TruEye: Fine-Grained Detection of AI-Generated Human Subjects in Images
Pith reviewed 2026-06-29 01:52 UTC · model grok-4.3
The pith
TruEye distinguishes five compositional categories of AI-generated human content in images using a dual-stream transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
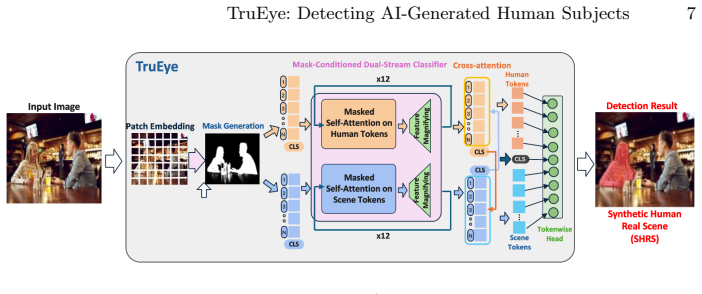
TruEye is the first to distinguish among five compositional categories of synthetic content, including the most challenging case in which a real human is composited into a real scene where they were never physically present. At its core is a mask-conditioned dual-stream transformer that separates human and scene tokens while preserving patch-level spatial correspondence, with region-gated cross attention and token-level supervision yielding robust predictions over 100 times faster than LLM-based methods.
What carries the argument
The mask-conditioned dual-stream transformer with region-gated cross attention and token-level supervision, which separates human and scene tokens and enforces semantic coherence between subject and background.
If this is right
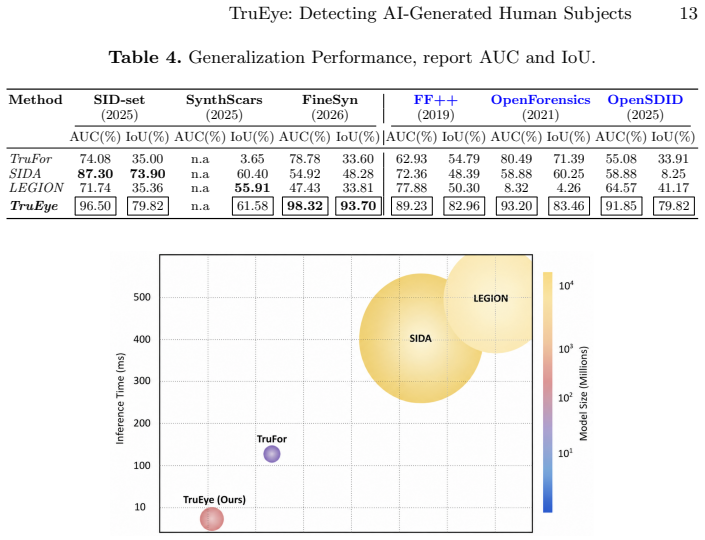
- Surpasses state-of-the-art detectors in accuracy on six datasets and the new FineSyn dataset.
- Generalizes to unseen AI-generated or manipulated images.
- Runs over 100 times faster than LLM-based competitors.
- Provides interpretable predictions without invoking an LLM.
- Localizes and classifies challenging real-human composite cases.
Where Pith is reading between the lines
- The separation of streams could be adapted for detecting other manipulated objects beyond humans.
- Token-level supervision might allow for pixel-precise localization in future extensions.
- Speed improvements enable deployment on resource-limited devices for real-time checks.
- Five-category classification could inform policies on image authenticity in social media.
Load-bearing premise
The mask-conditioned dual-stream transformer will reliably separate human and scene tokens and enforce semantic coherence across unseen generators and real-world compositions.
What would settle it
Evaluation on a new dataset of composited real humans in real scenes generated by a previously unseen method, where the model misclassifies the category at rates similar to or higher than binary detectors.
Figures

read the original abstract
AI generated images are proliferating across the Internet. While some are used for entertainment, others are weaponized for fraud and social engineering attacks on social media users. Existing detectors overfit to generators seen during training, treat detection as opaque binary classification, or rely on costly Large Language Models (LLMs) to explain their outputs. In this paper, we present TruEye, a novel model for fine grained detection and localization of AI manipulated or AI generated humans and scenes. Unlike conventional detectors that assign a single authenticity label, TruEye is the first to distinguish among five compositional categories of synthetic content, including the most challenging case in which a real human is composited into a real scene where they were never physically present. At its core is a mask conditioned dual stream transformer that separates human and scene tokens while preserving patch level spatial correspondence. Specialized reasoning within each stream and region gated cross attention enforce semantic coherence between subject and background, while token level supervision and global compositional classification yield robust, interpretable predictions without invoking an LLM. By restricting intra stream attention to semantically coherent tokens, TruEye also runs over $100\times$ faster than LLM based competitors. Experiments on 6 datasets and our newly curated FineSyn dataset, show that TruEye surpasses state of the art detectors with higher accuracy, faster inference, and stronger generalization to unseen AI generated or manipulated images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TruEye, a mask-conditioned dual-stream transformer for fine-grained detection and localization of AI-generated or manipulated humans in images. It claims to be the first method to distinguish among five compositional categories of synthetic content—including the hardest case of a real human composited into a real scene where they were never physically present—while achieving higher accuracy, stronger generalization across six datasets plus the new FineSyn dataset, and over 100× faster inference than LLM-based competitors, all without relying on LLMs.
Significance. If the performance claims and FineSyn label reliability hold, the work would meaningfully advance beyond binary or LLM-dependent detection by introducing compositional taxonomy and an efficient dual-stream architecture with region-gated cross-attention and token-level supervision. This could have practical impact in applications requiring interpretable, real-time synthetic-content detection.
major comments (2)
- [FineSyn Dataset Curation] The central claim of distinguishing the five compositional categories, especially the 'real human never present' case, rests on FineSyn providing verifiable ground truth for non-presence. The manuscript provides no details on curation (e.g., timestamps, metadata, or scene provenance) that would confirm a human was never in the original scene; without this, the category reduces to generic real-human detection and the five-way taxonomy cannot be meaningfully evaluated.
- [Experiments and Results] The abstract asserts superior accuracy, generalization, and 100× speed on six datasets plus FineSyn, yet the available description supplies no quantitative results, error bars, ablation tables, or dataset statistics. This prevents verification of the performance claims that are load-bearing for the contribution.
minor comments (2)
- [Inference Efficiency] The speed comparison to LLM-based methods should include concrete wall-clock timings, hardware specifications, and batch sizes in a dedicated table or section to support the 100× claim.
- [Method] Notation for the region-gated cross-attention and token-level supervision losses should be introduced with explicit equations rather than descriptive text only.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which identify key areas where the manuscript can be strengthened. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [FineSyn Dataset Curation] The central claim of distinguishing the five compositional categories, especially the 'real human never present' case, rests on FineSyn providing verifiable ground truth for non-presence. The manuscript provides no details on curation (e.g., timestamps, metadata, or scene provenance) that would confirm a human was never in the original scene; without this, the category reduces to generic real-human detection and the five-way taxonomy cannot be meaningfully evaluated.
Authors: We agree that the manuscript lacks sufficient detail on FineSyn curation to allow independent verification of the non-presence labels. In the revised version we will add a dedicated subsection describing the dataset construction process, including scene sources, metadata inspection where available, manual verification protocols used to confirm that inserted humans were never physically present in the original scenes, and any timestamp or provenance records collected during curation. revision: yes
-
Referee: [Experiments and Results] The abstract asserts superior accuracy, generalization, and 100× speed on six datasets plus FineSyn, yet the available description supplies no quantitative results, error bars, ablation tables, or dataset statistics. This prevents verification of the performance claims that are load-bearing for the contribution.
Authors: The referee correctly observes that the abstract contains only qualitative claims. While the full manuscript includes quantitative tables, speed benchmarks, generalization results, ablations, and dataset statistics in the experimental section, we acknowledge that these should be more explicitly summarized for readers. In revision we will insert key numerical results (with error bars where computed) into the abstract and ensure all tables are clearly referenced and complete. revision: yes
Circularity Check
No circularity: empirical architecture with external validation
full rationale
The paper presents TruEye as an empirical neural architecture (mask-conditioned dual-stream transformer with region-gated cross attention and token-level supervision) whose performance claims rest on experimental results across six datasets plus the newly curated FineSyn set. No equations, derivations, or first-principles predictions appear in the provided text; the five-category taxonomy and generalization claims are evaluated via held-out test data rather than being defined into existence by the model itself or by self-citation chains. The architecture choices are presented as design decisions, not as outputs forced by prior self-referential results. This is the standard non-circular case for an applied ML detector paper.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard supervised learning assumptions hold for the token-level and global classification objectives.
invented entities (1)
-
FineSyn dataset
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE Symposium on Security and Privacy (IEEE S&P) (2024)
Abdullah, S.M., Cheruvu, A., Kanchi, S., Chung, T., Gao, P., Jadliwala, M., Viswanath, B.: An analysis of recent advances in deepfake image detection in an evolving threat landscape. In: Proceedings of the IEEE Symposium on Security and Privacy (IEEE S&P) (2024)
2024
-
[2]
In: CVPR
Andriluka, M., Pishchulin, L., Gehler, P., Schiele, B.: 2d human pose estimation: New benchmark and state of the art analysis. In: CVPR. pp. 3686–3693 (2014)
2014
-
[3]
In: ICLR (2018)
Brock, A., Donahue, J., Simonyan, K.: Large scale gan training for high fidelity natural image synthesis. In: ICLR (2018)
2018
-
[4]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Chen, J., Tan, S., Wang, J., Li, W.: Mvss-net: Multi-view multi-scale supervised networks for image manipulation detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 14183–14191 (2021)
2021
-
[5]
Chen, Y., Huang, X., Zhang, Q., Li, W., Zhu, M., Yan, Q., Li, S., Chen, H., Hu, H., Yang, J., Liu, W., Hu, J.: Gim: a million-scale benchmark for generative im- age manipulation detection and localization. In: Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on In- novative Applications of Artificial...
-
[6]
In: CVPR
Choi, Y., Choi, M., Kim, M., Ha, J.W., Kim, S., Choo, J.: Stargan: Unified genera- tive adversarial networks for multi-domain image-to-image translation. In: CVPR. pp. 8789–8797 (2018)
2018
-
[7]
arXiv preprint arXiv:2408.16892 (2024),https://arxiv.org/abs/2408.16892, accessed: Nov 2025
Dagar, D., Vishwakarma, D.K.: Tex-vit: A generalizable, robust, texture-based dual-branch cross-attention deepfake detector. arXiv preprint arXiv:2408.16892 (2024),https://arxiv.org/abs/2408.16892, accessed: Nov 2025
-
[8]
In: CVPR
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: CVPR. pp. 248–255 (2009)
2009
-
[9]
for Good Lab, M.A.: How good are humans at detecting ai-generated images? results from the “real or not?” quiz. arXiv preprint arXiv:2507.18640 (2025), https://arxiv.org/abs/2507.18640, accessed: Nov 2025
-
[10]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Guillaro, M., Verdoliva, L., Cozzolino, D.: Trufor: Leveraging trustworthiness and uncertainty for generalized image forgery detection and localization. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20606–20615 (2023)
2023
-
[11]
Applied Intelligence 55, 1–15 (2025)
Gupta, A., Sharma, N.: Freqfacenet: An enhanced transformer architecture with dual-order frequency attention for ai-generated face detection. Applied Intelligence 55, 1–15 (2025)
2025
-
[12]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025) TruEye: Detecting AI-Generated Human Subjects 17
Huang, T., Zhang, Q., Li, X., Zhao, H., Chen, P.Y.: Sida: Social media image ai- generation detection, localization and explanation with large multimodal models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2025) TruEye: Detecting AI-Generated Human Subjects 17
2025
-
[13]
Huh, M., Liu, A., Owens, A., Efros, A.A.: Fighting fake news: Image splice detec- tion via learned self-consistency. Tech. Rep. UCB/EECS-2018-67, EECS Depart- ment, University of California, Berkeley (2018),https://www2.eecs.berkeley. edu/Pubs/TechRpts/2018/EECS-2018-67.pdf
2018
- [14]
-
[15]
In: ICLR (2018)
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for im- proved quality, stability, and variation. In: ICLR (2018)
2018
-
[16]
In: CVPR
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: CVPR. pp. 4401–4410 (2019)
2019
-
[17]
In: CVPR
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: CVPR. pp. 4401–4410 (2019), introduced FFHQ dataset
2019
-
[18]
In: CVPR
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of stylegan. In: CVPR. pp. 8110–8119 (2020)
2020
-
[19]
In: ECCV (2022)
Ke, Z., Sun, C., Zhu, L., Xu, K., Lau, R.W.H.: Harmonizer: Learning to perform white-box image and video harmonization. In: ECCV (2022)
2022
-
[20]
In: Proceedings of the ACM International Conference on Content-Based Multimedia Indexing (CBMI)
Khan, R., Yu, X., Liu, Y.: Hybrid transformer network for ai-generated image detection. In: Proceedings of the ACM International Conference on Content-Based Multimedia Indexing (CBMI). pp. 1–6 (2022)
2022
-
[21]
arXiv preprint arXiv:2303.00917 (2023), https://arxiv.org/abs/2303.00917, accessed: Nov 2025
Kong, C., Li, H., Wang, S.: Enhancing general face forgery detection via vision transformer with low-rank adaptation. arXiv preprint arXiv:2303.00917 (2023), https://arxiv.org/abs/2303.00917, accessed: Nov 2025
-
[22]
Le, T.N., Nguyen, H.H., Yamagishi, J., Echizen, I.: Openforensics: Large-scale challenging dataset for multi-face forgery detection and segmentation in-the-wild. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 10117–10127 (2021).https://doi.org/10.1109/ICCV48922.2021. 00997
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Li, L., Bao, J., Yang, H., Chen, D., Wen, F.: Face x-ray for more general face forgery detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5001–5010 (2020)
2020
-
[24]
In: ECCV
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Doll´ ar, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV. pp. 740–755 (2014)
2014
-
[25]
arXiv preprint arXiv:2306.02412 (2023),https: //arxiv.org/abs/2306.02412, accessed: Nov 2025
Liu, J., Wang, T., Zhang, S., Liu, F.: Frequency-modulated vision transformers for generalized deepfake detection. arXiv preprint arXiv:2306.02412 (2023),https: //arxiv.org/abs/2306.02412, accessed: Nov 2025
-
[26]
arXiv preprint arXiv:2312.13015 (2023)
Liu, Y., He, B., Zhang, W., Guo, Y.: Forgery-aware adaptive transformer for gen- eralizable synthetic image detection. arXiv preprint arXiv:2312.13015 (2023)
-
[27]
News, A.: How south-east asia’s pig butchering scam- mers are using ai face-swapping and other tools (May 15 2024),https://www.abc.net.au/news/2024-05-16/ pig-butchering-scams-artificial-intelligence-ai-face-swapping-/ 103804830
2024
-
[28]
arXiv preprint arXiv:2411.01256 (2024)
Nguyen, T., Patel, V.M.: Fakeformer: Efficient vulnerability-driven transformers for generalisable deepfake detection. arXiv preprint arXiv:2411.01256 (2024)
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ojha, U., Li, Y., Lee, Y.J.: Towards universal synthetic image detectors that gen- eralize across generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 24480–24489 (2023)
2023
-
[30]
In: CVPR
Park, T., Liu, M.Y., Wang, T.C., Zhu, J.Y.: Semantic image synthesis with spatially-adaptive normalization. In: CVPR. pp. 2337–2346 (2019) 18 J. Barot and D. Lin
2019
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Qu, C., Zhong, Y., Liu, C., Xu, G., Peng, D., Guo, F., Jin, L.: Towards mod- ern image manipulation localization: A large-scale dataset and novel methods. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 10781–10790 (June 2024)
2024
-
[32]
In: CVPR
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR. pp. 10684–10695 (2022)
2022
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
R¨ ossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.: Face- forensics++: Learning to detect manipulated facial images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 1–11 (2019)
2019
-
[34]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2024)
Tan, H., Zhao, Y., Liu, F.: Frequency-aware vision transformers for detecting ai- generated visual content. In: Proceedings of the AAAI Conference on Artificial Intelligence (2024)
2024
-
[35]
Mathematics11(12), 2782 (2023)
Wang, M., Li, P., Chen, L.: Frequency domain filtered residual network for ai- generated image detection. Mathematics11(12), 2782 (2023)
2023
-
[36]
Wang, S.Y., Zhang, O., Owens, A., Efros, A.A.: Cnn-generated images are sur- prisingly easy to spot... for now. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8695–8704 (2020)
2020
- [37]
-
[38]
Wired: Meta finally breaks its silence on pig butchering (Nov 21 2024),https: //www.wired.com/story/meta-pig-butchering-report-2024/
2024
-
[39]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Wu, Y., AbdAlmageed, W., Natarajan, P.: Mantra-net: Manipulation tracing net- work for detection and localization of image forgeries. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 9543–9552 (2019)
2019
-
[40]
In: Proceedings of the AAAI Conference on Ar- tificial Intelligence
Zhang, Z., Li, M., Chang, M.C.: A new benchmark and model for challenging image manipulation detection. In: Proceedings of the AAAI Conference on Ar- tificial Intelligence. pp. 12759–12768 (2024),https://dl.acm.org/doi/10.1609/ aaai.v38i7.28571
2024
-
[41]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhao, H., Dong, J., Chen, M.: Multi-attentional deepfake detection. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2185–2194 (2021)
2021
-
[42]
Communica- tions of the ACM (2025),https://cacm.acm.org/research/ as-good-as-a-coin-toss-human-detection-of-ai-generated-content/, early Access, Accessed: Nov 2025
Zhou, X., Williams, J., Groves, M.: As good as a coin toss: Human detection of ai-generated content. Communica- tions of the ACM (2025),https://cacm.acm.org/research/ as-good-as-a-coin-toss-human-detection-of-ai-generated-content/, early Access, Accessed: Nov 2025
2025
-
[43]
In: CVPR
Zhou, Y., Fang, X., Chen, P.Y., Wang, S.: Sig: Spatially interpretable grounded deepfake detection via vision-language alignment. In: CVPR. pp. 11854–11863 (2024)
2024
-
[44]
In: ICCV
Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: ICCV. pp. 2223–2232 (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.