SelectAnyTree: A Promptable Instance Segmentation Model for 3D Forest LiDAR Point Clouds
Pith reviewed 2026-06-29 02:07 UTC · model grok-4.3
The pith
SelectAnyTree segments any tree in a 3D forest LiDAR point cloud from a single click at 78.2 IoU.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
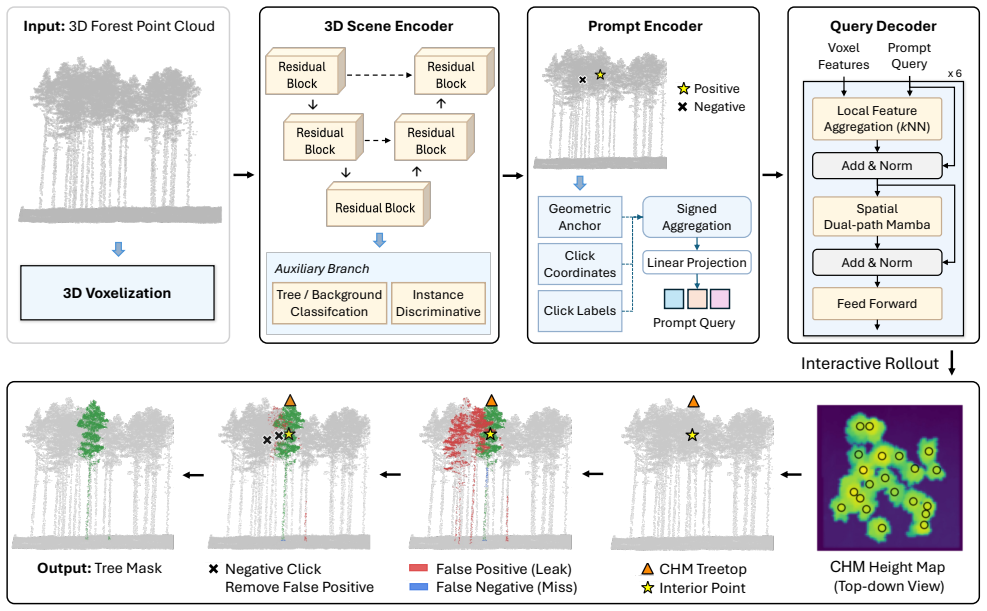
SelectAnyTree converts user clicks into single content queries through a dedicated encoder that pools local backbone features with 3D position and polarity, supplies an initial prompt from a Canopy Height Model without user input, and decodes the resulting query into one tree mask via a state-space query decoder that handles long-range context in large scenes.
What carries the argument
Click-to-query prompt encoder that produces one content query per click together with a Canopy Height Model-guided first prompt and state-space query decoder.
If this is right
- Interactive correction of automatic pre-segmentations becomes feasible at scale.
- Annotation effort per hectare falls because each tree requires only the fewest clicks to reach target accuracy.
- Linear-time decoding supports processing of hectare-scale scenes without quadratic cost growth.
- Fewer parameters and shorter inference time allow the model to run on standard hardware for field use.
Where Pith is reading between the lines
- The same click-to-query design could be adapted to segment other point-cloud objects such as individual buildings or vehicles.
- Combining the CHM-guided prompt with multi-temporal LiDAR might enable change detection of tree growth or removal.
- Deployment on mobile devices could support on-site verification during forest inventories.
Load-bearing premise
The CHM-guided first prompt and click-to-query encoder will reliably produce usable queries across unseen forest structures and sensor characteristics without domain-specific retraining.
What would settle it
A measurable drop in single-click IoU below the strongest baseline when the model is tested on a new forest region recorded with a different LiDAR sensor and tree species mix.
Figures
read the original abstract
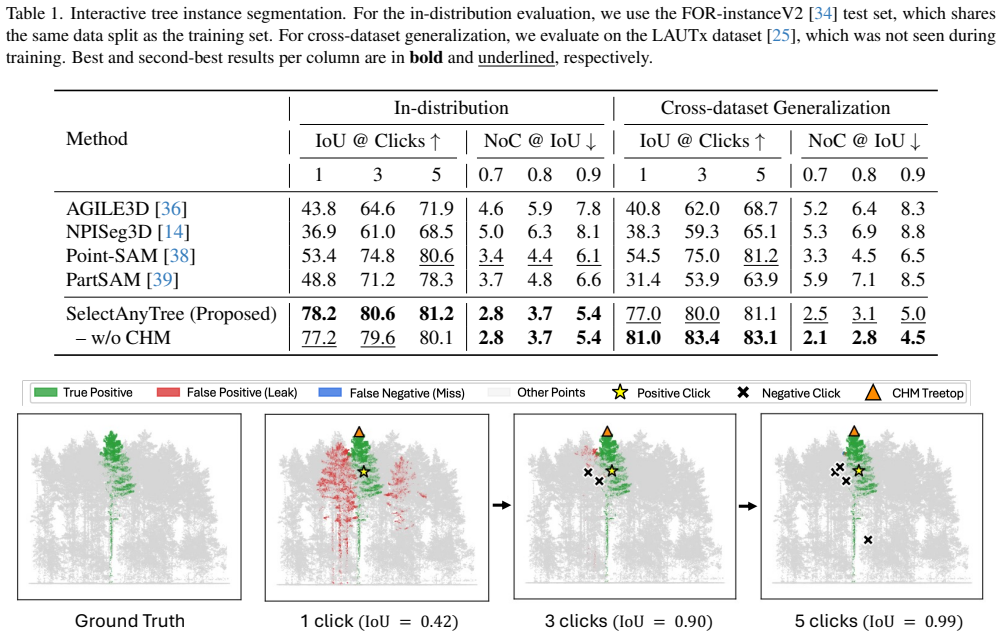
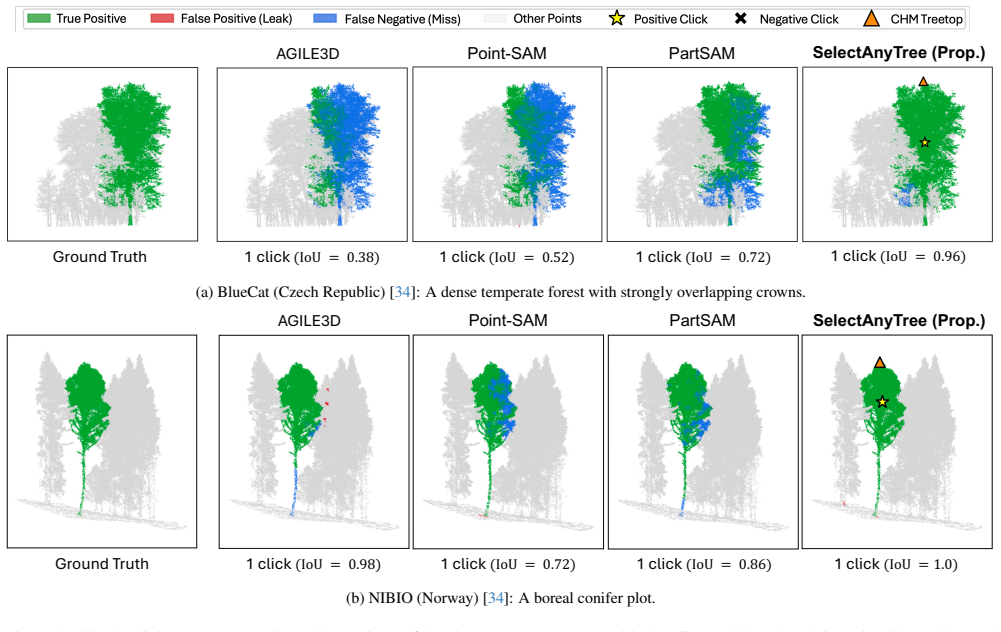
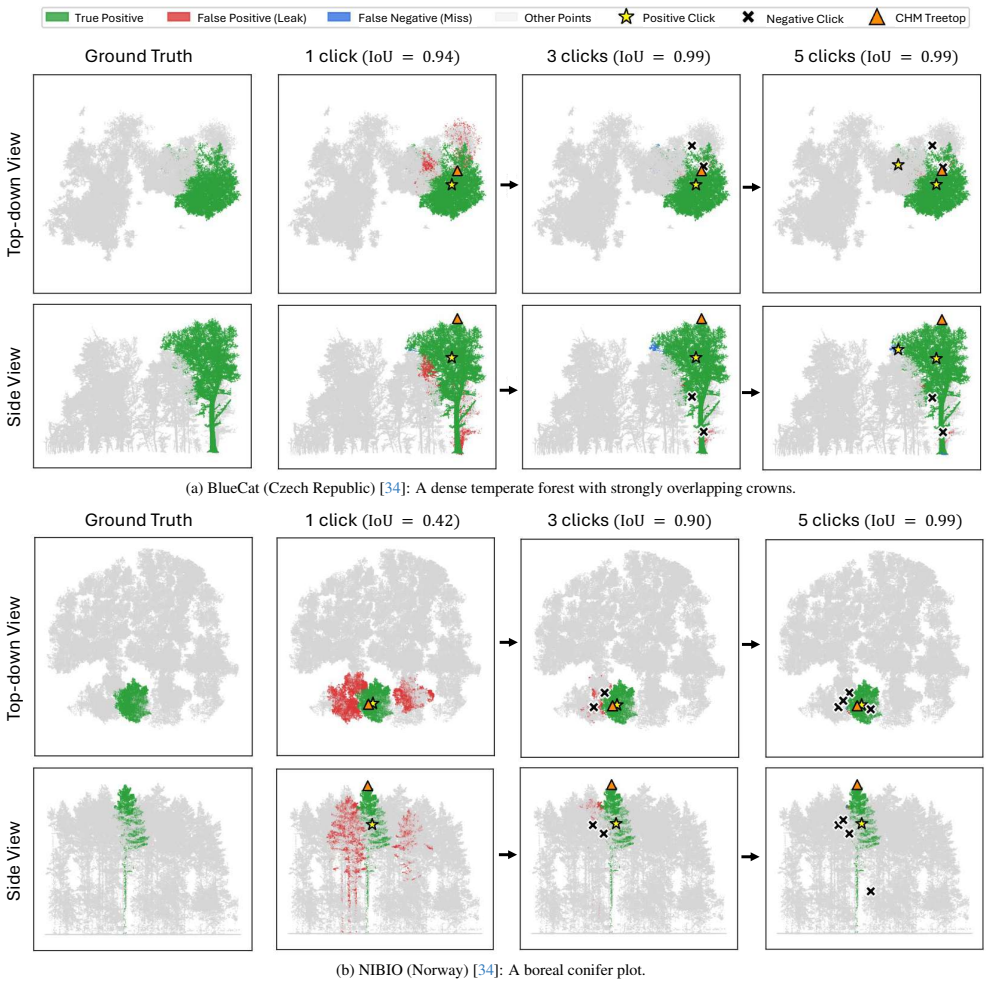
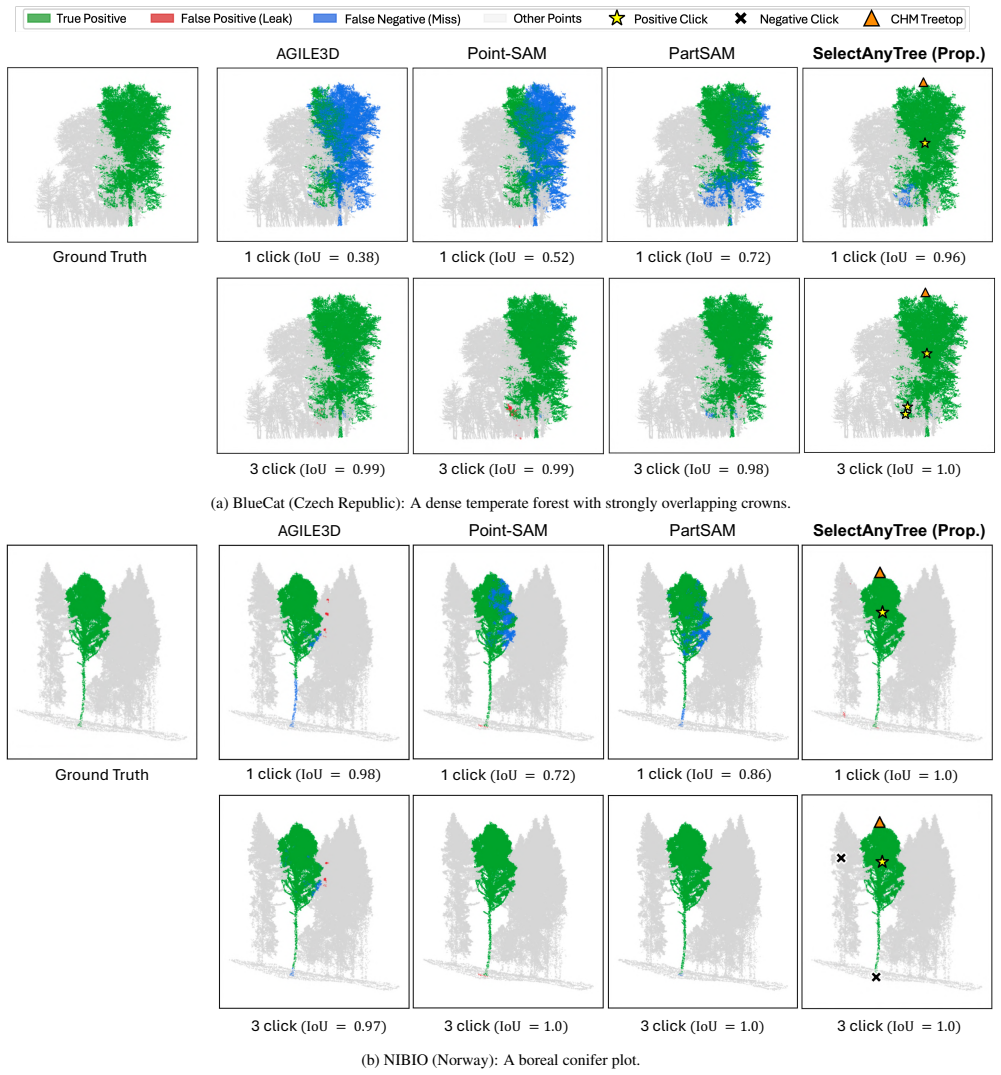
Automated instance segmentation of forest LiDAR point clouds is increasingly critical as forest monitoring moves toward scalable, detailed, 3D measurement. Yet, progress is constrained by label scarcity for tree instances; a single hectare can hold millions of points and hundreds of overlapping, complex crowns, making manual annotation from scratch with raw data laborious and error-prone. Annotations are often corrected from automatic pre-segmentations, but remain costly as these provide no interactive or AI-assisted refinement. Inspired by the promptable paradigm of foundation segmentation models, we propose SelectAnyTree, a promptable instance segmentation model that delineates any individual tree in a 3D forest point cloud from a few clicks. It introduces two key components: Click-to-query prompt encoder and Canopy Height Model (CHM)-guided first prompt. The former turns each click into a single content query, encoding its 3D position and positive/negative polarity together with a pooled local backbone feature. The latter provides treetops as a geometry- and ecologically guided first prompt without any user input. The resulting prompt query is then decoded into one tree mask by a state-space query decoder to efficiently capture long-range context in large-scale forest scenes with linear-time complexity. We evaluate SelectAnyTree in interactive and instance-level settings across seven diverse forest regions and an independent held-out test dataset, demonstrating strong generalization beyond the training domains. It segments a target tree to 78.2 Intersection over Union (IoU) from a single click, 24.8 points above the strongest promptable baseline, and reaches every accuracy target with the fewest clicks, while using far fewer parameters and less inference time than prior promptable models. The source code is available at https://github.com/thanhhff/SelectAnyTree.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. SelectAnyTree is a promptable instance segmentation model for 3D forest LiDAR point clouds. It converts user clicks into content queries via a Click-to-query prompt encoder (encoding 3D position, positive/negative polarity, and pooled local backbone features) and augments them with an automatic CHM-guided first prompt for treetop detection. These queries are decoded into individual tree masks using a state-space query decoder with linear-time complexity. The model is evaluated interactively and at instance level on seven diverse forest regions plus an independent held-out test set, reporting 78.2 IoU from a single click (24.8 points above the strongest promptable baseline), fewer clicks to reach all accuracy targets, and advantages in parameter count and inference time over prior models. Source code is released.
Significance. If the performance numbers and cross-domain generalization hold, the work offers a practical advance for scalable forest monitoring by enabling efficient interactive refinement of tree instances in large, complex point clouds where manual annotation is costly. The state-space decoder's linear complexity addresses a key scalability issue for hectare-scale scenes, and the public code release supports reproducibility.
major comments (2)
- [§5] §5 (Experiments and held-out evaluation): The central claims of 78.2 IoU from one click and strong generalization beyond training domains rest on the CHM-guided first prompt and click-to-query encoder producing reliable queries across unseen sensors/structures; however, no explicit cross-sensor ablation, CHM peak-detection failure analysis under varying point densities or canopy closure, or sensitivity study is reported, leaving the single-click result and generalization statement insufficiently secured.
- [Method] Method (Click-to-query prompt encoder description): The integration of the pooled local backbone feature with 3D position and polarity into the query is described at a high level without specifying pooling radius, feature dimension, or exact concatenation/embedding steps; this detail is load-bearing for the query quality that underpins the reported 24.8-point IoU gain and fewest-clicks result.
minor comments (2)
- [Abstract] Abstract and §3: The phrase 'state-space query decoder' is introduced without a short parenthetical reference to the underlying SSM formulation or prior work on first mention, which may slow readers outside the immediate subfield.
- [Figures] Figure 3/4 captions (qualitative results): Adding the specific forest region, sensor type, and point density for each example would improve interpretability of the generalization evidence.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications and additional analyses.
read point-by-point responses
-
Referee: [§5] §5 (Experiments and held-out evaluation): The central claims of 78.2 IoU from one click and strong generalization beyond training domains rest on the CHM-guided first prompt and click-to-query encoder producing reliable queries across unseen sensors/structures; however, no explicit cross-sensor ablation, CHM peak-detection failure analysis under varying point densities or canopy closure, or sensitivity study is reported, leaving the single-click result and generalization statement insufficiently secured.
Authors: We agree that the generalization claims would be more robust with explicit supporting analyses. The current held-out test set already evaluates performance on data from domains distinct from training, but we will add the requested elements to the revised §5: a cross-sensor ablation partitioning results by LiDAR sensor, a failure-mode analysis of CHM peak detection stratified by point density and canopy closure, and a sensitivity study on CHM-guided prompt parameters. These additions will directly support the single-click IoU and cross-domain results. revision: yes
-
Referee: [Method] Method (Click-to-query prompt encoder description): The integration of the pooled local backbone feature with 3D position and polarity into the query is described at a high level without specifying pooling radius, feature dimension, or exact concatenation/embedding steps; this detail is load-bearing for the query quality that underpins the reported 24.8-point IoU gain and fewest-clicks result.
Authors: We agree that the prompt encoder description requires additional implementation specifics to allow full reproduction of the reported gains. In the revised method section we will explicitly state the pooling radius for local backbone feature extraction, the feature dimension, and the precise concatenation and embedding operations that combine 3D position, polarity, and the pooled features into each content query. revision: yes
Circularity Check
No circularity: empirical results on held-out data with independent validation
full rationale
The paper introduces architectural components (Click-to-query prompt encoder, CHM-guided first prompt, state-space query decoder) and reports performance metrics such as 78.2 IoU from a single click on seven diverse regions plus an independent held-out test set. No equations, fitted parameters, or self-citations reduce these metrics to quantities defined or fitted on the same test distributions by construction. The derivation chain consists of model design choices followed by external empirical evaluation without self-referential reductions or load-bearing self-citations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Labeled training data for tree instances is available and sufficiently representative of target deployment forests.
Reference graph
Works this paper leans on
-
[1]
Terrestrial laser scanning in forest ecology: Expanding the horizon.Re- mote Sensing of Environment, 251(112102):1–17, 2020
Kim Calders, Jennifer Adams, John Armston, Harm Bartholomeus, Sebastien Bauwens, Lisa Patrick Bentley, Jerome Chave, F Mark Danson, Miro Demol, Mathias Dis- ney, Rachel Gaulton, Sruthi M Krishna Moorthy, Shaun R Levick, Ninni Saarinen, Crystal Schaaf, Atticus Stovall, Louise Terryn, Phil Wilkes, and Hans Verbeeck. Terrestrial laser scanning in forest ecol...
2020
-
[2]
End-to- end object detection with Transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with Transformers. InProceedings of the 16th European Conference on Computer Vision,Part I, pages 213–229, 2020. 2
2020
-
[3]
Masked-attention mask Transformer for universal image segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexan- der Kirillov, and Rohit Girdhar. Masked-attention mask Transformer for universal image segmentation. InProceed- ings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1290–1299, 2022. 2
2022
-
[4]
4D spatio-temporal ConvNets: Minkowski convolutional neu- ral networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4D spatio-temporal ConvNets: Minkowski convolutional neu- ral networks. InProceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition, pages 3075– 3084, 2019. 2
2019
-
[5]
Se- mantic instance segmentation for autonomous driving
Bert De Brabandere, Davy Neven, and Luc Van Gool. Se- mantic instance segmentation for autonomous driving. In Proceedings of the 2017 IEEE Conference on Computer Vi- sion and Pattern Recognition Workshops, pages 478–480,
2017
-
[6]
Close-range remote sensing of forest structure for biodiver- sity assessments: A systematic literature review.Current Forestry Reports, 11(1):1–18, 2025
Jan Feigl, Julian Frey, Thomas Seifert, and Barbara Koch. Close-range remote sensing of forest structure for biodiver- sity assessments: A systematic literature review.Current Forestry Reports, 11(1):1–18, 2025. 1
2025
-
[7]
3D semantic segmentation with submanifold sparse convolutional networks
Benjamin Graham, Martin Engelcke, and Laurens van der Maaten. 3D semantic segmentation with submanifold sparse convolutional networks. InProceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, pages 9224–9232, 2018. 2
2018
-
[8]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InProceedings of the 2024 International Conference on Learning Representations, pages 1–32, 2024. 2, 3
2024
-
[9]
TreeLearn: A deep learn- ing method for segmenting individual trees from ground- based LiDAR forest point clouds.Ecological Informatics, 84(102888):1–16, 2024
Jonathan Henrich, Jan van Delden, Dominik Seidel, Thomas Kneib, and Alexander S Ecker. TreeLearn: A deep learn- ing method for segmenting individual trees from ground- based LiDAR forest point clouds.Ecological Informatics, 84(102888):1–16, 2024. 1, 2, 5, 7
2024
-
[10]
Allometric equations for integrating remote sensing imagery into forest monitor- ing programmes.Global Change Biology, 23(1):177–190,
Tommaso Jucker, John Caspersen, J ´erˆome Chave, C ´ecile Antin, Nicolas Barbier, Frans Bongers, Michele Dalponte, Karin Y van Ewijk, David I Forrester, Matthias Haeni, Steven I Higgins, Robert J Holdaway, Yoshiko Iida, Craig Lorimer, Peter L Marshall, St ´ephane Momo, Glenn R Mon- crieff, Pierre Ploton, Lourens Poorter, Kassim Abd Rah- man, Michael Schlu...
-
[11]
Review on Convolutional Neural Networks (CNN) in vegetation remote sensing.ISPRS Journal of Photogramme- try and Remote Sensing, 173:24–49, 2021
Teja Kattenborn, Jens Leitloff, Felix Schiefer, and Stefan Hinz. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing.ISPRS Journal of Photogramme- try and Remote Sensing, 173:24–49, 2021. 1, 8
2021
-
[12]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything. InProceedings of the 19th IEEE/CVF International Conference on Computer Vi- sion, pages 4015–4026, 2023. 2, 4, 11
2023
-
[13]
OneFormer3D: One Transformer for unified point cloud segmentation
Maxim Kolodiazhnyi, Anna V orontsova, Anton Konushin, and Danila Rukhovich. OneFormer3D: One Transformer for unified point cloud segmentation. InProceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, pages 20943–20953, 2024. 1, 2, 5, 7, 14
2024
-
[14]
Probabilistic interactive 3D segmentation with hierarchical neural processes
Jie Liu, Pan Zhou, Zehao Xiao, Jiayi Shen, Wenzhe Yin, Jan- jakob Sonke, and Efstratios Gavves. Probabilistic interactive 3D segmentation with hierarchical neural processes. InPro- ceedings of the 42nd International Conference on Machine Learning, pages 1–20, 2025. 2, 5, 6, 7, 12, 13, 15
2025
-
[15]
VMamba: Visual state space model.Advances in Neural Information Processing Systems, 37:103031–103063, 2024
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, and Yunfan Liu. VMamba: Visual state space model.Advances in Neural Information Processing Systems, 37:103031–103063, 2024. 2
2024
-
[16]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InProceedings of the 2019 International Conference on Learning Representations, pages 1–19, 2019. 5, 13, 14
2019
-
[17]
V-Net: Fully convolutional neural networks for volumetric medical image segmentation
Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. InProceedings of the 4th In- ternational Conference on 3D Vision, pages 565–571, 2016. 5, 11
2016
-
[18]
Individual tree crown delineation using multispectral LiDAR data.Sensors, 19(24):1–21, 2019
Faizaan Naveed, Baoxin Hu, Jianguo Wang, and G Brent Hall. Individual tree crown delineation using multispectral LiDAR data.Sensors, 19(24):1–21, 2019. 2
2019
-
[19]
ForestMamba: Sparse Mamba with Geometry-guided Queries for 3D Forest Point Cloud Segmentation
Trung Thanh Nguyen, Tuan-Anh Vu, Duc Viet Le, Yasutomo Kawanishi, Takahiro Komamizu, Ichiro Ide, and Teja Katten- born. ForestMamba: Sparse Mamba with geometry-guided queries for 3D forest point cloud segmentation.Computing Research Repository, arXiv Preprints,arXiv:2606.01549, pages 1–18, 2026. 1, 2, 3, 4, 5, 7, 12, 14
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Estimating plot- level tree heights with LiDAR: Local filtering with a canopy- height based variable window size.Computers and Electron- ics in Agriculture, 37:71–95, 2002
Sorin C Popescu and Randolph H Wynne. Estimating plot- level tree heights with LiDAR: Local filtering with a canopy- height based variable window size.Computers and Electron- ics in Agriculture, 37:71–95, 2002. 2, 3, 4 9
2002
-
[21]
PointNet: Deep learning on point sets for 3D classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. InProceedings of the 2017 IEEE Con- ference on Computer Vision and Pattern Recognition, pages 652–660, 2017. 2
2017
-
[22]
PointNet++: Deep hierarchical feature learning on point sets in a metric space.Advances in Neural Information Processing Systems, 30:5105–5114, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. PointNet++: Deep hierarchical feature learning on point sets in a metric space.Advances in Neural Information Processing Systems, 30:5105–5114, 2017. 2
2017
-
[23]
U- Net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- Net: Convolutional networks for biomedical image segmen- tation. InProceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Inter- vention, Part III, pages 234–241, 2015. 2
2015
-
[24]
Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Franc ¸ois Goulette, and Leonidas Guibas
Hugues Thomas, Charles R. Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Franc ¸ois Goulette, and Leonidas Guibas. KPConv: Flexible and deformable convolution for point clouds. InProceedings of the 17th IEEE/CVF Inter- national Conference on Computer Vision, pages 6411–6420,
-
[25]
LAUTx — Individual tree point clouds from Austrian forest inventory plots.Zenodo, 2022
A Tockner, C Gollob, T Ritter, and A Noth- durft. LAUTx — Individual tree point clouds from Austrian forest inventory plots.Zenodo, 2022. https://doi.org/10.5281/zenodo.6560112. 5, 6, 8, 12
-
[26]
Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in Neural Information Processing Systems, 30, 2017. 2
2017
-
[27]
Test-time augmentation for 3D point cloud classification and segmentation
Tuan Anh Vu, Srinjay Sarkar, Zhiyuan Zhang, Binh Son Hua, and Sai Kit Yeung. Test-time augmentation for 3D point cloud classification and segmentation. InProceedings of the 2024 International Conference on 3D Vision, pages 1543–1553, 2024. 2
2024
-
[28]
Re- mote sensing technologies for enhancing forest inventories: A review.Canadian Journal of Remote Sensing, 42(5):619– 641, 2016
Joanne C White, Nicholas C Coops, Michael A Wulder, Mikko Vastaranta, Thomas Hilker, and Piotr Tompalski. Re- mote sensing technologies for enhancing forest inventories: A review.Canadian Journal of Remote Sensing, 42(5):619– 641, 2016. 1
2016
-
[29]
SegmentAnyTree: A sen- sor and platform agnostic deep learning model for tree seg- mentation using any 3D point cloud data.Remote Sensing of Environment, 313(114367):1–13, 2024
Maciej Wielgosz, Stefano Puliti, Binbin Xiang, Konrad Schindler, and Rasmus Astrup. SegmentAnyTree: A sen- sor and platform agnostic deep learning model for tree seg- mentation using any 3D point cloud data.Remote Sensing of Environment, 313(114367):1–13, 2024. 2
2024
-
[30]
Maciej Wielgosz, Stefano Puliti, and Rasmus Astrup. SegmentAnyTreeV2: Scaling Transformer-based tree instance segmentation across sensors, platforms, and forests.Computing Research Repository, arXiv Preprints, arXiv:2606.08206, pages 1–20, 2026. 2
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Point Transformer V2: Grouped vector atten- tion and partition-based pooling.Advances in Neural Infor- mation Processing Systems, 35:33330–33342, 2022
Xiaoyang Wu, Yixing Lao, Li Jiang, Xihui Liu, and Heng- shuang Zhao. Point Transformer V2: Grouped vector atten- tion and partition-based pooling.Advances in Neural Infor- mation Processing Systems, 35:33330–33342, 2022. 2
2022
-
[32]
Point Transformer V3: Simpler, faster, stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xi- hui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point Transformer V3: Simpler, faster, stronger. In Proceedings of the 2024 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 4840–4851,
2024
-
[33]
Automated forest inventory: Analysis of high- density airborne LiDAR point clouds with 3D deep learning
Binbin Xiang, Maciej Wielgosz, Theodora Kontogianni, Tor- ben Peters, Stefano Puliti, Rasmus Astrup, and Konrad Schindler. Automated forest inventory: Analysis of high- density airborne LiDAR point clouds with 3D deep learning. Remote Sensing of Environment, 305(114078):1–20, 2024. 1, 2, 5, 7
2024
-
[34]
Forest- Former3D: A unified framework for end-to-end segmenta- tion of forest LiDAR 3D point clouds
Binbin Xiang, Maciej Wielgosz, Stefano Puliti, Kamil Kr ´al, Martin Kr˚uˇcek, Azim Missarov, and Rasmus Astrup. Forest- Former3D: A unified framework for end-to-end segmenta- tion of forest LiDAR 3D point clouds. InProceedings of the 20th IEEE/CVF International Conference on Computer Vi- sion, pages 24717–24727, 2025. 1, 2, 3, 5, 6, 7, 8, 12, 14, 15, 16
2025
-
[35]
Lei Yao, Yi Wang, Yawen Cui, Moyun Liu, and Lap-Pui Chau. LaSSM: Efficient semantic-spatial query decoding via Local aggregation and State Space Models for 3D instance segmentation.IEEE Transactions on Circuits and Systems for Video Technology, pages 1–13, 2026. 2, 4
2026
-
[36]
AGILE3D: Attention guided interactive multi- object 3D segmentation
Yuanwen Yue, Sabarinath Mahadevan, Jonas Schult, Francis Engelmann, Bastian Leibe, Konrad Schindler, and Theodora Kontogianni. AGILE3D: Attention guided interactive multi- object 3D segmentation. InProceedings of the 12th Interna- tional Conference on Learning Representations, pages 1–21,
-
[37]
2, 5, 6, 7, 8, 12, 13, 15, 17
-
[38]
Point Transformer
Hengshuang Zhao, Li Jiang, Jiaya Jia, Philip Torr, and Vladlen Koltun. Point Transformer. InProceedings of the 18th IEEE/CVF International Conference on Computer Vi- sion, pages 16259–16268, 2021. 2
2021
-
[39]
Point-SAM: Promptable 3D segmentation model for point clouds
Yuchen Zhou, Jiayuan Gu, Tung Yen Chiang, Fanbo Xi- ang, and Hao Su. Point-SAM: Promptable 3D segmentation model for point clouds. InProceedings of the 13th Interna- tional Conference on Learning Representations, pages 1–20,
-
[40]
2, 4, 5, 6, 7, 8, 11, 12, 13, 15, 17
-
[41]
PartSAM: A scalable promptable part segmentation model trained on native 3D data
Zhe Zhu, Le Wan, Rui Xu, Yiheng Zhang, Honghua Chen, Zhiyang Dou, Cheng Lin, Yuan Liu, and Mingqiang Wei. PartSAM: A scalable promptable part segmentation model trained on native 3D data. InProceedings of the 14th In- ternational Conference on Learning Representations, pages 1–25, 2026. 2, 5, 6, 7, 8, 12, 14, 15, 17 10 A. Promptable Training Loss SelectAn...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.