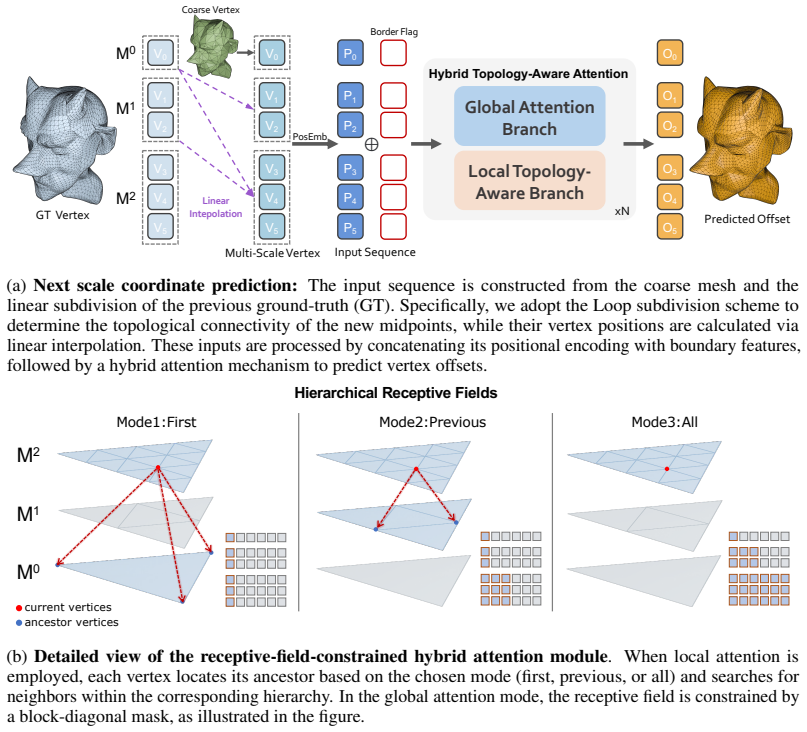
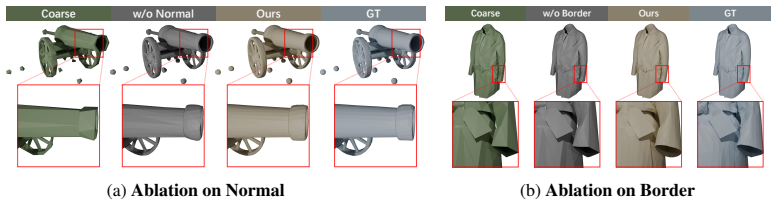
SubdivAR introduces Mesh Autoregressive Representation (MAR) that arranges meshes at different subdivision levels into an ordered scale sequence, reformulating the task as autoregressive next-scale prediction. A Hybrid Topology-Aware Transformer combines global semantic attention with topology-constrained local feature aggregation to regress vertex offsets at each refinement stage. This preserves the subdivision topology while recovering fine-grained geometric details. The approach is trained on the FII-40K dataset of nearly 40,000 high-quality meshes with multi-level supervision and is reported to reduce Hausdorff Distance by 18.8% and Chamfer Distance by 14.2% over baselines while showing
What carries the argument
Mesh Autoregressive Representation (MAR), which sequences meshes across subdivision levels to enable next-scale coordinate prediction.
If this is right
- The subdivision topology remains fixed while vertex offsets add geometric detail at each scale.
- Global semantic attention and local topology constraints operate together inside the Hybrid Topology-Aware Transformer.
- Training uses explicit multi-level subdivision supervision from the FII-40K dataset.
- Reported error reductions reach 18.8% on Hausdorff Distance and 14.2% on Chamfer Distance relative to prior methods.
- Performance remains stable on complex open-surface geometries.
Where Pith is reading between the lines
- The sequencing idea could transfer to related tasks such as point-cloud densification or hierarchical surface reconstruction.
- Coarse editable meshes could serve as controllable starting points inside larger text-to-3D pipelines.
- Performance may depend on whether new meshes follow subdivision rules similar to those used when curating FII-40K.
- Autoregressive next-scale prediction might extend to time-varying or animated mesh sequences.
Load-bearing premise
The FII-40K dataset of nearly 40,000 meshes supplies training signals diverse enough for the autoregressive model to generalize to unseen meshes and hierarchies.
What would settle it
Run SubdivAR on a fresh collection of meshes drawn from sources or topologies absent from FII-40K and measure whether the reported reductions in Hausdorff and Chamfer distances still hold.
Figures













read the original abstract
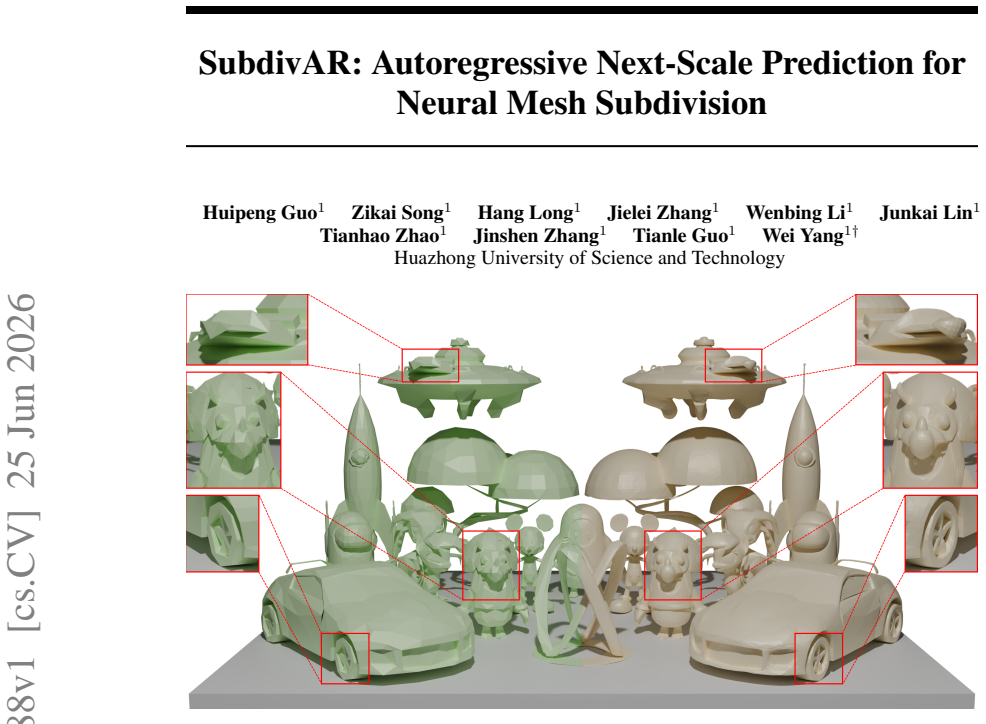
Mesh subdivision is a fundamental operation for converting coarse, editable meshes into high-resolution surfaces, with broad applications in digital asset creation. Classical rule-based schemes rely on fixed local refinement rules and often produce over-smoothed surfaces. Recent neural subdivision methods improve detail synthesis, but remain constrained by local modeling and exhibit limited generalizability. We present SubdivAR, a neural mesh subdivision framework based on our proposed Mesh Autoregressive Representation (MAR). MAR arranges meshes at different subdivision levels into an ordered scale sequence, reformulating subdivision as autoregressive next-scale prediction. To support this formulation, we introduce a Hybrid Topology-Aware Transformer that combines global semantic attention with topology-constrained local feature aggregation. SubdivAR adopts a next-scale coordinate prediction paradigm, regressing vertex offsets at each refinement stage to preserve subdivision topology while recovering fine-grained geometric details. To enable reliable learning, we construct FII-40K, a curated dataset of nearly 40,000 high-quality meshes with multi-level subdivision supervision. Experiments show that SubdivAR outperforms state-of-the-art baselines, reducing Hausdorff Distance and Chamfer Distance by 18.8% and 14.2%, respectively, and demonstrates strong robustness on complex open-surface geometries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SubdivAR, a neural mesh subdivision method based on Mesh Autoregressive Representation (MAR) that reformulates subdivision as autoregressive next-scale prediction. It employs a Hybrid Topology-Aware Transformer combining global semantic attention with topology-constrained local aggregation, adopts next-scale coordinate prediction for vertex offsets, and constructs the FII-40K dataset of nearly 40,000 meshes with multi-level subdivision supervision. Experiments claim SubdivAR outperforms state-of-the-art baselines by reducing Hausdorff Distance by 18.8% and Chamfer Distance by 14.2%, with robustness on complex open-surface geometries.
Significance. If the empirical results are validated with transparent dataset protocols and retrained baselines, the autoregressive next-scale formulation could meaningfully advance neural subdivision beyond local modeling constraints, offering improved detail recovery and generalizability. The large-scale FII-40K dataset with explicit multi-level supervision would also constitute a reusable resource for the community.
major comments (1)
- [Abstract] Abstract: The headline performance claims (18.8% Hausdorff Distance and 14.2% Chamfer Distance reductions) are obtained exclusively on the newly constructed FII-40K dataset. No information is supplied on curation criteria, category balance, train/test split construction, or confirmation that baselines were retrained on identical data and subdivision levels; without these details the attribution of gains to the MAR + Hybrid Transformer architecture cannot be verified and the central empirical claim remains load-bearing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater transparency on the FII-40K dataset and experimental protocol. We address this point directly below and will incorporate the requested details in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline performance claims (18.8% Hausdorff Distance and 14.2% Chamfer Distance reductions) are obtained exclusively on the newly constructed FII-40K dataset. No information is supplied on curation criteria, category balance, train/test split construction, or confirmation that baselines were retrained on identical data and subdivision levels; without these details the attribution of gains to the MAR + Hybrid Transformer architecture cannot be verified and the central empirical claim remains load-bearing.
Authors: We agree that the current manuscript does not provide sufficient detail on FII-40K construction and baseline retraining within the abstract (and, upon re-examination, the Experiments section also lacks explicit statements on these points). In the revised version we will add a dedicated subsection under Experiments that specifies: (i) curation criteria used to assemble the ~40K meshes, (ii) category distribution and balance, (iii) exact train/test split methodology, and (iv) confirmation that every baseline was retrained from scratch on the identical FII-40K data and multi-level subdivision targets. These additions will allow readers to directly attribute performance differences to the MAR formulation and Hybrid Topology-Aware Transformer. revision: yes
Circularity Check
No circularity; empirical results on new dataset
full rationale
The paper's central claims consist of an architectural reformulation (MAR as autoregressive next-scale prediction) and reported empirical gains (18.8% Hausdorff, 14.2% Chamfer reduction) on the newly constructed FII-40K dataset. No equations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. The performance numbers are external benchmarks against baselines rather than quantities forced by construction from the inputs. This is a standard empirical ML contribution with no detectable reduction of the claimed results to the method's own definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Recursively generated b-spline surfaces on arbitrary topo- logical meshes
Edwin Catmull and James Clark. Recursively generated b-spline surfaces on arbitrary topo- logical meshes. InSeminal graphics: pioneering efforts that shaped the field, pages 183–188. 1998
1998
-
[2]
Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zekun Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012, 2015
Pith/arXiv arXiv 2015
-
[3]
Triangular mesh surface subdivision based on graph neural network.Applied Sciences, 14(23), 2024
Guojun Chen and Rongji Wang. Triangular mesh surface subdivision based on graph neural network.Applied Sciences, 14(23), 2024. ISSN 2076-3417. doi: 10.3390/app142311378
-
[4]
Activating more pixels in image super-resolution transformer
Xiangyu Chen, Xintao Wang, Jiantao Wen, Yu Qiao Zhou, Chao Dong Xiang, and Li Cheng. Activating more pixels in image super-resolution transformer. InCVPR, 2023
2023
-
[5]
Yun-Chun Chen, Vladimir Kim, Noam Aigerman, and Alec Jacobson. Neural progressive meshes. SIGGRAPH ’23, New York, NY , USA, 2023. Association for Computing Machinery. ISBN 9798400701597. doi: 10.1145/3588432.3591531
-
[6]
Metro: measuring error on simplified surfaces.Computer Graphics Forum, 17(2):167–174, 1998
Paolo Cignoni, Claudio Rocchini, and Roberto Scopigno. Metro: measuring error on simplified surfaces.Computer Graphics Forum, 17(2):167–174, 1998
1998
-
[7]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13142–13153, 2023
2023
-
[8]
Behavior of recursive division surfaces near extraordinary points.Computer-Aided Design, 10(6):356–360, 1978
Daniel Doo and Malcolm Sabin. Behavior of recursive division surfaces near extraordinary points.Computer-Aided Design, 10(6):356–360, 1978
1978
-
[9]
A point set generation network for 3d object reconstruction from a single image
Haoqiang Fan, Hao Su, and Leonidas J Guibas. A point set generation network for 3d object reconstruction from a single image. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 605–613, 2017
2017
-
[10]
3d-future: 3d furniture shape with texture.International Journal of Computer Vision, 129 (12):3313–3337, 2021
Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3d-future: 3d furniture shape with texture.International Journal of Computer Vision, 129 (12):3313–3337, 2021
2021
-
[11]
Surface simplification using quadric error metrics
Michael Garland and Paul S Heckbert. Surface simplification using quadric error metrics. In Proceedings of the 24th annual conference on Computer graphics and interactive techniques, pages 209–216, 1997
1997
-
[12]
Spiralnet++: A fast and highly efficient mesh convolution operator
Shunwang Gong et al. Spiralnet++: A fast and highly efficient mesh convolution operator. In ICCVW, 2019
2019
-
[13]
Meshcnn: a network with an edge.ACM Transactions on Graphics (ToG), 38(4):1–12, 2019
Rana Hanocka, Amir Hertz, Noa Fish, Raja Giryes, Shachar Fleishman, and Daniel Cohen-Or. Meshcnn: a network with an edge.ACM Transactions on Graphics (ToG), 38(4):1–12, 2019
2019
-
[14]
Piecewise smooth surface reconstruction
Hugues Hoppe, Tony DeRose, Tom Duchamp, Mark Halstead, Hubert Jin, John McDonald, Jean Schweitzer, and Werner Stuetzle. Piecewise smooth surface reconstruction. InProceedings of the 21st annual conference on Computer graphics and interactive techniques, pages 295–302, 1994
1994
-
[15]
Subdivision-based mesh convolution networks.ACM Transactions on Graphics (TOG), 41(3):1–16, 2022
Shi-Min Hu, Zheng-Ning Liu, Meng-Hao Guo, Jun-Xiong Cai, Jiahui Huang, Tai-Jiang Mu, and Ralph R Martin. Subdivision-based mesh convolution networks.ACM Transactions on Graphics (TOG), 41(3):1–16, 2022
2022
-
[16]
√ 3-subdivision
Leif Kobbelt. √ 3-subdivision. InProceedings of the 27th annual conference on Computer graphics and interactive techniques, pages 103–112, 2000
2000
-
[17]
Armesh: Autoregressive mesh generation via next-level-of-detail prediction, 2025
Jiabao Lei, Kewei Shi, Zhihao Liang, and Kui Jia. Armesh: Autoregressive mesh generation via next-level-of-detail prediction, 2025. URLhttps://arxiv.org/abs/2509.20824. 10
arXiv 2025
-
[18]
Deeper insights into graph convolutional networks for semi-supervised learning, 2018
Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning, 2018. URLhttps://arxiv.org/abs/1801.07606
Pith/arXiv arXiv 2018
-
[19]
Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Yangguang Li, Zi-Xin Zou, Zexiang Liu, Dehu Wang, Yuan Liang, Zhipeng Yu, Xingchao Liu, Yuan-Chen Guo, Ding Liang, Wanli Ouyang, et al. Triposg: High-fidelity 3d shape synthesis using large-scale rectified flow models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[20]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, pages 1833–1844, October 2021
2021
-
[21]
Junkai Lin, Hang Long, Huipeng Guo, Jielei Zhang, JiaYi Yang, Tianle Guo, Yang Yang, Jianwen Li, Wenxiao Zhang, Matthias Nießner, et al. Meshripple: Structured autoregressive generation of artist-meshes.arXiv preprint arXiv:2512.07514, 2025
arXiv 2025
-
[22]
Neural subdivision.arXiv preprint arXiv:2005.01819, 2020
Hsueh-Ti Derek Liu, Vladimir G Kim, Siddhartha Chaudhuri, Noam Aigerman, and Alec Jacobson. Neural subdivision.arXiv preprint arXiv:2005.01819, 2020
arXiv 2005
-
[23]
Implicit neural distance optimization for mesh neural subdivision
Ke Liu, Ning Ma, Zhihua Wang, Jingjun Gu, Jiajun Bu, and Haishuai Wang. Implicit neural distance optimization for mesh neural subdivision. In2023 IEEE International Conference on Multimedia and Expo (ICME), pages 2039–2044, 2023. doi: 10.1109/ICME55011.2023.00349
-
[24]
Smooth subdivision surfaces based on triangles
Charles Loop. Smooth subdivision surfaces based on triangles. 1987
1987
-
[25]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2017
2017
-
[26]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis, 2020. URL https://arxiv.org/abs/2003.08934
arXiv 2020
-
[27]
Geometric deep learning on graphs and manifolds using mixture model cnns
Federico Monti et al. Geometric deep learning on graphs and manifolds using mixture model cnns. InCVPR, 2017
2017
-
[28]
Deepsdf: Learning continuous signed distance functions for shape representation
Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. Deepsdf: Learning continuous signed distance functions for shape representation. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 165–174, 2019
2019
-
[29]
Pytorch: An imperative style, high-performance deep learning library
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. InAdvances in neural information processing systems, 2019
2019
-
[30]
Convolutional occupancy networks, 2020
Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. Convolutional occupancy networks, 2020. URLhttps://arxiv.org/abs/2003.04618
arXiv 2020
-
[31]
Learning mesh-based simulation with graph networks
Tobias Pfaff et al. Learning mesh-based simulation with graph networks. InICLR, 2021
2021
-
[32]
Rolandos Alexandros Potamias, Stylianos Ploumpis, and Stefanos Zafeiriou. Neural mesh simplification. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18562–18571, 2022. doi: 10.1109/CVPR52688.2022.01803
-
[33]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017
2017
-
[34]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
2017
-
[35]
Pu-gcn: Point cloud upsampling using graph convolutional networks
Guocheng Qian, Abdulellah Abualshour, Guohao Li, Ali Thabet, and Bernard Ghanem. Pu-gcn: Point cloud upsampling using graph convolutional networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11683–11692, 2021. 11
2021
-
[36]
Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis.Advances in Neural Information Processing Systems, 34:6087–6101, 2021
Tianchang Shen, Jun Gao, Kangxue Yin, Ming-Yu Liu, and Sanja Fidler. Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis.Advances in Neural Information Processing Systems, 34:6087–6101, 2021
2021
-
[37]
Meshgpt: Generating triangle meshes with decoder-only transformers
Yawar Siddiqui, Antonio Alliegro, Alexey Artemov, Tatiana Tommasi, Daniele Sirigatti, Vladislav Rosov, Angela Dai, and Matthias Nießner. Meshgpt: Generating triangle meshes with decoder-only transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19615–19625, 2024
2024
-
[38]
Using shape to categorize: Low-shot learning with an explicit shape bias
Stefan Stojanov, Anh Thai, and James M Rehg. Using shape to categorize: Low-shot learning with an explicit shape bias. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1798–1808, 2021
2021
-
[39]
Structured 3d latents for scalable and versatile generation.arXiv:2412.01506, 2024
Jiaming Sun et al. Structured 3d latents for scalable and versatile generation.arXiv:2412.01506, 2024
Pith/arXiv arXiv 2024
-
[40]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. Visual autoregressive mod- eling: Scalable image generation via next-scale prediction.arXiv preprint arXiv:2404.02905, 2024
arXiv 2024
-
[41]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, 2017
2017
-
[42]
Feastnet: Feature-steered graph convolutions for 3d shape analysis
Nitika Verma et al. Feastnet: Feature-steered graph convolutions for 3d shape analysis. In CVPR, 2018
2018
-
[43]
Jiale Xu et al. Instantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruction models.arXiv:2404.07191, 2024
Pith/arXiv arXiv 2024
-
[44]
Rui Xu, Longdu Liu, Ningna Wang, Shuangmin Chen, Shiqing Xin, Xiaohu Guo, Zichun Zhong, Taku Komura, Wenping Wang, and Changhe Tu. Cwf: Consolidating weak features in high-quality mesh simplification.ACM Transactions on Graphics (TOG), 43(4), 2024. ISSN 0730-0301. doi: 10.1145/3658159. URLhttps://doi.org/10.1145/3658159
-
[45]
Pu-net: Point cloud upsampling network
Lequan Yu, Xianzhi Li, Chi-Wing Fu, Daniel Cohen-Or, and Pheng-Ann Heng. Pu-net: Point cloud upsampling network. InProceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018
2018
-
[46]
3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023
Biao Zhang, Jiapeng Tang, Matthias Niessner, and Peter Wonka. 3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models.ACM Transactions On Graphics (TOG), 42(4):1–16, 2023
2023
-
[47]
Clay: A controllable large-scale generative model for creating high- quality 3d assets.ACM Trans
Longwen Zhang, Ziyu Wang, Qixuan Zhang, Qiwei Qiu, Anqi Pang, Haoran Jiang, Wei Yang, Lan Xu, and Jingyi Yu. Clay: A controllable large-scale generative model for creating high- quality 3d assets.ACM Trans. Graph., 43(4), July 2024. ISSN 0730-0301. doi: 10.1145/ 3658146
2024
-
[48]
Torr, and Vladlen Koltun
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip H.S. Torr, and Vladlen Koltun. Point transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 16259–16268, October 2021
2021
-
[49]
Tianhao Zhao, Youjia Zhang, Hang Long, Jinshen Zhang, Wenbing Li, Yang Yang, Gongbo Zhang, Jozef Hladk `y, Matthias Nießner, and Wei Yang. Lato: 3d mesh flow matching with structured topology preserving latents.arXiv preprint arXiv:2603.06357, 2026
arXiv 2026
-
[50]
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, Yunfei Zhao, Haolin Liu, Shuhui Yang, Yifei Feng, Mingxin Yang, Sheng Zhang, Xianghui Yang, et al. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202, 2025
Pith/arXiv arXiv 2025
-
[51]
Pymesh-geometry processing library for python.GitHub repository, 2018
Qingnan Zhou and Eitan Grinspun. Pymesh-geometry processing library for python.GitHub repository, 2018
2018
-
[52]
Neural mesh refinement.Frontiers of Information Technology & Electronic Engineering, 26(5):695–712, 2025
Zhiwei Zhu, Xiang Gao, Lu Yu, and Yiyi Liao. Neural mesh refinement.Frontiers of Information Technology & Electronic Engineering, 26(5):695–712, 2025. 12
2025
-
[53]
Interpolating subdivision for meshes with arbitrary topology
Denis Zorin, Peter Schröder, and Wim Sweldens. Interpolating subdivision for meshes with arbitrary topology. InProceedings of the 23rd annual conference on Computer graphics and interactive techniques, pages 189–192, 1996. A Dataset A.1 Data Collection We collect meshes from several public datasets and apply a unified preprocessing and filtering pipeline ...
1996
-
[54]
Models >40,000 faces are simpli- fied via QEM (Garland and Heckbert[11])
Decimation and Cleaning:Filter meshes with <2,500 faces. Models >40,000 faces are simpli- fied via QEM (Garland and Heckbert[11]). We per- form cleaning and repair non-manifold structures using standard mesh processing libraries (Zhou and Grinspun [51])
-
[55]
Orientation and Normalization:Face orienta- tions are corrected using view-dependent visibility methods(algorithm 1) and meshes are normalized into a[−1,1]canonical space
-
[56]
[22]) to a coarse resolution of 750–850 faces and re- parametrization
Subdivision Generation:Cleaned meshes un- dergo stochastic decimation (Liu et al. [22]) to a coarse resolution of 750–850 faces and re- parametrization. Algorithm 1Mesh Normal Orientation Correction Require:verticesV, facesF Ensure:corrected mesh(V ′, F ′) 1:(F ′, C)←BFSOrient(F) 2:V ′ ←Normalize(V) 3:M←(V ′, F ′) 4:Sample cameras{c i}Nc i=1 on sphere 5:f...
-
[57]
and LATO [ 49] attempt to decode structured meshes from high-resolution voxel features. While promising, these methods currently face significant hurdles, including incomplete modeling, non-manifold holes, and the loss of fine-grained details, which hinder their practical adoption. Alternatively, the autoregressive approach, exemplified by AR-Mesh [ 17], ...
-
[58]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.