Beyond Surface Forms: A Comprehensive, Mechanism-Oriented Taxonomy of Indirect Linguistic Encoding for LLM-Based Coded Language Detection
Pith reviewed 2026-06-26 03:57 UTC · model grok-4.3
The pith
A mechanism-oriented taxonomy of indirect linguistic encoding improves LLM detection of coded social media language over existing methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present a comprehensive taxonomy of indirect linguistic encoding centered on mechanisms such as substitution, abbreviation, and contextual inference. When this taxonomy guides LLM prompts, it achieves the best document-level and span-level detection results, with 4.7 percent higher accuracy and 5.4 percent higher F1 score than the strongest benchmark taxonomy on the annotated dataset.
What carries the argument
The mechanism-oriented taxonomy, which groups indirect expressions by the operations through which meaning is encoded and recovered.
If this is right
- The taxonomy serves as a stable scaffold for detecting emerging coded language.
- It supplies a useful input to content moderation pipelines.
- Gains appear consistently across three LLMs at both document and span levels.
- Abstracting away from communicative goals yields broader applicability than intent-based alternatives.
Where Pith is reading between the lines
- The same mechanism categories could be applied to posts from additional platforms to test cross-site consistency.
- Embedding the taxonomy in real-time moderation systems might lower missed detections of novel euphemisms.
- Automated extraction of new mechanism instances from fresh data could keep the taxonomy current without full re-annotation.
Load-bearing premise
The 2,000 manually annotated posts from TikTok and Bluesky provide reliable ground truth labels for both document-level and span-level presence of indirect linguistic expressions.
What would settle it
A new collection of social media posts where an LLM prompted with the proposed taxonomy fails to exceed the accuracy or F1 of the best benchmark taxonomy would falsify the performance advantage.
Figures


read the original abstract
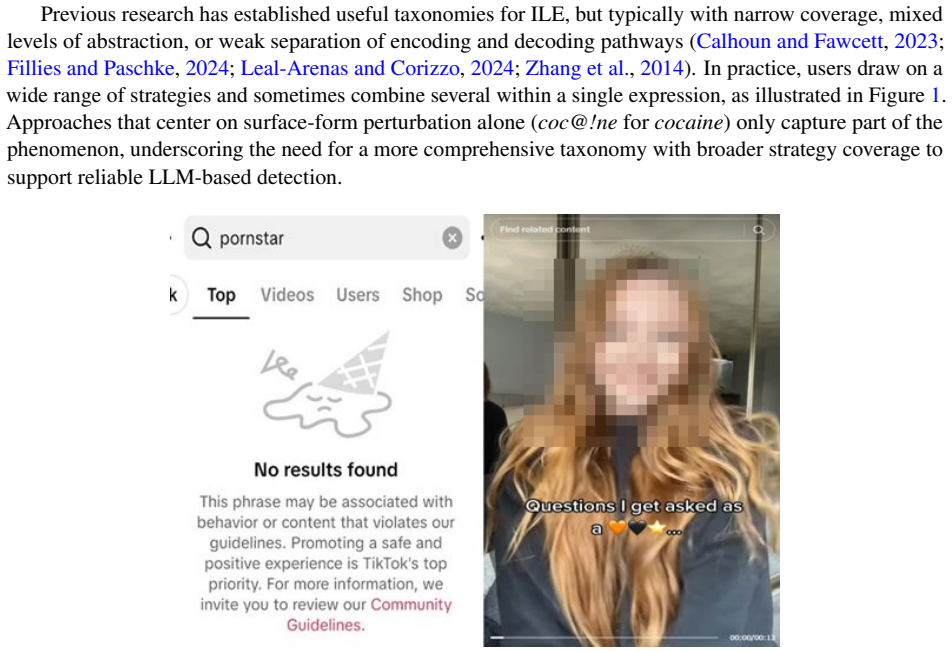
To avoid moderation and surveillance on social media, some users routinely invent indirect linguistic expressions (ILE) that camouflage sensitive meanings. Such expressions surface as algospeak, euphemisms, and adversarial obfuscation, depending on intent and context, and they involve recurring encoding mechanisms. We propose a comprehensive, mechanism-oriented taxonomy of ILE that abstracts away from communicative goals and instead categorizes the underlying operations through which meaning is encoded and recovered. We evaluate the taxonomy by incorporating it into LLM prompts and comparing it with four existing taxonomies and a no-taxonomy baseline, using 2,000 manually annotated TikTok and Bluesky posts. The proposed taxonomy attains the strongest document- and span-level performance across the three LLMs, achieving an improvement of 4.7% in accuracy and 5.4% in F1 over the best-performing benchmark. The empirical results reveal the importance of a comprehensive, mechanism-oriented taxonomy as a stable scaffold for detecting emerging coded language and a useful input to content moderation. Disclaimer: This paper contains content that may be profane, vulgar, or offensive.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a mechanism-oriented taxonomy of indirect linguistic expressions (ILE) that categorizes encoding operations rather than communicative goals. It integrates the taxonomy into LLM prompts and evaluates it against four existing taxonomies and a no-taxonomy baseline on 2,000 manually annotated TikTok and Bluesky posts, reporting that the new taxonomy yields the best document- and span-level performance across three LLMs with gains of 4.7% accuracy and 5.4% F1 over the strongest benchmark.
Significance. If the ground-truth labels are reliable, the taxonomy could provide a stable, mechanism-focused scaffold for detecting emerging coded language and support content moderation. The work is strengthened by its direct empirical comparisons and focus on abstraction from surface forms. However, the absence of any reported validation for the annotations substantially limits the strength of the performance claims and their generalizability.
major comments (1)
- [Evaluation] Evaluation section (dataset and annotation description): All reported performance gains (4.7% accuracy, 5.4% F1) rest exclusively on the 2,000 manually annotated posts as ground truth for both document- and span-level tasks. No inter-annotator agreement statistics, annotation protocol, number of annotators, span-boundary guidelines, or external validation are provided. This is load-bearing for the central claim; without these details, the observed advantage over the four benchmarks could be an artifact of labeling inconsistencies rather than a property of the taxonomy.
minor comments (1)
- [Abstract] Abstract: the disclaimer regarding profane content is present but could usefully note the specific platforms and annotation scope for reader context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation section. We address the major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (dataset and annotation description): All reported performance gains (4.7% accuracy, 5.4% F1) rest exclusively on the 2,000 manually annotated posts as ground truth for both document- and span-level tasks. No inter-annotator agreement statistics, annotation protocol, number of annotators, span-boundary guidelines, or external validation are provided. This is load-bearing for the central claim; without these details, the observed advantage over the four benchmarks could be an artifact of labeling inconsistencies rather than a property of the taxonomy.
Authors: We agree that the absence of detailed annotation information limits the interpretability of the reported gains and that these details are essential to substantiate the ground-truth reliability. The current manuscript provides only a high-level mention of the 2,000 manually annotated posts without describing the protocol, annotator count, IAA metrics, span guidelines, or validation steps. In the revised version we will add a dedicated subsection to the Evaluation section that fully documents the annotation process, including these elements, to allow readers to assess whether the taxonomy-driven improvements are robust to labeling variation. revision: yes
Circularity Check
No circularity: evaluation rests on external annotations and independent benchmarks
full rationale
The paper introduces a mechanism-oriented taxonomy and evaluates it by embedding the taxonomy into LLM prompts, then measuring document- and span-level accuracy/F1 on 2,000 manually annotated TikTok/Bluesky posts against four existing taxonomies plus a no-taxonomy baseline. No equations, fitted parameters, or self-citation chains are described that would reduce the reported 4.7% accuracy / 5.4% F1 gains to the paper's own inputs by construction. The central empirical claim is therefore measured against externally supplied ground truth and independent comparator taxonomies, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The manually annotated dataset accurately represents instances of indirect linguistic encoding at document and span levels.
Reference graph
Works this paper leans on
-
[1]
Robert C Nickerson, Upkar Varshney, and Jan Muntermann
The emerging science of content labeling: Contextualizing social media content moderation.Journal of the Association for Information Science and Technology, 73(10):1365–1386. Robert C Nickerson, Upkar Varshney, and Jan Muntermann. 2013. A method for taxonomy development and its application in information systems.European Journal of Information Systems, 22...
arXiv 2013
-
[2]
Orthographic Transformation Visual Similarity Substi- tution A target expression is altered by replacing one or more letters with visually similar characters, numbers, or symbols, while preserving the word’s ordinary reading orientation. w33d→weed Inversion Based Glyph Encoding A target expression is encoded using numbers or glyphs whose meaning becomes r...
-
[3]
seggs→sex not see→Nazi Alphanumeric Rebus Letters or numbers are used for their phonetic value to rep- resent sounds, syllables, or words in the target expression
Phonetic Substitution Near Homophone Drift A lexical substitute approximates the sound of a target ex- pression while altering its spelling or lexical form. seggs→sex not see→Nazi Alphanumeric Rebus Letters or numbers are used for their phonetic value to rep- resent sounds, syllables, or words in the target expression. CU46 → see you for sex Phonological ...
-
[4]
Formal Compression Initialism Acronym A multiword target expression is compressed by retaining the initial letters, or a pronounceable subset, of its compo- nent words. SH→self-harm DV → Domestic Vio- lence Lexical Clipping A single lexical item is shortened by removing one or more segments while preserving a recognizable fragment that stands for the full...
-
[5]
Formal Encoding Systems Classical Cipher A target expression is transformed using an established cipher or cryptographic rule, producing an encoded form that requires applying the corresponding inverse procedure to decode. fhvpvqr → suicide (ROT13) Textual Algorithmic En- coding A target expression is encoded through an explicit rule ap- plied to letters,...
-
[6]
Conventional Sign Reassignment Lexical Reassignment An ordinary lexical item acquires a stable coded meaning by convention, without relying on visual, phonetic, or algo- rithmic transformation. accountant → sex worker Conventional Numeric Symbol Reassignment A number or symbol is assigned a stable coded meaning through social convention rather than a dete...
-
[7]
Morpho-lexical Encoding Blending A coded expression is formed by merging parts of two or more lexical items into a single new form, so that the source words remain partially recoverable. covidiot → COVID + id- iot Affix Manipulation A target expression is modified by adding productive pre- fixes, suffixes, or bound morphemes, creating a derived form whose...
-
[8]
Referential Alias Encoding Attribute Based Alias An indirect label that refers to a specific entity through a salient attribute, such as appearance, color, role, function, ownership, reputation, or platform design. the bald billionaire → Jeff Bezos orange-and-black YouTube→Pornhub Pseudonymous Labeling A substitute name, nickname, or moniker assigned to a...
-
[9]
Semantic Circumlocution Euphemism A socially softer, less explicit, or less stigmatized expression replaces a direct taboo or sensitive term. passed away→died spicy content → pornog- raphy Periphrasis A target concept is expressed through a longer descriptive phrase that identifies it by its function, effect, or associated activity rather than naming it d...
-
[10]
Metaphorical and Metonymic Encoding Continued on next page 18 Sub-mechanism Definition Examples Metaphorical Mapping A target concept is encoded through a source-domain ex- pression whose perceived qualities, appearance, function, or symbolic associations resemble the target. snow→cocaine taco→female genitalia Metonymic Encoding A target concept is encode...
-
[11]
Pictorial and Symbolic Encoding Referential Iconicity A pictorial symbol or emoji encodes a target meaning be- cause its visual appearance directly resembles, depicts, or conventionally symbolizes the referent. →cannabis →butt Eventive Iconicity A pictorial symbol or symbol combination encodes a target action, event, or practice by depicting an object, bo...
-
[12]
Cross-linguistic Transformation Translation Based En- coding A target expression is replaced with its equivalent or near- equivalent in another language, allowing the sensitive mean- ing to be concealed from audiences or systems that primarily process the original language. muerte→death; chudai→sex/fucking Script Transliteration En- coding A target expres...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.