From General-Purpose Audio Tagging to Spatially Grounded Sound Event Localization and Detection
Pith reviewed 2026-06-29 03:18 UTC · model grok-4.3
The pith
Pretrained general-purpose audio tagging models can support sound event localization and detection when coupled with first-order ambisonics descriptors and multi-stage architecture search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
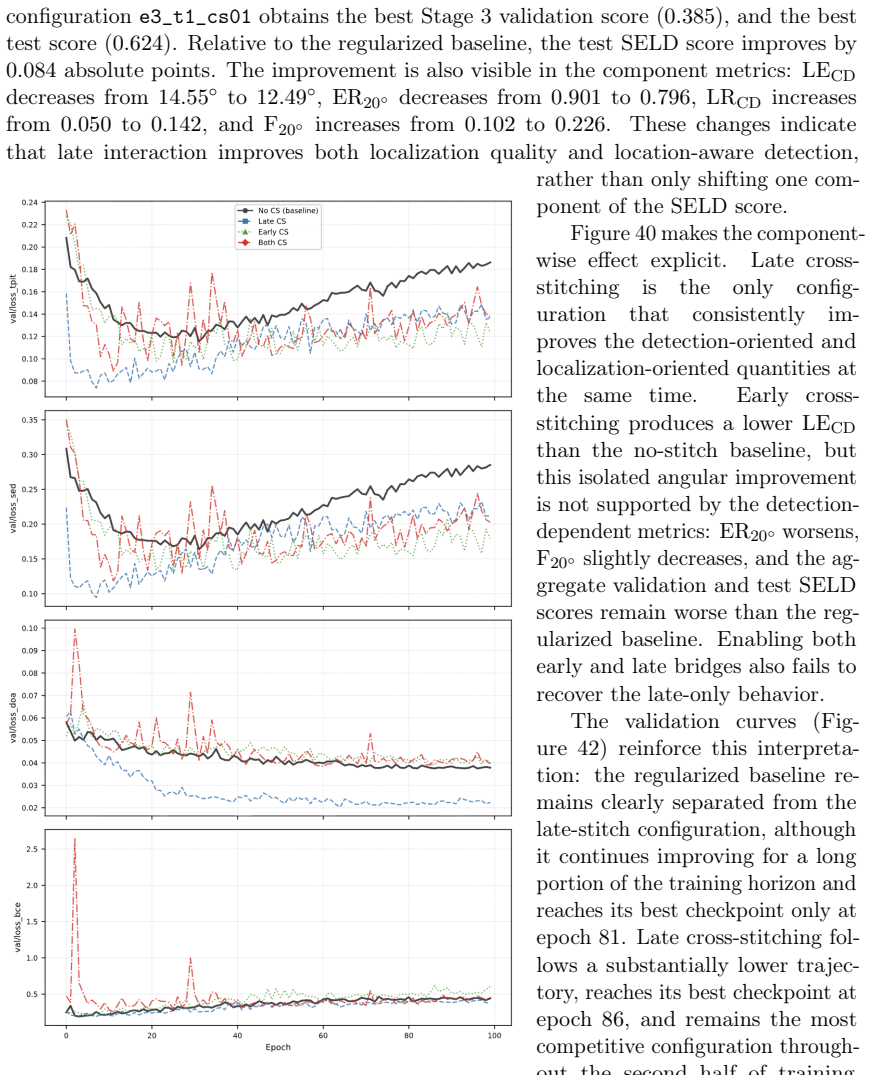
Spectral first-order ambisonics descriptors based on magnitude, phase, and intensity vectors supply the most reliable interface for transferring semantic priors from a general-purpose audio tagging backbone into sound event localization and detection; early residual spatial encoding is the main capacity bottleneck while late cross-stitch fusion and recurrent smoothing act as refinement stages.
What carries the argument
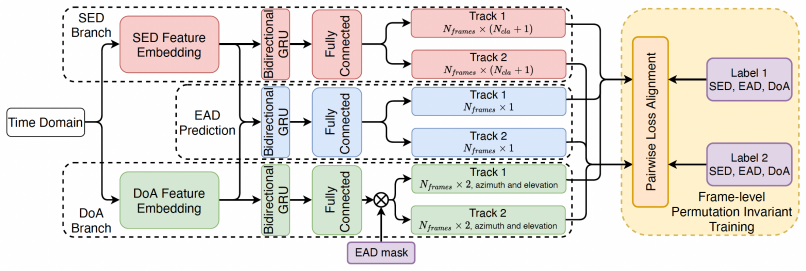
AT2SELD framework that couples a pretrained audio-tagging backbone with first-order ambisonics spatial processing, track-wise SED, Cartesian DOA estimation, permutation-aware supervision, and calibration, discovered via multi-stage NAS.
If this is right
- Spectral FOA magnitude-phase-intensity descriptors enable more reliable semantic-to-spatial transfer than alternative input representations.
- Early residual spatial encoding is the component most sensitive to model capacity; late track-wise abstraction and recurrent smoothing mainly refine outputs.
- Late cross-stitch coupling between semantic and spatial streams improves interaction more effectively than early fusion at lower computational cost.
- Focal loss and activity-conditioned DOA supervision mitigate inactive-target dominance and improve the activity detection point without retraining spatial features.
- Validation-selected thresholds recover calibration performance on new datasets while preserving the spatial learning already achieved.
Where Pith is reading between the lines
- The same descriptor interface may allow pretrained tagging models to initialize other spatial audio tasks such as source separation or acoustic mapping.
- The identified split between early spatial encoding and late semantic refinement could be tested for transfer to non-ambisonics microphone arrays.
- Integrated calibration steps suggest that deployment pipelines for SELD can be made more robust by treating threshold selection as a final validation stage rather than part of spatial training.
Load-bearing premise
Spectral first-order ambisonics descriptors based on magnitude, phase, and intensity vectors form a reliable and general interface for semantic-to-spatial knowledge transfer across datasets.
What would settle it
If the architecture selected by the three-stage NAS fails to outperform a strong non-pretrained baseline on a held-out dataset with new room acoustics or source distributions, the claim that GP-AT priors transfer usefully would be falsified.
Figures












































read the original abstract
This report investigates the extension of pretrained General-Purpose Audio Tagging (GP-AT) models toward spatially grounded Sound Event Localization and Detection (SELD). The proposed AT2SELD framework couples a pretrained AT backbone with compact First-Order Ambisonics (FOA) spatial processing, track-wise SED and Cartesian DOA estimation, permutation aware supervision, and calibration. It characterizes how semantic audio priors support localization-aware scene analysis under data, computation, and deployment constraints. The framework is developed through informed multi-stage Neural Architecture Search (NAS). Stage 1 shows that spectral FOA descriptors, based on magnitude, phase, and Intensity Vectors (IVs), provide the most reliable interface for semantic-to-spatial transfer. Stage 2 identifies early residual spatial encoding as the main capacity-sensitive component, while late track-wise abstraction and recurrent smoothing act mainly as refinement stages. Stage 3 shows that late cross-stitch coupling improves semantic-spatial interaction, whereas early fusion is costlier and less effective. Diagnostic evaluation analyzes the selected architecture under class balancing, focal loss, activity-conditioned DOA supervision, threshold calibration, and transfer across STARSS23, TAU2019, TAU-NIGENS2020, and TAU-NIGENS2021. Focal loss improves the activity point, active-only DOA supervision mitigates inactive target dominance, and validation-selected thresholds recover calibration without replacing spatial learning. Cross-dataset and oracle-activity analyses indicate strong fixed source localization on TAU2019, transferable representations from TAU NIGENS2021, and meaningful but uncertain behavior on STARSS23. Overall, GP-AT priors appear promising for SELD design when embedded in spatial-aware architectures and optimized through integrated calibration and deployment oriented strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the AT2SELD framework, which extends pretrained General-Purpose Audio Tagging (GP-AT) models to Sound Event Localization and Detection (SELD) by coupling them with compact First-Order Ambisonics (FOA) spatial processing, track-wise SED and Cartesian DOA estimation, permutation-aware supervision, and calibration. Developed via a three-stage Neural Architecture Search (NAS), the work identifies spectral FOA descriptors as the optimal interface for semantic-to-spatial transfer, early residual spatial encoding as key, and late cross-stitch coupling as beneficial. Diagnostic experiments evaluate focal loss, activity-conditioned supervision, threshold calibration, and cross-dataset transfer across STARSS23, TAU2019, TAU-NIGENS2020, and TAU-NIGENS2021, concluding that GP-AT priors are promising for SELD when embedded in spatial-aware architectures with integrated optimization strategies.
Significance. If the central claims hold, this work demonstrates a practical pathway for leveraging large pretrained audio tagging models in spatially grounded tasks like SELD, potentially improving data efficiency and performance under computational constraints. The multi-stage NAS provides a systematic empirical approach to architecture exploration, and the focus on calibration and deployment strategies addresses practical applicability. The cross-dataset analysis offers insights into transferability. Credit is due for the diagnostic evaluation of loss functions, supervision variants, and the integrated calibration approach.
major comments (2)
- [Stage 1 of the NAS analysis] Stage 1 of the NAS analysis: The claim that spectral FOA descriptors based on magnitude, phase, and Intensity Vectors provide the most reliable interface for semantic-to-spatial knowledge transfer is load-bearing for the cross-dataset transfer results and the overall conclusion that GP-AT priors are promising. However, the reported results show strong fixed-source behavior on TAU2019, transferable representations only from TAU-NIGENS2021, and uncertain behavior on STARSS23. This pattern is consistent with the descriptors capturing dataset-specific spatial statistics rather than purely semantic features that transfer independently of source configuration or room acoustics.
- [Diagnostic evaluation] Diagnostic evaluation section: The manuscript reports that focal loss improves the activity point, active-only DOA supervision mitigates inactive target dominance, and validation-selected thresholds recover calibration. However, without quantitative ablation tables or error analysis showing the magnitude of these improvements relative to standard baselines (e.g., cross-entropy or full DOA supervision), it is difficult to assess whether these components substantively support the central claim that the GP-AT priors are promising when embedded in the proposed architecture.
minor comments (1)
- [Stage 1-3 NAS descriptions] The delineation of the three NAS stages would benefit from explicit statements of the search space, selection criteria, and computational budget for each stage to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below, with planned revisions where the concerns identify gaps in evidence or clarity.
read point-by-point responses
-
Referee: [Stage 1 of the NAS analysis] Stage 1 of the NAS analysis: The claim that spectral FOA descriptors based on magnitude, phase, and Intensity Vectors provide the most reliable interface for semantic-to-spatial knowledge transfer is load-bearing for the cross-dataset transfer results and the overall conclusion that GP-AT priors are promising. However, the reported results show strong fixed-source behavior on TAU2019, transferable representations only from TAU-NIGENS2021, and uncertain behavior on STARSS23. This pattern is consistent with the descriptors capturing dataset-specific spatial statistics rather than purely semantic features that transfer independently of source configuration or room acoustics.
Authors: We agree that the cross-dataset patterns reported in the manuscript are consistent with partial capture of dataset-specific spatial statistics (particularly the strong fixed-source results on TAU2019). The manuscript already notes this variability, but the referee is correct that the load-bearing claim of a 'most reliable interface for semantic-to-spatial transfer' requires qualification. Stage 1 NAS still shows these descriptors outperforming alternatives, yet the transfer is not purely semantic. We will revise the relevant sections to explicitly discuss this limitation and adjust the strength of the conclusion accordingly. revision: partial
-
Referee: [Diagnostic evaluation] Diagnostic evaluation section: The manuscript reports that focal loss improves the activity point, active-only DOA supervision mitigates inactive target dominance, and validation-selected thresholds recover calibration. However, without quantitative ablation tables or error analysis showing the magnitude of these improvements relative to standard baselines (e.g., cross-entropy or full DOA supervision), it is difficult to assess whether these components substantively support the central claim that the GP-AT priors are promising when embedded in the proposed architecture.
Authors: The referee correctly identifies that the diagnostic section relies on qualitative descriptions rather than quantitative ablations. We will add expanded ablation tables in the revised manuscript that report the magnitude of improvements (e.g., error rate deltas, DOA error reductions) for focal loss vs. cross-entropy, active-only vs. full DOA supervision, and calibrated vs. uncalibrated thresholds, each compared against the relevant baselines. revision: yes
Circularity Check
No significant circularity; empirical NAS-driven design with independent cross-dataset validation.
full rationale
The paper reports results from a multi-stage Neural Architecture Search process that empirically identifies effective components (FOA descriptors in Stage 1, residual encoding in Stage 2, cross-stitch in Stage 3) for coupling pretrained GP-AT backbones with spatial SELD processing. These are presented as search outcomes evaluated on held-out data and cross-dataset transfers (TAU2019, TAU-NIGENS2021, STARSS23), not as closed-form predictions or definitions that reduce to their own inputs by construction. No equations, self-citations, or ansatzes are invoked in a load-bearing way that would create circularity. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Pretrained GP-AT models contain semantic priors that can support localization-aware scene analysis
- domain assumption Spectral FOA descriptors provide the most reliable interface for semantic-to-spatial transfer
Reference graph
Works this paper leans on
-
[1]
Audio Set: An Ontology and Human-Labeled Dataset for Audio Events,
J.F. Gemmeke et al., “Audio Set: An Ontology and Human-Labeled Dataset for Audio Events,” in2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE Press, 2017, p. 776–780
2017
-
[2]
From General-Purpose Audio Tagging to Real-Time Emergency Vehicle Siren Detection,
S. Giacomelli et al., “From General-Purpose Audio Tagging to Real-Time Emergency Vehicle Siren Detection,”IEEE Transactions on Audio, Speech and Language Processing, pp. 1–16, 2026
2026
-
[3]
Sound Event Localization and Detection of Overlapping Sources Using Convolutional Recurrent Neural Networks,
S. Adavanne et al., “Sound Event Localization and Detection of Overlapping Sources Using Convolutional Recurrent Neural Networks,”IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 1, pp. 34–48, 2019
2019
-
[4]
Localization, Detection and Tracking of Multiple Moving Sound Sources with a Convolutional Recurrent Neural Network,
S. Adavanne, A. Politis, and T. Virtanen, “Localization, Detection and Tracking of Multiple Moving Sound Sources with a Convolutional Recurrent Neural Network,” in Proceedings of the Detection and Classification of Acoustic Scenes and Events 2019 Workshop (DCASE2019), 2019, pp. 20–24
2019
-
[5]
Permutation Invariant Recurrent Neural Networks for Sound Source Tracking Applications,
D. Diaz-Guerra et al., “Permutation Invariant Recurrent Neural Networks for Sound Source Tracking Applications,” inProceedings of Forum Acusticum 2023, 2023, preprint also available as arXiv:2306.08510
-
[6]
TheNERC-SLIPSystemforSoundEventLocalizationandDetectionof DCASE2022 Challenge,
Q.Wangetal., “TheNERC-SLIPSystemforSoundEventLocalizationandDetectionof DCASE2022 Challenge,” inProceedings of the Detection and Classification of Acoustic Scenes and Events 2022 Workshop (DCASE2022), 2022
2022
-
[7]
The Neural-SRP Method for Universal Robust Multi-Source Tracking,
E. Grinstein aet al., “The Neural-SRP Method for Universal Robust Multi-Source Tracking,”IEEE Open Journal of Signal Processing, vol. 5, pp. 19–38, 2024
2024
-
[8]
Sound Event Detection: A Tutorial,
A. Mesaros et al., “Sound Event Detection: A Tutorial,”IEEE Signal Processing Magazine, vol. 38, no. 5, pp. 67–83, 2021
2021
-
[9]
ACCDOA: Activity-Coupled Cartesian Direction of Arrival Repre- sentation for Sound Event Localization and Detection,
K. Shimada et al., “ACCDOA: Activity-Coupled Cartesian Direction of Arrival Repre- sentation for Sound Event Localization and Detection,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 915–919
2021
-
[10]
Multi-ACCDOA: Localizing and Detecting Overlapping Sounds From the Same Class With Auxiliary Duplicating Permutation Invariant Training,
——, “Multi-ACCDOA: Localizing and Detecting Overlapping Sounds From the Same Class With Auxiliary Duplicating Permutation Invariant Training,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 316–320
2022
-
[11]
Event-Independent Network for Polyphonic Sound Event Localization and Detection,
Y. Cao et al., “Event-Independent Network for Polyphonic Sound Event Localization and Detection,” inProceedings of the Detection and Classification of Acoustic Scenes and Events 2020 Workshop (DCASE2020), 2020, pp. 112–116
2020
-
[12]
An Improved Event-Independent Network for Polyphonic Sound Event Local- ization and Detection,
——, “An Improved Event-Independent Network for Polyphonic Sound Event Local- ization and Detection,” inICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 885–889
2021
-
[13]
Attention Is All You Need,
A. Vaswani et al., “Attention Is All You Need,” inProceedings of the 31st International Conference on Neural Information Processing Systems, ser. NIPS’17. Red Hook, NY, USA: Curran Associates Inc., 2017, p. 6000–6010. 121
2017
-
[14]
Cross-stitch networks for multi-task learning,
I. Misra et al., “Cross-stitch networks for multi-task learning,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
2016
-
[15]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” inInter- national Conference on Learning Representations (ICLR), 2015, poster presentation, preprint available at ArXiv 10.48550/arXiv.1412.6980
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1412.6980 2015
-
[16]
Early Stopping — But When?
L. Prechelt, “Early Stopping — But When?” inNeural Networks: Tricks of the Trade, ser. Lecture Notes in Computer Science, G. Montavon, G. B. Orr, and K.-R. Müller, Eds. Berlin, Heidelberg: Springer, 2012, vol. 7700, pp. 53–67
2012
-
[17]
TUT Sound Events 2018 - Ambisonic, Anechoic and Synthetic Impulse Response Dataset,
S. Adavanne, A. Politis, and T. Virtanen, “TUT Sound Events 2018 - Ambisonic, Anechoic and Synthetic Impulse Response Dataset,” Apr. 2018
2018
-
[18]
U Recurrent Neural Network for Polyphonic Sound Event Detection and Localization,
L. Pi et al., “U Recurrent Neural Network for Polyphonic Sound Event Detection and Localization,” inProceedings of the 2020 13th International Symposium on Chinese Spoken Language Processing (ISCSLP), 2020, pp. 1–5
2020
-
[19]
U-Net: Convolutional Networks for Biomed- ical Image Segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional Networks for Biomed- ical Image Segmentation,” inMedical Image Computing and Computer-Assisted Inter- vention – MICCAI 2015. Springer International Publishing, 2015, pp. 234–241
2015
-
[20]
The Generalized Correlation Method for Estimation of Time Delay,
C. Knapp and G. Carter, “The Generalized Correlation Method for Estimation of Time Delay,”IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 24, no. 4, pp. 320–327, 1976
1976
-
[21]
Minimal Gated Unit for Recurrent Neural Networks,
G. Zhou et al., “Minimal Gated Unit for Recurrent Neural Networks,”International Journal of Automation and Computing, vol. 13, no. 3, pp. 226–234, 2016
2016
-
[22]
Resnet-Conformer Network using Multi-Scale Channel Attention for Sound Event Localization and Detection in Real Scenes,
L. Xue et al., “Resnet-Conformer Network using Multi-Scale Channel Attention for Sound Event Localization and Detection in Real Scenes,” in2023 IEEE 15th Interna- tional Conference on Wireless Communications and Signal Processing (WCSP), 2023, pp. 1–6
2023
-
[23]
ResNet-Conformer Network with Shared Weights and Atten- tion Mechanism for Sound Event Localization, Detection, and Distance Estimation,
Q. T. Vo and D. K. Han, “ResNet-Conformer Network with Shared Weights and Atten- tion Mechanism for Sound Event Localization, Detection, and Distance Estimation,” inProceedings of the Detection and Classification of Acoustic Scenes and Events 2024 Workshop (DCASE2024), 2024
2024
-
[24]
Deep residual learning for image recognition,
K. He et al., “Deep residual learning for image recognition,” in2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 770–778
2016
-
[25]
Zhang et al.,Dive into Deep Learning
A. Zhang et al.,Dive into Deep Learning. Cambridge University Press, 2023. [Online]. Available: https://d2l.ai/
2023
-
[26]
Conformer: Convolution-augmented Transformer for Speech Recogni- tion,
A. Gulati et al., “Conformer: Convolution-augmented Transformer for Speech Recogni- tion,” inProceedings of Interspeech 2020, 2020, pp. 5036–5040
2020
-
[27]
STARSS22: A Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events,
A. Politis et al., “STARSS22: A Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events,” inProceedings of the Detection and Classification of Acoustic Scenes and Events 2022 Workshop (DCASE2022), 2022, pp. 125–129
2022
-
[28]
Starss23: Sony-tau realistic spatial soundscapes 2023,
——, “Starss23: Sony-tau realistic spatial soundscapes 2023,” Mar. 2023. [Online]. Available: https://doi.org/10.5281/zenodo.7880637 122
-
[29]
ESC: Dataset for Environmental Sound Classification,
K. J. Piczak, “ESC: Dataset for Environmental Sound Classification,” inProceedings of the 23rd ACM International Conference on Multimedia. ACM, 2015, pp. 1015–1018
2015
-
[30]
FSD50K: An Open Dataset of Human-Labeled Sound Events,
E. Fonseca et al., “FSD50K: An Open Dataset of Human-Labeled Sound Events,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 829–852, 2022
2022
-
[31]
TAU-NIGENS Spatial Sound Events 2021: A Synthetic Spatial Sound Events Dataset,
A. Politis et al., “TAU-NIGENS Spatial Sound Events 2021: A Synthetic Spatial Sound Events Dataset,” inProceedings of the Detection and Classification of Acoustic Scenes and Events 2021 Workshop (DCASE2021), 2021, pp. 189–193
2021
-
[32]
AugMix: A Simple Method to Improve Robustness and Uncer- tainty under Data Shift,
D. Hendrycks et al., “AugMix: A Simple Method to Improve Robustness and Uncer- tainty under Data Shift,” inInternational Conference on Learning Representations, 2020
2020
-
[33]
SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,
D.S. Park et al., “SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition,” inProceedings of Interspeech 2019, 2019, pp. 2613–2617
2019
-
[34]
SoundDet: Polyphonic Moving Sound Event De- tection and Localization from Raw Waveform,
Y. He, N. Trigoni, and A. Markham, “SoundDet: Polyphonic Moving Sound Event De- tection and Localization from Raw Waveform,” inProceedings of the 38th International Conference on Machine Learning (ICML), 2021, pp. 4160–4170, preprint available at arXiv:2106.06969
-
[35]
SoundDoA: Learn Sound Source Direction of Arrival and Semantics from Sound Raw Waveforms,
Y. He and A. Markham, “SoundDoA: Learn Sound Source Direction of Arrival and Semantics from Sound Raw Waveforms,” inProceedings of the Annual Conference of the International Speech Communication Association (Interspeech), 2022, pp. 2408–2412
2022
-
[36]
Differentiable Tracking-Based Training of Deep Learning Sound Source Localizers,
S. Adavanne, A. Politis, and T. Virtanen, “Differentiable Tracking-Based Training of Deep Learning Sound Source Localizers,” in2021 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2021, pp. 1–5, preprint available at arXiv:2111.00030
-
[37]
Robust Sound Source Tracking Using SRP-PHAT and 3D Convolutional Neural Networks,
D. Diaz-Guerra, A. Miguel, and J. R. Beltran, “Robust Sound Source Tracking Using SRP-PHAT and 3D Convolutional Neural Networks,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 300–311, 2021
2021
-
[38]
E-PANNs: Sound recognition using efficient pre-trained audio neural networks,
A. Singh, H. Liu, and M. D. Plumbley, “E-PANNs: Sound recognition using efficient pre-trained audio neural networks,” inInter-Noise and Noise-Con Congress and Conference Proceedings, vol. 268, no. 1. Institute of Noise Control Engineering, 2023, pp. 7220–7228
2023
-
[39]
Efficient CNNs via Passive Filter Pruning,
A. Singh and M. D. Plumbley, “Efficient CNNs via Passive Filter Pruning,”IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 33, pp. 1763–1774, 2025
2025
-
[40]
Neural Architecture Search: A Survey,
T. Elsken, J. H. Metzen, and F. Hutter, “Neural Architecture Search: A Survey,” Journal of Machine Learning Research, vol. 20, no. 55, pp. 1–21, 2019
2019
-
[41]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
A.G. Howard et al., “MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications,”preprint arXiv:1704.04861, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
Focal Loss for Dense Object Detection,
T. Lin et al., “Focal Loss for Dense Object Detection,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 42, no. 2, pp. 318–327, 2020. 123
2020
-
[43]
Decoupled Weight Decay Regularization,
I. Loshchilov and F. Hutter, “Decoupled Weight Decay Regularization,” in International Conference on Learning Representations (ICLR), 2019. [Online]. Available: https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[44]
SGDR: Stochastic Gradient Descent with Warm Restarts,
——, “SGDR: Stochastic Gradient Descent with Warm Restarts,” inInternational Conference on Learning Representations (ICLR), 2017. [Online]. Available: https://openreview.net/forum?id=Skq89Scxx
2017
-
[45]
STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events,
K. Shimada et al., “STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 3488–3500, 2023
2023
-
[46]
A Multi-Room Reverberant Dataset for Sound Event Localization and Detection,
S. Adavanne, A. Politis, and T. Virtanen, “A Multi-Room Reverberant Dataset for Sound Event Localization and Detection,” inProceedings of the Detection and Classifi- cation of Acoustic Scenes and Events 2019 Workshop (DCASE2019), New York, NY, USA, 2019
2019
-
[47]
A Dataset of Reverberant Spatial Sound Scenes with Moving Sources for Sound Event Localization and Detection,
A. Politis, S. Adavanne, and T. Virtanen, “A Dataset of Reverberant Spatial Sound Scenes with Moving Sources for Sound Event Localization and Detection,” in Proceedings of the Detection and Classification of Acoustic Scenes and Events 2020 Challenge, 2020. [Online]. Available: https://dcase.community/documents/challenge2 020/technical_reports/DCASE2020_Po...
2020
-
[48]
A Four-Stage Data Augmentation Approach to ResNet-Conformer Based Acoustic Modeling for Sound Event Localization and Detection,
Q. Wang et al., “A Four-Stage Data Augmentation Approach to ResNet-Conformer Based Acoustic Modeling for Sound Event Localization and Detection,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 1251–1264, 2023
2023
-
[49]
Paszke et al.,PyTorch: an imperative style, high-performance deep learning library
A. Paszke et al.,PyTorch: an imperative style, high-performance deep learning library. Red Hook, NY, USA: Curran Associates Inc., 2019
2019
-
[50]
An Optimal Algorithm for Selection in a Min-Heap,
G. N. Frederickson, “An Optimal Algorithm for Selection in a Min-Heap,”Information and Computation, vol. 104, no. 2, pp. 197–214, Jun. 1993. 124
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.