LMs as Task-Specific Knowledge Bases: An Interpretability Analysis
Pith reviewed 2026-06-26 04:12 UTC · model grok-4.3
The pith
Language models encode the same fact using different parameters depending on the task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
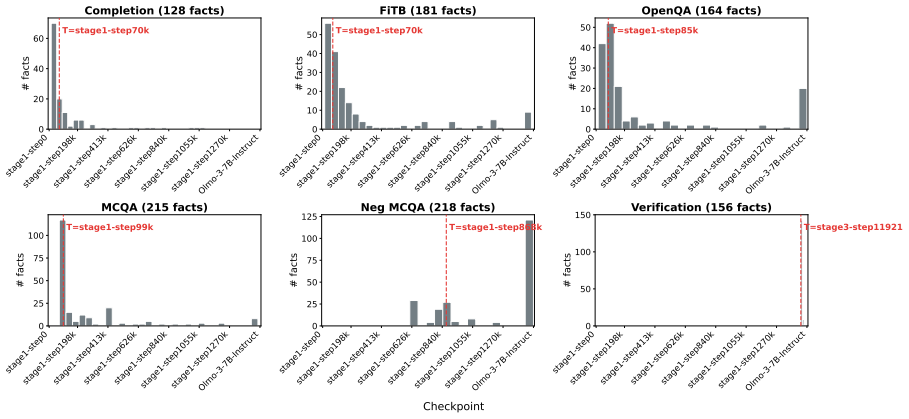
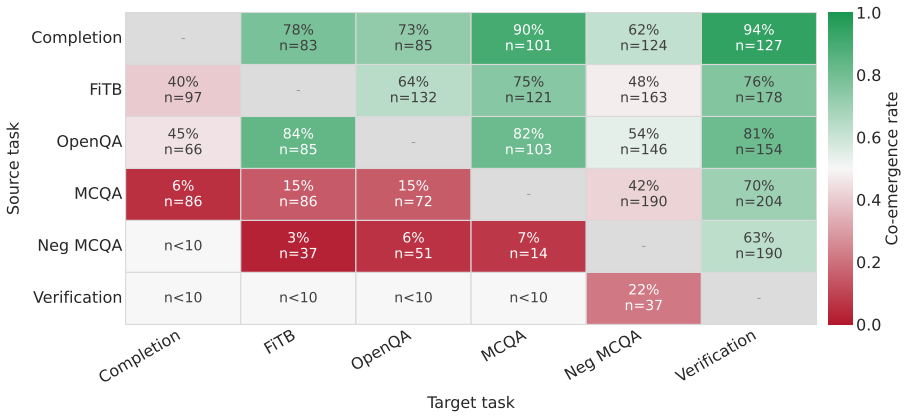
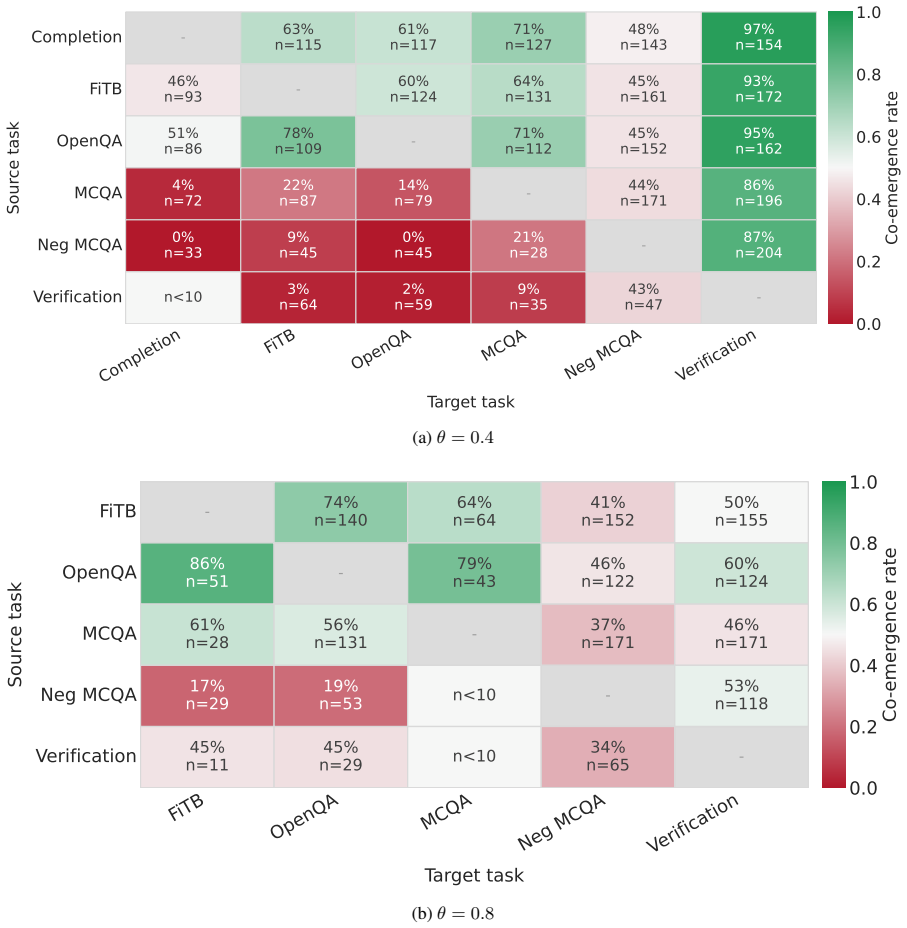
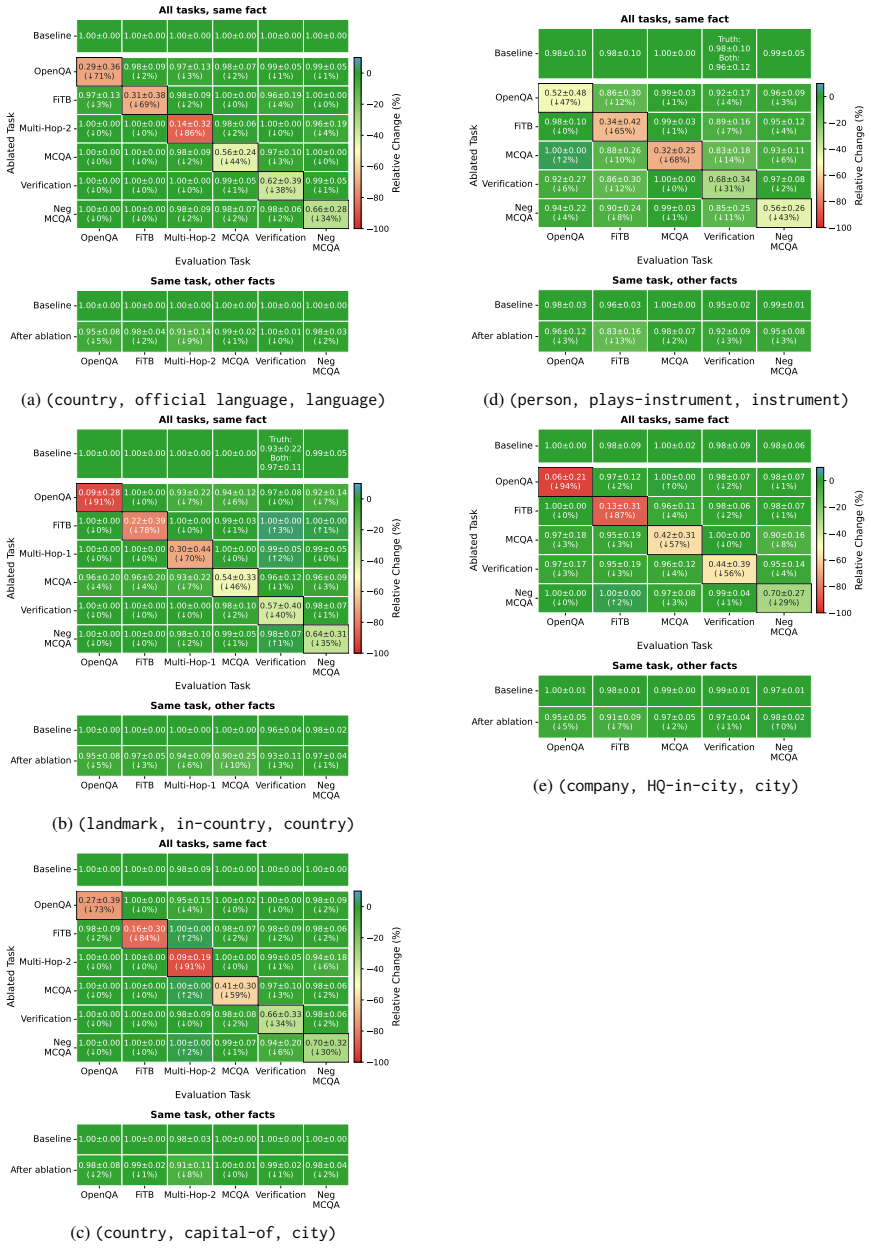
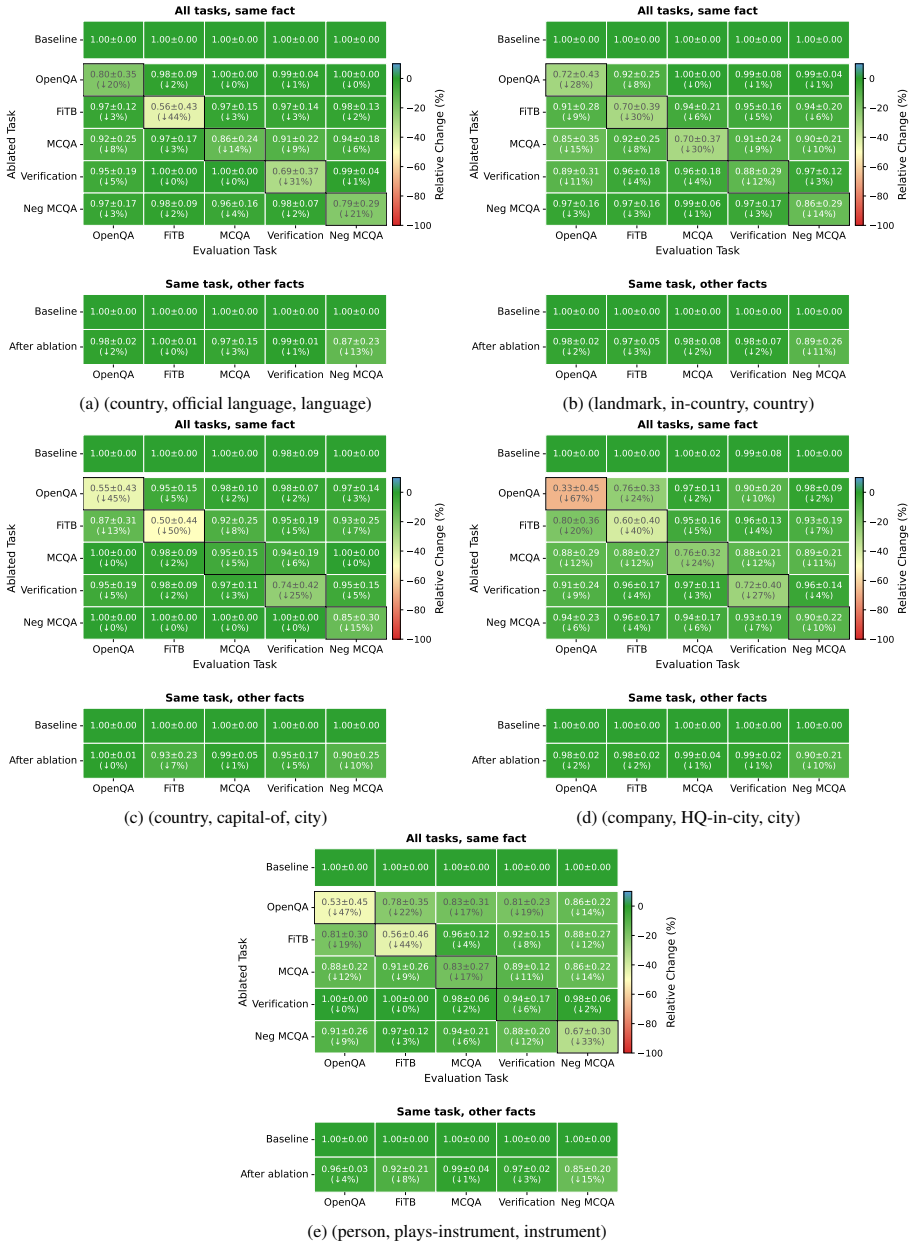
Language models encode knowledge in a task-specific manner. Behaviorally, facts acquired on one task frequently fail to co-emerge on others during training. Parameter localization experiments reveal distinct parameter subsets underlying different tasks for the same fact. Chain-of-thought reasoning draws part of its effectiveness from engaging task-specific parameters beyond those tied to the evaluation task. The findings indicate that what the model knows and how it is asked are intertwined in parameter space, undermining the knowledge base analogy.
What carries the argument
Task-specific parameter subsets that store the same fact under different query conditions.
If this is right
- Facts learned on one task do not reliably transfer to other tasks during training.
- Different tasks for the same fact rely on non-overlapping parameter groups.
- Chain-of-thought benefits arise from recruiting additional task-specific parameters.
- Factual knowledge in models cannot be treated as a single unified source.
- Reliability and controllability of facts depend on the task used to query them.
Where Pith is reading between the lines
- Knowledge editing methods may need to modify multiple disjoint parameter sets to update a fact consistently across tasks.
- Training objectives that explicitly encourage parameter sharing could reduce task-specific fragmentation.
- The pattern raises the possibility that larger models will continue to encode knowledge in task-dependent ways unless training explicitly counters it.
- Task-specific parameter localization could enable selective control over which facts are accessible under which conditions.
Load-bearing premise
The selected tasks and training dynamics are representative enough that failure of facts to co-emerge reflects task-specific parameter encoding rather than differences in task difficulty or optimization paths.
What would settle it
Finding that the same fact consistently activates overlapping parameters across a broad set of tasks and models during localization experiments would contradict the task-specific encoding claim.
Figures



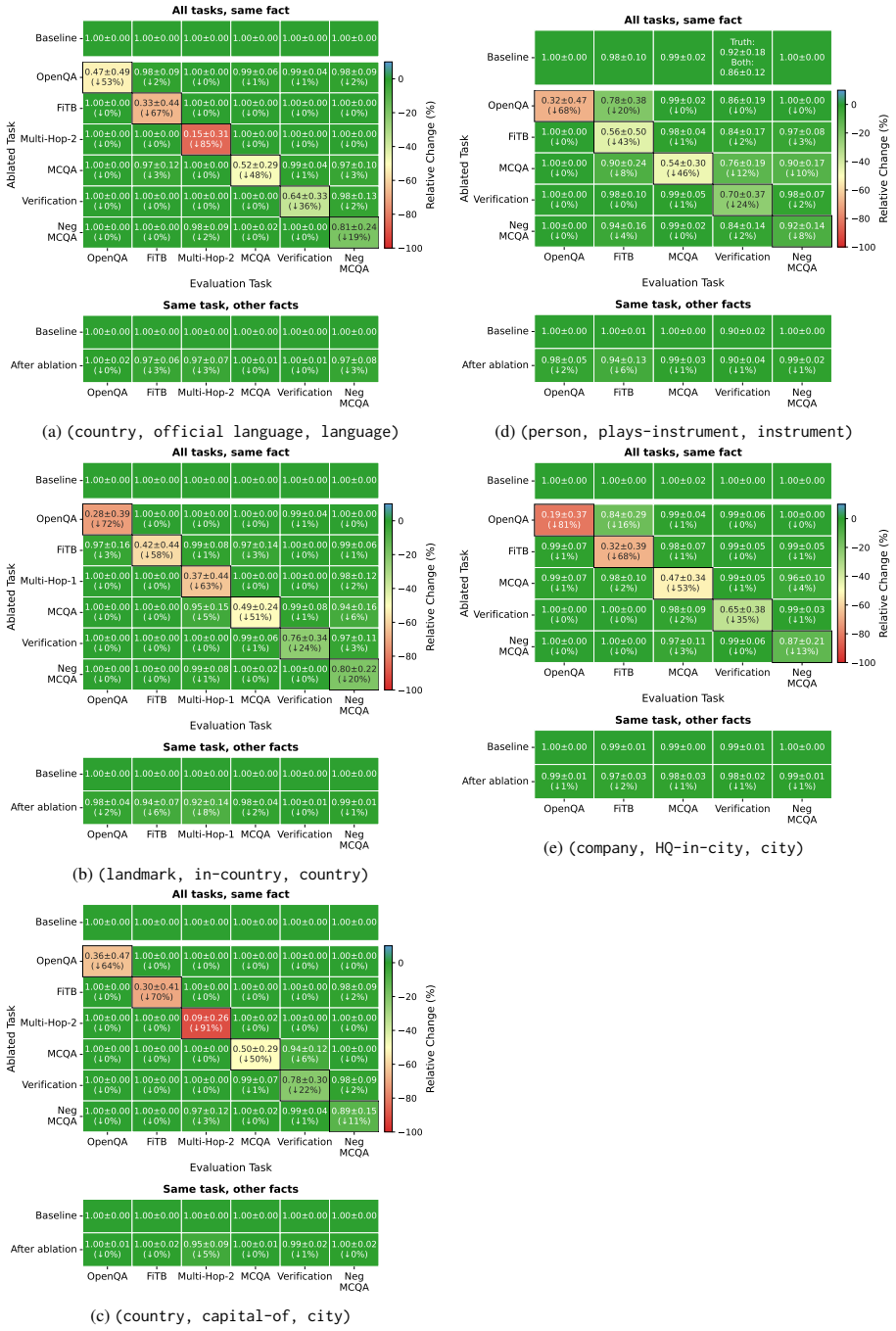


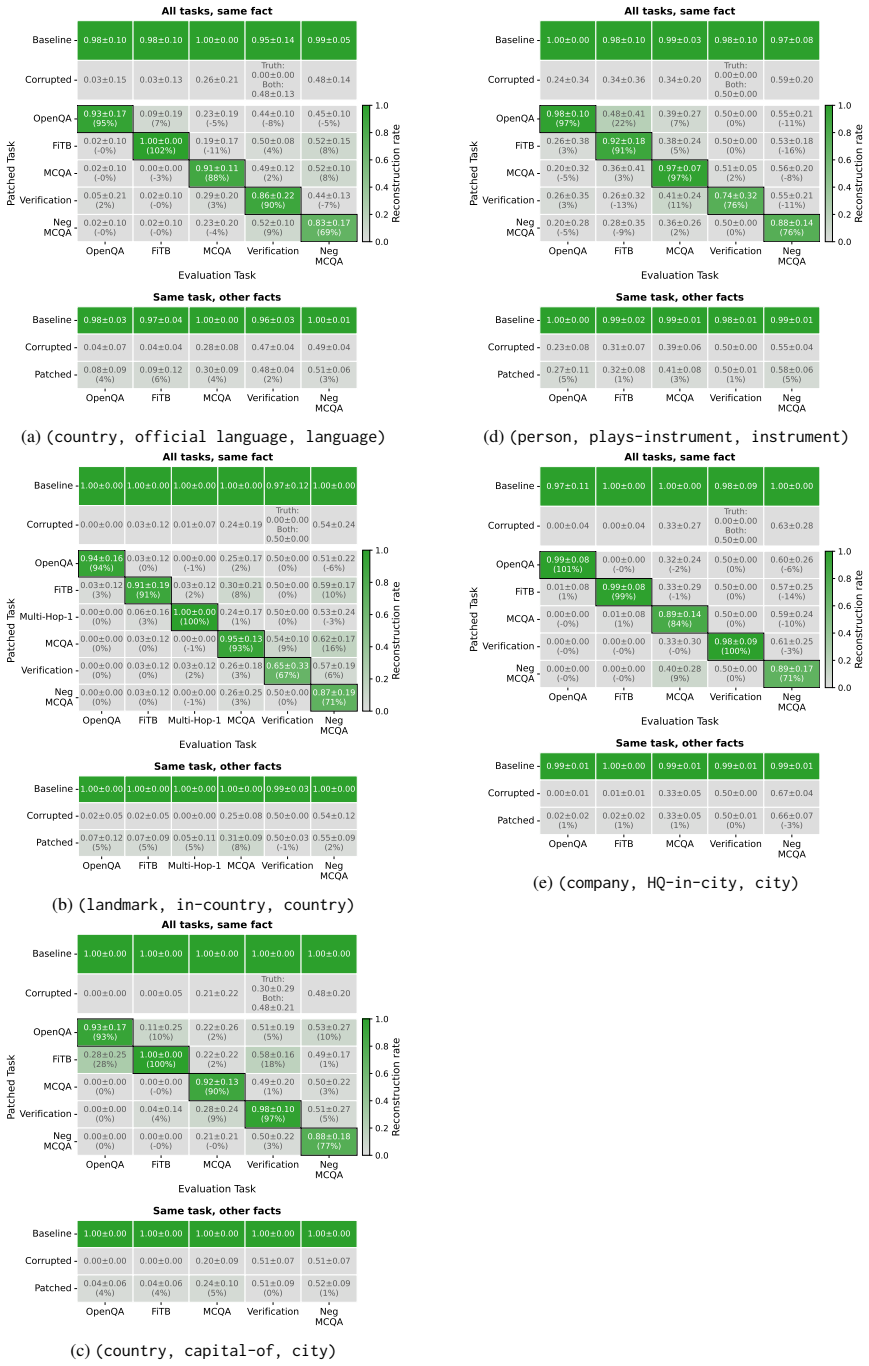
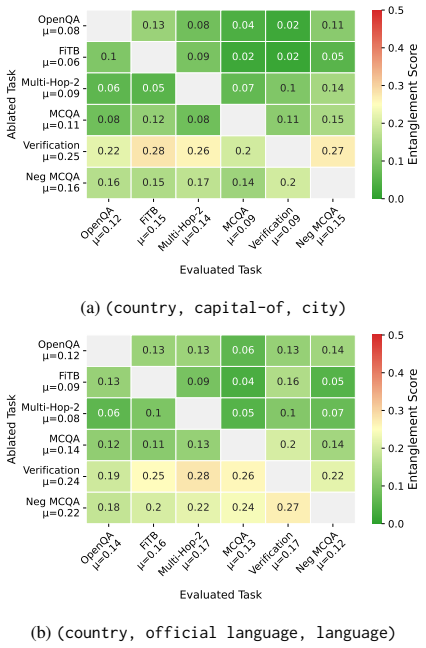
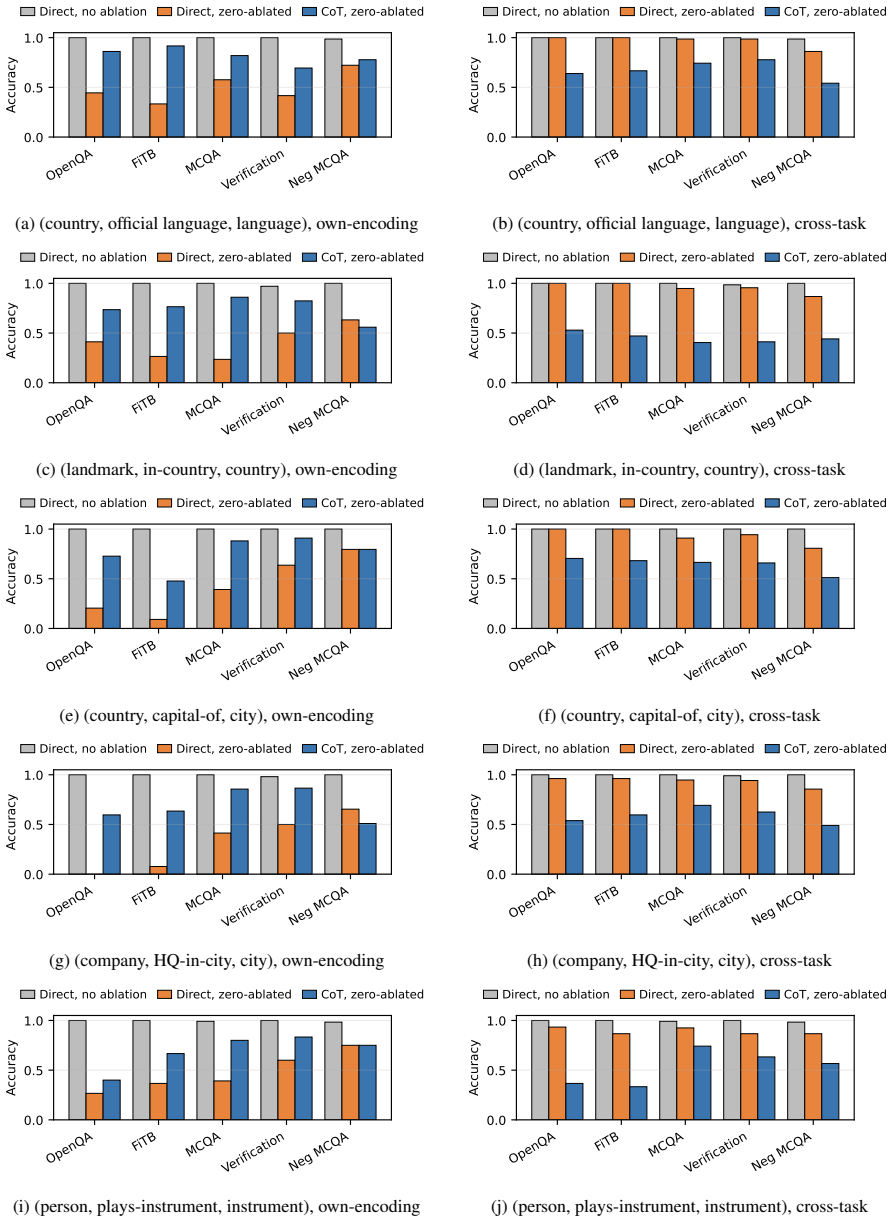
read the original abstract
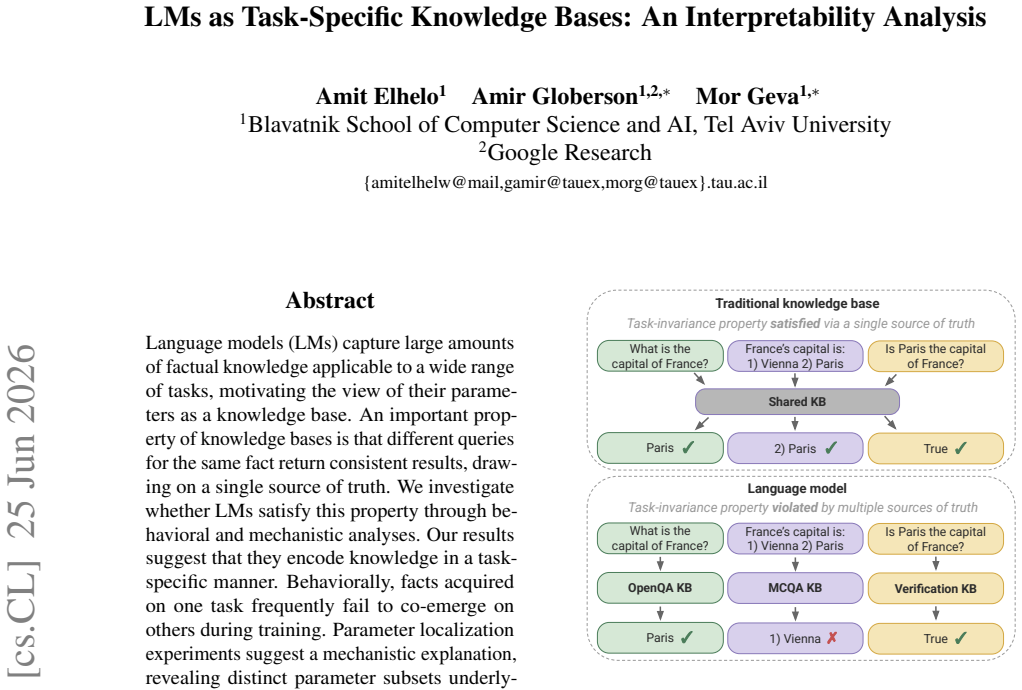
Language models (LMs) capture large amounts of factual knowledge applicable to a wide range of tasks, motivating the view of their parameters as a knowledge base. An important property of knowledge bases is that different queries for the same fact return consistent results, drawing on a single source of truth. We investigate whether LMs satisfy this property through behavioral and mechanistic analyses. Our results suggest that they encode knowledge in a task-specific manner. Behaviorally, facts acquired on one task frequently fail to co-emerge on others during training. Parameter localization experiments suggest a mechanistic explanation, revealing distinct parameter subsets underlying different tasks for the same fact. Finally, we show that chain-of-thought reasoning draws part of its effectiveness from engaging task-specific parameters beyond those tied to the evaluation task. Our findings suggest that what the model knows and how it is asked are intertwined in parameter space, undermining the "knowledge base" analogy and carrying implications for the reliability and controllability of factual knowledge in LMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that language models encode factual knowledge in a task-specific manner rather than as a unified, task-agnostic knowledge base. Behavioral experiments show that facts acquired during training on one task frequently fail to co-emerge when the model is evaluated on other tasks. Parameter localization identifies distinct subsets of parameters supporting the same fact under different tasks. An additional analysis indicates that chain-of-thought reasoning benefits from engaging parameters beyond those tied to the direct evaluation task. These observations are taken to undermine the knowledge-base analogy and to have implications for reliability and controllability of factual outputs.
Significance. If the central claims survive controls for task difficulty and optimization confounds, the work would meaningfully advance LM interpretability by supplying both behavioral and mechanistic evidence that factual recall is entangled with task formulation in parameter space. The training-dynamics approach and the extension to chain-of-thought are constructive contributions that could inform knowledge-editing methods and prompt design. The paper does not supply machine-checked proofs or parameter-free derivations, but the empirical framing is falsifiable in principle.
major comments (2)
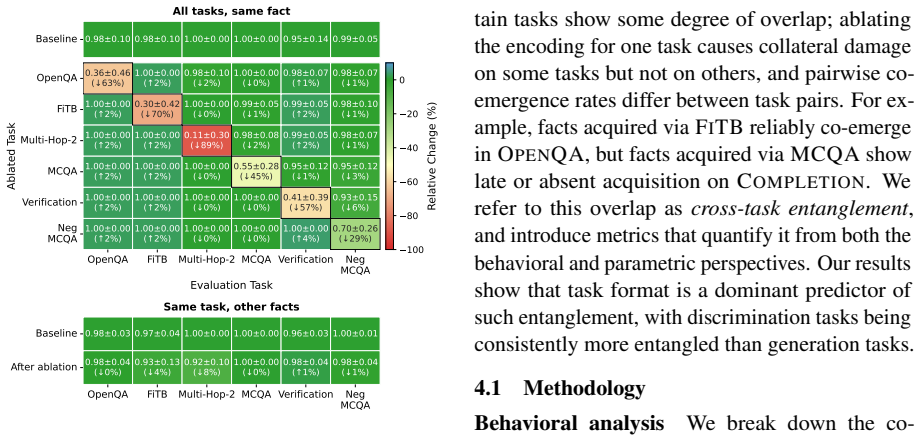
- [§3] §3 (behavioral analysis): the claim that non-co-emergence of the same fact across tasks indicates task-specific parameter encoding rests on the assumption that the chosen tasks are comparable in difficulty and optimization trajectory. No matched accuracy curves, synthetic controls, or difficulty metrics are reported that would rule out the alternative that differences in learning speed or loss landscapes, rather than distinct fact-specific parameters, drive the observed divergence.
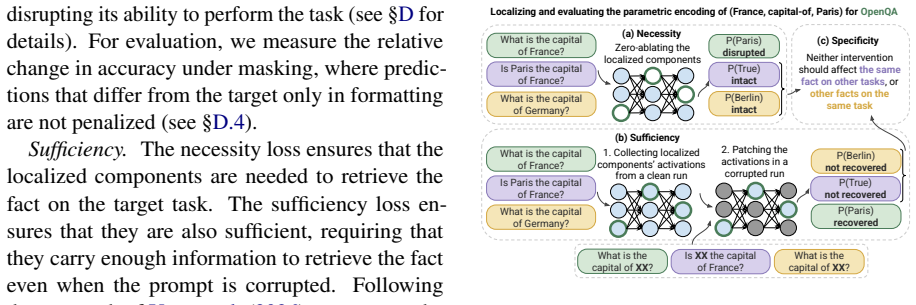
- [§4] §4 (parameter localization): the localization procedure identifies subsets whose ablation affects task performance, yet it is not demonstrated that these subsets are independent of task-specific optimization paths or that ablating them selectively impairs the underlying fact across all tasks. Without such a dissociation, the mechanistic interpretation that distinct parameter subsets underlie the same fact remains under-supported.
minor comments (2)
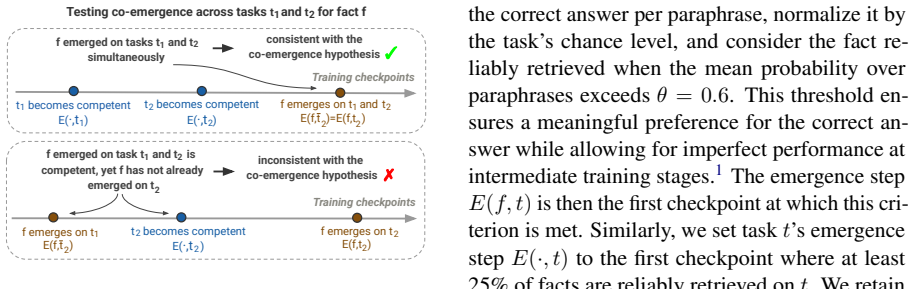
- [Figures 1-3] Figure captions and legends should explicitly define the quantitative criterion used for 'co-emergence' (e.g., accuracy threshold and time window) so that the behavioral plots can be interpreted without reference to the main text.
- [§4] Notation for the localization metric (e.g., the precise definition of the importance score) would benefit from an explicit equation or pseudocode block.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important considerations for strengthening the behavioral and mechanistic claims. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [§3] §3 (behavioral analysis): the claim that non-co-emergence of the same fact across tasks indicates task-specific parameter encoding rests on the assumption that the chosen tasks are comparable in difficulty and optimization trajectory. No matched accuracy curves, synthetic controls, or difficulty metrics are reported that would rule out the alternative that differences in learning speed or loss landscapes, rather than distinct fact-specific parameters, drive the observed divergence.
Authors: We selected tasks from established benchmarks with comparable final accuracies and similar input/output formats to mitigate difficulty confounds, and the non-co-emergence pattern holds across multiple random seeds. However, we acknowledge the absence of explicit matched accuracy curves, synthetic controls, or quantitative difficulty metrics. In the revision we will add these: per-task accuracy trajectories plotted against training steps, a synthetic dataset variant controlling for loss landscape properties, and a difficulty metric based on token-level perplexity. These additions will directly test whether divergence arises from task-specific parameter encoding rather than optimization differences. revision: yes
-
Referee: [§4] §4 (parameter localization): the localization procedure identifies subsets whose ablation affects task performance, yet it is not demonstrated that these subsets are independent of task-specific optimization paths or that ablating them selectively impairs the underlying fact across all tasks. Without such a dissociation, the mechanistic interpretation that distinct parameter subsets underlie the same fact remains under-supported.
Authors: The localization relies on task-conditioned attribution followed by ablation that impairs fact recall only under the original task formulation. We agree that full dissociation from optimization trajectories and cross-task selectivity has not been shown. In revision we will add (i) localization repeated under alternative optimizers and learning-rate schedules to check trajectory dependence, and (ii) cross-task ablation experiments measuring whether parameters localized for task A impair the same fact when evaluated on task B. These controls will be reported with quantitative effect sizes. revision: yes
Circularity Check
No circularity: claims rest on direct experimental observations without derivations or fitted predictions.
full rationale
The paper presents behavioral results from training dynamics (facts failing to co-emerge across tasks) and parameter localization experiments as evidence for task-specific encoding. These are empirical measurements, not mathematical derivations, predictions from fitted parameters, or self-citation chains. No equations, ansatzes, or uniqueness theorems are invoked that reduce to inputs by construction. The central interpretation follows from the observed data rather than being forced by prior self-referential steps. This is self-contained experimental work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Interpretability in the Wild: a Circuit for Indirect Object Identification in
Kevin Ro Wang and Alexandre Variengien and Arthur Conmy and Buck Shlegeris and Jacob Steinhardt , bibsource =. Interpretability in the Wild: a Circuit for Indirect Object Identification in. The Eleventh International Conference on Learning Representations,
-
[2]
The Twelfth International Conference on Learning Representations , year=
Circuit Component Reuse Across Tasks in Transformer Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[3]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Discovering knowledge-critical subnetworks in pretrained language models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[4]
Chen, Yuheng and Cao, Pengfei and Chen, Yubo and Wang, Yining and Liu, Shengping and Liu, Kang and Zhao, Jun. Cracking Factual Knowledge: A Comprehensive Analysis of Degenerate Knowledge Neurons in Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2...
-
[5]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Journey to the center of the knowledge neurons: Discoveries of language-independent knowledge neurons and degenerate knowledge neurons , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[6]
Language models as knowledge bases? , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[7]
Intrinsic Test of Unlearning Using Parametric Knowledge Traces
Hong, Yihuai and Yu, Lei and Yang, Haiqin and Ravfogel, Shauli and Geva, Mor. Intrinsic Test of Unlearning Using Parametric Knowledge Traces. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.985
-
[8]
arXiv preprint arXiv:2512.05648 , year=
Beyond Data Filtering: Knowledge Localization for Capability Removal in LLMs , author=. arXiv preprint arXiv:2512.05648 , year=
-
[9]
ArXiv , year=
Measuring Massive Multitask Language Understanding , author=. ArXiv , year=
-
[10]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle =. Scalable training of
-
[11]
Algorithms on Strings, Trees and Sequences , year =
Dan Gusfield , publisher =. Algorithms on Strings, Trees and Sequences , year =
-
[12]
Tetreault , journal =
Mohammad Sadegh Rasooli and Joel R. Tetreault , journal =. Yara Parser:
-
[13]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , volume =
Ando, Rie Kubota and Zhang, Tong , issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , volume =. Journal of Machine Learning Research , numpages =
-
[14]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[15]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[16]
Ruslan Salakhutdinov , bibsource =. Deep learning , url =. The 20th. doi:10.1145/2623330.2630809 , editor =
-
[17]
A mathematical framework for transformer circuits , volume =
Elhage, Nelson and Nanda, Neel and Olsson, Catherine and Henighan, Tom and Joseph, Nicholas and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and Conerly, Tom and others , journal =. A mathematical framework for transformer circuits , volume =
-
[18]
Gomez and Lukasz Kaiser and Illia Polosukhin , bibsource =
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , bibsource =. Attention is All you Need , url =. Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA,
2017
-
[19]
Analyzing Transformers in Embedding Space
Dar, Guy and Geva, Mor and Gupta, Ankit and Berant, Jonathan , booktitle =. Analyzing Transformers in Embedding Space , url =. doi:10.18653/v1/2023.acl-long.893 , editor =
-
[20]
nostalgebraist , title =
-
[21]
The Twelfth International Conference on Learning Representations , year=
Successor Heads: Recurring, Interpretable Attention Heads In The Wild , author=. The Twelfth International Conference on Learning Representations , year=
-
[22]
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space
Geva, Mor and Caciularu, Avi and Wang, Kevin and Goldberg, Yoav , booktitle =. Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space , url =. doi:10.18653/v1/2022.emnlp-main.3 , editor =
-
[23]
Wikidata: A Free Collaborative Knowledgebase , url =
Vrande. Wikidata: a free collaborative knowledgebase , url =. Commun. ACM , number =. doi:10.1145/2629489 , issn =
-
[24]
The Twelfth International Conference on Learning Representations , year=
Linearity of Relation Decoding in Transformer Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[25]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov , bibsource =. Locating and Editing Factual Associations in. Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022 , editor =
2022
-
[26]
doi:10.3115/1118108.1118117 , pages =
Loper, Edward and Bird, Steven , booktitle =. doi:10.3115/1118108.1118117 , pages =
-
[27]
Ghandeharioun, A., Caciularu, A., Pearce, A., Dixon, L., and Geva, M
Geva, Mor and Schuster, Roei and Berant, Jonathan and Levy, Omer , booktitle =. Transformer Feed-Forward Layers Are Key-Value Memories , url =. doi:10.18653/v1/2021.emnlp-main.446 , editor =
work page internal anchor Pith review doi:10.18653/v1/2021.emnlp-main.446 2021
-
[28]
Backward Lens: Projecting Language Model Gradients into the Vocabulary Space
Katz, Shahar and Belinkov, Yonatan and Geva, Mor and Wolf, Lior. Backward Lens: Projecting Language Model Gradients into the Vocabulary Space. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.142
-
[29]
Dissecting Recall of Factual Associations in Auto-Regressive Language Models
Geva, Mor and Bastings, Jasmijn and Filippova, Katja and Globerson, Amir , booktitle =. Dissecting Recall of Factual Associations in Auto-Regressive Language Models , url =. doi:10.18653/v1/2023.emnlp-main.751 , editor =
-
[30]
McDougall, Callum Stuart and Conmy, Arthur and Rushing, Cody and McGrath, Thomas and Nanda, Neel. Copy Suppression: Comprehensively Understanding a Motif in Language Model Attention Heads. Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2024. doi:10.18653/v1/2024.blackboxnlp-1.22
-
[31]
Attention Heads of Large Language Models: A Survey , url =
Zheng, Zifan and Wang, Yezhaohui and Huang, Yuxin and Song, Shichao and Tang, Bo and Xiong, Feiyu and Li, Zhiyu , journal =. Attention Heads of Large Language Models: A Survey , url =
-
[32]
In-context learning and induction heads , url =
Olsson, Catherine and Elhage, Nelson and Nanda, Neel and Joseph, Nicholas and DasSarma, Nova and Henighan, Tom and Mann, Ben and Askell, Amanda and Bai, Yuntao and Chen, Anna and others , journal =. In-context learning and induction heads , url =
-
[33]
ArXiv preprint , title =
Ferrando, Javier and Sarti, Gabriele and Bisazza, Arianna and Costa-juss. ArXiv preprint , title =
-
[34]
ArXiv preprint , title =
Kim, Geonhee and Valentino, Marco and Freitas, Andr. ArXiv preprint , title =
-
[35]
How does
Jorge Garc. How does. International Conference on Artificial Intelligence and Statistics, 2-4 May 2024, Palau de Congressos, Valencia, Spain , editor =
2024
-
[36]
Beren Millidge and Sid Black , title =
-
[37]
TransformerLens , year =
Neel Nanda and Joseph Bloom , howpublished =. TransformerLens , year =
-
[38]
doi: 10.18653/v1/2020.emnlp-demos.6
Wolf, Thomas and Debut, Lysandre and Sanh, Victor and Chaumond, Julien and Delangue, Clement and Moi, Anthony and Cistac, Pierric and Rault, Tim and Louf, Remi and Funtowicz, Morgan and Davison, Joe and Shleifer, Sam and von Platen, Patrick and Ma, Clara and Jernite, Yacine and Plu, Julien and Xu, Canwen and Le Scao, Teven and Gugger, Sylvain and Drame, M...
-
[39]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Talking Heads: Understanding Inter-Layer Communication in Transformer Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[40]
On the Role of Attention Heads in Large Language Model Safety , url =
Zhou, Zhenhong and Yu, Haiyang and Zhang, Xinghua and Xu, Rongwu and Huang, Fei and Wang, Kun and Liu, Yang and Fang, Junfeng and Li, Yongbin , journal =. On the Role of Attention Heads in Large Language Model Safety , url =
-
[41]
ArXiv preprint , title =
Bolukbasi, Tolga and Pearce, Adam and Yuan, Ann and Coenen, Andy and Reif, Emily and Vi. ArXiv preprint , title =
-
[42]
ArXiv preprint , title =
Gao, Leo and la Tour, Tom Dupr. ArXiv preprint , title =
-
[43]
ICML 2024 Workshop on Mechanistic Interpretability , year=
Interpreting Attention Layer Outputs with Sparse Autoencoders , author=. ICML 2024 Workshop on Mechanistic Interpretability , year=
2024
-
[44]
The llama 3 herd of models , url =
Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Yang, Amy and Fan, Angela and others , journal =. The llama 3 herd of models , url =
-
[45]
Stella Biderman and Hailey Schoelkopf and Quentin Gregory Anthony and Herbie Bradley and Kyle O'Brien and Eric Hallahan and Mohammad Aflah Khan and Shivanshu Purohit and USVSN Sai Prashanth and Edward Raff and Aviya Skowron and Lintang Sutawika and Oskar van der Wal , bibsource =. Pythia:. International Conference on Machine Learning,
-
[46]
Language models are unsupervised multitask learners , volume =
Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya and others , journal =. Language models are unsupervised multitask learners , volume =
-
[47]
Mojan Javaheripi and Sébastien Bubeck , title =
-
[48]
Gpt-4o system card , url =
Hurst, Aaron and Lerer, Adam and Goucher, Adam P and Perelman, Adam and Ramesh, Aditya and Clark, Aidan and Ostrow, AJ and Welihinda, Akila and Hayes, Alan and Radford, Alec and others , journal =. Gpt-4o system card , url =
-
[49]
Voita, Elena and Talbot, David and Moiseev, Fedor and Sennrich, Rico and Titov, Ivan , booktitle =. Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned , url =. doi:10.18653/v1/P19-1580 , editor =
-
[50]
Efficient Streaming Language Models with Attention Sinks , url =
Guangxuan Xiao and Yuandong Tian and Beidi Chen and Song Han and Mike Lewis , booktitle =. Efficient Streaming Language Models with Attention Sinks , url =
-
[51]
Schwarte , journal =
Patrick Schober and Christa Boer and Lothar A. Schwarte , journal =. Correlation Coefficients: Appropriate Use and Interpretation , url =
-
[52]
GQA : Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
Ainslie, Joshua and Lee-Thorp, James and de Jong, Michiel and Zemlyanskiy, Yury and Lebron, Federico and Sanghai, Sumit , booktitle =. doi:10.18653/v1/2023.emnlp-main.298 , editor =
-
[53]
Proceedings of the 1st International Workshop on Feature Extraction: Modern Questions and Challenges at NIPS 2015 , pages =
Convergent Learning: Do different neural networks learn the same representations? , author =. Proceedings of the 1st International Workshop on Feature Extraction: Modern Questions and Challenges at NIPS 2015 , pages =. 2015 , editor =
2015
-
[54]
arXiv preprint arXiv:2406.11717 , year=
Refusal in language models is mediated by a single direction , author=. arXiv preprint arXiv:2406.11717 , year=
-
[55]
Forty-first International Conference on Machine Learning , year=
Patchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Models , author=. Forty-first International Conference on Machine Learning , year=
-
[56]
What Does BERT Look at? An Analysis of BERT ' s Attention
Clark, Kevin and Khandelwal, Urvashi and Levy, Omer and Manning, Christopher D. What Does BERT Look at? An Analysis of BERT ' s Attention. Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. 2019. doi:10.18653/v1/W19-4828
-
[57]
Analyzing the Structure of Attention in a Transformer Language Model
Vig, Jesse and Belinkov, Yonatan. Analyzing the Structure of Attention in a Transformer Language Model. Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP. 2019. doi:10.18653/v1/W19-4808
-
[58]
Jump to Conclusions: Short-Cutting Transformers with Linear Transformations
Yom Din, Alexander and Karidi, Taelin and Choshen, Leshem and Geva, Mor. Jump to Conclusions: Short-Cutting Transformers with Linear Transformations. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024
2024
-
[59]
2024 , url=
Curt Tigges and Michael Hanna and Qinan Yu and Stella Biderman , booktitle=. 2024 , url=
2024
-
[60]
Ethayarajh, Kawin. How Contextual are Contextualized Word Representations? C omparing the Geometry of BERT , ELM o, and GPT -2 Embeddings. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1006
-
[61]
The Eleventh International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. The Eleventh International Conference on Learning Representations , year=
-
[62]
The Internal State of an LLM Knows When It ' s Lying
Azaria, Amos and Mitchell, Tom. The Internal State of an LLM Knows When It`s Lying. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.68
-
[63]
Anisotropy Is Inherent to Self-Attention in Transformers
Godey, Nathan and Clergerie, \'E ric and Sagot, Beno \^ t. Anisotropy Is Inherent to Self-Attention in Transformers. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
2024
-
[64]
Mechanistic Understanding and Mitigation of Language Model Non-Factual Hallucinations
Yu, Lei and Cao, Meng and Cheung, Jackie CK and Dong, Yue. Mechanistic Understanding and Mitigation of Language Model Non-Factual Hallucinations. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.466
-
[65]
arXiv preprint arXiv:2501.08319 , year=
Enhancing Automated Interpretability with Output-Centric Feature Descriptions , author=. arXiv preprint arXiv:2501.08319 , year=
-
[66]
arXiv preprint arXiv:2212.08037 , year=
Attributed question answering: Evaluation and modeling for attributed large language models , author=. arXiv preprint arXiv:2212.08037 , year=
-
[67]
arXiv preprint arXiv:2506.20746 , year=
Multiple Streams of Relation Extraction: Enriching and Recalling in Transformers , author=. arXiv preprint arXiv:2506.20746 , year=
-
[68]
On Relation-Specific Neurons in Large Language Models
Liu, Yihong and Chen, Runsheng and Hirlimann, Lea and Hakimi, Ahmad Dawar and Wang, Mingyang and Kargaran, Amir Hossein and Rothe, Sascha and Yvon, Fran c ois and Schuetze, Hinrich. On Relation-Specific Neurons in Large Language Models. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.52
-
[69]
arXiv preprint arXiv:2406.15940 , year=
Beyond Individual Facts: Investigating Categorical Knowledge Locality of Taxonomy and Meronomy Concepts in GPT Models , author=. arXiv preprint arXiv:2406.15940 , year=
-
[70]
Advances in Neural Information Processing Systems , volume=
Knowledge circuits in pretrained transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[71]
arXiv preprint arXiv:2505.16178 , year=
Understanding Fact Recall in Language Models: Why Two-Stage Training Encourages Memorization but Mixed Training Teaches Knowledge , author=. arXiv preprint arXiv:2505.16178 , year=
-
[72]
The Thirteenth International Conference on Learning Representations , year=
The Unreasonable Ineffectiveness of the Deeper Layers , author=. The Thirteenth International Conference on Learning Representations , year=
-
[73]
Forty-second International Conference on Machine Learning , year=
Extractive Structures Learned in Pretraining Enable Generalization on Finetuned Facts , author=. Forty-second International Conference on Machine Learning , year=
-
[74]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
The Rise of Parameter Specialization for Knowledge Storage in Large Language Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[75]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Do all autoregressive transformers remember facts the same way? a cross-architecture analysis of recall mechanisms , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[76]
2024 , eprint=
Summing Up the Facts: Additive Mechanisms Behind Factual Recall in LLMs , author=. 2024 , eprint=
2024
-
[77]
On the Representations of Entities in Auto-regressive Large Language Models
Morand, Victor and Mothe, Josiane and Piwowarski, Benjamin. On the Representations of Entities in Auto-regressive Large Language Models. Proceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP. 2025. doi:10.18653/v1/2025.blackboxnlp-1.25
-
[78]
Alignment Forum , author=
Fact Finding: Attempting to Reverse-Engineer Factual Recall on the Neuron Level , url=. Alignment Forum , author=. 2023 , month=
2023
-
[79]
S hort GPT : Layers in Large Language Models are More Redundant Than You Expect
Men, Xin and Xu, Mingyu and Zhang, Qingyu and Yuan, Qianhao and Wang, Bingning and Lin, Hongyu and Lu, Yaojie and Han, Xianpei and Chen, Weipeng. S hort GPT : Layers in Large Language Models are More Redundant Than You Expect. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.1035
-
[80]
Advances in neural information processing systems , volume=
How do large language models acquire factual knowledge during pretraining? , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.