Policy Gradient Learning for Distributionally Robust Markov Decision Processes under Wasserstein Ambiguity
Pith reviewed 2026-06-29 00:29 UTC · model grok-4.3
The pith
Wasserstein dual reformulation of the robust Bellman recursion produces an explicit recursive robust policy gradient.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using a Wasserstein dual reformulation of the robust Bellman recursion and directional differentiability analysis yields an explicit recursive characterization of the robust policy gradient, enabling a robust actor-critic algorithm.
What carries the argument
Wasserstein dual reformulation of the robust Bellman recursion combined with directional differentiability analysis with respect to policy parameters.
If this is right
- The robust policy gradient can be computed recursively without explicitly solving the inner maximization over transitions at each step.
- A robust actor-critic algorithm follows directly by using the gradient expression for policy updates and the robust value function for the critic.
- The approach applies to both discrete and continuous benchmark MDPs under state-action-dependent ambiguity sets.
Where Pith is reading between the lines
- The same dual-based recursion might extend to infinite-horizon problems if the directional differentiability property carries over to the discounted case.
- Analogous gradient derivations could be attempted for other convex ambiguity sets that admit tractable dual reformulations.
Load-bearing premise
The robust Bellman recursion under state-action-dependent Wasserstein balls admits directional differentiability with respect to policy parameters.
What would settle it
A numerical check in a small discrete MDP showing that the derived recursive gradient expression fails to match the directional derivative obtained by finite policy perturbations would falsify the characterization.
Figures

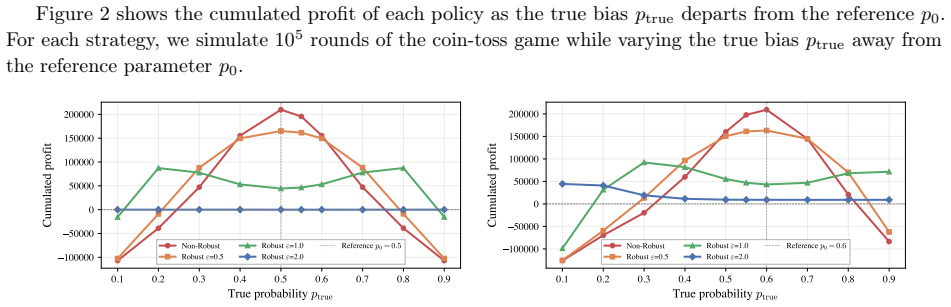
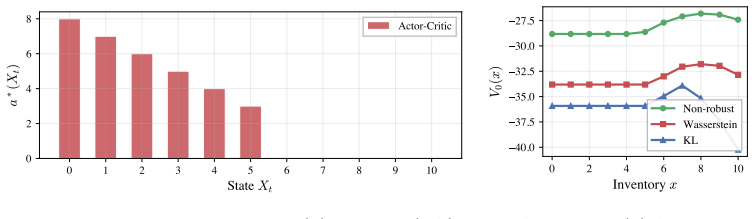
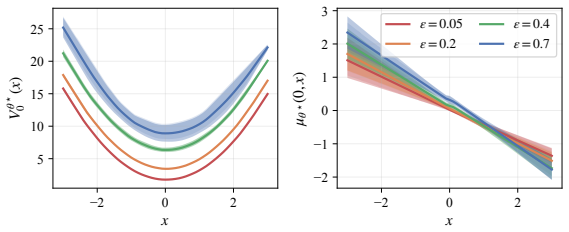

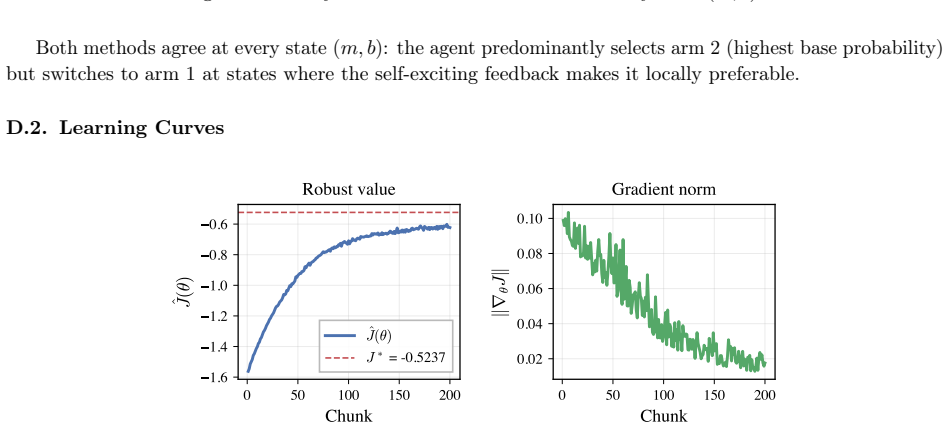
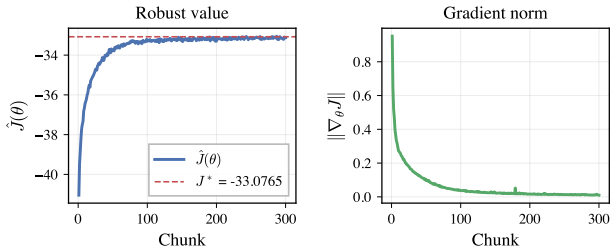
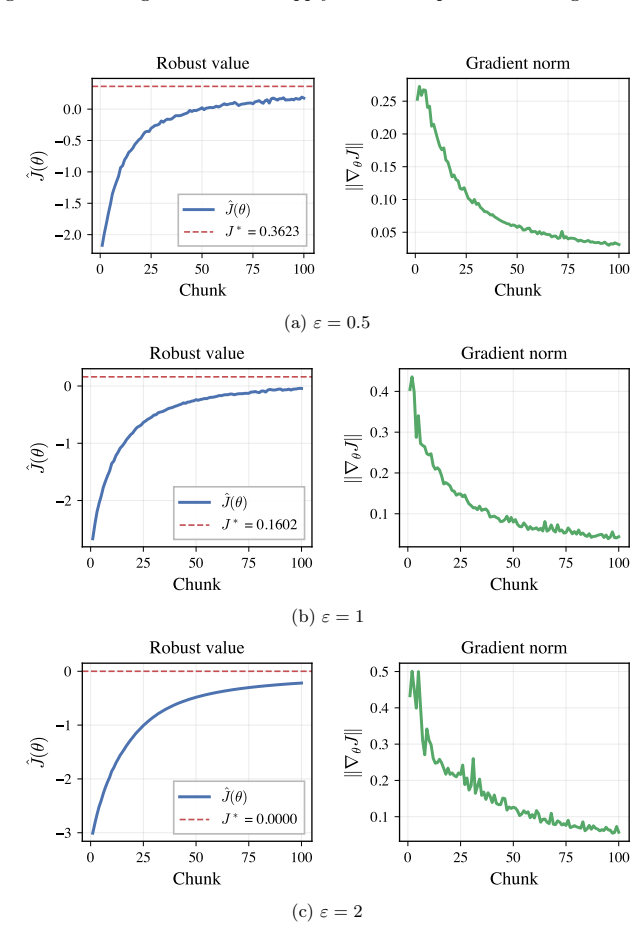
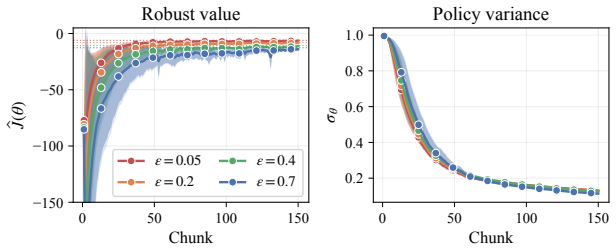
read the original abstract
We study finite-horizon Markov Decision Processes (MDPs) under distributional uncertainty in the transition kernels and develop a policy-gradient framework for Wasserstein distributionally robust control. Ambiguity is modeled by state-action dependent Wasserstein balls around nominal transition kernels, leading to a max-min control problem over randomized policies and admissible transition laws. Since the worst-case transition law depends implicitly on the policy parameters, the usual policy-gradient argument does not apply. We address this difficulty by using a Wasserstein dual reformulation of the robust Bellman recursion and analyzing its directional differentiability. This yields an explicit recursive characterization of the robust policy gradient. Building on this characterization, we propose a robust actor-critic algorithm and illustrate its behavior on discrete and continuous benchmark examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a policy-gradient framework for finite-horizon MDPs with distributional uncertainty modeled via state-action-dependent Wasserstein balls. It employs a Wasserstein dual reformulation of the robust Bellman recursion together with a directional differentiability analysis to obtain an explicit recursive characterization of the robust policy gradient, which supports a robust actor-critic algorithm demonstrated on discrete and continuous benchmarks.
Significance. If the directional differentiability result is rigorously established, the work supplies a technically non-trivial extension of policy-gradient methods to the distributionally robust setting in which the worst-case transition kernel depends on the policy parameters; this addresses a gap that standard policy-gradient arguments cannot handle directly.
major comments (2)
- [dual reformulation and directional differentiability] § on dual reformulation and directional differentiability (abstract and main derivation): the central claim that the robust value function admits a directional derivative w.r.t. policy parameters that can be passed inside the inner supremum over transition kernels requires explicit verification of the requisite regularity conditions (e.g., local strict convexity of the dual or uniform continuity of the subgradient); the abstract sketches the argument but supplies no proof details or counterexample checks, leaving the interchange of gradient and max unverified when the Wasserstein radius is state-action dependent.
- [Robust Bellman recursion] Robust Bellman recursion and gradient characterization: without the directional differentiability step, the claimed recursive form of the robust policy gradient does not follow from the dual reformulation, rendering the subsequent actor-critic construction unsupported; the manuscript must either supply the missing regularity argument or state the precise additional assumptions under which the envelope theorem applies.
minor comments (2)
- [Numerical experiments] The numerical section would benefit from explicit reporting of the Wasserstein radius values used and a sensitivity plot showing how policy performance varies with radius.
- [Notation and preliminaries] Notation for the state-action-dependent radius function should be introduced once and used consistently to avoid ambiguity in the dual formulation.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. The major comments correctly identify that the directional differentiability argument requires more explicit regularity verification to support the recursive gradient characterization. We address each point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [dual reformulation and directional differentiability] § on dual reformulation and directional differentiability (abstract and main derivation): the central claim that the robust value function admits a directional derivative w.r.t. policy parameters that can be passed inside the inner supremum over transition kernels requires explicit verification of the requisite regularity conditions (e.g., local strict convexity of the dual or uniform continuity of the subgradient); the abstract sketches the argument but supplies no proof details or counterexample checks, leaving the interchange of gradient and max unverified when the Wasserstein radius is state-action dependent.
Authors: We agree that the abstract provides only a sketch and that explicit verification of the regularity conditions is needed for rigor when the radius is state-action dependent. In the revision we will add a dedicated lemma verifying local strict convexity of the dual objective (for positive radii) together with uniform continuity of the subgradient with respect to policy parameters. This will justify the interchange under the paper's standing assumptions on the cost and ambiguity sets. revision: yes
-
Referee: [Robust Bellman recursion] Robust Bellman recursion and gradient characterization: without the directional differentiability step, the claimed recursive form of the robust policy gradient does not follow from the dual reformulation, rendering the subsequent actor-critic construction unsupported; the manuscript must either supply the missing regularity argument or state the precise additional assumptions under which the envelope theorem applies.
Authors: We concur that the recursive gradient form rests on the differentiability step. In the revised manuscript we will explicitly list the additional assumptions (Lipschitz continuity of costs, compactness of the parameter space, and positive lower bound on radii) under which the envelope theorem applies, and we will supply the full proof of directional differentiability that closes the argument from the dual reformulation to the recursion. revision: yes
Circularity Check
No circularity: derivation uses external dual properties of Wasserstein distance
full rationale
The claimed derivation proceeds from the robust Bellman recursion via a Wasserstein dual reformulation followed by directional differentiability analysis to obtain an explicit recursive form for the policy gradient. These steps invoke standard mathematical properties of the Wasserstein metric and envelope-type results rather than any self-definition, fitted parameter renamed as prediction, or load-bearing self-citation. No equation in the abstract or described chain reduces the output gradient to an input by construction, and the central result remains independent of the paper's own fitted values or prior unverified claims by the same authors.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Finite-horizon MDPs admit randomized policies and well-defined value functions under distributional uncertainty.
- domain assumption The Wasserstein ball admits a dual reformulation that preserves the structure needed for directional differentiability.
Reference graph
Works this paper leans on
-
[1]
and Zou, S
Wang, Y. and Zou, S. , title =. International Conference on Machine Learning , year =
-
[2]
Lim, S. H. and Xu, H. and Mannor, S. , title =. Advances in Neural Information Processing Systems , volume =
-
[3]
and Ho, C
Wang, Q. and Ho, C. P. and Petrik, M. , title =. Proceedings of the International Conference on Machine Learning (ICML) , pages =
-
[4]
and Sester, J
Neufeld, A. and Sester, J. and. Markov decision processes under model uncertainty , journal =
-
[5]
Sutton, R. S. and Barto, A. G. , title =
-
[6]
and Sester, J
Neufeld, A. and Sester, J. , title =. Automatica , volume =
-
[7]
and Ryll-Nardzewski, C
Kuratowski, K. and Ryll-Nardzewski, C. , title =. Bulletin de l'Acad\'
-
[8]
Bayraktar, E. and Feng, Q. and Zhang, Z. and Zhang, Z. , title =. arXiv preprint arXiv:2511.07235 , year =
-
[9]
Bertsekas, D. P. , title =
-
[10]
and Kuhn, D
Wiesemann, W. and Kuhn, D. and Sim, M. , title =. Operations Research , volume =
-
[11]
and Kuhn, D
Mohajerin Esfahani, P. and Kuhn, D. , title =. Mathematical Programming , volume =
-
[12]
and Kleywegt, A
Gao, R. and Kleywegt, A. J. , title =. Mathematics of Operations Research , volume =
-
[13]
and Kang, Y
Blanchet, J. and Kang, Y. and Murthy, K. , title =. Journal of Applied Probability , volume =
-
[14]
and Drapeau, S
Bartl, D. and Drapeau, S. and Ob. Sensitivity analysis of Wasserstein distributionally robust optimization problems , journal =
-
[15]
and Bhudisaksang, T
Cartea, Á. and Bhudisaksang, T. and Sánchez-Betancourt, L. , title =. Mathematics and Financial Economics , year =
-
[16]
and Thiele, A
Bertsimas, D. and Thiele, A. , title =. Operations Research , volume =
-
[17]
and Border, Kim C
Aliprantis, Charalambos D. and Border, Kim C. , title =
-
[18]
and Ryll-Nardzewski, C
Kuratowski, K. and Ryll-Nardzewski, C. , title =. Bulletin of the Polish Academy of Sciences. Mathematics, Astronomy, Physics , volume =
-
[19]
and Chen, L
Blanchet, J. and Chen, L. and Zhou, XY. , title =. Management Science , volume =
- [20]
-
[21]
Compoint, A. and Sauldubois, N. and Touzi, N. , title =. arXiv preprint arXiv:2511.01828 , year =
-
[22]
Aliprantis, C. D. and Border, K. C. , title =
-
[23]
Kruger, A. Ya. , title =. Journal of Mathematical Sciences , volume =
-
[24]
Kim, Y. G. and Chung, B. D. , title =. Omega , volume =
-
[25]
and El Ghaoui, L
Nilim, A. and El Ghaoui, L. , title =. Operations Research , volume =
-
[26]
Iyengar, G. N. , title =. Mathematics of Operations Research , volume =
-
[27]
and Li, J
Buckdahn, R. and Li, J. , title =. SIAM Journal on Control and Optimization , volume =
-
[28]
Hansen, L. P. and Sargent, T. J. , title =
-
[29]
Hansen, L. P. and Sargent, T. J. , title =. American Economic Review , volume =
-
[30]
Dowson, D. C. and Landau, B. V. , title =. Journal of Multivariate Analysis , volume =
-
[31]
, title =
Yang, I. , title =. IEEE Transactions on Automatic Control , volume =
-
[32]
and Yang, I
Kim, K. and Yang, I. , title =. SIAM Journal on Control and Optimization , volume =
-
[33]
SIAM Journal on Mathematics of Data Science , year=
Robust Reinforcement Learning with Dynamic Distortion Risk Measures , author=. SIAM Journal on Mathematics of Data Science , year=
-
[34]
Scarf, H. E. , title =. Studies in the Mathematical Theory of Inventory and Production , pages =. 1958 , publisher =
1958
-
[35]
and Moon, I
Gallergo, G. and Moon, I. , title =. Journal of the Operational Research Society , volume =. 1993 , doi =
1993
-
[36]
Operations Research , year=
A robust optimization approach to inventory theory , author=. Operations Research , year=
-
[37]
and Xu, H
Lim, S.H.. and Xu, H. and Mannor, S. , journal=. Reinforcement learning in robust. 2013 , volume=
2013
-
[38]
and Ho, C.P
Wang, Q. and Ho, C.P. and Petrik, M. , journal=. Policy gradient in robust. 2023 , pages=
2023
-
[39]
and Sester, J
Neufeld, A. and Sester, J. , journal=. Robust. 2024 , volume=
2024
-
[40]
Mathematics of Operations Research , year=
Quantifying distributional model risk via optimal transport , author=. Mathematics of Operations Research , year=
-
[41]
, title =
Billinsley, P. , title =
-
[42]
Bonnans, J. Fr\'. Optimization Problems with Perturbations: A Guided Tour , journal =. 1998 , doi =
1998
-
[43]
Advances in Neural Information Processing Systems , year =
Policy Gradient for Rectangular Robust Markov Decision Processes , author =. Advances in Neural Information Processing Systems , year =
-
[44]
Advances in Neural Information Processing Systems , year =
Policy Optimization for Robust Average Cost MDPs , author =. Advances in Neural Information Processing Systems , year =
-
[45]
Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , year =
Distributionally Robust Policy Gradient for Offline Contextual Bandits , author =. Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , year =
-
[46]
Tyrrell and Wets, Roger J.-B
Rockafellar, R. Tyrrell and Wets, Roger J.-B. , title =. 1998 , doi =
1998
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.