When are likely answers right? On Sequence Probability and Correctness in LLMs
Pith reviewed 2026-06-26 01:53 UTC · model grok-4.3
The pith
Sequence probability predicts correctness across prompt-answer pairs in a dataset but not when changing decoding methods or within responses to one prompt.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
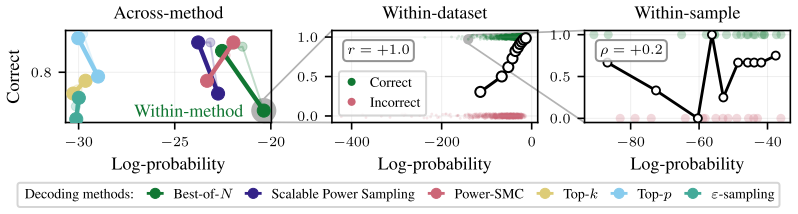
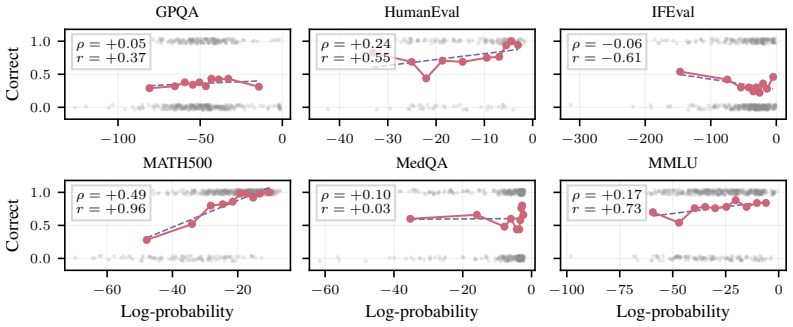
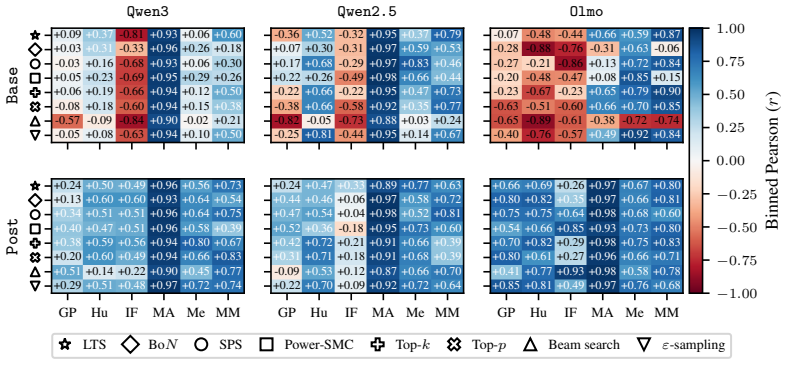
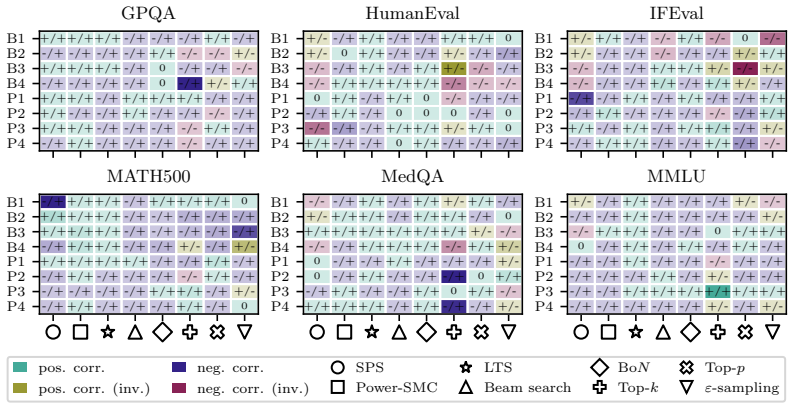
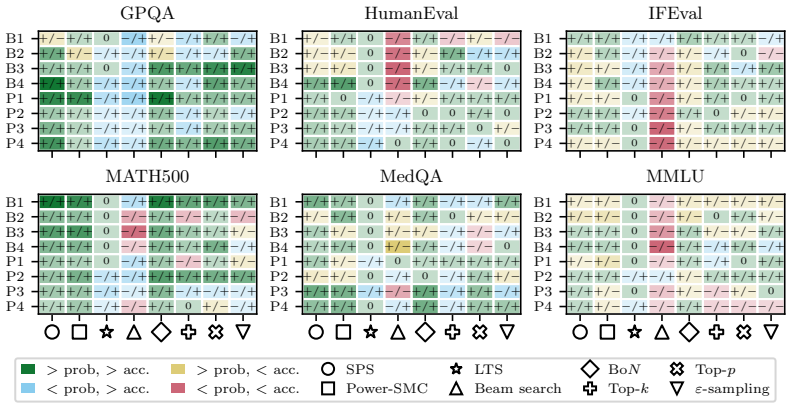
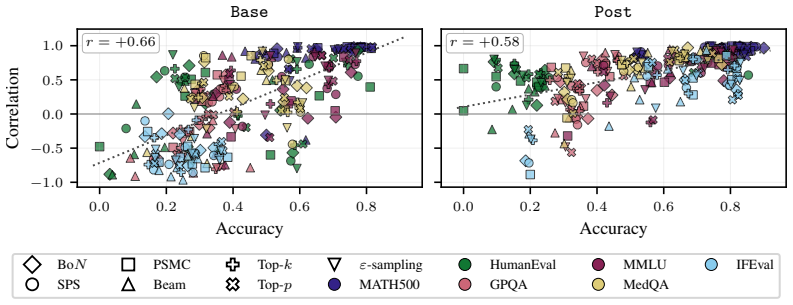
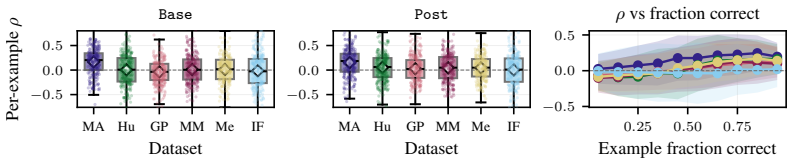
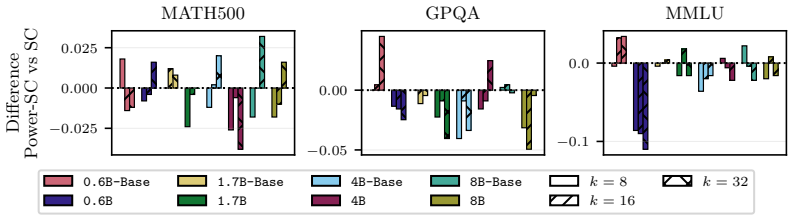
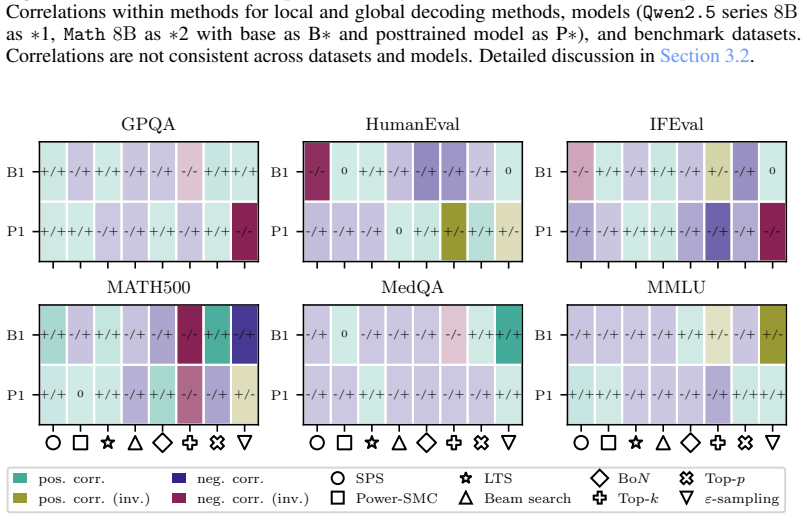
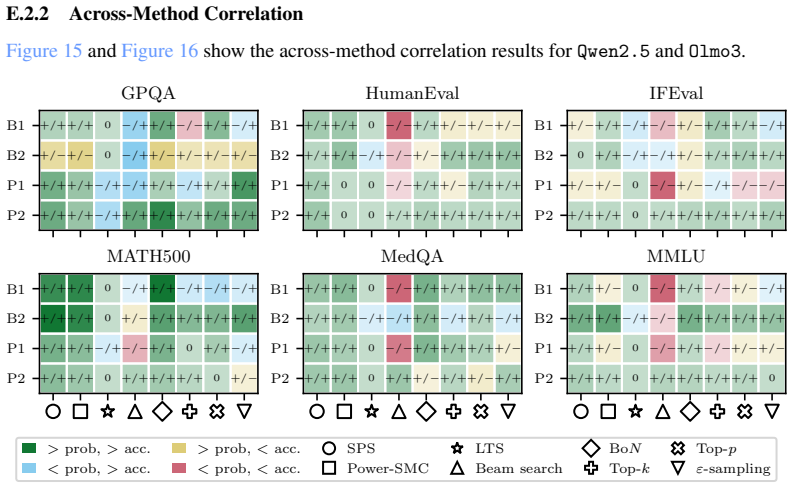
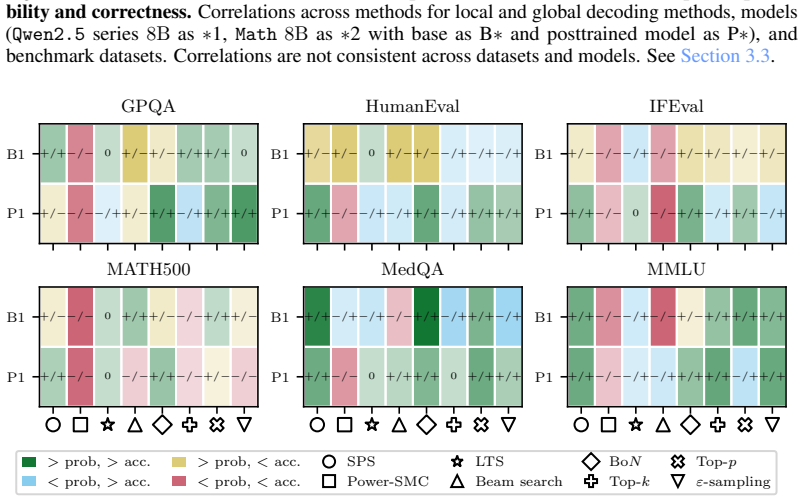
The paper establishes that sequence probability aligns with correctness when comparing different prompt-answer pairs inside one dataset, yet this alignment does not extend to choices made by varying decoding hyperparameters or methods, nor does it hold for selecting among responses to a single prompt.
What carries the argument
Sequence probability (the model's conditional probability of an entire continuation given the prompt) and its measured correlation with correctness at four distinct levels of comparison.
If this is right
- Decoding methods that increase sequence probability cannot be assumed to raise accuracy.
- Hyperparameter changes that raise sequence probability do not reliably improve performance.
- Sequence probability cannot be used to pick the correct answer among multiple generations for the same prompt.
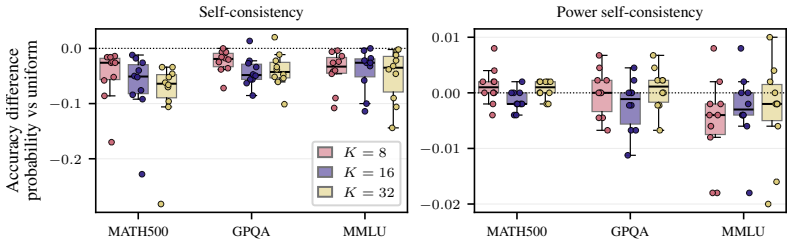
- Self-consistency and verifier-free self-improvement techniques that rely on probability need to account for these limits.
Where Pith is reading between the lines
- Training objectives that directly encourage probability to track correctness may be needed rather than relying on post-training decoding adjustments.
- Signals other than sequence probability, such as cross-sample consistency, could be combined with or replace probability for answer selection.
- Dataset-specific thresholds on probability might still allow rough correctness prediction even if they do not guide decoding.
Load-bearing premise
The models, benchmarks, and decoding methods tested are representative enough that the observed probability-correctness patterns apply beyond the specific cases examined.
What would settle it
A controlled experiment in which a new decoding method or hyperparameter setting raises sequence probability on multiple benchmarks and also raises accuracy would falsify the claim that such increases do not reliably improve correctness.
Figures





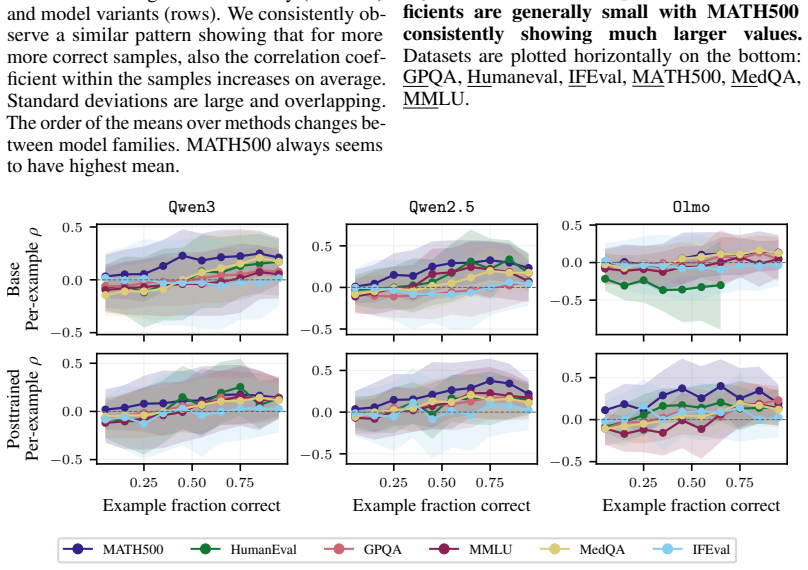
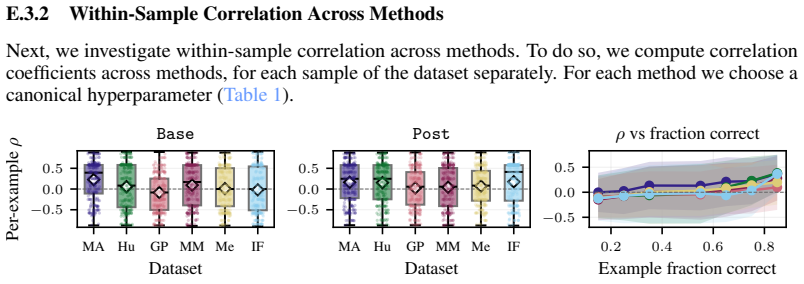
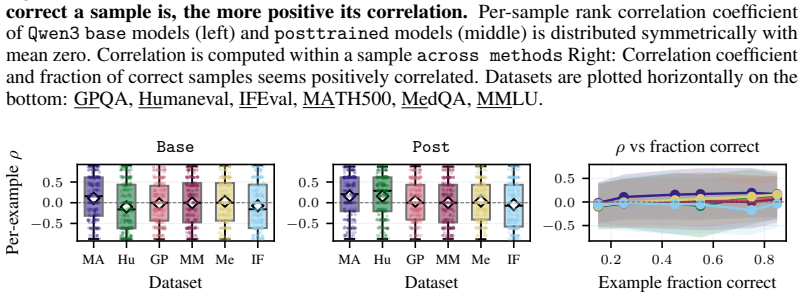
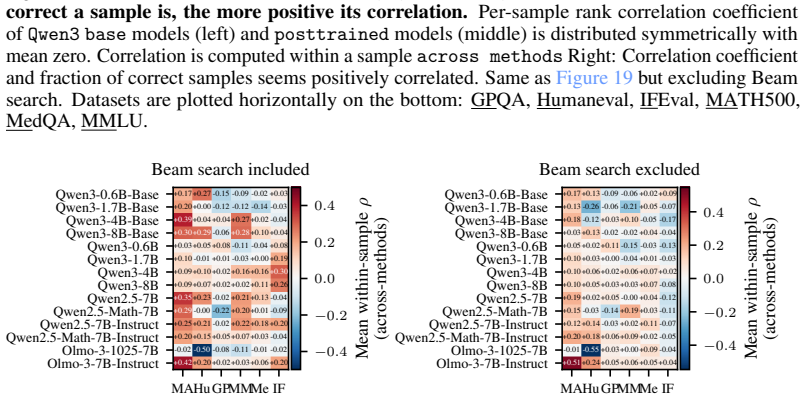
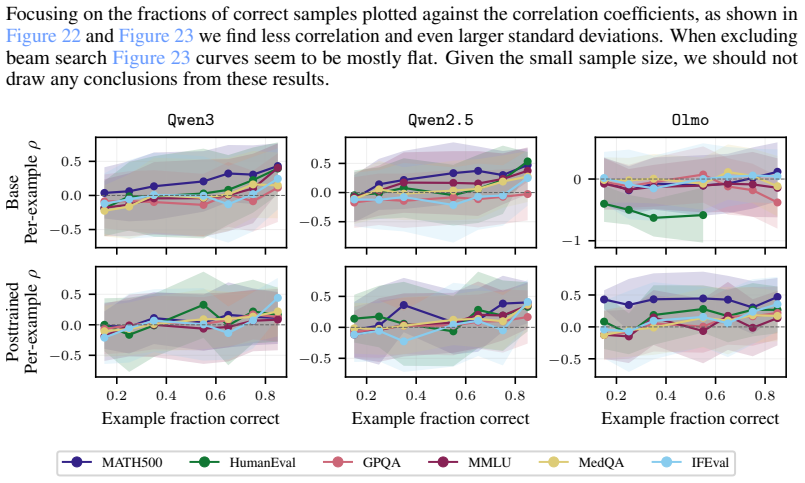
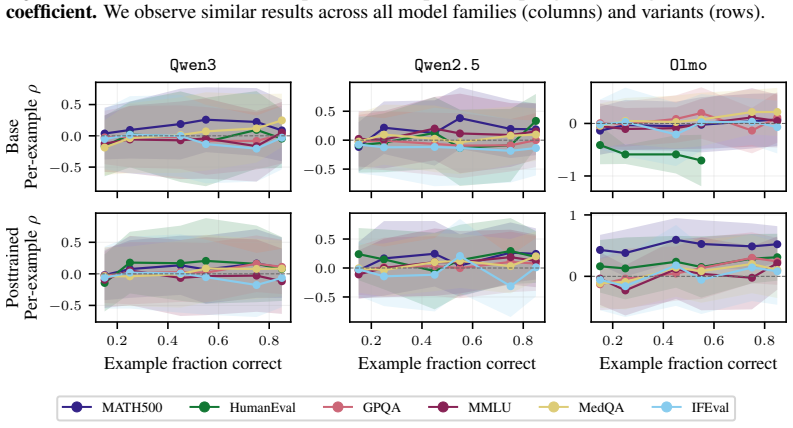
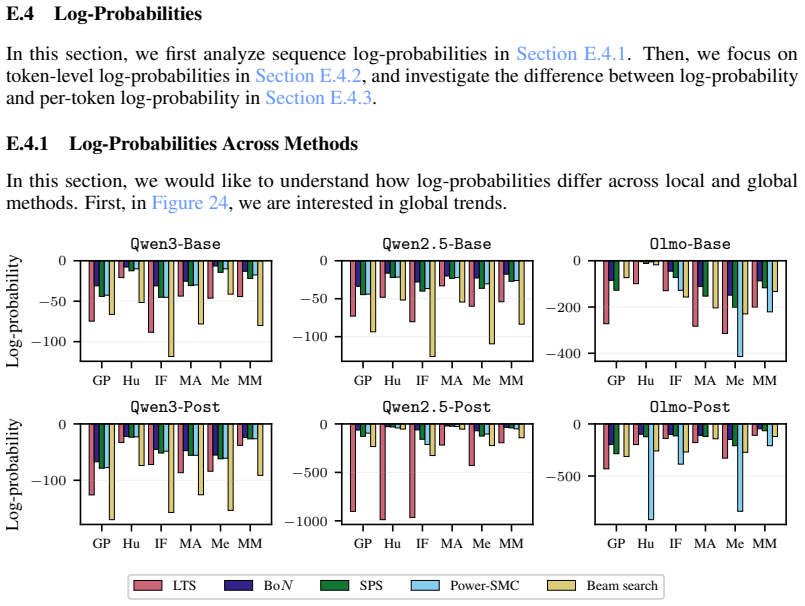
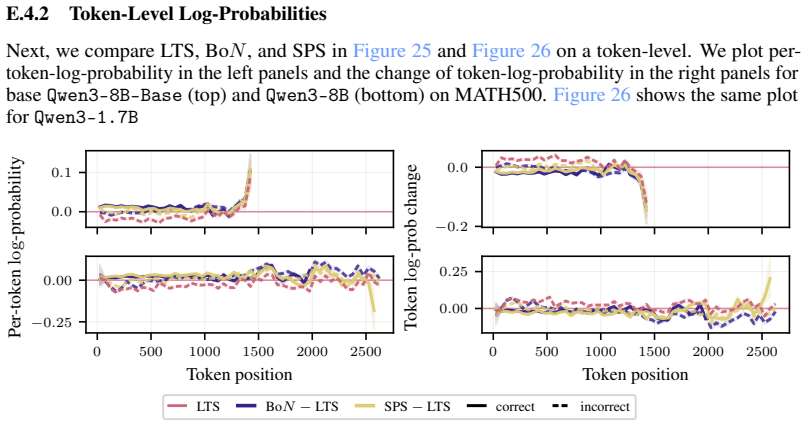
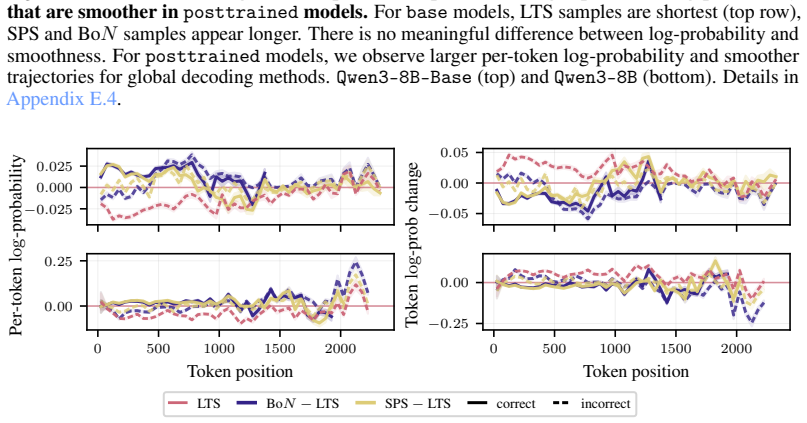
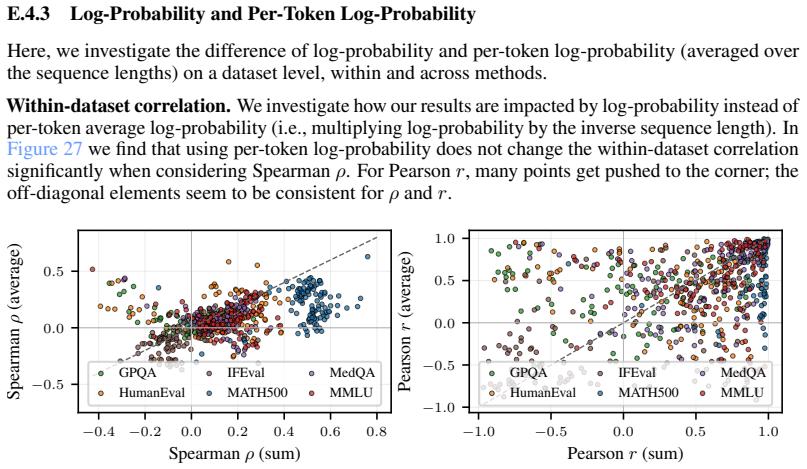
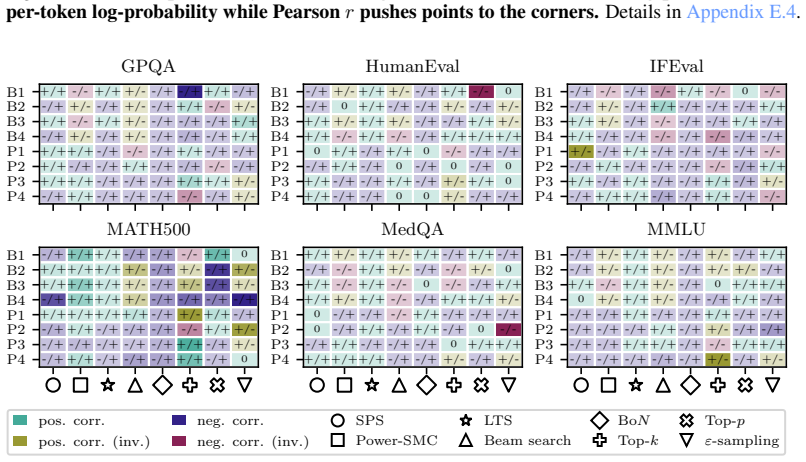
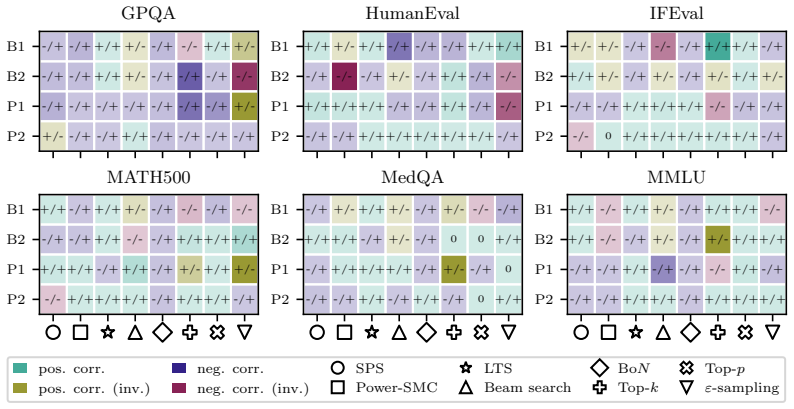
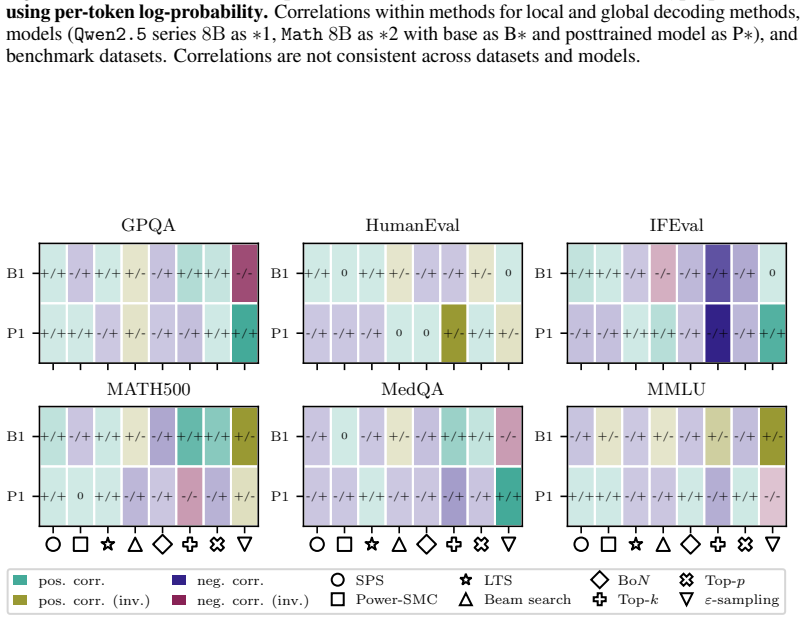
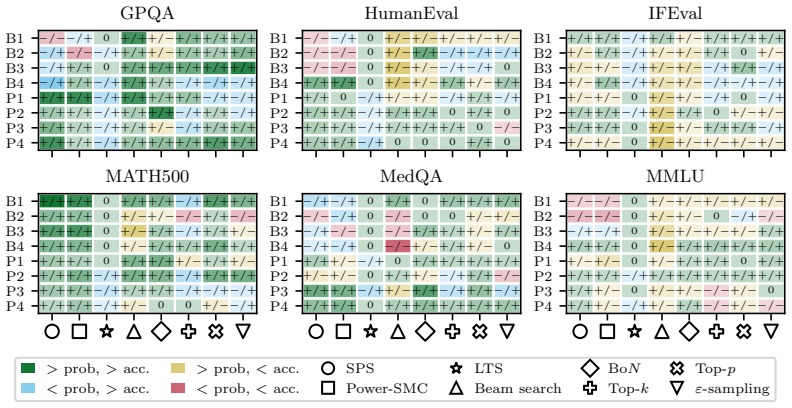
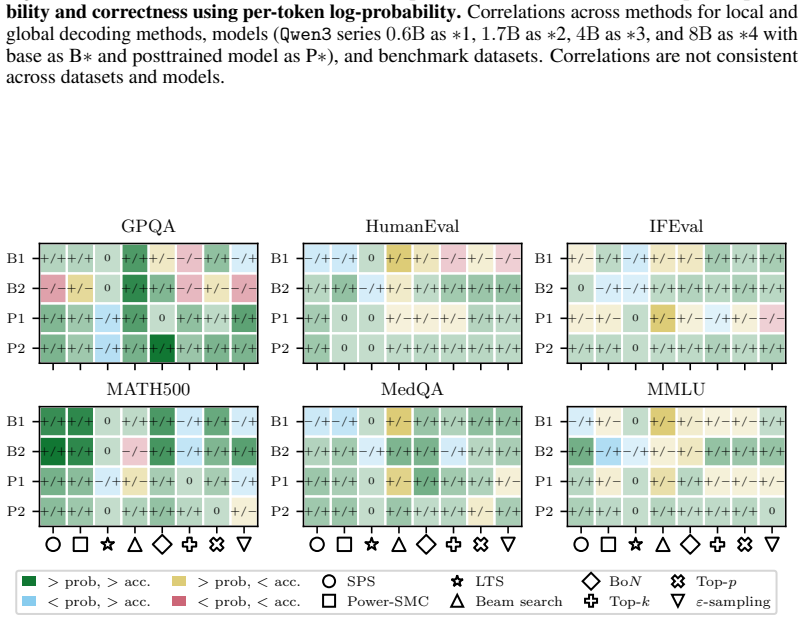
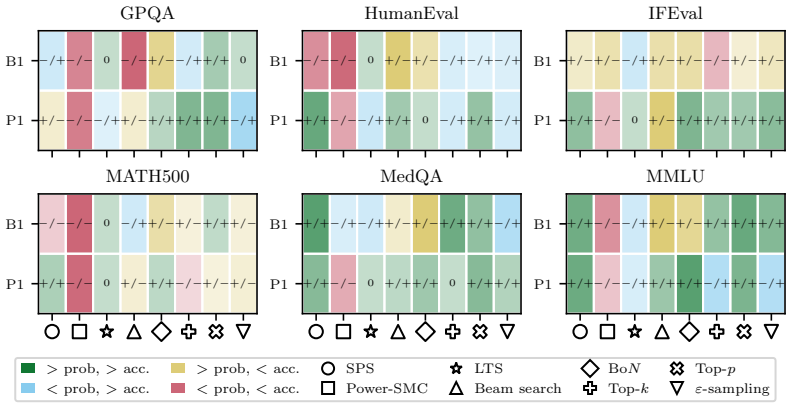
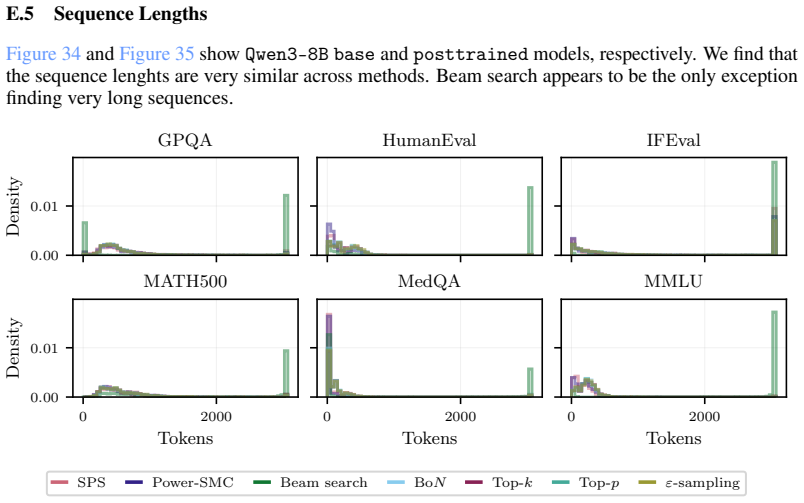
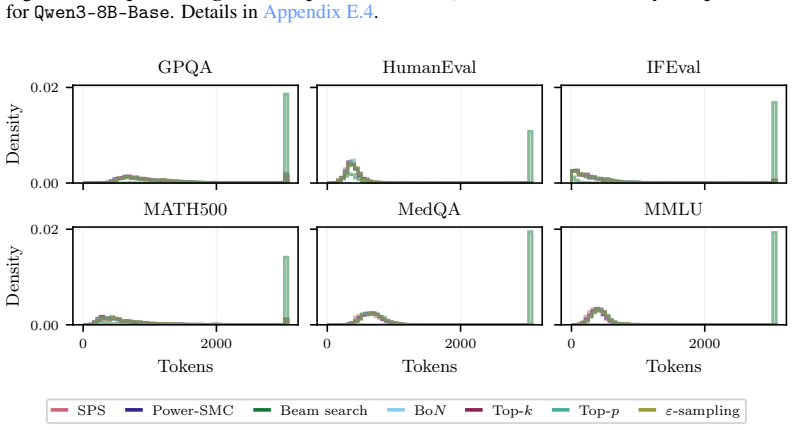
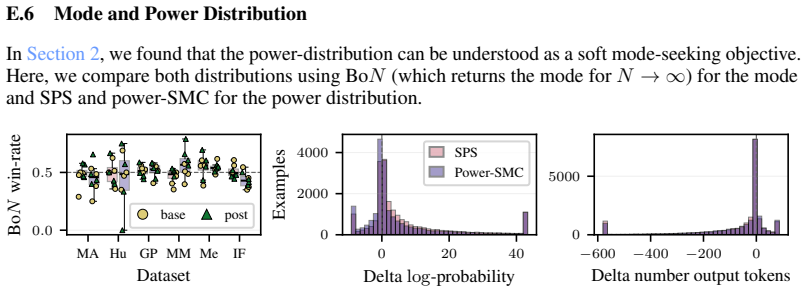
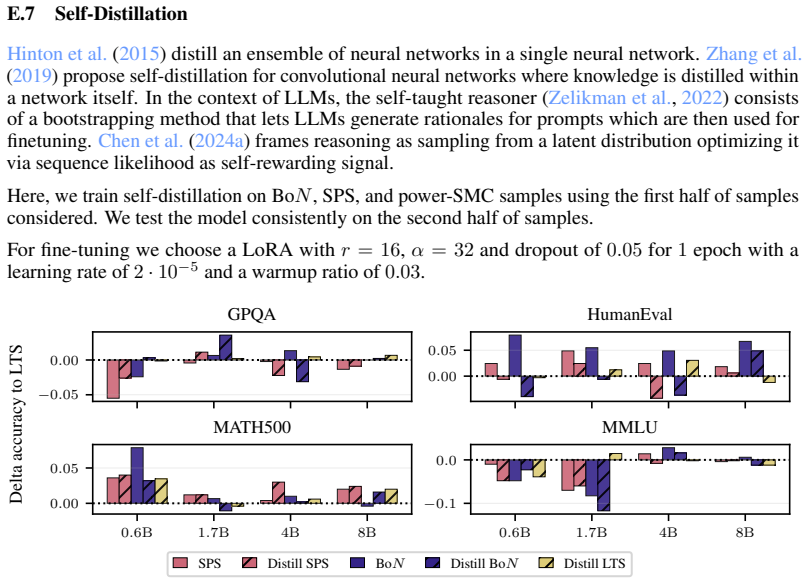
read the original abstract
Many decoding methods for large language models can be understood as shifting probability mass toward outputs that are more likely under the model, either locally at the token level or globally at the sequence level. Therefore, their success depends on a fundamental question: when does sequence probability, that is, the conditional probability of a continuation given a prompt, actually align with correctness? In this paper, we set out to quantify this relationship across decoding methods, models, and benchmarks at four levels: across decoding methods, across hyperparameters within a method, across prompt-answer pairs within a dataset, and across repeated responses to the same prompt. We find that higher sequence probability is often predictive of correctness across prompt-answer pairs within a fixed dataset. However, this relationship does not generally transfer to decoding decisions: increasing sequence probability by changing hyperparameters or methods does not reliably improve accuracy. Further, sequence probability is not a good indicator of correctness for responses to the same prompt. These findings clarify when decoding can and cannot be expected to improve correctness, and provide practical guidance for decoding, self-consistency, and verifier-free self-improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines the alignment between sequence probability (conditional probability of a continuation given a prompt) and correctness in LLMs. It quantifies the relationship at four levels—across decoding methods, across hyperparameters within a method, across prompt-answer pairs within a dataset, and across repeated responses to the same prompt—finding that higher sequence probability is often predictive of correctness across prompt-answer pairs within a fixed dataset, but that increasing sequence probability via changes to hyperparameters or methods does not reliably improve accuracy, and that sequence probability is not a reliable indicator of correctness for responses to the same prompt. The work aims to clarify when decoding methods can and cannot be expected to improve correctness.
Significance. If the reported patterns hold under broader testing, the multi-level empirical analysis provides useful practical guidance for decoding choices, self-consistency, and verifier-free self-improvement in LLMs by delineating where probability-correctness alignment exists and where it fails to transfer. The four-level breakdown is a strength, as it separates within-dataset correlations from causal effects of decoding interventions.
major comments (2)
- [Abstract] Abstract: The headline claims use qualifiers such as 'often predictive' and 'does not generally transfer.' These rest on the assumption that the tested models, benchmarks, and decoding methods are representative; however, the abstract provides no enumeration of the specific models (scale, families), benchmarks (task types), or methods, making it impossible to assess whether the negative transfer result is an artifact of a narrow experimental slice (e.g., only small models or multiple-choice tasks).
- [Abstract and experimental sections] The central empirical claims at the 'across decoding methods' and 'across hyperparameters' levels require evidence that the observed lack of accuracy improvement when sequence probability is increased is not driven by post-hoc benchmark or method selection. Without explicit reporting of the full set of methods, models, and controls (including statistical tests and exclusion criteria), the 'does not generally transfer' conclusion cannot be evaluated for robustness.
minor comments (1)
- [Introduction] Clarify the precise definition of 'sequence probability' (e.g., whether it is the product of token probabilities or normalized) with an equation early in the paper to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our experimental scope. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims use qualifiers such as 'often predictive' and 'does not generally transfer.' These rest on the assumption that the tested models, benchmarks, and decoding methods are representative; however, the abstract provides no enumeration of the specific models (scale, families), benchmarks (task types), or methods, making it impossible to assess whether the negative transfer result is an artifact of a narrow experimental slice (e.g., only small models or multiple-choice tasks).
Authors: We agree that the abstract should briefly enumerate the experimental scope to support the qualifiers. In revision we will add a concise clause listing the model families and scales, benchmark task types (including both multiple-choice and generative), and decoding methods tested, while preserving length constraints. revision: yes
-
Referee: [Abstract and experimental sections] The central empirical claims at the 'across decoding methods' and 'across hyperparameters' levels require evidence that the observed lack of accuracy improvement when sequence probability is increased is not driven by post-hoc benchmark or method selection. Without explicit reporting of the full set of methods, models, and controls (including statistical tests and exclusion criteria), the 'does not generally transfer' conclusion cannot be evaluated for robustness.
Authors: The body already reports results aggregated over the full set of models, benchmarks, and methods used. To address the concern directly we will add an appendix that lists every configuration considered, states inclusion/exclusion criteria, and reports the statistical tests applied to accuracy differences. This will make the robustness of the 'does not generally transfer' finding transparent without altering the core claims. revision: yes
Circularity Check
No circularity: purely empirical observational study
full rationale
The paper conducts an empirical analysis of sequence probability vs. correctness across decoding methods, models, benchmarks, and prompt levels. It reports observational patterns from experiments without any derivation chain, equations, fitted parameters presented as predictions, or self-citations that reduce claims to inputs by construction. No self-definitional, fitted-input, or uniqueness-theorem patterns appear. The central claims rest on direct measurement rather than reduction to prior fitted quantities or author-specific ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard statistical assumptions underlying correlation and predictive-power measurements hold for the chosen benchmarks and models.
Reference graph
Works this paper leans on
-
[1]
Power-smc: Low-latency sequence-level power sampling for training-free llm reasoning
Seyedarmin Azizi, Erfan Baghaei Potraghloo, Minoo Ahmadi, Souvik Kundu, and Massoud Pedram. Power-smc: Low-latency sequence-level power sampling for training-free llm reasoning. arXiv preprint arXiv:2602.10273, 2026
arXiv 2026
-
[2]
Smoothing algorithms for state--space models
Mark Briers, Arnaud Doucet, and Simon Maskell. Smoothing algorithms for state--space models. Annals of the Institute of Statistical Mathematics, 62: 0 61--89, 2010
2010
-
[3]
Language models are hidden reasoners: Unlocking latent reasoning capabilities via self-rewarding
Haolin Chen, Yihao Feng, Zuxin Liu, Weiran Yao, Akshara Prabhakar, Shelby Heinecke, Ricky Ho, Phil Mui, Silvio Savarese, Caiming Xiong, et al. Language models are hidden reasoners: Unlocking latent reasoning capabilities via self-rewarding. arXiv preprint arXiv:2411.04282, 2024 a
arXiv 2024
-
[4]
Evaluating large language models trained on code, 2021
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code, 2021. arXiv preprint arXiv:2107.03374, 2025
Pith/arXiv arXiv 2021
-
[5]
Universal self-consistency for large language models
Xinyun Chen, Renat Aksitov, Uri Alon, Jie Ren, Kefan Xiao, Pengcheng Yin, Sushant Prakash, Charles Sutton, Xuezhi Wang, and Denny Zhou. Universal self-consistency for large language models. In International Conference on Machine Learning, Workshop on In-Context Learning, 2024 b
2024
-
[6]
Central limit theorem for sequential Monte Carlo methods and its application to Bayesian inference
Nicolas Chopin. Central limit theorem for sequential Monte Carlo methods and its application to Bayesian inference . The Annals of Statistics, 32 0 (6): 0 2385 -- 2411, 2004
2004
-
[7]
An introduction to sequential Monte Carlo, volume 4
Nicolas Chopin, Omiros Papaspiliopoulos, et al. An introduction to sequential Monte Carlo, volume 4. Springer, 2020
2020
-
[8]
Training verifiers to solve math word problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[9]
Empirical analysis of beam search performance degradation in neural sequence models
Eldan Cohen and Christopher Beck. Empirical analysis of beam search performance degradation in neural sequence models. In International Conference on Machine Learning, 2019
2019
-
[10]
Feynman-Kac Formulae, pages 47--93
Pierre Del Moral. Feynman-Kac Formulae, pages 47--93. Springer New York, 2004
2004
-
[11]
Sequential monte carlo samplers
Pierre Del Moral, Arnaud Doucet, and Ajay Jasra. Sequential monte carlo samplers. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 68 0 (3): 0 411--436, 2006
2006
-
[12]
An introduction to sequential monte carlo methods
Arnaud Doucet, Nando De Freitas, and Neil Gordon. An introduction to sequential monte carlo methods. Sequential Monte Carlo methods in practice, pages 3--14, 2001
2001
-
[13]
Hierarchical Neural Story Generation
Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical Neural Story Generation . In Iryna Gurevych and Yusuke Miyao, editors, Annual Meeting of the Association for Computational Linguistics , Long Papers , 2018
2018
-
[14]
Yichao Fu, Xuewei Wang, Yuandong Tian, and Jiawei Zhao. Deep Think with Confidence . arXiv preprint arXiv:2508.15260, 2025
Pith/arXiv arXiv 2025
-
[15]
J. Gai, G. Zeng, H. Zhang, and A. Raghunathan. Differential smoothing mitigates sharpening and improves LLM reasoning. arXiv preprint arXiv:2511.19942, 2025
arXiv 2025
-
[16]
W. K. Hastings. Monte carlo sampling methods using markov chains and their applications. Biometrika, 57 0 (1): 0 97--109, 1970
1970
-
[17]
He, Daniel Fried, and Sean Welleck
Amy W. He, Daniel Fried, and Sean Welleck. Rewarding the unlikely: Lifting GRPO beyond distribution sharpening. In Conference on Empirical Methods in Natural Language Processing, 2025
2025
-
[18]
Measuring mathematical problem solving with the math dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
Pith/arXiv arXiv 2021
-
[19]
John Hewitt, Christopher D. Manning, and Percy Liang. Truncation Sampling as Language Model Desmoothing . arXiv preprint arXiv:2210.15191, 2022
arXiv 2022
-
[20]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
Pith/arXiv arXiv 2015
-
[21]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The Curious Case of Neural Text Degeneration . arXiv preprint arXiv:1904.09751, 2020
Pith/arXiv arXiv 1904
-
[22]
Xiaotong Ji, Rasul Tutunov, Matthieu Zimmer, and Haitham Bou Ammar. Scalable power sampling: Unlocking efficient, training-free reasoning for llms via distribution sharpening. arXiv preprint arXiv:2601.21590, 2026
arXiv 2026
-
[23]
What disease does this patient have? a large-scale open domain question answering dataset from medical exams
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11 0 (14): 0 6421, 2021
2021
-
[24]
Language models (mostly) know what they know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221, 2022
Pith/arXiv arXiv 2022
-
[25]
Scalable Best -of- N Selection for Large Language Models via Self - Certainty
Zhewei Kang, Xuandong Zhao, and Dawn Song. Scalable Best -of- N Selection for Large Language Models via Self - Certainty . arXiv preprint arXiv:2502.18581, 2025
arXiv 2025
-
[26]
Reasoning with sampling: Your base model is smarter than you think
Aayush Karan and Yilun Du. Reasoning with sampling: Your base model is smarter than you think. arXiv preprint arXiv:2510.14901, 2025
Pith/arXiv arXiv 2025
-
[27]
Tom Kempton and Stuart Burrell. Local normalization distortion and the thermodynamic formalism of decoding strategies for large language models. arXiv preprint arXiv:2503.21929, 2025
arXiv 2025
-
[28]
Six Challenges for Neural Machine Translation
Philipp Koehn and Rebecca Knowles. Six Challenges for Neural Machine Translation . In Annual Meeting of the Association for Computational Linguistics, Workshop on Neural Machine Translation , 2017
2017
-
[29]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Symposium on Operating Systems Principles, 2023
2023
-
[30]
Sixo: Smoothing inference with twisted objectives
Dieterich Lawson, Allan Ravent \'o s, Andrew Warrington, and Scott Linderman. Sixo: Smoothing inference with twisted objectives. In Advances in Neural Information Processing Systems, 2022
2022
-
[31]
Sample smart, not hard: Correctness-first decoding for better reasoning in LLM s
Xueyan Li, Guinan Su, Mrinmaya Sachan, and Jonas Geiping. Sample smart, not hard: Correctness-first decoding for better reasoning in LLM s. In International Conference on Learning Representations, 2026 a
2026
-
[32]
-leaf enumeration: Non-repeating self-consistency via truncated tree search
Xueyan Li, Johannes Zenn, Ekaterina Fadeeva, Guinan Su, Mrinmaya Sachan, and Jonas Geiping. -leaf enumeration: Non-repeating self-consistency via truncated tree search. International Conference on Learning Representations (ICLR), Workshop on Latent & Implicit Thinking, 2026 b
2026
-
[33]
Let's verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In International Conference on Learning Representations, 2024
2024
-
[34]
Critic sequential monte carlo
Vasileios Lioutas, Jonathan Wilder Lavington, Justice Sefas, Matthew Niedoba, Yunpeng Liu, Berend Zwartsenberg, Setareh Dabiri, Frank Wood, and Adam Scibior. Critic sequential monte carlo. In International Conference on Learning Representations, 2022
2022
-
[35]
The harpy speech recognition system
Bruce T Lowerre. The harpy speech recognition system. Carnegie Mellon University, 1976
1976
-
[36]
Equation of state calculations by fast computing machines
Nicholas Metropolis, Arianna W Rosenbluth, Marshall N Rosenbluth, Augusta H Teller, and Edward Teller. Equation of state calculations by fast computing machines. The journal of chemical physics, 21 0 (6): 0 1087--1092, 1953
1953
-
[37]
K. Ni, Z. Tan, Z. Liu, P. Li, and T. Chen. Can GRPO help LLMs transcend their pretraining origin? arXiv preprint arXiv:2510.15990, 2025
arXiv 2025
-
[38]
Karl Pearson. Iii. contributions to the mathematical theory of evolution. Philosophical Transactions of the Royal Society of London. (A.), 0 (185): 0 71--110, 12 1894
-
[39]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. In Conference on Language Modeling, 2024
2024
-
[40]
Y. Song, J. Kempe, and R. Munos. Outcome-based exploration for LLM reasoning. arXiv preprint arXiv:2509.06941, 2025
arXiv 2025
- [41]
-
[42]
Calibration and correctness of language models for code
Claudio Spiess, David Gros, Kunal Suresh Pai, Michael Pradel, Md Rafiqul Islam Rabin, Amin Alipour, Susmit Jha, Prem Devanbu, and Toufique Ahmed. Calibration and correctness of language models for code. In International Conference on Software Engineering, 2025
2025
-
[43]
A contrastive framework for neural text generation
Yixuan Su, Tian Lan, Yan Wang, Dani Yogatama, Lingpeng Kong, and Nigel Collier. A contrastive framework for neural text generation. In Advances in Neural Information Processing Systems, 2022
2022
-
[44]
Sequence to sequence learning with neural networks
Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks. Advances in neural information processing systems, 2014
2014
-
[45]
Confidence improves self-consistency in LLM s
Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. Confidence improves self-consistency in LLM s. In Findings of the Association for Computational Linguistics, 2025
2025
-
[46]
Diverse beam search: Decoding diverse solutions from neural sequence models
Ashwin K Vijayakumar, Michael Cogswell, Ramprasath R Selvaraju, Qing Sun, Stefan Lee, David Crandall, and Dhruv Batra. Diverse beam search: Decoding diverse solutions from neural sequence models. arXiv preprint arXiv:1610.02424, 2016
Pith/arXiv arXiv 2016
-
[47]
Arithmetic sampling: parallel diverse decoding for large language models
Luke Vilnis, Yury Zemlyanskiy, Patrick Murray, Alexandre Tachard Passos, and Sumit Sanghai. Arithmetic sampling: parallel diverse decoding for large language models. In International Conference on Machine Learning, 2023
2023
-
[48]
Soft Self-Consistency Improves Language Models Agents
Han Wang, Archiki Prasad, Elias Stengel-Eskin , and Mohit Bansal. Soft Self-Consistency Improves Language Models Agents . In Annual Meeting of the Association for Computational Linguistics , Short Papers , 2024 a
2024
-
[49]
Integrate the essence and eliminate the dross: Fine-grained self-consistency for free-form language generation
Xinglin Wang, Yiwei Li, Shaoxiong Feng, Peiwen Yuan, Boyuan Pan, Heda Wang, Yao Hu, and Kan Li. Integrate the essence and eliminate the dross: Fine-grained self-consistency for free-form language generation. In Annual Meeting of the Association for Computational Linguistics, Long Papers, 2024 b
2024
-
[50]
Self- Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self- Consistency Improves Chain of Thought Reasoning in Language Models . arXiv preprint arXiv:2203.11171, 2023
Pith/arXiv arXiv 2023
-
[51]
MMLU - Pro : A More Robust and Challenging Multi - Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, and Wenhu Chen. MMLU - Pro : A More Robust and Challenging Multi - Task Language Understanding Benchmark . arXiv preprint arXiv:2406.01574, 2024 c
Pith/arXiv arXiv 2024
-
[52]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[53]
Breaking the Beam Search Curse : A Study of ( Re -) Scoring Methods and Stopping Criteria for Neural Machine Translation
Yilin Yang, Liang Huang, and Mingbo Ma. Breaking the Beam Search Curse : A Study of ( Re -) Scoring Methods and Stopping Criteria for Neural Machine Translation . In Conference on Empirical Methods in Natural Language Processing , 2018
2018
-
[54]
Y. Yue, Z. Chen, R. Lu, A. Zhao, Z. Wang, S. Song, and G. Huang. Does reinforcement learning really incentivize reasoning capacity in LLMs beyond the base model? arXiv preprint arXiv:2504.13837, 2025
Pith/arXiv arXiv 2025
-
[55]
Star: Bootstrapping reasoning with reasoning
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning. In Advances in Neural Information Processing Systems, 2022
2022
-
[56]
Be your own teacher: Improve the performance of convolutional neural networks via self distillation
Linfeng Zhang, Jiebo Song, Anni Gao, Jingwei Chen, Chenglong Bao, and Kaisheng Ma. Be your own teacher: Improve the performance of convolutional neural networks via self distillation. In International Conference on Computer Vision, 2019
2019
-
[57]
Probabilistic inference in language models via twisted sequential monte carlo
Stephen Zhao, Rob Brekelmans, Alireza Makhzani, and Roger Baker Grosse. Probabilistic inference in language models via twisted sequential monte carlo. In International Conference on Machine Learning, 2024
2024
-
[58]
Instruction-following evaluation for large language models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911, 2023
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.