CHAMB-GA: A Containerized HPC Scalable Microservice-Based Framework for Genetic Algorithms
Pith reviewed 2026-06-26 02:23 UTC · model grok-4.3
The pith
A microservice framework runs genetic algorithms with embedded simulations at scale on both cloud and HPC systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
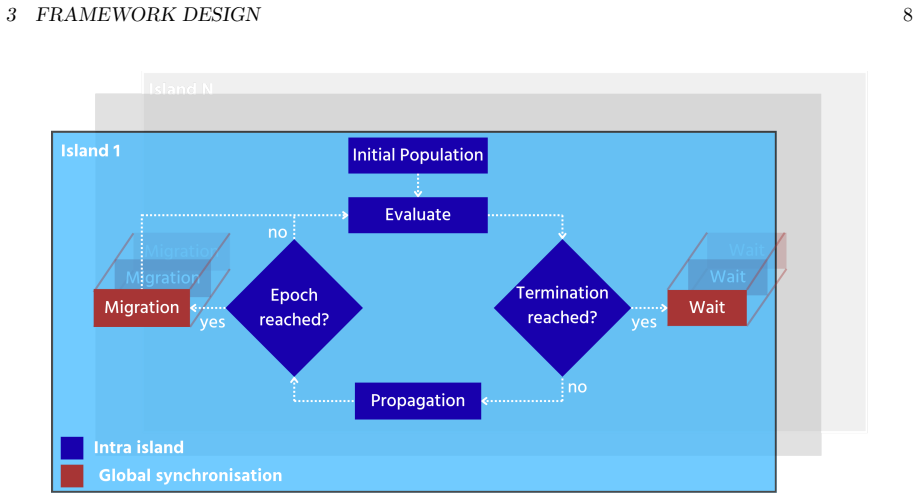
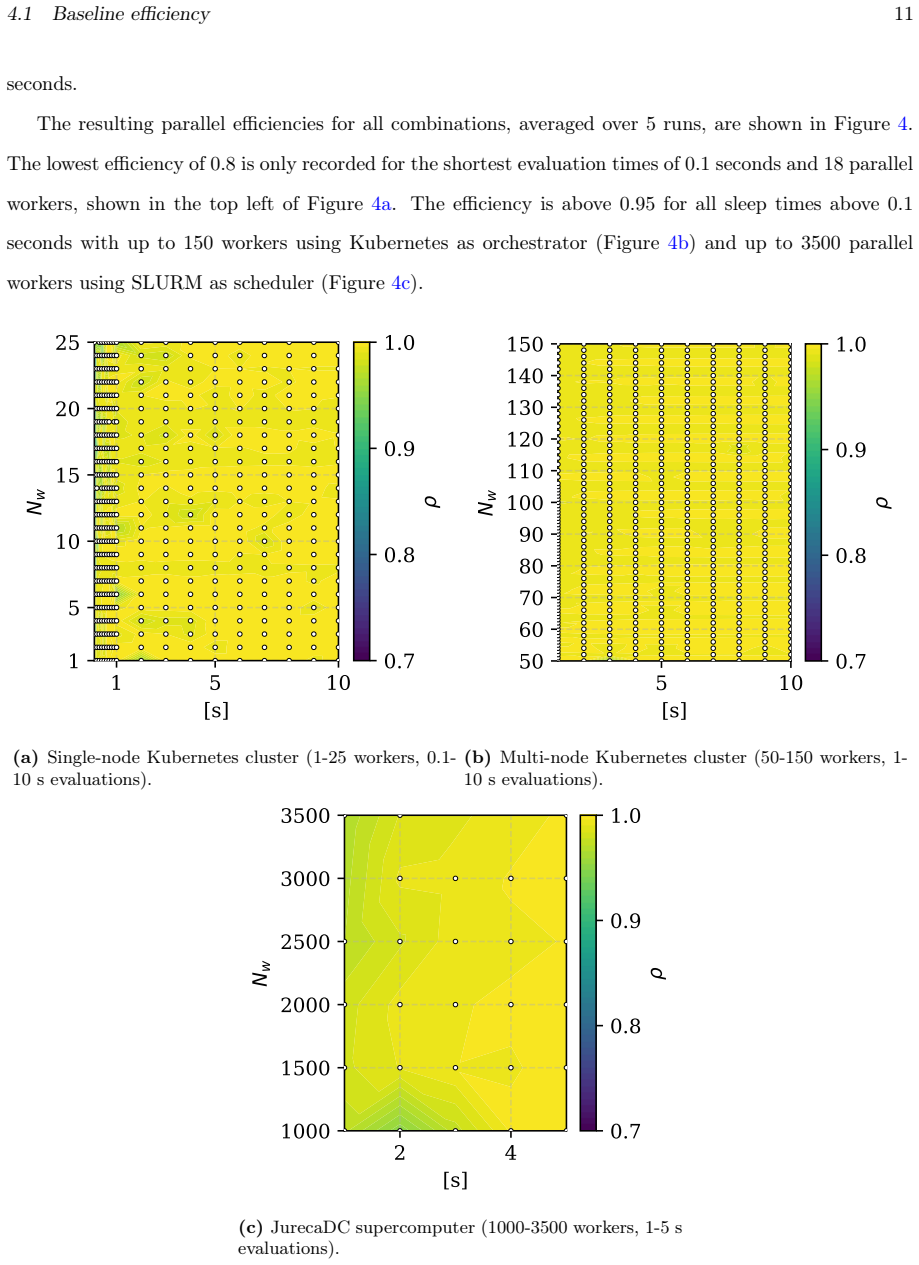
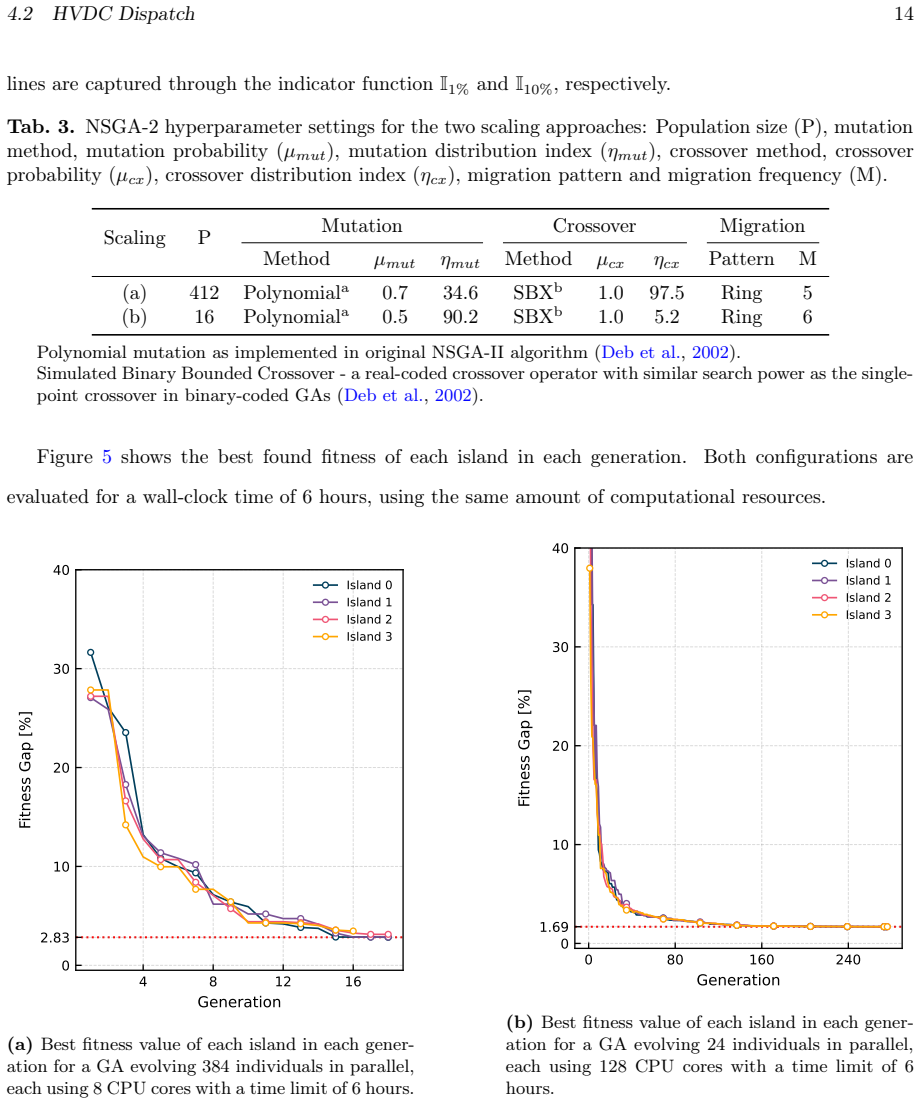
CHAMB-GA deploys genetic algorithms with long-running embedded simulations by running fitness evaluations and genetic operations in distinct microservices that communicate asynchronously through a central message broker. This mapping to separate hardware resources supports distributed execution across cloud and HPC environments. The framework demonstrates scalability with minimal overhead to over 3500 CPU cores in benchmarks and applies the approach to dispatch optimization of HVDC lines in the German transmission grid, showing seamless migration between orchestration systems and integration of multi-stage workflows.
What carries the argument
The microservice architecture coordinated by a central message broker that handles asynchronous manager-worker communication between separate fitness and genetic operation components.
If this is right
- The framework supports seamless migration from Kubernetes to SLURM environments without code changes.
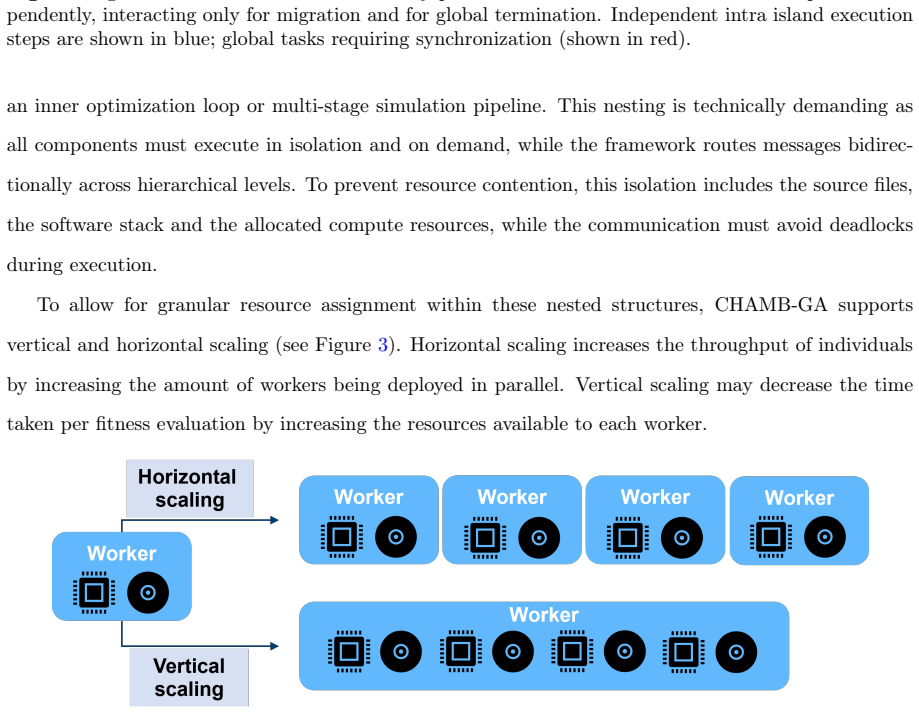
- It enables combined horizontal scaling across nodes and vertical scaling within nodes for optimization tasks.
- Users can integrate external tools and complex simulations by providing only the operator and backend modules.
- Evolutionary operations and fitness evaluations execute in parallel on distinct parts of the compute infrastructure.
Where Pith is reading between the lines
- The same decoupled microservice pattern could apply to other population-based metaheuristics that pair search operators with expensive simulations.
- Emphasis on reproducibility across environments may allow research groups to share complete optimization workflows more reliably.
- Support for multi-stage workflows suggests the design could handle sequential phases such as initialization followed by refinement in one deployment.
Load-bearing premise
Separating fitness evaluation and genetic operations into distinct microservices coordinated by a message broker will not create communication bottlenecks that prevent scaling when simulations are long-running and complex.
What would settle it
A scaling test that shows communication time through the message broker growing faster than the parallel speedup gained, or performance flattening or declining past a few thousand cores.
Figures

read the original abstract
Metaheuristic-based global optimization with embedded, long-running simulations is a computationally expensive process. To support various stages of development and execution, a seamless transition from personal computers to distributed clusters is desired, enabling execution across all computational scales. However, existing tool chains are often characterized by rigidity and hardware-bound constraints, which impede scalability and the integration of complex simulations. Bridging this gap, we present a containerized HPC scalable microservice-based framework for genetic algorithms with embedded simulations (CHAMB-GA). The deployment of the framework scales consistently across cloud infrastructure via container orchestration and HPC clusters via batch-scheduled parallel execution. Users provide the GA operators and simulation backend separately. The framework is designed to run these components in a distributed and decoupled manner, mapped to separate hardware. This approach ensures that the fitness evaluation and genetic operations are not managed within the same process and are utilizing distinct parts of the compute infrastructure. A central message broker coordinates asynchronous manager-worker communication between microservices, thereby parallelizing evolutionary operations and fitness evaluations. We demonstrate CHAMB-GA's scalability, portability, and reproducibility, while facilitating the integration of external tools and complex simulations on benchmark and powerflow problems. The capabilities of CHAMB-GA are validated in a two-part approach: (i) a benchmark study demonstrating minimal overhead while scaling to over 3,500 CPU cores, and (ii) a dispatch optimization of High Voltage Direct Current (HVDC) lines in the German transmission grid, showing seamless migration from Kubernetes to SLURM, combined horizontal and vertical scaling, and integration of multi-stage workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CHAMB-GA, a containerized microservice-based framework for genetic algorithms with embedded simulations. It decouples fitness evaluation and genetic operations into separate microservices coordinated asynchronously by a central message broker, enabling deployment on both Kubernetes-orchestrated cloud infrastructure and SLURM-scheduled HPC clusters. The central claims are consistent scalability with minimal overhead to over 3,500 CPU cores, portability across environments, reproducibility, and successful demonstration on synthetic benchmarks plus a real-world HVDC dispatch optimization problem in the German transmission grid.
Significance. If the scalability and overhead claims hold with quantitative support, the framework would provide a practical solution for running complex, simulation-embedded GAs across development-to-production scales without hardware-specific constraints, addressing a recognized gap in existing toolchains. The explicit separation of concerns, support for external tool integration, and two-part validation (benchmark + domain application) are constructive elements.
major comments (2)
- [Abstract] Abstract and validation description: the claim of 'minimal overhead' while scaling to over 3,500 CPU cores is load-bearing for the central contribution, yet no quantitative breakdown is provided of wall-clock time spent in message-broker communication, serialization, or queuing versus actual computation; without this metric the assertion that broker coordination does not dominate for long-running simulations cannot be evaluated.
- [Validation section] Two-part validation approach: the benchmark study and HVDC application report neither specific performance numbers (e.g., speedup curves, efficiency at each core count), error bars, nor direct comparison against a non-microservice baseline GA implementation, leaving the 'minimal overhead' and 'seamless migration' claims unsupported by data.
minor comments (1)
- The description of the microservice mapping and message-broker protocol would benefit from an explicit diagram or pseudocode listing the exact message types exchanged between manager and worker services.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger quantitative support of the scalability and overhead claims. We address each major comment below and commit to revisions that will improve the manuscript's rigor without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract and validation description: the claim of 'minimal overhead' while scaling to over 3,500 CPU cores is load-bearing for the central contribution, yet no quantitative breakdown is provided of wall-clock time spent in message-broker communication, serialization, or queuing versus actual computation; without this metric the assertion that broker coordination does not dominate for long-running simulations cannot be evaluated.
Authors: We agree that a quantitative breakdown of overhead components is required to substantiate the minimal-overhead claim for long-running simulations. In the revised manuscript we will add profiling measurements from the benchmark runs that report the wall-clock fractions spent in message-broker communication, serialization, and queuing versus computation. These data will be presented in a new table or subsection of the validation section and referenced from the abstract. revision: yes
-
Referee: [Validation section] Two-part validation approach: the benchmark study and HVDC application report neither specific performance numbers (e.g., speedup curves, efficiency at each core count), error bars, nor direct comparison against a non-microservice baseline GA implementation, leaving the 'minimal overhead' and 'seamless migration' claims unsupported by data.
Authors: We acknowledge that the validation section would be strengthened by explicit metrics. We will revise it to include speedup curves, parallel efficiency at each core count, and error bars derived from repeated runs. We will also add timing data demonstrating seamless migration between Kubernetes and SLURM. A direct comparison against a non-microservice baseline will be included where the necessary experimental data already exist; any limitations in scope will be stated explicitly. revision: partial
Circularity Check
No circularity: software framework with empirical demonstration only
full rationale
The paper presents CHAMB-GA, a containerized microservice framework for GA with embedded simulations. It describes architecture (separate microservices for GA operators and fitness, coordinated by message broker), deployment on Kubernetes/SLURM, and two-part validation: (i) benchmark scaling to >3500 cores with minimal overhead, (ii) HVDC dispatch optimization. No equations, parameters, predictions, or derivations are present. Claims rest on direct empirical runs and code portability, not on any reduction to fitted inputs or self-citations. The architecture description and scaling results are independent of any circular step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Container orchestration platforms and batch schedulers can deploy the same containerized microservices consistently across cloud and HPC environments
invented entities (1)
-
CHAMB-GA microservice framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
URL:https://gemfony-scientific.eu/
Geneva manual. URL:https://gemfony-scientific.eu/. (Accessed on: 2025-04-23). Biscani, F., Izzo, D.,
2025
-
[2]
A parallel global multiobjective framework for optimization: pagmo,
doi:10.21105/joss.02338. Böttcher, L., Wolf, H., Jung, B., Lutat, P., Trageser, M., Pohl, O., Tao, X., Ulbig, A., Grohe, M.,
-
[3]
Solving AC Power Flow with Graph Neural Networks under Realistic Constraints, in: 2023 IEEE Belgrade PowerTech, IEEE. pp. 1–7. doi:10.1109/PowerTech55446.2023.10202246. REFERENCES 20 Cant’u-Paz, E.,
-
[4]
A survey on handling computationally expen- sivemultiobjectiveoptimizationproblemswithevolutionaryalgorithms. SoftComputing23, 3137–3166. doi:10.1007/s00500-017-2965-0. De Rainville, F.M., Fortin, F.A., Gardner, M.A., Parizeau, M., Gagné, C.,
-
[5]
DEAP: A python framework for evolutionary algorithms, in: Proceedings of the 14th Annual Conference Companion on Genetic and Evolutionary Computation, ACM, Philadelphia Pennsylvania USA. pp. 85–92. doi:10. 1145/2330784.2330799. Deb, K., Pratap, A., Agarwal, S., Meyarivan, T.,
-
[6]
A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation 6, 182–197. doi:10.1109/4235.996017. Dibos, S., Pesch, T., Benigni, A.,
-
[7]
Heatnetsim: An open-source simulation tool for heating and cooling networks suitable for future energy systems. Energy 312, 133588. doi:https://doi.org/10. 1016/j.energy.2024.133588. Dongarra, J., Gunnels, J., Bayraktar, H., Haidar, A., Ernst, D.,
arXiv 2024
-
[8]
Hardwaretrendsimpactingfloating- point computations in scientific applications. doi:10.48550/arXiv.2411.12090,arXiv:2411.12090. Feix, O., Obermann, R., Hermann, M., Zelter, S.,
-
[9]
(Accessed on: 2026-03-27)
URL:https://www.netzentwicklungsplan.de/sites/default/files/paragraphs-files/ nep_2012_1_entwurf_teil_1_kap_1_bis_8.pdf. (Accessed on: 2026-03-27). Gong, Y.J., Chen, W.N., Zhan, Z.H., Zhang, J., Li, Y., Zhang, Q., Li, J.J.,
2026
-
[10]
Applied Soft Computing 34, 286–300
Distributed evolutionary algorithms and their models: A survey of the state-of-the-art. Applied Soft Computing 34, 286–300. doi:10.1016/j.asoc.2015.04.061. Ivanovic, M., Simic, V.,
-
[11]
Applied Soft Computing 129, 109610
Efficient evolutionary optimization using predictive auto-scaling in con- tainerized environment. Applied Soft Computing 129, 109610. doi:10.1016/j.asoc.2022.109610. Izzo, D., Ruciński, M., Biscani, F.,
-
[12]
(Eds.), Parallel Architectures and Bioinspired Algorithms
The Generalized Island Model, in: Fernández De Vega, F., Hidalgo Pérez, J.I., Lanchares, J. (Eds.), Parallel Architectures and Bioinspired Algorithms. Springer Berlin Heidelberg, Berlin, Heidelberg. volume 415, pp. 151–169. doi:10.1007/978-3-642-28789-3_7. REFERENCES 21 Jin, Y., Olhofer, M., Sendhoff, B.,
-
[13]
A framework for evolutionary optimization with approximate fitness functions. IEEE Transactions on Evolutionary Computation 6, 481–494. doi:10.1109/TEVC. 2002.800884. Jülich Supercomputing Centre,
-
[14]
URL:https://apps.fz-juelich.de/jsc/hps/jureca/index.html
Jureca user documentation — jureca user documentation docu- mentation. URL:https://apps.fz-juelich.de/jsc/hps/jureca/index.html. (Accessed on: 2025- 08-04). Kaushik, E., Prakash, V., Mahela, O.P., Khan, B., Abdelaziz, A.Y., Hong, J., Geem, Z.W.,
2025
- [15]
-
[16]
A generic flexible and scalable framework for hierarchical parallelization of population-based metaheuristics. Internet of Things 16, 100433. doi:10.1016/j.iot.2021.100433. Kurtzer, G.M., Cclerget, Bauer, M., Kaneshiro, I., Trudgian, D., Godlove, D.,
-
[17]
Hpcng/singularity: Singularity 3.7.3. Zenodo. doi:10.5281/ZENODO.4667718. Lu, Y., Pesch, T., Benigni, A.,
-
[18]
GasNetSim: An Open-Source Package for Gas Network Simulation with Complex Gas Mixture Compositions, in: 2022 Open Source Modelling and Simulation of Energy Systems (OSMSES), IEEE, Aachen, Germany. pp. 1–6. doi:10.1109/OSMSES54027.2022.9769148. Ma, Z., Guo, H., Gong, Y.J., Zhang, J., Tan, K.C.,
-
[19]
IEEE Transactions on Evolutionary Computation 30, 667–687
Toward Automated Algorithm Design: A Survey and Practical Guide to Meta-Black-Box-Optimization. IEEE Transactions on Evolutionary Computation 30, 667–687. doi:10.1109/TEVC.2025.3568053. Mallipeddi, R., Suganthan, P.N.,
-
[20]
Empirical study on the effect of population size on differential evolution algorithm, in: 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence), IEEE, Hong Kong, China. pp. 3663–3670. doi:10.1109/CEC.2008. 4631294. Maqbool, F., Razzaq, S., Lehmann, J., Jabeen, H.,
-
[21]
(Eds.), Intelligent Comput- ing Theories and Application
Scalable distributed genetic algorithm using apache spark (s-ga), in: Huang, D.S., Bevilacqua, V., Premaratne, P. (Eds.), Intelligent Comput- ing Theories and Application. Springer International Publishing, Cham. volume 11643, pp. 424–435. doi:10.1007/978-3-030-26763-6_41. REFERENCES 22 Mcluckie, C.,
-
[22]
URL:https: //cloudplatform.googleblog.com/2014/08/containers-vms-kubernetes-and-vmware.html
Google cloud platform blog: Containers, vms, kubernetes and vmware. URL:https: //cloudplatform.googleblog.com/2014/08/containers-vms-kubernetes-and-vmware.html. (Accessed on: 2025-07-21). Merelo Guervós, J.J., García-Valdez, J.M.,
2014
-
[23]
(Eds.), Parallel Problem Solving from Nature – PPSN XV
Introducing an event-based architecture for concurrent and distributed evolutionary algorithms, in: Auger, A., Fonseca, C.M., Lourenço, N., Machado, P., Pa- quete, L., Whitley, D. (Eds.), Parallel Problem Solving from Nature – PPSN XV. Springer International Publishing, Cham. volume 11101, pp. 399–410. doi:10.1007/978-3-319-99253-2_32. Merkel, D.,
-
[24]
IEEE Transactions on Smart Grid 8, 2941–2962
A Survey of Distributed Optimization and Control Algorithms for Electric Power Systems. IEEE Transactions on Smart Grid 8, 2941–2962. doi:10.1109/TSG.2017.2720471. Pesch, T.C.,
-
[25]
Multiskalare Modellierung integrierter Energie- und Elektrizitätssysteme. Disser- tation. RWTH Aachen University. Jülich. doi:10.18154/RWTH-2020-00990. Druckausgabe:
-
[26]
URL:https://github.com/rabbitmq/ rabbitmq-server
Rabbitmq/rabbitmq-server. URL:https://github.com/rabbitmq/ rabbitmq-server. (Accessed on: 2026-03-17). RabbitMQ,
2026
-
[27]
URL:https://www.rabbitmq
Rabbitmq: One broker to queue them all | rabbitmq. URL:https://www.rabbitmq. com/. (Accessed on: 2025-05-27). Salza, P.,
2025
-
[28]
URL:https://github.com/pasqualesalza/elephant56
Pasqualesalza/elephant56. URL:https://github.com/pasqualesalza/elephant56. (Accessed on: 2025-05-15). Salza, P., Ferrucci, F.,
2025
-
[29]
Future Generation Computer Systems 92, 276–289
Speed up genetic algorithms in the cloud using software containers. Future Generation Computer Systems 92, 276–289. doi:10.1016/j.future.2018.09.066. Sherry, D., Veeramachaneni, K., McDermott, J., O’Reilly, U.M.,
-
[30]
IEEE Transactions on Control of Network Systems 6, 1004–1014
A Hierarchical Optimization Architecture for Large- Scale Power Networks. IEEE Transactions on Control of Network Systems 6, 1004–1014. doi:10.1109/ TCNS.2019.2906917. Stenman, E.,
arXiv 2019
-
[31]
URL:https://top500.org/statistics/ perfdevel/
Performance development |top500. URL:https://top500.org/statistics/ perfdevel/. (Accessed on: 2025-04-23). Vecchiola, C., Kirley, M., Buyya, R.,
2025
-
[32]
URL:https://arxiv.org/abs/0903.1386,arXiv:0903.1386
Multi-objective problem solving with offspring on enterprise clouds. URL:https://arxiv.org/abs/0903.1386,arXiv:0903.1386. Weßner, J., Berlich, R., Schwarz, K., Lutz, M.F.M.,
-
[33]
Yoo, A.B., Jette, M.A., Grondona, M.,
doi:10.1007/s41781-023-00098-6. Yoo, A.B., Jette, M.A., Grondona, M.,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.